Motion-Aware Reinforcement Learning For Object Localization
Pith reviewed 2026-06-26 14:08 UTC · model grok-4.3
The pith
A constant-velocity motion prior added to a PPO bounding-box refinement agent raises IoU success by up to 1.1 points on VOC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
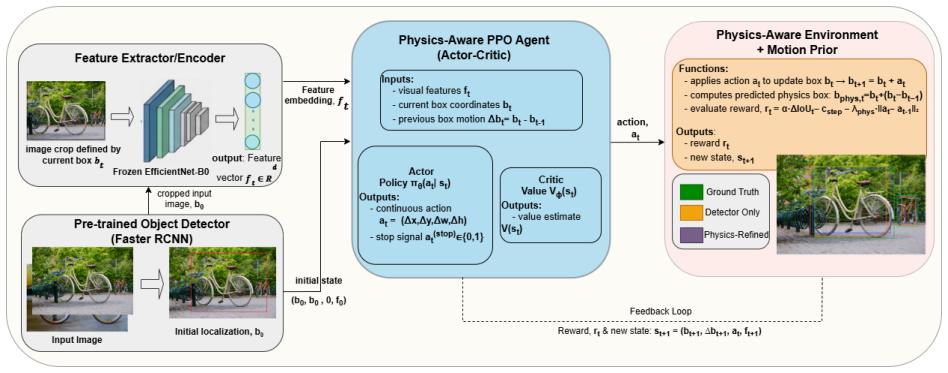
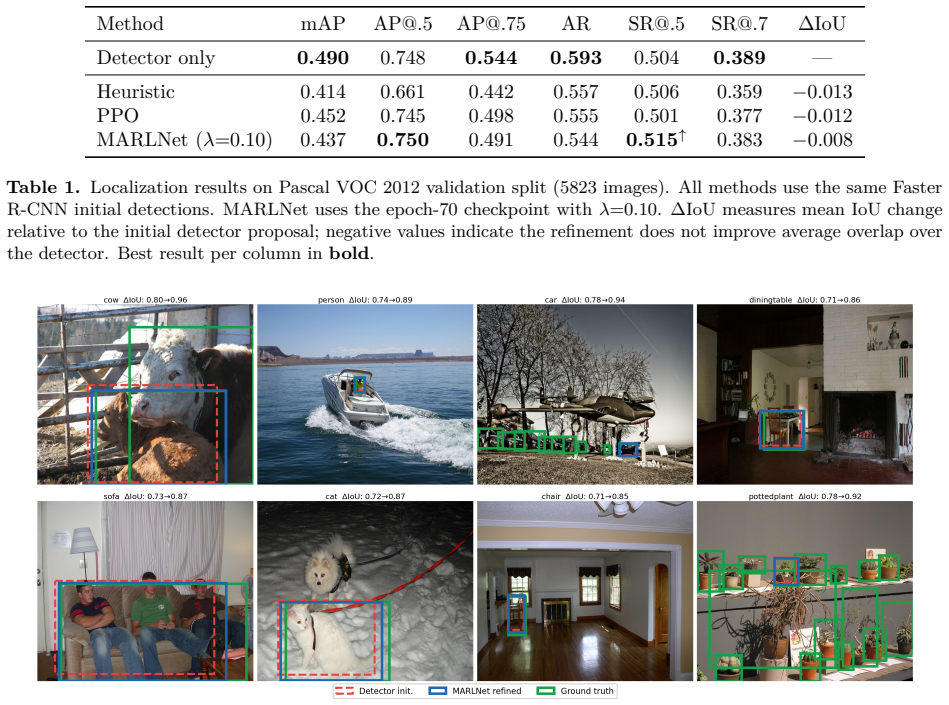
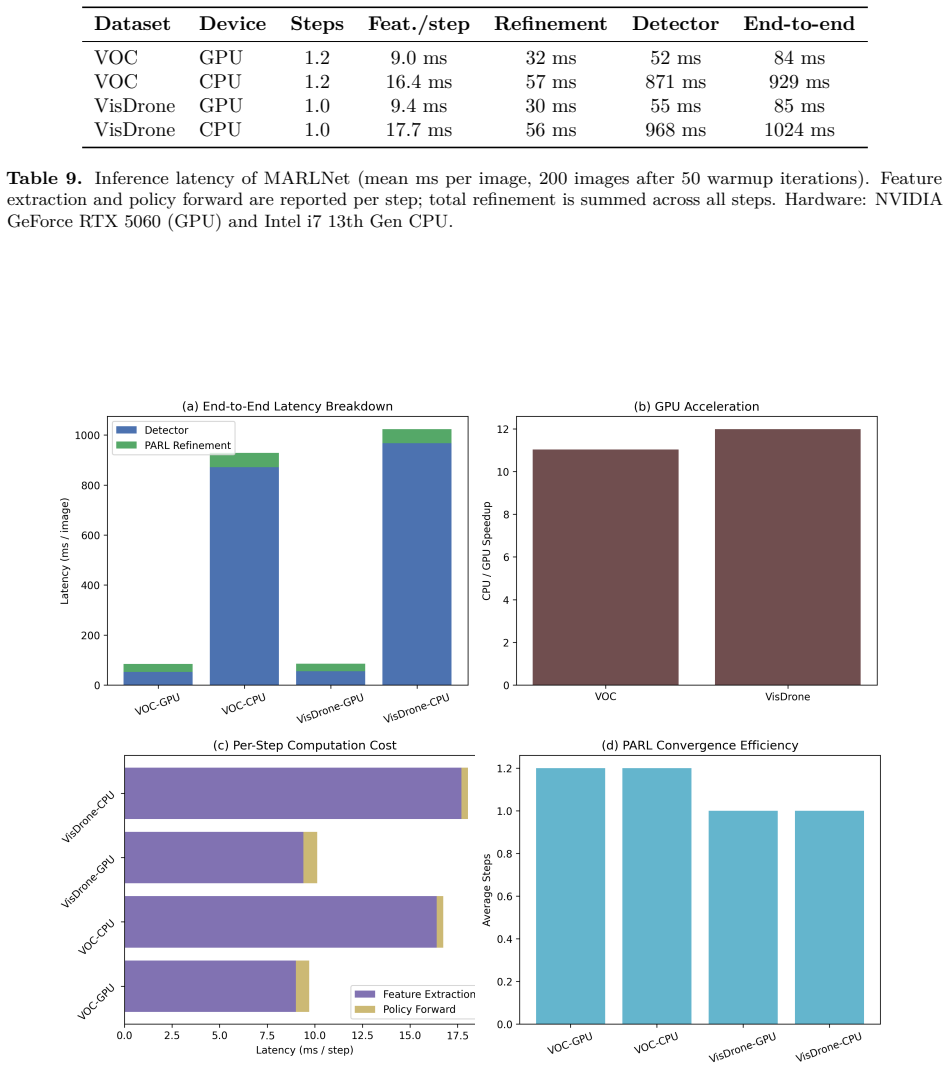
MARLNet is a PPO-based bounding-box refinement agent that incorporates a constant-velocity motion prior into the 268-dimensional observation state and an action smoothness penalty into the reward function. The agent learns a five-dimensional policy controlling coordinate adjustments and a binary termination trigger. On Pascal VOC 2012 it reaches detection success gains of up to +0.011 at IoU ≥ 0.5 when the physical regularization weight is 0.10; on VisDrone 2019 the gain is +0.007 at weight 0.70. The motion prior is credited with preventing the overshooting that causes plain PPO to regress on the success metric, while reward ablations confirm that the smoothness term avoids trigger collapse.
What carries the argument
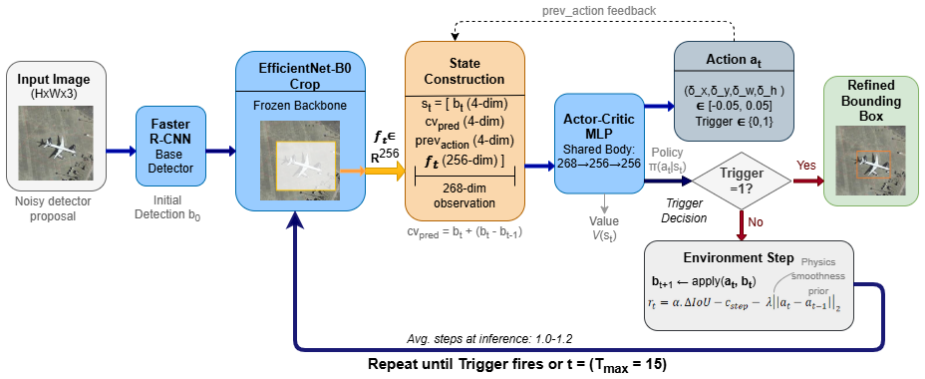
The 268-dimensional observation that concatenates the current proposal, a constant-velocity kinematic prediction computed from the previous action, the previous action itself, and a 256-dimensional EfficientNet-B0 crop feature, together with the action smoothness penalty in the reward.
If this is right
- The motion prior prevents overshooting during refinement and thereby raises IoU ≥ 0.5 success rates relative to unconstrained PPO on VOC.
- On VisDrone the weaker base detector allows larger absolute gains for plain PPO, yet MARLNet still records a positive though smaller improvement.
- Pairing a constant-velocity deviation penalty with an absolute IoU reward term produces trigger collapse; the action smoothness penalty eliminates this interference.
- Crop-feature refinement agents that share a backbone with their base detector encounter a representational ceiling, as shown by the global-plus-local observation ablation.
Where Pith is reading between the lines
- The same observation construction could be applied to video sequences where frame-to-frame motion is stronger and the constant-velocity assumption is more often valid.
- Replacing the kinematic predictor with a learned motion model that handles acceleration would test whether the reported gains are tied specifically to the constant-velocity choice.
- The reward-interference finding may generalize to other RL localization tasks that combine geometric and appearance-based reward terms.
Load-bearing premise
The constant-velocity kinematic prediction computed from the previous action remains a useful signal even when the base detector's initial proposals are noisy or when object motion deviates from constant velocity.
What would settle it
Running the identical MARLNet agent on a test set of objects whose motion is strongly non-constant (for example, rapidly accelerating vehicles filmed at high frame rate) and measuring whether the reported gains over plain PPO disappear.
Figures

read the original abstract
We present MARLNet (Motion-Aware Reinforcement Learning Network), a PPO-based bounding-box refinement agent that incorporates a constant-velocity motion prior into the observation state and an action smoothness penalty into the reward function. The agent operates on 268-dimensional observations encoding the current proposal, a kinematic prediction, the previous action, and a 256-dimensional EfficientNet-B0 crop feature, and learns a five-dimensional policy controlling coordinate adjustments and a binary termination trigger. Evaluated on Pascal VOC 2012 and VisDrone 2019, MARLNet trains stably across all regularization strengths tested and achieves consistent gains in detection success rate at $\text{IoU} \geq 0.5$: up to $+0.011$ on VOC ($\lambda_\text{phys}{=}0.10$), where the motion prior prevents the overshooting that causes plain PPO to regress on this metric, and $+0.007$ on VisDrone ($\lambda_\text{phys}{=}0.70$), where unconstrained PPO achieves a larger gain ($+0.025$) owing to the weaker base detector. Through reward design ablations and training dynamics analysis, we identify a reward interference in which combining a constant-velocity deviation penalty with an absolute IoU term causes trigger collapse, and show that replacing it with the action smoothness penalty resolves this failure. We further characterize a representational ceiling facing crop-feature refinement agents that share a backbone with their base detector, confirmed through a global-plus-local observation ablation. Project page: https://prithviraj97.github.io/marl-net
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MARLNet, a PPO-based bounding-box refinement agent for object detection that augments the 268-dimensional observation state with a constant-velocity kinematic prediction derived from the prior action and incorporates an action smoothness penalty in the reward. It reports empirical gains in IoU≥0.5 success rate of up to +0.011 on Pascal VOC 2012 (at λ_phys=0.10) and +0.007 on VisDrone 2019 (at λ_phys=0.70), attributes the VOC improvement to the motion prior preventing overshooting seen in plain PPO, identifies a reward-interference failure mode (trigger collapse) via ablations on constant-velocity deviation penalties versus smoothness penalties, and notes a representational ceiling for agents sharing a backbone with the base detector.
Significance. If the reported gains prove robust, the work offers a concrete demonstration that kinematic priors in the observation and targeted reward penalties can stabilize RL refinement agents and avoid specific failure modes such as overshooting or trigger collapse; the reward-design ablations and training-dynamics analysis constitute a useful contribution to RL-for-vision practice. The project page further supports reproducibility. The modest effect sizes and the fact that unconstrained PPO outperforms on VisDrone nevertheless limit the broader significance.
major comments (2)
- [Observation construction and evaluation on VOC/VisDrone] The central claim that the motion prior prevents overshooting (and thereby produces the +0.011 VOC gain) rests on the constant-velocity kinematic prediction remaining informative. No experiment tests this channel when initial proposals are noisy or when object trajectories deviate from constant velocity, which directly affects attribution of the reported numeric lifts.
- [Quantitative results and ablations] The headline numeric results (+0.011 on VOC, +0.007 on VisDrone) are presented as point estimates with no error bars, no standard deviations across random seeds, and no statistical significance tests. This is load-bearing for the claim of “consistent gains” and “stable training across all regularization strengths.”
minor comments (2)
- [Method] The 268-dimensional observation breakdown (current proposal, kinematic prediction, previous action, 256-dim EfficientNet crop) would benefit from an explicit per-component dimension table for immediate clarity.
- [Abstract] The abstract states that unconstrained PPO achieves a larger gain (+0.025) on VisDrone; a brief discussion of why the motion prior is still presented as beneficial in that regime would help readers interpret the cross-dataset pattern.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that the motion prior prevents overshooting (and thereby produces the +0.011 VOC gain) rests on the constant-velocity kinematic prediction remaining informative. No experiment tests this channel when initial proposals are noisy or when object trajectories deviate from constant velocity, which directly affects attribution of the reported numeric lifts.
Authors: The reported results are obtained on Pascal VOC 2012 and VisDrone 2019 using proposals from a base detector, which inherently include noise, and real object trajectories that are not strictly constant-velocity. Attribution of the VOC gain to the motion prior is supported by the training dynamics analysis showing that plain PPO overshoots while the augmented agent does not. We nevertheless agree that the claim would be strengthened by explicit tests of the kinematic channel under controlled noise levels or non-constant-velocity conditions. In the revised manuscript we will add an ablation that perturbs initial proposal noise and trajectory assumptions to directly evaluate when the constant-velocity prediction remains informative. revision: yes
-
Referee: The headline numeric results (+0.011 on VOC, +0.007 on VisDrone) are presented as point estimates with no error bars, no standard deviations across random seeds, and no statistical significance tests. This is load-bearing for the claim of “consistent gains” and “stable training across all regularization strengths.”
Authors: We acknowledge that the headline numbers are reported as single-run point estimates. While the training-dynamics figures demonstrate stability across regularization strengths, the absence of variability measures and significance tests weakens the support for claims of consistent gains. In the revision we will rerun the key experiments with multiple random seeds, report means and standard deviations, and include statistical significance tests for the reported improvements. revision: yes
Circularity Check
No circularity: empirical RL results on fixed datasets
full rationale
The paper describes a PPO-based agent whose 268-dim observation includes a constant-velocity kinematic extrapolation and whose reward includes an action-smoothness term. All reported metrics (+0.011 IoU gain on VOC, +0.007 on VisDrone) are measured outcomes of training runs on standard dataset splits; none are quantities defined in terms of λ_phys or obtained by algebraic rearrangement of the observation vector. No self-citation chain, uniqueness theorem, or fitted-parameter-renamed-as-prediction appears in the derivation. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- λ_phys =
0.10 / 0.70
axioms (2)
- domain assumption PPO policy-gradient updates converge to a useful policy when the observation includes a constant-velocity forecast derived from the previous action.
- domain assumption The EfficientNet-B0 crop feature extracted from the current proposal remains informative even when the backbone is shared with the base detector.
Reference graph
Works this paper leans on
-
[1]
Beyond kalman filters: deep learning-based filters for improved object tracking
Momir Adžemović, Predrag Tadić, Andrija Petrović, and Mladen Nikolić. Beyond kalman filters: deep learning-based filters for improved object tracking. Machine Vision and Applications, 36(1):20, 2025. 3
2025
-
[2]
Simple online and re- altime tracking
Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and re- altime tracking. In2016 IEEE international confer- ence on image processing (ICIP), pages 3464–3468. Ieee, 2016. 1, 3
2016
-
[3]
Kinematic 3d object detection in monocular video
Garrick Brazil, Gerard Pons-Moll, Xiaoming Liu, and Bernt Schiele. Kinematic 3d object detection in monocular video. InEuropean Conference on Computer Vision, pages 135–152. Springer, 2020. 3
2020
-
[4]
Active object localization with deep reinforcement learning
Juan C Caicedo and Svetlana Lazebnik. Active object localization with deep reinforcement learning. InProceedings of the IEEE international conference on computer vision, pages 2488–2496, 2015. 1, 3
2015
-
[5]
Visible and clear: Finding tiny objects in difference map
Bing Cao, Haiyu Yao, Pengfei Zhu, and Qinghua Hu. Visible and clear: Finding tiny objects in difference map. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024. 8
2024
-
[6]
Enhancing your trained detrs with box refinement.arXiv preprint arXiv:2307.11828, 2023
Yiqun Chen, Qiang Chen, Peize Sun, Shoufa Chen, Jingdong Wang, and Jian Cheng. Enhancing your trained detrs with box refinement.arXiv preprint arXiv:2307.11828, 2023. 1, 2
arXiv 2023
-
[7]
Iterative multiple bounding-box refine- ments for visual tracking.Journal of Imaging, 8(3): 61, 2022
Giorgio Cruciata, Liliana Lo Presti, and Marco La Cascia. Iterative multiple bounding-box refine- ments for visual tracking.Journal of Imaging, 8(3): 61, 2022. 2
2022
-
[8]
Visdrone-det2019: The vision meets drone object detection in image challenge results
Dawei Du, Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Lin, Qinghua Hu, Tao Peng, Jiayu Zheng, Xinyao Wang, Yue Zhang, et al. Visdrone-det2019: The vision meets drone object detection in image challenge results. InProceedings of the IEEE/CVF 14 international conference on computer vision work- shops, pages 0–0, 2019. 8
2019
-
[9]
Frederik Ebert, Chelsea Finn, Sudeep Dasari, et al. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018. 3
Pith/arXiv arXiv 2018
-
[10]
The pascal visual object classes (voc) challenge.Inter- national journal of computer vision, 88(2):303–338,
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.Inter- national journal of computer vision, 88(2):303–338,
-
[11]
Pm- track: multi-object tracking with motion-aware
Xu Guo, Yujin Zheng, and Dingwen Wang. Pm- track: multi-object tracking with motion-aware. In Proceedings of the Asian Conference on Computer Vision, pages 3091–3106, 2024. 1, 3
2024
-
[12]
Deep residual learning for image recog- nition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016. 5
2016
-
[13]
Bbre- finement: A universal scheme to improve the preci- sion of box object detectors.Applied Sciences, 12 (7):3402, 2022
Petr Hurtik, Marek Vajgl, and David Hynar. Bbre- finement: A universal scheme to improve the preci- sion of box object detectors.Applied Sciences, 12 (7):3402, 2022. 1, 2
2022
-
[14]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 7, 1
Pith/arXiv arXiv 2014
-
[15]
Multi-stage reinforcement learning for object detection
Jonas König, Simon Malberg, Martin Martens, Se- bastian Niehaus, Artus Krohn-Grimberghe, and Arunselvan Ramaswamy. Multi-stage reinforcement learning for object detection. InScience and Infor- mation Conference, pages 178–191. Springer, 2019. 3
2019
-
[16]
Gradient-based regulariza- tion for action smoothness in robotic control with reinforcement learning
I Lee, Hoang-Giang Cao, Cong-Tinh Dao, Yu-Cheng Chen, and I-Chen Wu. Gradient-based regulariza- tion for action smoothness in robotic control with reinforcement learning. In2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 603–610. IEEE, 2024. 3
2024
-
[17]
Microsoft coco: Com- mon objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Com- mon objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 8
2014
-
[18]
Kurl: A knowledge-guided reinforce- ment learning model for active object tracking
Xin Liu, Jie Tan, Xiaoguang Ren, Weiya Ren, and Huadong Dai. Kurl: A knowledge-guided reinforce- ment learning model for active object tracking. In Asian conference on machine learning, pages 818–
- [19]
-
[20]
Reinforcement learning for visual object detection
Stefan Mathe, Aleksis Pirinen, and Cristian Smin- chisescu. Reinforcement learning for visual object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2894–2902, 2016. 3
2016
-
[21]
Regularizing action policies for smooth control with reinforcement learning
Siddharth Mysore, Bassel Mabsout, Renato Man- cuso, and Kate Saenko. Regularizing action policies for smooth control with reinforcement learning. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1810–1816. IEEE,
2021
-
[22]
Visual object tracking in drone im- ages with deep reinforcement learning
Sedat Ozer et al. Visual object tracking in drone im- ages with deep reinforcement learning. In2020 25th International Conference on Pattern Recognition (ICPR), pages 10082–10089. IEEE, 2021. 3
2021
-
[23]
Deep reinforcement learning of region proposal networks for object detection
Aleksis Pirinen and Cristian Sminchisescu. Deep reinforcement learning of region proposal networks for object detection. Inproceedings of the IEEE con- ference on computer vision and pattern recognition, pages 6945–6954, 2018. 3
2018
-
[24]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015. 2, 5, 7
2015
-
[25]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using general- ized advantage estimation.arXiv preprint arXiv:1506.02438, 2015. 7
Pith/arXiv arXiv 2015
-
[26]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhari- wal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 1, 5, 7
Pith/arXiv arXiv 2017
-
[27]
Efficientnet: Rethink- ing model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethink- ing model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR, 2019. 2, 4, 5
2019
-
[28]
Motiontrack: Learning motion predictor for multi- ple object tracking.Neural Networks, 179:106539,
Changcheng Xiao, Qiong Cao, Yujie Zhong, Long Lan, Xiang Zhang, Zhigang Luo, and Dacheng Tao. Motiontrack: Learning motion predictor for multi- ple object tracking.Neural Networks, 179:106539,
-
[29]
Alpha-refine: Boosting track- ing performance by precise bounding box estima- tion
Bin Yan, Xinyu Zhang, Dong Wang, Huchuan Lu, and Xiaoyun Yang. Alpha-refine: Boosting track- ing performance by precise bounding box estima- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5289–5298, 2021. 1, 2
2021
-
[30]
Lpae-yolov8: lightweight aerial small object detection via lse-head and adaptive attention.Scientific Reports, 15(1): 44780, 2025
Yi Zhao and Guiping Chen. Lpae-yolov8: lightweight aerial small object detection via lse-head and adaptive attention.Scientific Reports, 15(1): 44780, 2025. 8
2025
-
[31]
Rein- forcenet: A reinforcement learning embedded object detection framework with region selection network
Man Zhou, Rujing Wang, Chengjun Xie, Liu Liu, Rui Li, Fangyuan Wang, and Dengshan Li. Rein- forcenet: A reinforcement learning embedded object detection framework with region selection network. Neurocomputing, 443:369–379, 2021. 1, 3
2021
-
[32]
Detection and tracking meet drones challenge.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 44(11):7380–7399, 2021
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Heng Fan, Qinghua Hu, and Haibin Ling. Detection and tracking meet drones challenge.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 44(11):7380–7399, 2021. 2, 7 15 Motion-Aware Reinforcement Learning For Object Localization Supplementary Material
2021
-
[33]
The shared MLP backbone comprises two fully con- nected layers of dimension 256 with ReLU activa- tions
Implementation Details Network architecture and feature extraction. The shared MLP backbone comprises two fully con- nected layers of dimension 256 with ReLU activa- tions. The actor head outputs a 4-dimensional mean vectorµt, a globally learnable log-standard-deviation logσ∈R4, and a scalar stopping logit; the critic head outputs a scalar value estimate ...
-
[34]
More Results on VOC & VisDrone Tables 7 and 8 report per-category AP@0.5 for all methods on VOC and VisDrone respectively, com- plementing the aggregate metrics in the main paper
-
[35]
Mathematical Formulation of the Learnable Motion Model While the fixed constant–velocity assumption pro- vides a simple and effective motion prior, it cannot capture complex object dynamics or camera motion. To address this limitation, we extend the frame- work by introducing alearnable motion modulethat predicts the next bounding box in a data-driven man...
arXiv 2011
-
[36]
The method requires no training and no ground-truth supervision at inference time
Heuristic Refinement Policy We describe the greedy detector-rescore heuristic used as a non-learned baseline throughout the ex- periments. The method requires no training and no ground-truth supervision at inference time. It shares the same base detector as MARLNet, ensuring a fair comparison: both methods operate from identical initial proposals and use ...
-
[37]
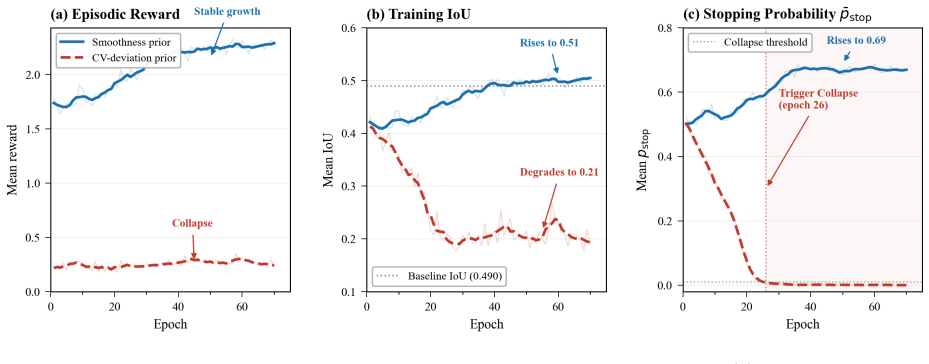
Discussion on Results of Experi- ment 13.1. Reward Design Analysis The CV-penalty reward causes catastrophic failure.When the motion penalty is defined as deviation from the constant-velocity prediction – λphys∥bt+1−ˆbcv t+1∥2 – training collapses by epoch
-
[38]
Figure 5(b) shows mean training IoU degrading from 0.42 to 0.21, confirming complete localization failure
The mean stopping probability¯pstop falls below 0.01 and never recovers, reducing the model to ran- dom per-step jitter over allTmax steps. Figure 5(b) shows mean training IoU degrading from 0.42 to 0.21, confirming complete localization failure. Algorithm 2Greedy Heuristic Refinement Input:Image I; initial detection(b0,s 0); detector D; max stepsT=8; sca...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.