A Smart Classroom Behavior Analysis Framework with a New Highly Congested Classroom Dataset
Pith reviewed 2026-06-26 14:58 UTC · model grok-4.3
The pith
ODER-HSFNet with three custom modules outperforms standard YOLO detectors on crowded classroom behavior tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
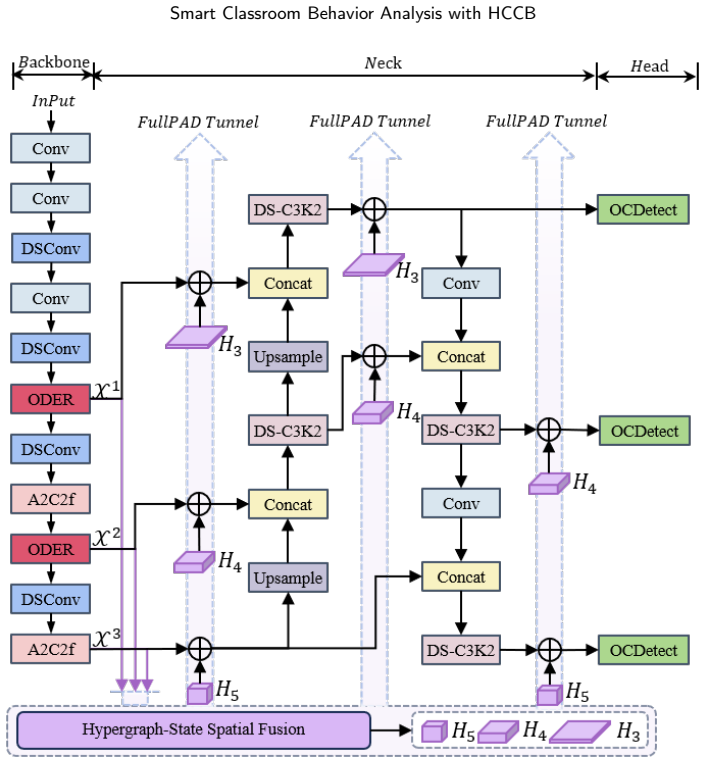
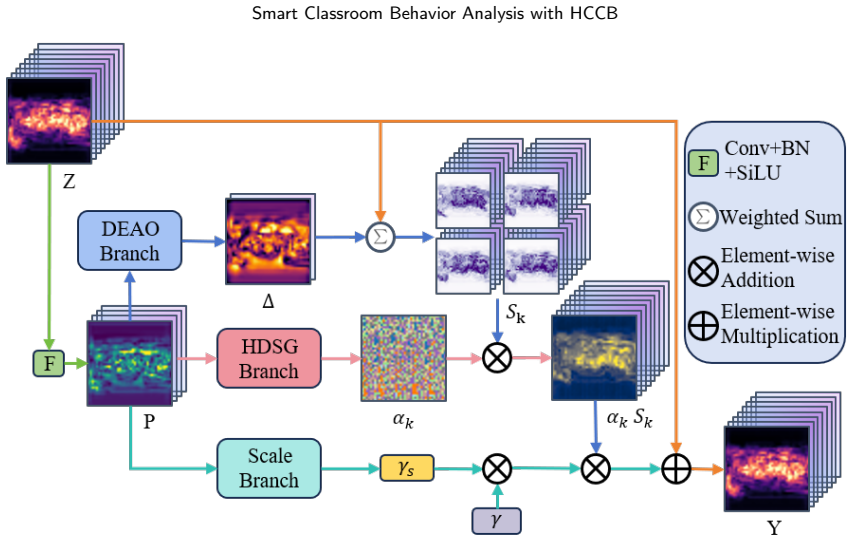
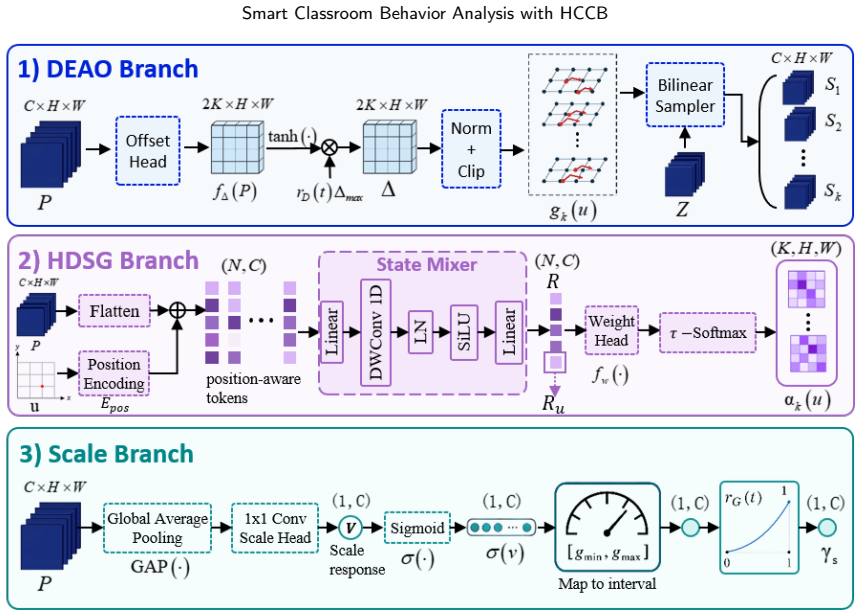
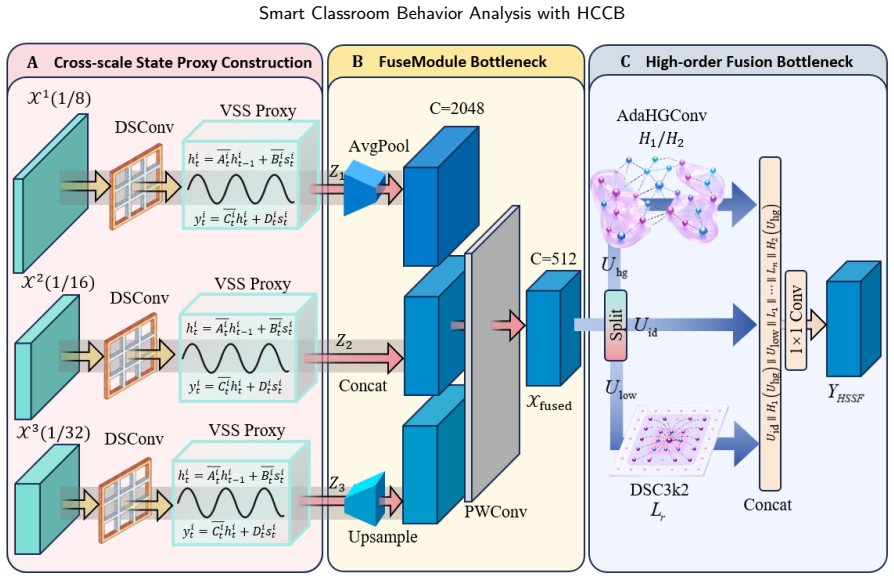
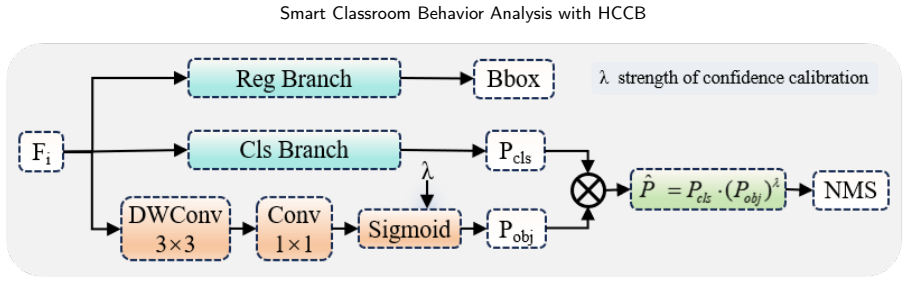
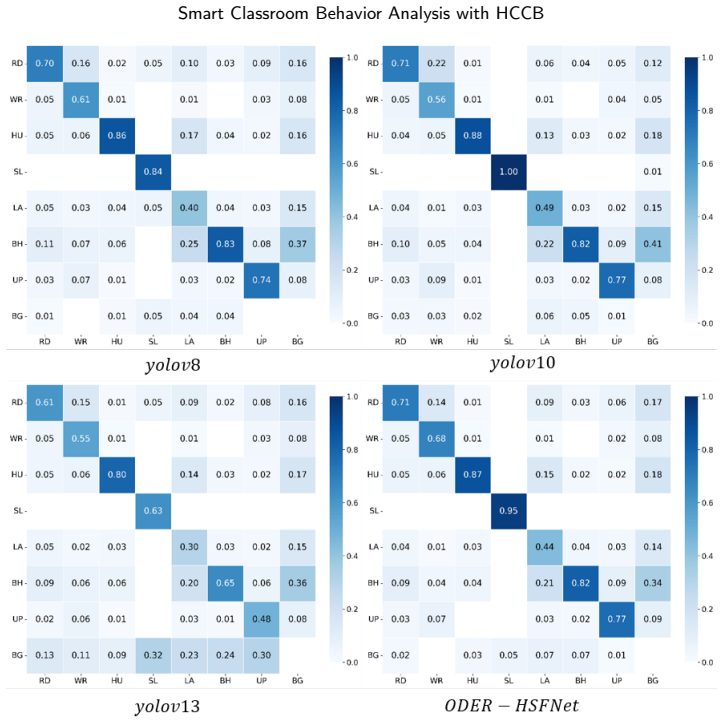
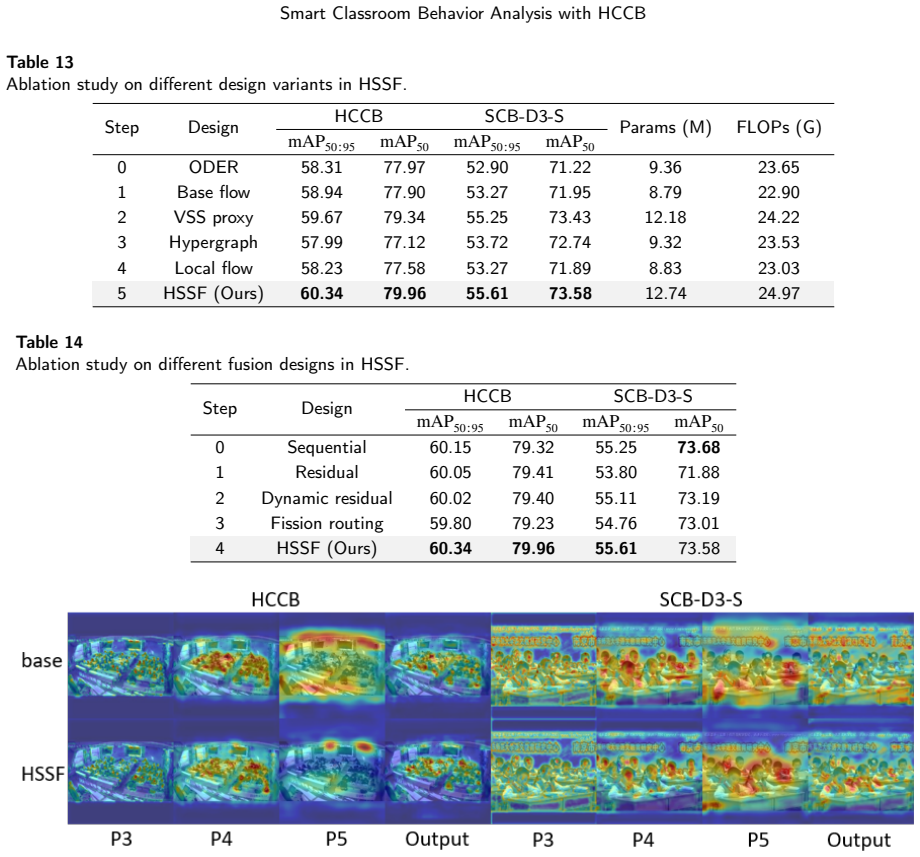
The authors claim that the ODER-HSFNet framework, built around the Occlusion-aware Deformable Edge Rectifier for boundary strengthening, the Hypergraph-State Spatial Fusion module for local-to-global context integration, and the Occlusion-Calibrated Detection Head for pruning weak candidates, delivers higher mean average precision than mainstream YOLO detectors when locating seven categories of student behavior under the conditions captured in the HCCB dataset.
What carries the argument
ODER-HSFNet, the YOLO-based detector whose three modules (ODER for deformable edge correction under occlusion, HSSF for hypergraph and state-space fusion, and OCDetect for pre-NMS candidate filtering) target the specific failure modes of dense classroom scenes.
If this is right
- Boundary evidence remains usable even when neighboring students heavily overlap.
- High-order spatial relations among instances can be aggregated without separate post-processing steps.
- False positives triggered by occlusion edges or adjacent students drop after candidate calibration.
- The same three modules transfer to the SCB-D3-S classroom dataset and still improve over unmodified YOLO baselines.
- Ablation results indicate that removing any one module measurably lowers performance on the congested benchmark.
Where Pith is reading between the lines
- The module pattern could be tested on other dense detection problems such as counting attendees at events or monitoring livestock in pens.
- The HCCB construction guidelines might be reused to create comparable benchmarks for fine-grained action categories in other crowded indoor settings.
- Video extensions of the same head could track behavior sequences across frames once single-frame detection is stabilized.
Load-bearing premise
The four listed scene challenges are the primary reasons standard detectors fail, and the three added modules correct them without introducing new failure modes or overfitting to the HCCB data collection process.
What would settle it
A baseline YOLO model trained from scratch on the HCCB training split that reaches or exceeds the reported 60.60 percent mAP50:95 and 80.12 percent mAP50 would show that the custom modules are not necessary for the claimed improvement.
Figures




read the original abstract
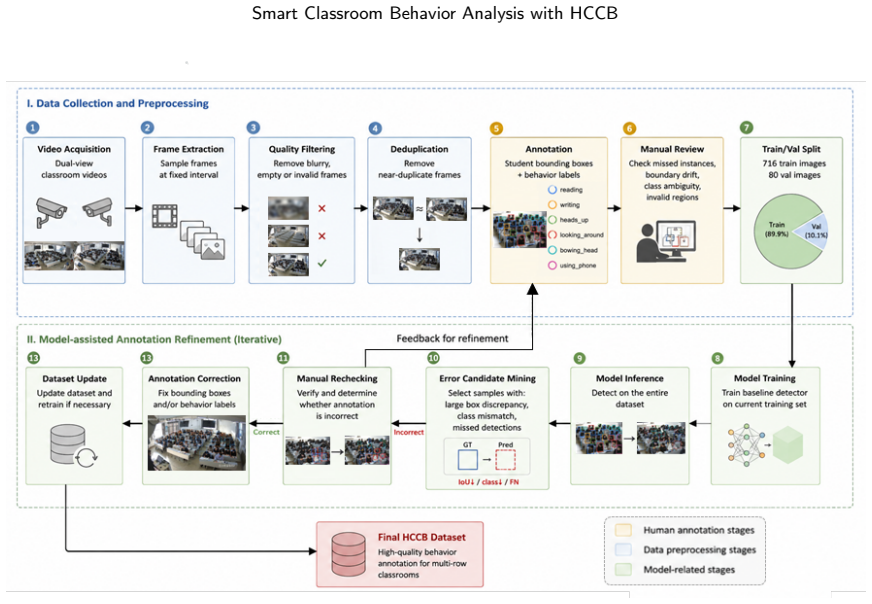
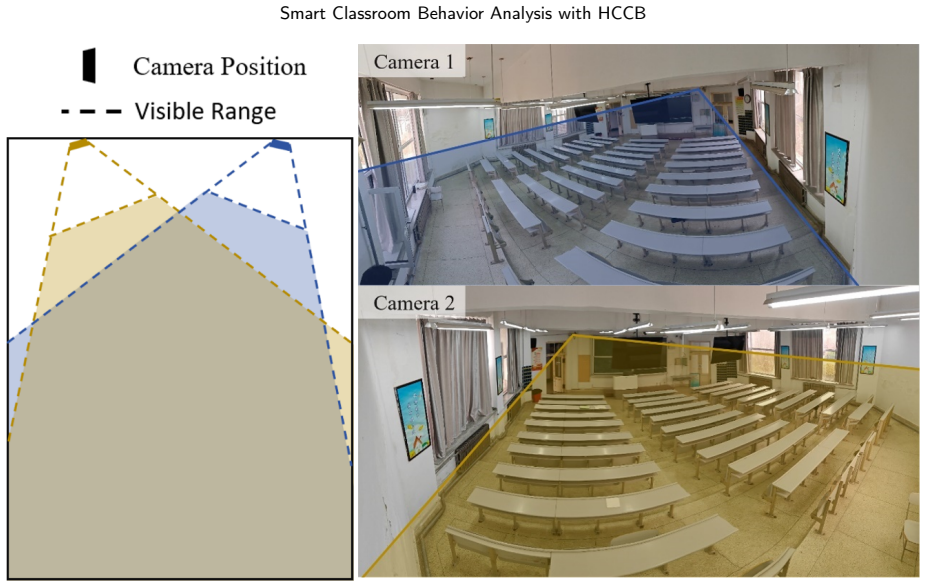
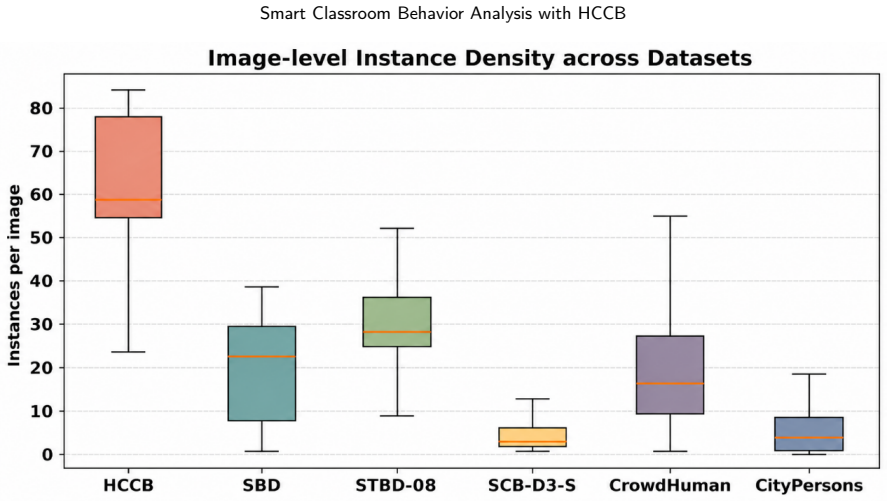
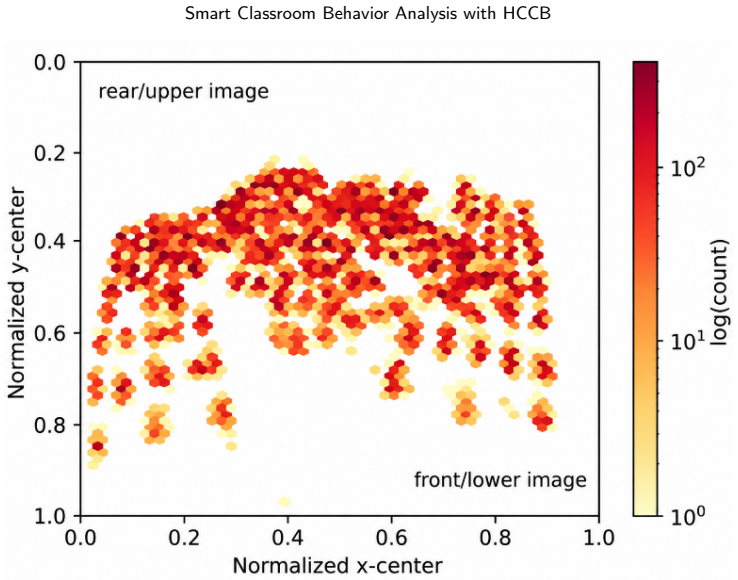
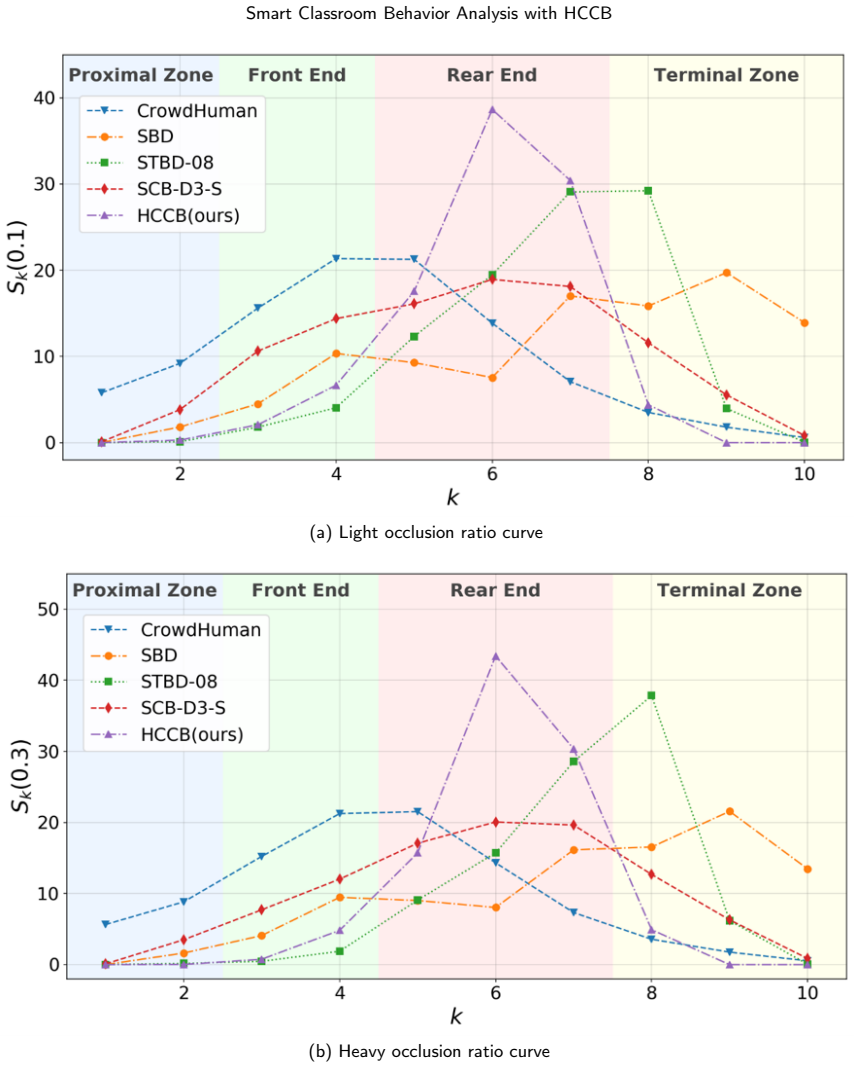
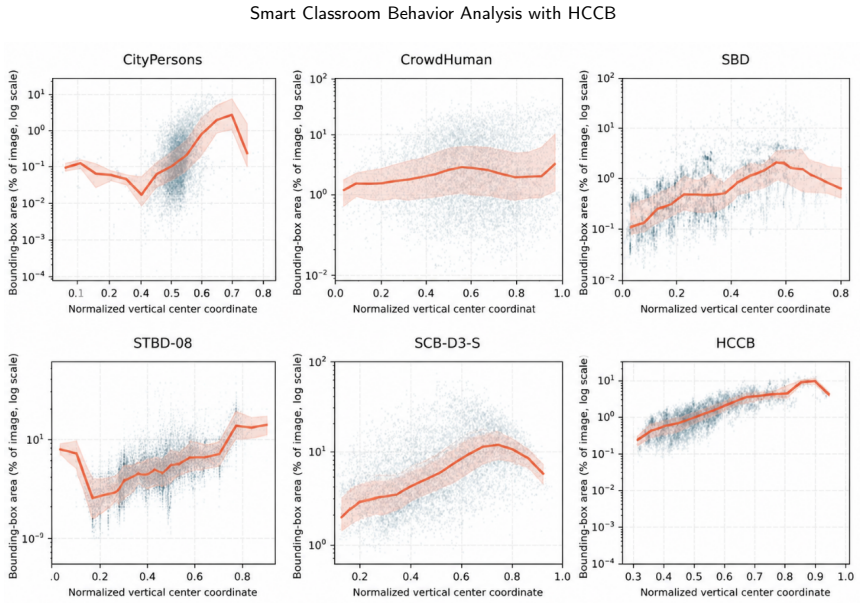
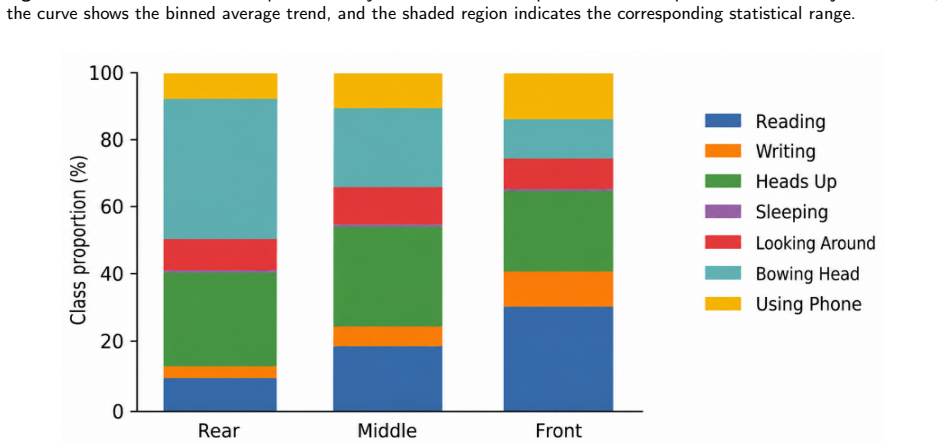
Student behavior detection is important for intelligent classroom analysis but remains challenging in large-class scenarios due to dense instance co-occurrence, asymmetric occlusion, depth-wise scale variation, and fine-grained semantic degradation in distant targets. Existing classroom behavior datasets and general-purpose detectors are insufficient to characterize and address these challenges. This paper constructs the Highly Congested Classroom Behavior (HCCB) dataset, containing 50,229 student behavior instances across seven categories: reading, writing, heads up, sleeping, looking around, bowing head, and using phone. HCCB provides a challenging benchmark that integrates dense distributions, severe occlusion, scale variation, and fine-grained behavioral semantics. To address these issues, we propose ODER-HSFNet, a YOLO-based detection framework tailored to highly crowded classrooms. At its core, ODER-HSFNet introduces three task-specific innovations: the Occlusion-aware Deformable Edge Rectifier (ODER), which strengthens boundary evidence under occlusion; the Hypergraph-State Spatial Fusion (HSSF) module, which integrates local structure enhancement, state-space contextual modeling, and high-order relation aggregation; and the Occlusion-Calibrated Detection Head (OCDetect), which suppresses low-quality Pre-NMS candidates and reduces false positives from occlusion boundaries and neighboring instances. Experiments on two classroom behavior detection datasets show that ODER-HSFNet outperforms mainstream YOLO-series methods, achieving 60.60%/80.12% mAP50:95/mAP50 on HCCB and 57.36%/74.65% on SCB-D3-S. Ablation studies further verify the effectiveness of the proposed design for highly crowded classroom behavior detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Highly Congested Classroom Behavior (HCCB) dataset with 50,229 instances across seven behavior categories and proposes ODER-HSFNet, a YOLO-based detector incorporating the Occlusion-aware Deformable Edge Rectifier (ODER), Hypergraph-State Spatial Fusion (HSSF) module, and Occlusion-Calibrated Detection Head (OCDetect). It reports that ODER-HSFNet outperforms YOLO-series baselines, achieving 60.60%/80.12% mAP50:95/mAP50 on HCCB and 57.36%/74.65% on SCB-D3-S, with ablation studies verifying module contributions.
Significance. If the quantitative claims are reproducible, the work contributes a new challenging benchmark for crowded classroom scenes and task-specific modules addressing occlusion and scale issues. Credit is given for conducting ablation studies that isolate module effects and for evaluating on an external dataset (SCB-D3-S).
major comments (2)
- [Experiments] Experiments section: The mAP improvements are reported without error bars, standard deviations across runs, or statistical tests, which is required to establish that outperformance over YOLO baselines is reliable rather than due to random variation on the newly constructed HCCB dataset.
- [Experiments] Experimental setup: No details are provided on train/validation/test splits, cross-validation procedure, or hyperparameter selection for the HCCB and SCB-D3-S evaluations; this directly affects the load-bearing claim of module effectiveness and outperformance.
minor comments (2)
- [Introduction] The abstract and introduction list four challenges but do not explicitly map each to the three modules with supporting citations or preliminary experiments; a table linking challenges to modules would improve clarity.
- Notation for the three modules (ODER, HSSF, OCDetect) should be introduced consistently with full names on first use in all sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental rigor. We address each major comment below and will revise the manuscript accordingly to strengthen reproducibility and statistical reliability.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The mAP improvements are reported without error bars, standard deviations across runs, or statistical tests, which is required to establish that outperformance over YOLO baselines is reliable rather than due to random variation on the newly constructed HCCB dataset.
Authors: We agree that the absence of error bars and statistical tests limits the strength of the outperformance claims. In the revised manuscript, we will conduct additional training runs using different random seeds, report mean mAP50:95 and mAP50 values with standard deviations, and include paired statistical tests (e.g., t-tests) against the YOLO baselines to demonstrate that the gains are not due to random variation. revision: yes
-
Referee: [Experiments] Experimental setup: No details are provided on train/validation/test splits, cross-validation procedure, or hyperparameter selection for the HCCB and SCB-D3-S evaluations; this directly affects the load-bearing claim of module effectiveness and outperformance.
Authors: We acknowledge that these experimental details are necessary for full reproducibility. The revised manuscript will add a dedicated subsection in the Experiments section that explicitly describes the train/validation/test splits for both HCCB and SCB-D3-S, the cross-validation procedure (if used), and the hyperparameter selection process. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the HCCB dataset and proposes ODER-HSFNet with three modules (ODER, HSSF, OCDetect) whose effectiveness is shown via direct mAP comparisons to YOLO baselines on HCCB and the external SCB-D3-S dataset, plus ablation studies. No equations or claims reduce a prediction to a fitted input by construction, no self-citations bear the central load, and no uniqueness theorems or ansatzes are smuggled in. The reported results are standard empirical measurements on held-out and external data, making the evaluation chain self-contained.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Occlusion-aware Deformable Edge Rectifier (ODER)
no independent evidence
-
Hypergraph-State Spatial Fusion (HSSF) module
no independent evidence
-
Occlusion-Calibrated Detection Head (OCDetect)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
H. Zhou, F. Jiang, J. Si, L. Xiong, and H. Lu. StuArt: Individualized classroom observation of students with automatic behavior recognition and tracking, 2022. arXiv preprint
2022
-
[2]
F. C. Lin, H. H. Ngo, C. R. Dow, K. H. Lam, and H. L. Le. Student behavior recognition system for the classroom environment based on skeleton pose estimation and person detection.Sensors, 21(16):5314, 2021
2021
-
[3]
Yang and T
F. Yang and T. Wang. SCB-Dataset3: A benchmark for detecting student classroom behavior, 2023. arXiv preprint
2023
-
[4]
F. Yang. Student classroom behavior detection based on improved YOLOv7, 2023. arXiv preprint
2023
-
[5]
Featurepyramidnetworksforobjectdetection
T.Y.Lin,P.Doll’ar,R.Girshick,K.He,B.Hariharan,andS.Belongie. Featurepyramidnetworksforobjectdetection. InProceedingsofthe IEEE Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017
2017
-
[6]
Redmon, S
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 779–788, 2016
2016
-
[7]
YOLOv13:Real-timeobjectdetectionwithhypergraph- enhanced adaptive visual perception, 2025
M.Lei,S.Li,Y.Wu,H.Hu,Y.Zhou,X.Zheng,G.Ding,S.Du,Z.Wu,andY.Gao. YOLOv13:Real-timeobjectdetectionwithhypergraph- enhanced adaptive visual perception, 2025. arXiv preprint
2025
-
[8]
S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Processing Systems, 2015
2015
-
[9]
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg. SSD: Single shot multibox detector. InEuropean Conference on Computer Vision, pages 21–37, 2016
2016
-
[10]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision, pages 213–229, 2020
2020
-
[11]
J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. InProceedings of the IEEE International Conference on Computer Vision, pages 764–773, 2017
2017
-
[12]
Gu and T
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2023. arXiv preprint
2023
-
[13]
Hypergraphneuralnetworks
Y.Feng,H.You,Z.Zhang,R.Ji,andY.Gao. Hypergraphneuralnetworks. InProceedingsoftheAAAIConferenceonArtificialIntelligence, volume 33, pages 3558–3565, 2019
2019
-
[14]
StudentclassroombehaviordetectionbasedonYOLOv7-BRAandmulti-modelfusion,2023
F.Yang,T.Wang,andX.Wang. StudentclassroombehaviordetectionbasedonYOLOv7-BRAandmulti-modelfusion,2023. arXivpreprint
2023
-
[15]
S. Shao, Z. Zhao, B. Li, T. Xiao, G. Yu, X. Zhang, and J. Sun. CrowdHuman: A benchmark for detecting human in a crowd, 2018. arXiv preprint
2018
-
[16]
Zhang, R
S. Zhang, R. Benenson, and B. Schiele. CityPersons: A diverse dataset for pedestrian detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3213–3221, 2017
2017
-
[17]
Zhang, Y
S. Zhang, Y. Xie, J. Wan, H. Xia, S. Z. Li, and G. Guo. WiderPerson: A diverse dataset for dense pedestrian detection in the wild.IEEE Transactions on Multimedia, 22(2):380–393, 2020
2020
-
[18]
V. A. Sindagi, R. Yasarla, and V. M. Patel. JHU-CROWD++: Large-scale crowd counting dataset and a benchmark method, 2020. arXiv preprint
2020
-
[19]
Bodla, B
N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Soft-NMS: Improving object detection with one line of code. InProceedings of the IEEE International Conference on Computer Vision, pages 5561–5569, 2017
2017
-
[20]
S. Liu, D. Huang, and Y. Wang. Adaptive NMS: Refining pedestrian detection in a crowd. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6459–6468, 2019. Xu et al.:Preprint submitted to ElsevierPage 31 of 32 Smart Classroom Behavior Analysis with HCCB
2019
-
[21]
X. Wang, T. Xiao, Y. Jiang, S. Shao, J. Sun, and C. Shen. Repulsion loss: Detecting pedestrians in a crowd. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7774–7783, 2018
2018
-
[22]
X. Chu, A. Zheng, X. Zhang, and J. Sun. Detection in crowded scenes: One proposal, multiple predictions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12214–12223, 2020
2020
-
[23]
S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8759–8768, 2018
2018
-
[24]
EfficientDet:Scalableandefficientobjectdetection
M.Tan,R.Pang,andQ.V.Le. EfficientDet:Scalableandefficientobjectdetection. InProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition, pages 10781–10790, 2020
2020
-
[25]
CascadeR-CNN:Delvingintohighqualityobjectdetection
Z.CaiandN.Vasconcelos. CascadeR-CNN:Delvingintohighqualityobjectdetection. InProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition, pages 6154–6162, 2018
2018
-
[26]
Zhang, C
S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9759–9768, 2020
2020
-
[27]
Z. Ge, S. Liu, Z. Li, O. Yoshie, and J. Sun. OTA: Optimal transport assignment for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 303–312, 2021
2021
-
[28]
Generalizedfocalloss:Learningqualifiedanddistributedboundingboxes for dense object detection
X.Li,W.Wang,L.Wu,S.Chen,X.Hu,J.Li,J.Tang,andJ.Yang. Generalizedfocalloss:Learningqualifiedanddistributedboundingboxes for dense object detection. InAdvances in Neural Information Processing Systems, volume 33, pages 21002–21012, 2020
2020
-
[29]
X.Zhu,W.Su,L.Lu,B.Li,X.Wang,andJ.Dai.DeformableDETR:Deformabletransformersforend-to-endobjectdetection.InInternational Conference on Learning Representations, 2021
2021
-
[30]
Pyramidvisiontransformer:Aversatilebackbonefordense prediction without convolutions
W.Wang,E.Xie,X.Li,D.P.Fan,K.Song,D.Liang,T.Lu,P.Luo,andL.Shao. Pyramidvisiontransformer:Aversatilebackbonefordense prediction without convolutions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 568–578, 2021
2021
-
[31]
Swintransformer:Hierarchicalvisiontransformerusingshiftedwindows
Z.Liu,Y.Lin,Y.Cao,H.Hu,Y.Wei,Z.Zhang,S.Lin,andB.Guo. Swintransformer:Hierarchicalvisiontransformerusingshiftedwindows. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[32]
X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7794–7803, 2018
2018
-
[33]
Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, J. Jiao, and Y. Liu. VMamba: Visual state space model. InAdvances in Neural Information Processing Systems, 2024
2024
-
[34]
H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei. Relation networks for object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3588–3597, 2018
2018
-
[35]
T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, 2017
2017
-
[36]
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. MobileNets: Efficient convolutional neural networks for mobile vision applications, 2017. arXiv preprint
2017
-
[37]
Jocher, A
G. Jocher, A. Chaurasia, and J. Qiu. Ultralytics YOLO, 2023. Ultralytics
2023
-
[38]
B. Sun, Y. Wu, K. Zhao, et al. Student class behavior dataset: A video dataset for recognizing, detecting, and captioning students’ behaviors in classroom scenes.Neural Computing and Applications, 33:8335–8354, 2021
2021
-
[39]
J.ZhaoandH.Zhu.CBPH-Net:Asmallobjectdetectorforbehaviorrecognitioninclassroomscenarios.IEEETransactionsonInstrumentation and Measurement, 2023
2023
-
[40]
MicrosoftCOCO:Commonobjectsincontext
T.Y.Lin,M.Maire,S.Belongie,J.Hays,P.Perona,D.Ramanan,P.Doll’ar,andC.L.Zitnick. MicrosoftCOCO:Commonobjectsincontext. InEuropean Conference on Computer Vision, pages 740–755, 2014
2014
-
[41]
C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, et al. YOLOv6: A single-stage object detection framework for industrial applications, 2022. arXiv preprint
2022
-
[42]
Terven and D
J. Terven and D. Cordova-Esparza. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS.Machine Learning and Knowledge Extraction, 5(4):1680–1716, 2023
2023
-
[43]
YOLOv9:Learningwhatyouwanttolearnusingprogrammablegradientinformation
C.Y.Wang,I.H.Yeh,andH.Y.M.Liao. YOLOv9:Learningwhatyouwanttolearnusingprogrammablegradientinformation. InEuropean Conference on Computer Vision, 2024
2024
-
[44]
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, and G. Ding. YOLOv10: Real-time end-to-end object detection. InAdvances in Neural Information Processing Systems, 2024
2024
-
[45]
Khanam and M
R. Khanam and M. Hussain. YOLOv11: An overview of the key architectural enhancements, 2024. arXiv preprint
2024
-
[46]
Y. Tian, Q. Ye, and D. Doermann. YOLOv12: Attention-centric real-time object detectors, 2025. arXiv preprint
2025
-
[47]
Ultralytics yolo26: Unified real-time end-to-end vision models.arXiv preprint arXiv:2606.03748, 2026
Glenn Jocher, Jing Qiu, Mengyu Liu, Shuai Lyu, Fatih Cagatay Akyon, and Muhammet Esat Kalfaoglu. Ultralytics yolo26: Unified real-time end-to-end vision models.arXiv preprint arXiv:2606.03748, 2026. Xu et al.:Preprint submitted to ElsevierPage 32 of 32
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.