Meta-Reinforcement Learning via Evolution for Multi-Objective Combinatorial Supply Chain Optimisation
Pith reviewed 2026-06-26 12:21 UTC · model grok-4.3
The pith
Population-based evolutionary meta-reinforcement learning produces more diverse Pareto fronts for multi-objective supply chain problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
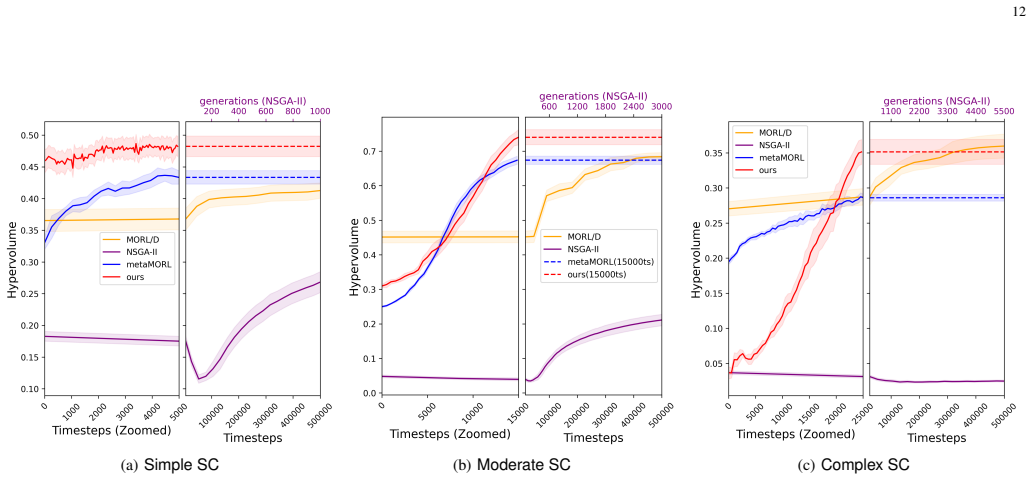
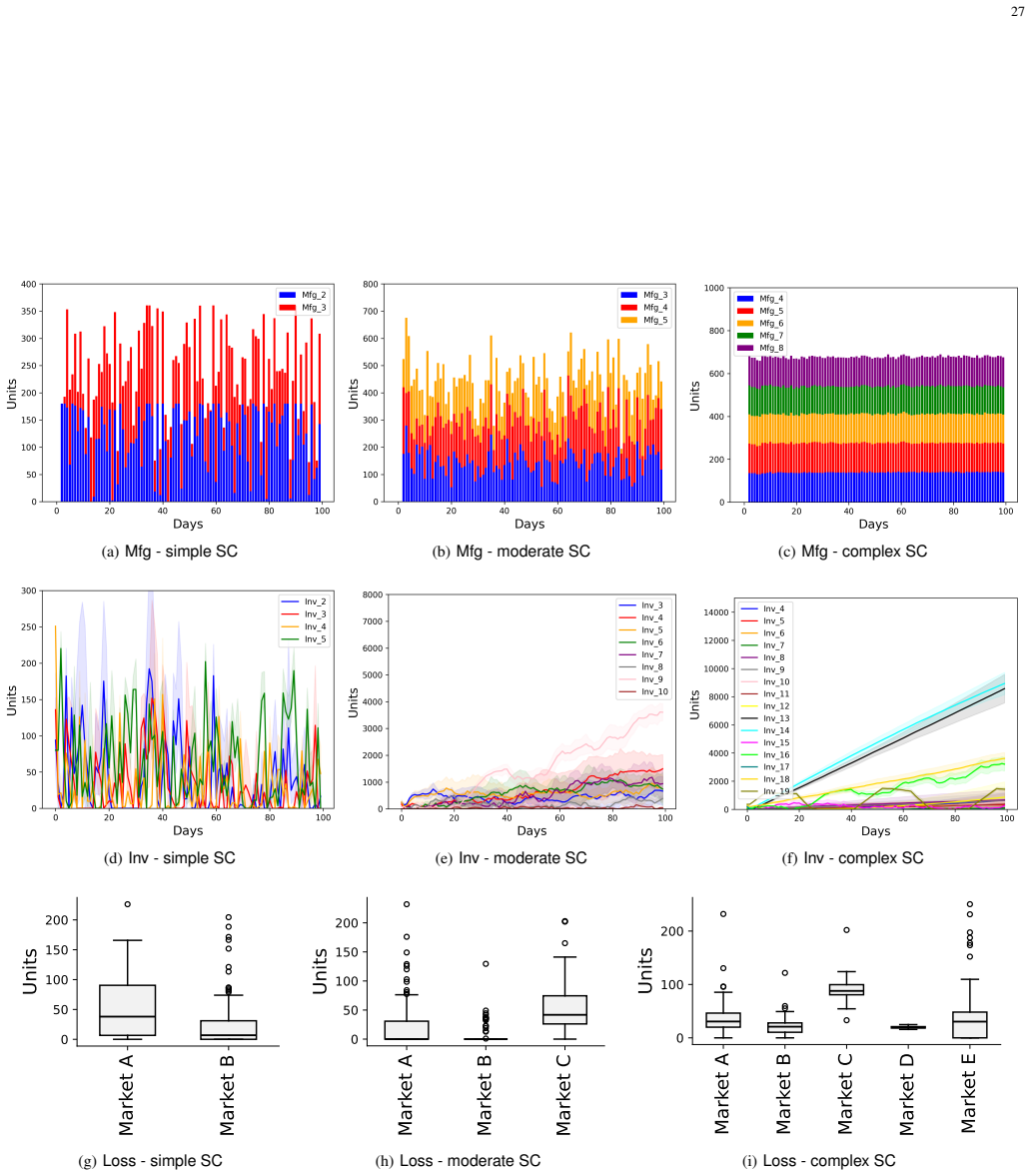
The central claim is that combining decomposition-based multi-objective optimization with evolutionary search in the space of scalarisation weights, while maintaining a population of associated meta-policies trained via gradient-based meta-learning, yields more diverse and better distributed Pareto front approximations, improves cross-task adaptation, and increases hypervolume by up to 32% over Meta-multi-objective reinforcement learning in the complex case, while attaining the lowest average Hausdorff distance.
What carries the argument
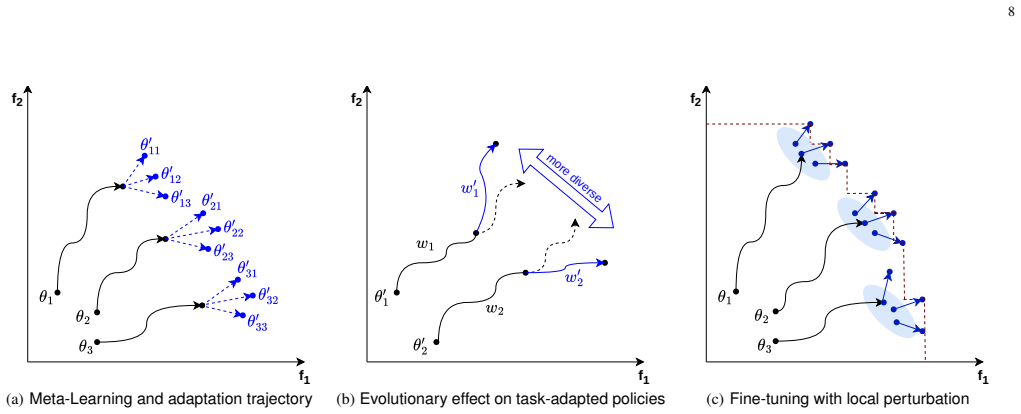
A population of weight vectors each associated with a distinct meta-policy, refined through elitist selection, crossover, and mutation guided by hypervolume and entropy contributions.
If this is right
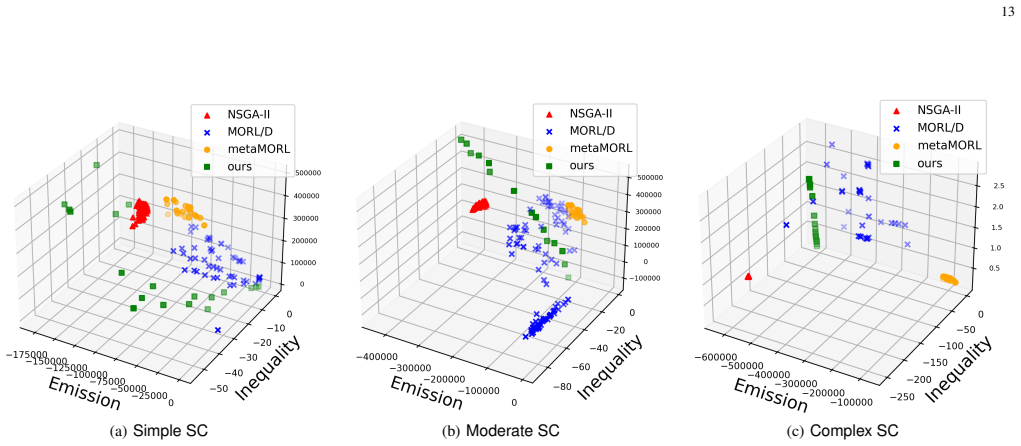
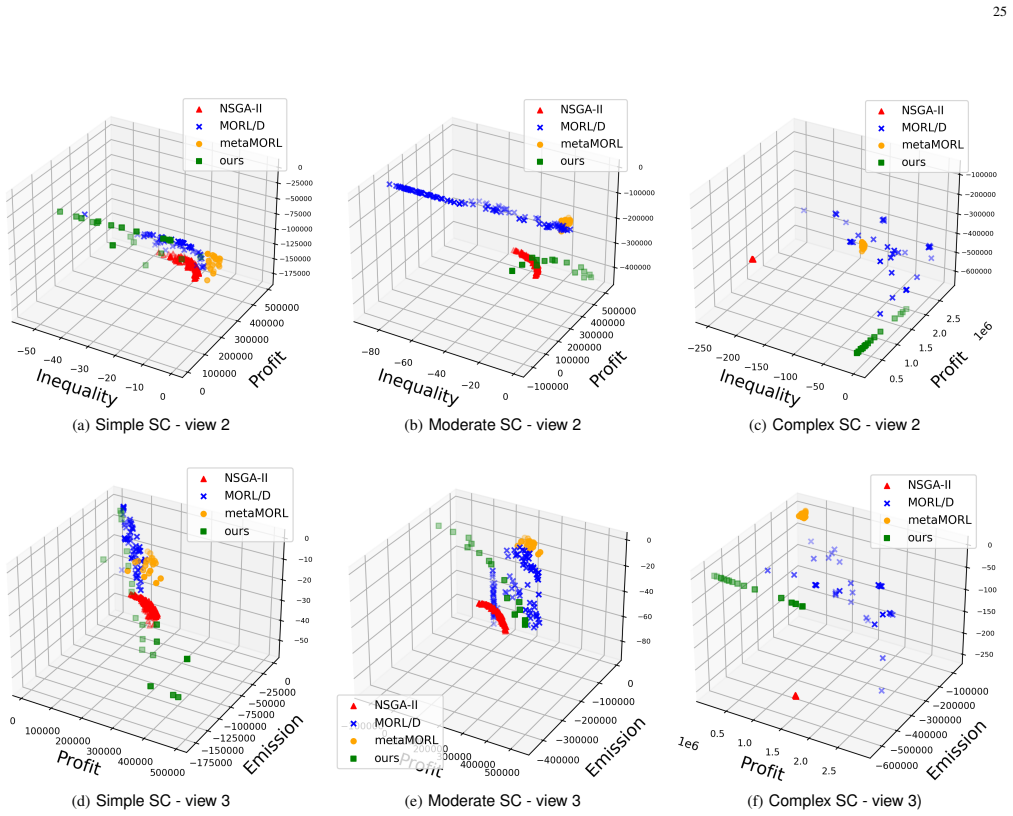
- Produces more diverse, better distributed Pareto front approximations
- Improves cross-task adaptation
- Increases hypervolume by up to 32% over Meta-multi-objective reinforcement learning in the complex case
- Attains the lowest average Hausdorff distance among compared methods
- Generalizes to standard reinforcement learning problems
Where Pith is reading between the lines
- This framework might apply to other high-dimensional multi-objective combinatorial problems where single-policy meta-learning collapses.
- The entropy contribution in evolution could help maintain exploration in changing environments beyond the tested supply chain setting.
- Combining evolutionary search with meta-RL suggests a hybrid path for handling preference changes without retraining from scratch.
Load-bearing premise
Evolutionary refinement of a population of weight vectors and their associated meta-policies will reliably increase solution diversity and hypervolume without single-meta-policy collapse, even when the underlying combinatorial problem structure changes.
What would settle it
A direct comparison experiment in the complex supply chain setting where the evolutionary population method shows no improvement in hypervolume or diversity, or exhibits the same collapse as single-meta-policy approaches.
Figures

read the original abstract
Meta-reinforcement learning is a promising approach to multi-objective optimisation because it enables rapid policy adaptation across changing environments and preference settings. However, conventional few-shot methods usually fine-tune from a single shared meta-policy, which can reduce solution diversity and limit exploration of the Pareto front, especially in high-dimensional combinatorial problems such as supply chain optimisation. We propose a population-based Meta-reinforcement learning framework that combines decomposition with evolutionary search in scalarisation weight space. The framework maintains a population of weight vectors, each associated with a distinct meta-policy trained through gradient-based meta-learning, and iteratively refines this population through elitist selection, crossover, and mutation guided by hypervolume and entropy contributions. We evaluate the method in a multi-objective supply chain setting with conflicting economic, environmental, and social goals, and further test its generality on standard reinforcement learning problems. The results show that the proposed approach yields more diverse, better distributed Pareto front approximations, improves cross-task adaptation, increases hypervolume by up to 32\% over Meta-multi-objective reinforcement learning in the complex case, and attains the lowest average Hausdorff distance among all compared methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a population-based meta-reinforcement learning framework for multi-objective combinatorial supply chain optimization. It maintains a population of scalarization weight vectors, each paired with a distinct meta-policy trained via gradient-based meta-learning, and refines the population using elitist selection, crossover, and mutation driven by hypervolume and entropy metrics. The approach is evaluated on a multi-objective supply chain problem with economic, environmental, and social objectives as well as standard RL benchmarks, with claims of improved Pareto front diversity, better cross-task adaptation, up to 32% higher hypervolume than Meta-multi-objective RL in complex cases, and the lowest average Hausdorff distance among compared methods.
Significance. If the empirical claims are substantiated, the work would address a recognized limitation of single-meta-policy approaches in multi-objective meta-RL by preserving solution diversity through evolutionary population maintenance. This could have value for high-dimensional combinatorial problems with conflicting objectives, such as supply chain optimization, and the reported generality to standard RL tasks would strengthen its contribution if the gains are reproducible.
major comments (1)
- [Abstract] Abstract: the central empirical claims (hypervolume gains of up to 32%, lowest Hausdorff distance, improved diversity without single-policy collapse) are presented without any description of experimental setup, baseline definitions, number of independent runs, statistical tests, or ablation studies. These omissions are load-bearing for the performance assertions that constitute the paper's primary contribution.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding our experimental claims. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (hypervolume gains of up to 32%, lowest Hausdorff distance, improved diversity without single-policy collapse) are presented without any description of experimental setup, baseline definitions, number of independent runs, statistical tests, or ablation studies. These omissions are load-bearing for the performance assertions that constitute the paper's primary contribution.
Authors: We agree that the abstract, in its current concise form, does not enumerate the experimental protocol. The full manuscript (Section 4) details the supply chain environment with three objectives, the compared baselines (including Meta-MORL and standard MORL variants), 10 independent runs per method, paired statistical tests, and ablations isolating the evolutionary population maintenance. To address the concern, we will expand the abstract with a brief clause on the evaluation setting, number of runs, and statistical validation while respecting length limits. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical proposal for a population-based meta-RL framework that augments standard meta-learning with evolutionary operators on weight vectors. All reported gains (hypervolume improvement, Hausdorff distance, diversity) are obtained by direct experimental comparison against existing meta-multi-objective RL baselines on supply-chain and RL benchmark tasks. No equations, uniqueness theorems, or first-principles derivations appear in the provided text; the central claims therefore rest on observable performance differences rather than any quantity that is definitionally or statistically forced by the method's own fitted parameters or self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi- Objective Optimization for Sustainable Supply Chain and Logistics: A Review,
C. P. Jayarathna, D. Agdas, L. Dawes, and T. Yigitcanlar, “Multi- Objective Optimization for Sustainable Supply Chain and Logistics: A Review,”Sustainability, vol. 13, no. 24, p. 13617, Dec. 2021
2021
-
[2]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 1st ed. Massachusetts: The MIT Press, 2015
2015
-
[3]
Multi-Objective Reinforcement Learning for Sustainable Supply Chain Optimization,
I. E. Shar, H. Wang, and C. Gupta, “Multi-Objective Reinforcement Learning for Sustainable Supply Chain Optimization,” in2023 IEEE 19th International Conference on Automation Science and Engineering (CASE). Auckland, New Zealand: IEEE, Aug. 2023, pp. 1–7
2023
-
[4]
Reinforcement learning for multi-objective multi-echelon supply chain optimisation,
R. Rachman, J. Tingey, R. Allmendinger, P. Shukla, and W. Pan, “Reinforcement learning for multi-objective multi-echelon supply chain optimisation,”European Journal of Operational Research, p. S0377221726001177, Feb. 2026
2026
-
[5]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,
C. Finn, P. Abbeel, and S. Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,” 2017. 15
2017
-
[6]
MIRACL: A Diverse Meta-Reinforcement Learning for Multi-Objective Multi-Echelon Combinatorial Supply Chain Optimisa- tion,
R. Rachman, J. Tingey, R. Allmendinger, W. Pan, P. Shukla, and B. I. Nasution, “MIRACL: A Diverse Meta-Reinforcement Learning for Multi-Objective Multi-Echelon Combinatorial Supply Chain Optimisa- tion,” 2026
2026
-
[7]
MOEA/D: A Multiobjective Evolutionary Algo- rithm Based on Decomposition,
Q. Zhang and H. Li, “MOEA/D: A Multiobjective Evolutionary Algo- rithm Based on Decomposition,”IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712–731, Dec. 2007
2007
-
[8]
A fast and elitist multiobjective genetic algorithm: NSGA-II,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,”IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, Apr. 2002
2002
-
[9]
A toolkit for reliable benchmarking and research in multi-objective reinforcement learning,
F. Felten, L. N. Alegre, A. Now ´e, A. L. C. Bazzan, E. G. Talbi, G. Danoy, and B. C. da Silva, “A toolkit for reliable benchmarking and research in multi-objective reinforcement learning,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), 2023
2023
-
[10]
Multi-objective Evolutionary Algorithms,
T. G. Smolinski, “Multi-objective Evolutionary Algorithms,” inEncy- clopedia of Computational Neuroscience, D. Jaeger and R. Jung, Eds. New York, NY: Springer New York, 2014, pp. 1–4
2014
-
[11]
Deb,Multi-Objective Optimization Using Evolutionary Algorithms, 1st ed., ser
K. Deb,Multi-Objective Optimization Using Evolutionary Algorithms, 1st ed., ser. Wiley-Interscience Series in Systems and Optimization. Chichester ; New York: John Wiley & Sons, 2001
2001
-
[12]
Meta-heuristics for sustainable supply chain management: A review,
S. Faramarzi-Oghani, P. Dolati Neghabadi, E.-G. Talbi, and R. Tavakkoli-Moghaddam, “Meta-heuristics for sustainable supply chain management: A review,”International Journal of Production Research, vol. 61, no. 6, pp. 1979–2009, Mar. 2023
1979
-
[13]
Metaheuristics in circular supply chain intelligent systems: A review of applications journey and forging a path to the future,
P. K. Detwal, R. Agrawal, A. Samadhiya, and A. Kumar, “Metaheuristics in circular supply chain intelligent systems: A review of applications journey and forging a path to the future,”Engineering Applications of Artificial Intelligence, vol. 126, p. 107102, 2023
2023
-
[14]
Genetic algorithms for multiob- jective optimization: Formulationdiscussion and generalization
C. M. Fonseca, P. J. Fleminget al., “Genetic algorithms for multiob- jective optimization: Formulationdiscussion and generalization.” inIcga, vol. 93. Citeseer, 1993, pp. 416–423
1993
-
[15]
Green logistics under imperfect pro- duction system: A Rough age based Multi-Objective Genetic Algorithm approach,
M. De, B. Das, and M. Maiti, “Green logistics under imperfect pro- duction system: A Rough age based Multi-Objective Genetic Algorithm approach,”Computers & Industrial Engineering, vol. 119, pp. 100–113, May 2018
2018
-
[16]
Using multi-objective genetic algorithm for partner selection in green supply chain problems,
W.-C. Yeh and M.-C. Chuang, “Using multi-objective genetic algorithm for partner selection in green supply chain problems,”Expert Systems with Applications, vol. 38, no. 4, pp. 4244–4253, Apr. 2011
2011
-
[17]
A multi-objective optimization model for sustainable supply chain network with using genetic algo- rithm,
R. Ehtesham Rasi and M. Sohanian, “A multi-objective optimization model for sustainable supply chain network with using genetic algo- rithm,”Journal of Modelling in Management, vol. 16, no. 2, pp. 714– 727, 2021
2021
-
[18]
Evaluation of multi-objective optimization approaches for solving green supply chain design problems,
M. Kadzi ´nski, T. Tervonen, M. K. Tomczyk, and R. Dekker, “Evaluation of multi-objective optimization approaches for solving green supply chain design problems,”Omega, vol. 68, pp. 168–184, Apr. 2017
2017
-
[19]
An efficiency sorting multi-objective optimization framework for sustainable supply network optimization and decision making,
Y . Wang, Q. Shi, Q. Hu, Z. You, Y . Bai, and C. Guo, “An efficiency sorting multi-objective optimization framework for sustainable supply network optimization and decision making,”Journal of Cleaner Pro- duction, vol. 272, p. 122842, Nov. 2020
2020
-
[20]
SPEA2: Improving the strength pareto evolutionary algorithm,
E. Zitzler, M. Laumanns, and L. Thiele, “SPEA2: Improving the strength pareto evolutionary algorithm,” ETH Zurich, Tech. Rep., May 2001
2001
-
[21]
Evolutionary multi-objective optimization of environmental indicators of integrated crude oil supply chain under uncertainty,
A. Azadeh, F. Shafiee, R. Yazdanparast, J. Heydari, and A. M. Fathabad, “Evolutionary multi-objective optimization of environmental indicators of integrated crude oil supply chain under uncertainty,”Journal of Cleaner Production, vol. 152, pp. 295–311, May 2017
2017
-
[22]
Handling multiple objectives with particle swarm optimization,
C. Coello, G. Pulido, and M. Lechuga, “Handling multiple objectives with particle swarm optimization,”IEEE Transactions on Evolutionary Computation, vol. 8, no. 3, pp. 256–279, Jun. 2004
2004
-
[23]
A sus- tainable vaccine supply-production-distribution network with heterolo- gous and homologous vaccination strategies: Bi-objective optimization,
A. Jahed, S. M. Hadji Molana, and R. Tavakkoli-Moghaddam, “A sus- tainable vaccine supply-production-distribution network with heterolo- gous and homologous vaccination strategies: Bi-objective optimization,” Socio-Economic Planning Sciences, vol. 98, p. 102113, Apr. 2025
2025
-
[24]
Multi- objective grey wolf optimizer: A novel algorithm for multi-criterion optimization,
S. Mirjalili, S. Saremi, S. M. Mirjalili, and L. d. S. Coelho, “Multi- objective grey wolf optimizer: A novel algorithm for multi-criterion optimization,”Expert Systems with Applications, vol. 47, pp. 106–119, 2016
2016
-
[25]
A fuzzy multi-objective optimization model for sustainable healthcare supply chain network design,
A. Ala, A. Goli, S. Mirjalili, and V . Simic, “A fuzzy multi-objective optimization model for sustainable healthcare supply chain network design,”Applied Soft Computing, vol. 150, p. 111012, 2024
2024
-
[26]
An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints,
K. Deb and H. Jain, “An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints,”IEEE Transactions on Evolutionary Computation, vol. 18, no. 4, pp. 577–601, 2014
2014
-
[27]
Green supply chain management and coordinated optimiza- tion by an improved sparrow search algorithm,
G. Wang, “Green supply chain management and coordinated optimiza- tion by an improved sparrow search algorithm,”Scientific Reports, vol. 15, no. 1, p. 36730, Oct. 2025
2025
-
[28]
Multi-objective closed-loop supply chain inventory model with learning and forgetting under carbon emission policies using NSGA-II, MOPSO, and TOPSIS,
T. Halder and B. K. Debnath, “Multi-objective closed-loop supply chain inventory model with learning and forgetting under carbon emission policies using NSGA-II, MOPSO, and TOPSIS,”Applied Soft Comput- ing, vol. 180, p. 113291, 2025
2025
-
[29]
Evolutionary Reinforcement Learning: A Systematic Review and Future Directions,
Y . Lin, F. Lin, G. Cai, H. Chen, L. Zou, Y . Liu, and P. Wu, “Evolutionary Reinforcement Learning: A Systematic Review and Future Directions,” Mathematics, vol. 13, no. 5, p. 833, Mar. 2025
2025
-
[30]
MO-CoERL: Multi-objective cooperative evolutionary deep reinforcement learning,
J. Shianifar, M. Schukat, and K. Mason, “MO-CoERL: Multi-objective cooperative evolutionary deep reinforcement learning,”Information Sci- ences, vol. 748, p. 123517, 2026
2026
-
[31]
Reducing idleness in financial cloud services via multi-objective evolutionary reinforcement learning based load balancer,
P. Yang, L. Zhang, H. Liu, and G. Li, “Reducing idleness in financial cloud services via multi-objective evolutionary reinforcement learning based load balancer,”Science China Information Sciences, vol. 67, no. 2, p. 120102, Feb. 2024
2024
-
[32]
Reinforcement learning-based multi-objective differential evolution algorithm for feature selection,
X. Yu, Z. Hu, W. Luo, and Y . Xue, “Reinforcement learning-based multi-objective differential evolution algorithm for feature selection,” Information Sciences, vol. 661, p. 120185, Mar. 2024
2024
-
[33]
Generating behavior-diverse game ais with evolutionary multi-objective deep reinforcement learning
R. Shen, Y . Zheng, J. Hao, Z. Meng, Y . Chen, C. Fan, and Y . Liu, “Generating behavior-diverse game ais with evolutionary multi-objective deep reinforcement learning.” inIJCAI, 2020, pp. 3371–3377
2020
-
[34]
Exploring Safer Behaviors for Deep Reinforcement Learning,
E. Marchesini, D. Corsi, and A. Farinelli, “Exploring Safer Behaviors for Deep Reinforcement Learning,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, pp. 7701–7709, Jun. 2022
2022
-
[35]
Leveraging reinforcement learning and evolutionary strategies for dynamic multi objective decision making in supply chain management,
Y . Qiu, N. Kotecha, and A. Del Rio Chanona, “Leveraging reinforcement learning and evolutionary strategies for dynamic multi objective decision making in supply chain management,”IFAC-PapersOnLine, vol. 58, no. 14, pp. 598–603, 2024
2024
-
[36]
Modeling the Evolution of Carbon Intensity: Linking the Solow Model to the Transport Equation,
P. Garcia and O. Pierrard, “Modeling the Evolution of Carbon Intensity: Linking the Solow Model to the Transport Equation,”Environmental and Resource Economics, vol. 88, no. 12, pp. 3473–3511, Dec. 2025
2025
-
[37]
Evolutionary principles in self-referential learning,
J. Schmidthuber, “Evolutionary principles in self-referential learning,” Ph.D. dissertation, 1987
1987
-
[38]
Learning to Learn: Introduction and Overview,
S. Thrun and L. Pratt, “Learning to Learn: Introduction and Overview,” inLearning to Learn, S. Thrun and L. Pratt, Eds. Boston, MA: Springer US, 1998, pp. 3–17
1998
-
[39]
Low data drug discovery with one-shot learning,
H. Altae-Tran, B. Ramsundar, A. S. Pappu, and V . Pande, “Low data drug discovery with one-shot learning,”ACS central science, vol. 3, no. 4, pp. 283–293, 2017
2017
-
[40]
AI Benchmark: All About Deep Learning on Smartphones in 2019,
A. Ignatov, R. Timofte, A. Kulik, S. Yang, K. Wang, F. Baum, M. Wu, L. Xu, and L. Van Gool, “AI Benchmark: All About Deep Learning on Smartphones in 2019,” 2019
2019
-
[41]
RL$ˆ2$: Fast Reinforcement Learning via Slow Reinforce- ment Learning,
Y . Duan, J. Schulman, X. Chen, P. L. Bartlett, I. Sutskever, and P. Abbeel, “RL$ˆ2$: Fast Reinforcement Learning via Slow Reinforce- ment Learning,” 2016
2016
-
[42]
Meta-Learning for Multi-objective Reinforcement Learning,
X. Chen, A. Ghadirzadeh, M. Bjorkman, and P. Jensfelt, “Meta-Learning for Multi-objective Reinforcement Learning,” in2019 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS). Macau, China: IEEE, Nov. 2019, pp. 977–983
2019
-
[43]
Prediction Guided Meta-Learning for Multi- Objective Reinforcement Learning,
F.-Y . Liu and C. Qian, “Prediction Guided Meta-Learning for Multi- Objective Reinforcement Learning,” in2021 IEEE Congress on Evolu- tionary Computation (CEC). Krak ´ow, Poland: IEEE, Jun. 2021, pp. 2171–2178
2021
-
[44]
A Meta-Learning Approach for Multi-Objective Reinforcement Learning in Sustainable Home Environ- ments,
J. Lu, P. Mannion, and K. Mason, “A Meta-Learning Approach for Multi-Objective Reinforcement Learning in Sustainable Home Environ- ments,” 2024
2024
-
[45]
Non-orthogonal age- optimal information dissemination in vehicular networks: A meta multi- objective reinforcement learning approach,
A. A. Al-Habob, H. Tabassum, and O. Waqar, “Non-orthogonal age- optimal information dissemination in vehicular networks: A meta multi- objective reinforcement learning approach,”IEEE Transactions on Mo- bile Computing, vol. 23, no. 10, pp. 9789–9803, 2024
2024
-
[46]
A practical guide to multi- objective reinforcement learning and planning,
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. K ¨allstr¨om, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, E. Howley, A. A. Irissappane, P. Mannion, A. Now ´e, G. Ramos, M. Restelli, P. Vamplew, and D. M. Roijers, “A practical guide to multi- objective reinforcement learning and planning,”Autonomous Agents and Multi-Age...
2022
-
[47]
A review of the evolution of multi- objective evolutionary algorithms,
T. Hanne and M. J. Moghaddam, “A review of the evolution of multi- objective evolutionary algorithms,”Computers, Materials and Continua, vol. 85, no. 3, pp. 4203–4236, 2025
2025
-
[48]
Bounding the Effectiveness of Hypervolume- Based (µ+λ)-Archiving Algorithms,
T. Ulrich and L. Thiele, “Bounding the Effectiveness of Hypervolume- Based (µ+λ)-Archiving Algorithms,” inLearning and Intelligent Optimization, Y . Hamadi and M. Schoenauer, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, vol. 7219, pp. 235–249
2012
-
[49]
The Hypervolume Indicator: Computational Problems and Algorithms,
A. P. Guerreiro, C. M. Fonseca, and L. Paquete, “The Hypervolume Indicator: Computational Problems and Algorithms,”ACM Computing Surveys, vol. 54, no. 6, pp. 1–42, Jul. 2022
2022
-
[50]
Knowles,Local-Search and Hybrid Evolutionary Algorithms for Pareto Optimization
J. Knowles,Local-Search and Hybrid Evolutionary Algorithms for Pareto Optimization. University of Reading, 2002. 16
2002
-
[51]
Performance assessment of multiobjective optimizers: An analysis and review,
E. Zitzler, L. Thiele, M. Laumanns, C. Fonseca, and V . Da Fonseca, “Performance assessment of multiobjective optimizers: An analysis and review,”IEEE Transactions on Evolutionary Computation, vol. 7, no. 2, pp. 117–132, Apr. 2003
2003
-
[52]
Branke,Multiobjective Optimization: Interactive and Evolutionary Approaches, ser
J. Branke,Multiobjective Optimization: Interactive and Evolutionary Approaches, ser. Lecture Notes in Computer Science. Berlin: Springer- Verlag, 2008, no. 5252
2008
-
[53]
Multiobjective optimization using evolutionary algorithms — A comparative case study,
E. Zitzler and L. Thiele, “Multiobjective optimization using evolutionary algorithms — A comparative case study,” inParallel Problem Solving from Nature — PPSN V, G. Goos, J. Hartmanis, J. Van Leeuwen, A. E. Eiben, T. B ¨ack, M. Schoenauer, and H.-P. Schwefel, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1998, vol. 1498, pp. 292–301
1998
-
[54]
¯Obayashi,Evolutionary Multi-Criterion Optimization: 4th Interna- tional Conference, EMO 2007, Matsushima, Japan, March 5-8, 2007 Proceedings, ser
S. ¯Obayashi,Evolutionary Multi-Criterion Optimization: 4th Interna- tional Conference, EMO 2007, Matsushima, Japan, March 5-8, 2007 Proceedings, ser. Lecture Notes in Computer Science. Berlin New York: Springer, 2007, no. 4403
2007
-
[55]
Quality Assessment of MORL Algorithms: A Utility-Based Approach,
L. M. Zintgraf, T. V . Kanters, D. M. Roijers, F. A. Oliehoek, and P. Beau, “Quality Assessment of MORL Algorithms: A Utility-Based Approach,” inProceedings of the 24th Annual Machine Learning Conference of Belgium and the Netherlands, 2015
2015
-
[56]
Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,
J. Xu, Y . Tian, P. Ma, D. Rus, S. Sueda, and W. Matusik, “Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, Jul. 2020, pp. 10 607–10 616
2020
-
[57]
Using the Averaged Hausdorff Distance as a Performance Measure in Evolution- ary Multiobjective Optimization,
O. Schutze, X. Esquivel, A. Lara, and C. A. C. Coello, “Using the Averaged Hausdorff Distance as a Performance Measure in Evolution- ary Multiobjective Optimization,”IEEE Transactions on Evolutionary Computation, vol. 16, no. 4, pp. 504–522, Aug. 2012
2012
-
[58]
Multi-objective Sequential Decision Making for Holistic Supply Chain Optimization,
R. Rachman, J. Tingey, R. Allmendinger, P. Shukla, and W. Pan, “Multi-objective Sequential Decision Making for Holistic Supply Chain Optimization,” inEvolutionary Multi-Criterion Optimization, H. Singh, T. Ray, J. Knowles, X. Li, J. Branke, B. Wang, and A. Oyama, Eds. Singapore: Springer Nature Singapore, 2025, vol. 15512, pp. 259–274
2025
-
[59]
Proximal Policy Optimization Algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” 2017
2017
-
[60]
RLlib: Abstractions for Distributed Reinforcement Learning,
E. Liang, R. Liaw, P. Moritz, R. Nishihara, R. Fox, K. Goldberg, J. E. Gonzalez, M. I. Jordan, and I. Stoica, “RLlib: Abstractions for Distributed Reinforcement Learning,” 2017
2017
-
[61]
Multi-Objective Reinforcement Learning Based on Decomposition: A Taxonomy and Framework,
F. Felten, E.-G. Talbi, and G. Danoy, “Multi-Objective Reinforcement Learning Based on Decomposition: A Taxonomy and Framework,” 2023
2023
-
[62]
Combining a gradient-based method and an evolution strategy for multi-objective reinforcement learning,
D. Chen, Y . Wang, and W. Gao, “Combining a gradient-based method and an evolution strategy for multi-objective reinforcement learning,” Applied Intelligence, vol. 50, no. 10, pp. 3301–3317, Oct. 2020
2020
-
[63]
Pymoo: Multi-Objective Optimization in Python,
J. Blank and K. Deb, “Pymoo: Multi-Objective Optimization in Python,” IEEE Access, vol. 8, pp. 89 497–89 509, 2020
2020
-
[64]
A parallel global multiobjective framework for optimization: pagmo,
F. Biscani and D. Izzo, “A parallel global multiobjective framework for optimization: pagmo,”Journal of Open Source Software, vol. 5, no. 53, p. 2338, 2020. [Online]. Available: https://doi.org/10.21105/joss.02338 17 APPENDIXA PROBLEMDEFINITION: MOMDP-BASEDFORMULATION Table V introduces the specific notation employed in the SC modelling, whereas Table VI ...
-
[65]
In our implementation, it is treated as a long-horizon control problem with a maximum episode length of 1000 steps
MO-HalfCheetah.:mo-halfcheetah-v4is a continuous-control MuJoCo locomotion task with a continuous observation space, a continuous action space, and two objectives. In our implementation, it is treated as a long-horizon control problem with a maximum episode length of 1000 steps. This environment is useful for testing whether a method can recover meaningfu...
-
[66]
It is one of the canonical MORL benchmarks because it provides a structured Pareto front with a clear trade-off between treasure value and time penalty
Deep Sea Treasure.:deep-sea-treasure-v0is a discrete grid-world problem with discrete observations, dis- crete actions, and two objectives. It is one of the canonical MORL benchmarks because it provides a structured Pareto front with a clear trade-off between treasure value and time penalty. We used a maximum episode length of 200 steps
-
[67]
Resource Gathering.:resource-gathering-v0is a discrete grid-world environment with discrete observations, discrete actions, and three objectives. The task requires bal- ancing multiple resource-related returns while avoiding un- favourable outcomes, making it a useful benchmark for testing 24 TABLE XXIII: RL standard problem environments details. Env. Obs...
-
[68]
Compared with mo-halfcheetah-v4, this environment introduces a more challenging multi-objective control setting with an additional objective and longer-horizon dynamics
MO-Hopper.:mo-hopper-v4is a continuous-control MuJoCo locomotion task with continuous observations, continuous actions, and three objectives. Compared with mo-halfcheetah-v4, this environment introduces a more challenging multi-objective control setting with an additional objective and longer-horizon dynamics. We used a maximum episode length of 1000 steps
-
[69]
MO-Reacher.:mo-reacher-v4is a multi-objective reaching task with a continuous observation space, a discrete action space in our benchmark interface, and four objectives. This task provides the highest reward dimensionality among the standard problems considered here, making it suitable for evaluating how well each method scales to more structured and high...
-
[70]
rgb_array
Common environment configuration.:All environments were instantiated throughmo_gym.make(..., render_mode="rgb_array")and wrapped with TimeLimitusing an environment-specific maximum episode length. No reward normalisation or scalarisation was applied at the environment level for benchmark evaluation, and comparisons were based on the cumulative raw vector ...
-
[71]
The discount factor was set toγ= 0.99for all methods
Common benchmark configuration.:Across all bench- mark algorithms, we used the same environment definitions, episode horizons, and random-seed interface. The discount factor was set toγ= 0.99for all methods. Algorithm applicability depended on the observation and action spaces of each task. In particular, PQL and MPMOQL were only used on discrete-observat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.