TALAS: Teacher-Anchored Layer Alignment with Adaptive Sharpness-Aware Minimization for Embedding Distillation
Pith reviewed 2026-06-26 12:15 UTC · model grok-4.3
The pith
TALAS selectively distills teacher sentence embeddings into student upper layers while using top-down geometric constraints and sharpness-aware minimization to improve distillation efficiency and performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
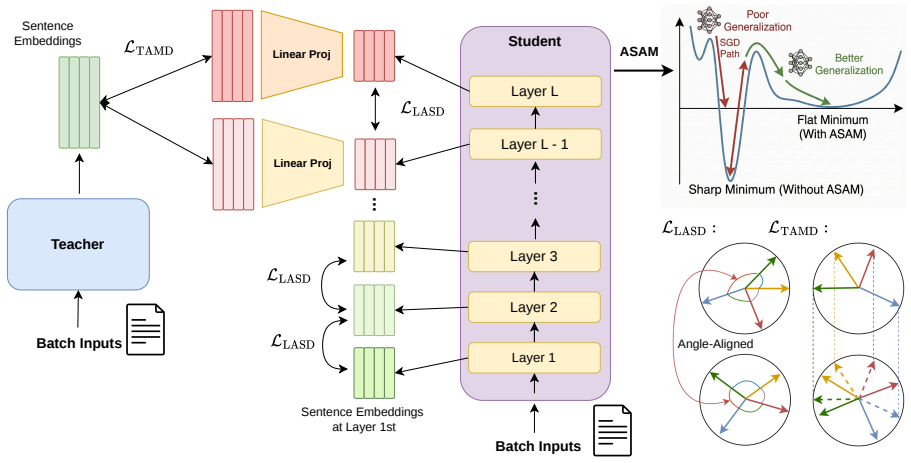
TALAS is a unified framework that synergizes hierarchical layer alignment with robust optimization: the Teacher-Anchored mechanism distills final sentence embeddings only into the student's upper layers, Layer-Aligned Self-Distillation propagates knowledge top-down using internal geometric relational constraints in the embedding space, and Adaptive Sharpness-Aware Minimization guides the model towards flat minima to enhance generalization, leading to consistent outperformance of baselines with superior training efficiency.
What carries the argument
Teacher-Anchored Layer Alignment mechanism that selectively distills final sentence embeddings into the student's upper layers, combined with top-down Layer-Aligned Self-Distillation using geometric relational constraints and Adaptive Sharpness-Aware Minimization.
If this is right
- The approach reduces prohibitive computational costs associated with full-layer feature mimicry.
- It respects capacity constraints by avoiding forcing lower layers to match teacher features directly.
- It achieves superior performance on standard sentence embedding benchmarks.
- It improves training efficiency in terms of computational cost and memory footprint.
- The integration of ASAM prevents memorizing point-wise teacher noise.
Where Pith is reading between the lines
- This selective distillation could extend to distilling other types of representations beyond sentence embeddings.
- The top-down relational constraints might help in scenarios with even larger capacity gaps between models.
- Combining TALAS with other compression techniques like pruning could yield further efficiency gains.
Load-bearing premise
Selectively distilling final sentence embeddings only into the student's upper layers combined with top-down relational constraints is sufficient to bridge the capacity gap without losing critical semantic information.
What would settle it
Demonstrating that a full-layer mimicry approach achieves substantially better results on sentence embedding benchmarks than TALAS would indicate the selective method loses important information.
Figures
read the original abstract
Knowledge Distillation (KD) has established itself as a pivotal technique for compressing large pre-trained language models. However, existing methods that force a student to strictly mimic the teacher's sentence embeddings or internal features often incur prohibitive computational costs and yield suboptimal performance due to the inherent capacity gap. To address these challenges, we propose TALAS (Teacher-Anchored Layer Alignment with Sharpness-aware minimization), a unified framework that synergizes hierarchical (multi-layer) alignment with robust optimization. First, we introduce a Teacher-Anchored mechanism that selectively distills final sentence embeddings only into the student's upper layers, thereby reducing overhead while respecting capacity constraints. Second, we bridge the semantic gap in lower layers via Layer-Aligned Self-Distillation, which propagates knowledge top-down using internal geometric relational constraints in the embedding space. Finally, to prevent the student from memorizing point-wise teacher noise, we integrate Adaptive Sharpness-Aware Minimization (ASAM) into the training objective, guiding the model towards flat minima for enhanced generalization. Empirical results on standard sentence embedding benchmarks demonstrate that TALAS consistently outperforms strong distillation baselines while achieving superior training efficiency in terms of computational cost and memory footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TALAS, a knowledge distillation framework for sentence embeddings in pre-trained language models. It combines a Teacher-Anchored mechanism that selectively distills final sentence embeddings only into the student's upper layers, Layer-Aligned Self-Distillation that propagates knowledge top-down via internal geometric relational constraints, and integration of Adaptive Sharpness-Aware Minimization (ASAM) into the training objective to reach flat minima and avoid memorizing teacher noise. The central claim is that this yields consistent outperformance over strong distillation baselines on standard sentence embedding benchmarks along with gains in computational cost and memory efficiency.
Significance. If the empirical claims are substantiated, the selective upper-layer approach combined with relational constraints and ASAM could provide a practical way to mitigate the capacity gap in distillation while improving generalization and efficiency, which would be relevant for compressing large PLMs for embedding tasks.
major comments (2)
- Abstract: the central empirical claim that TALAS 'consistently outperforms strong distillation baselines' and achieves 'superior training efficiency' is asserted without any quantitative results, specific benchmark names, baseline details, ablation studies, or error bars. This is load-bearing for the paper's contribution and prevents verification of the claimed gains.
- Abstract: the weakest assumption—that selectively distilling only into upper layers plus top-down relational constraints suffices to bridge the capacity gap without loss of critical semantic information—is presented as resolved by the method but is not accompanied by any supporting analysis or comparison to full-layer mimicry.
minor comments (2)
- Abstract: the description of ASAM is introduced as 'Adaptive Sharpness-Aware Minimization (ASAM)' but the title uses 'Adaptive Sharpness-Aware Minimization'; consistent acronym usage would improve clarity.
- Abstract: 'standard sentence embedding benchmarks' is referenced without naming the datasets (e.g., STS, SentEval), which would help situate the claimed results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and propose revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: the central empirical claim that TALAS 'consistently outperforms strong distillation baselines' and achieves 'superior training efficiency' is asserted without any quantitative results, specific benchmark names, baseline details, ablation studies, or error bars. This is load-bearing for the paper's contribution and prevents verification of the claimed gains.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the claims. The full manuscript reports detailed results on standard benchmarks including STS12-STS16, STS-B, and others, with comparisons to multiple distillation baselines, ablation studies, and error bars from repeated runs. We will revise the abstract to incorporate key quantitative highlights (e.g., average performance gains and efficiency metrics) while preserving brevity. revision: yes
-
Referee: Abstract: the weakest assumption—that selectively distilling only into upper layers plus top-down relational constraints suffices to bridge the capacity gap without loss of critical semantic information—is presented as resolved by the method but is not accompanied by any supporting analysis or comparison to full-layer mimicry.
Authors: The manuscript contains layer-wise ablation studies and direct comparisons to full-layer mimicry baselines in the experimental section, which empirically support that selective upper-layer alignment preserves semantic information without degradation. We acknowledge the abstract does not reference this analysis. We will update the abstract to briefly note the supporting empirical evidence from the layer alignment ablations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a new distillation framework (TALAS) via procedural architectural choices—selective upper-layer embedding distillation, top-down relational constraints, and ASAM integration—without presenting equations, derivations, or formal proofs. Performance claims rest on empirical benchmark results rather than any reduction of outputs to fitted inputs or self-referential quantities. No self-citations, uniqueness theorems, or ansatzes appear in a load-bearing role within the abstract or method outline. The derivation chain is therefore self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A capacity gap exists between teacher and student models such that full-layer mimicry is suboptimal.
- domain assumption Internal geometric relational constraints in the embedding space can propagate semantic knowledge top-down from upper to lower layers.
Reference graph
Works this paper leans on
-
[1]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[2]
2020 , eprint=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. 2020 , eprint=
2020
-
[3]
Xiaoqi Jiao and Yichun Yin and Lifeng Shang and Xin Jiang and Xiao Chen and Linlin Li and Fang Wang and Qun Liu , title =. CoRR , volume =. 2019 , url =. 1909.10351 , timestamp =
arXiv 2019
-
[4]
2023 , eprint=
MTEB: Massive Text Embedding Benchmark , author=. 2023 , eprint=
2023
-
[5]
2025 , eprint=
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models , author=. 2025 , eprint=
2025
-
[6]
2024 , eprint=
C-Pack: Packed Resources For General Chinese Embeddings , author=. 2024 , eprint=
2024
-
[7]
2019 , eprint=
Patient Knowledge Distillation for BERT Model Compression , author=. 2019 , eprint=
2019
-
[8]
2024 , eprint=
MiniLLM: Knowledge Distillation of Large Language Models , author=. 2024 , eprint=
2024
-
[9]
2025 , eprint=
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs , author=. 2025 , eprint=
2025
-
[10]
2024 , eprint=
Knowledge Fusion of Large Language Models , author=. 2024 , eprint=
2024
-
[11]
2024 , eprint=
Dual-Space Knowledge Distillation for Large Language Models , author=. 2024 , eprint=
2024
-
[12]
2020 , eprint=
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , author=. 2020 , eprint=
2020
-
[13]
2025 , eprint=
A Survey of Large Language Models , author=. 2025 , eprint=
2025
-
[14]
2020 , eprint=
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices , author=. 2020 , eprint=
2020
-
[15]
2023 , eprint=
DistilCSE: Effective Knowledge Distillation For Contrastive Sentence Embeddings , author=. 2023 , eprint=
2023
-
[16]
2016 , eprint=
Sequence-Level Knowledge Distillation , author=. 2016 , eprint=
2016
-
[17]
2023 , eprint=
Specializing Smaller Language Models towards Multi-Step Reasoning , author=. 2023 , eprint=
2023
-
[18]
2023 , eprint=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. 2023 , eprint=
2023
-
[19]
2019 , eprint=
Similarity of Neural Network Representations Revisited , author=. 2019 , eprint=
2019
-
[20]
2024 , eprint=
KDMCSE: Knowledge Distillation Multimodal Sentence Embeddings with Adaptive Angular margin Contrastive Learning , author=. 2024 , eprint=
2024
-
[21]
2025 , eprint=
CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers , author=. 2025 , eprint=
2025
-
[22]
and Szedmak, Sandor and Shawe-Taylor, John , journal=
Hardoon, David R. and Szedmak, Sandor and Shawe-Taylor, John , journal=. Canonical Correlation Analysis: An Overview with Application to Learning Methods , year=
-
[23]
2023 , eprint=
Feature Structure Distillation with Centered Kernel Alignment in BERT Transferring , author=. 2023 , eprint=
2023
-
[24]
2025 , eprint=
Rho-1: Not All Tokens Are What You Need , author=. 2025 , eprint=
2025
-
[25]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Distilled Contrastive Learning for Sentence Embeddings , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =. doi:10.18653/v1/2023.findings-emnlp.547 , url =
-
[26]
Constraint-aware and Ranking-distilled Token Pruning for Efficient Transformer Inference , url=
Li, Junyan and Zhang, Li Lyna and Xu, Jiahang and Wang, Yujing and Yan, Shaoguang and Xia, Yunqing and Yang, Yuqing and Cao, Ting and Sun, Hao and Deng, Weiwei and Zhang, Qi and Yang, Mao , year=. Constraint-aware and Ranking-distilled Token Pruning for Efficient Transformer Inference , url=. doi:10.1145/3580305.3599284 , booktitle=
-
[27]
2021 , eprint=
Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth , author=. 2021 , eprint=
2021
-
[28]
33rd British Machine Vision Conference 2022,
Aninda Saha and Alina N Bialkowski and Sara Khalifa , title =. 33rd British Machine Vision Conference 2022,. 2022 , url =
2022
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Improving Language Model Distillation through Hidden State Matching , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
BIGPATENT : A Large-Scale Dataset for Abstractive and Coherent Summarization
Sharma, Eva and Li, Chen and Wang, Lu. BIGPATENT : A Large-Scale Dataset for Abstractive and Coherent Summarization. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1212
-
[31]
Tushar Khot and Ashish Sabharwal and Peter Clark , Booktitle =
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Natural Language Inference in Context - Investigating Contextual Reasoning over Long Texts , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i15.17580 , number=
-
[33]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Adversarial NLI: A New Benchmark for Natural Language Understanding , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-level optimal transport for universal cross-tokenizer knowledge distillation on language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
2024 , url=
Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy , booktitle=. 2024 , url=
2024
-
[36]
Marelli, Marco and Bentivogli, Luisa and Baroni, Marco and Bernardi, Raffaella and Menini, Stefano and Zamparelli, Roberto. S em E val-2014 Task 1: Evaluation of Compositional Distributional Semantic Models on Full Sentences through Semantic Relatedness and Textual Entailment. Proceedings of the 8th International Workshop on Semantic Evaluation ( S em E v...
-
[37]
2024 , eprint=
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author=. 2024 , eprint=
2024
-
[38]
Frontiers in Systems Neuroscience , author =
Kriegeskorte, Nikolaus and Mur, Marieke and Bandettini, Peter A. , TITLE=. Frontiers in Systems Neuroscience , VOLUME=. 2008 , URL=. doi:10.3389/neuro.06.004.2008 , ISSN=
-
[39]
2023 , url=
Less is More: Task-aware Layer-wise Distillation for Language Model Compression , author=. 2023 , url=
2023
-
[40]
arXiv preprint arXiv:2508.12519 , year=
An Introduction to Sliced Optimal Transport , author=. arXiv preprint arXiv:2508.12519 , year=
-
[41]
Improving Vietnamese-English Cross-Lingual Retrieval for Legal and General Domains , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2025
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mitigating Non-Representative Prototypes and Representation Bias in Few-Shot Continual Relation Extraction , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
Enhancing Discriminative Representation in Similar Relation Clusters for Few-Shot Continual Relation Extraction , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[44]
Mutual-pairing Data Augmentation for Fewshot Continual Relation Extraction , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[45]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
HiCOT: Improving Neural Topic Models via Optimal Transport and Contrastive Learning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[46]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Topic Modeling for Short Texts via Optimal Transport-Based Clustering , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[47]
arXiv preprint arXiv:1906.02762 , year=
Understanding and improving transformer from a multi-particle dynamic system point of view , author=. arXiv preprint arXiv:1906.02762 , year=
Pith/arXiv arXiv 1906
-
[48]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Beyond Logits: Aligning Feature Dynamics for Effective Knowledge Distillation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[49]
2009 , publisher=
Systemic functional grammar: A first step into the theory , author=. 2009 , publisher=
2009
-
[50]
2015 , publisher=
Lexical-functional syntax , author=. 2015 , publisher=
2015
-
[51]
2019 , eprint=
What Does BERT Look At? An Analysis of BERT's Attention , author=. 2019 , eprint=
2019
-
[52]
Lifting the Curse of Capacity Gap in Distilling Language Models
Zhang, Chen and Yang, Yang and Liu, Jiahao and Wang, Jingang and Xian, Yunsen and Wang, Benyou and Song, Dawei. Lifting the Curse of Capacity Gap in Distilling Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
2023
-
[53]
AD - KD : Attribution-Driven Knowledge Distillation for Language Model Compression
Wu, Siyue and Chen, Hongzhan and Quan, Xiaojun and Wang, Qifan and Wang, Rui. AD - KD : Attribution-Driven Knowledge Distillation for Language Model Compression. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
2023
-
[54]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Multi-granularity structural knowledge distillation for language model compression , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
EMO : Embedding Model Distillation via Intra-Model Relation and Optimal Transport Alignments
Truong, Minh-Phuc and Vu, Hai An and Vu, Tu and Diep, Nguyen Thi Ngoc and Van, Linh Ngo and Nguyen, Thien Huu and Le, Trung. EMO : Embedding Model Distillation via Intra-Model Relation and Optimal Transport Alignments. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.385
-
[56]
2025 , eprint=
Enhancing Cross-Tokenizer Knowledge Distillation with Contextual Dynamical Mapping , author=. 2025 , eprint=
2025
-
[57]
Adapter-based Selective Knowledge Distillation for Federated Multi-domain Meeting Summarization , author =. 2023 , eprint =. doi:10.48550/arXiv.2308.03275 , url =
-
[58]
VkD: Improving Knowledge Distillation using Orthogonal Projections , author =. 2024 , eprint =. doi:10.48550/arXiv.2403.06213 , url =
-
[59]
1970 , publisher=
An introduction to celestial mechanics , author=. 1970 , publisher=
1970
-
[60]
A Comparative Analysis of Task-Agnostic Distillation Methods for Compressing Transformer Language Models
Udagawa, Takuma and Trivedi, Aashka and Merler, Michele and Bhattacharjee, Bishwaranjan. A Comparative Analysis of Task-Agnostic Distillation Methods for Compressing Transformer Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2023
2023
-
[61]
2024 , eprint =
DeepSeek-V3 Technical Report , author =. 2024 , eprint =
2024
-
[62]
2024 , eprint =
GPT-4 Technical Report , author =. 2024 , eprint =
2024
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Neural Ordinary Differential Equations , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2018 , url =
2018
-
[64]
Universal Cross-Tokenizer Distillation via Approximate Likelihood Matching , author =. 2025 , eprint =. doi:10.48550/arXiv.2503.20083 , url =
-
[65]
Super- N atural I nstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
Wang, Yizhong and Mishra, Swaroop and Alipoormolabashi, Pegah and Kordi, Yeganeh and Mirzaei, Amirreza and Arunkumar, Anjana and Ashok, Arjun and Dhanasekaran, Arut Selvan and Naik, Atharva and Stap, David and Pathak, Eshaan and Karamanolakis, Giannis and Lai, Haizhi Gary and Purohit, Ishan and Mondal, Ishani and Anderson, Jacob and Kuznia, Kirby and Dosh...
-
[66]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , month =. Vicuna:
-
[67]
D ialog S um: A Real-Life Scenario Dialogue Summarization Dataset
Chen, Yulong and Liu, Yang and Chen, Liang and Zhang, Yue. D ialog S um: A Real-Life Scenario Dialogue Summarization Dataset. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021
2021
-
[68]
Smith and Daniel Khashabi and Hannaneh Hajishirzi , editor =
Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh. S elf- I nstruct: Aligning Language Models with S elf- G enerated Instructions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl...
-
[69]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=. 2019 , url =
2019
-
[70]
2024 , url =
Zhang, Peiyuan and Zeng, Guangtao and Wang, Tianduo and Lu, Wei , journal=. 2024 , url =
2024
-
[71]
arXiv preprint arXiv:2309.16609 , year =
Qwen Technical Report , author =. arXiv preprint arXiv:2309.16609 , year =
-
[72]
Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer , year=. 2205.01068 , archivePrefix=
-
[73]
Identifying and Mitigating Vulnerabilities in
Jiang, Fengqing and Xu, Zhangchen and Niu, Luyao and Wang, Boxin and Jia, Jinyuan and Li, Bo and Poovendran, Radha , journal =. Identifying and Mitigating Vulnerabilities in. 2023 , month = nov, doi =
2023
-
[74]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[75]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[76]
2024 , eprint=
Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models , author=. 2024 , eprint=
2024
-
[77]
2024 , eprint=
DistiLLM: Towards Streamlined Distillation for Large Language Models , author=. 2024 , eprint=
2024
-
[78]
2023 , eprint=
f-Divergence Minimization for Sequence-Level Knowledge Distillation , author=. 2023 , eprint=
2023
-
[79]
On the analysis and distillation of emergent outlier properties in pre-trained language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[80]
, author=
ESE: Espresso Sentence Embeddings. , author=. ICLR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.