Investigating The Security of Modern AI and Cloud Infrastructure
Pith reviewed 2026-06-26 11:29 UTC · model grok-4.3
The pith
The assumption that deep neural networks and large language models operate in isolation does not hold, as shown by attacks that exploit vulnerabilities from physical memory to remote services.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the isolation assumption in AI and cloud infrastructure can be broken by practical attacks that exploit assumptions at each layer of abstraction, from physical memory co-location through architectural and algorithmic levels up to remote service interfaces.
What carries the argument
A taxonomy of interaction levels from physical memory co-location to remote service interfaces that organizes how vulnerabilities manifest across the AI stack.
If this is right
- Security analysis must consider the full stack rather than isolated components.
- Attacks can combine assumptions from multiple abstraction layers.
- Current deployments of neural networks and cloud systems may be open to cross-layer exploits.
- A unified taxonomy enables systematic reasoning about vulnerability connections.
Where Pith is reading between the lines
- Cloud providers might redesign isolation mechanisms for AI workloads to block the identified layer connections.
- The taxonomy could be applied to specialized AI hardware to identify new cross-layer risks.
- Interface designs between layers could be adjusted to reduce unintended information flows.
Load-bearing premise
Individual attack surfaces have been studied separately but the security community lacks a unified framework for connecting vulnerabilities across the AI stack.
What would settle it
A test that attempts to chain a physical memory access attack through to a remote service compromise on a deployed large language model system and either succeeds or fails in practice.
Figures

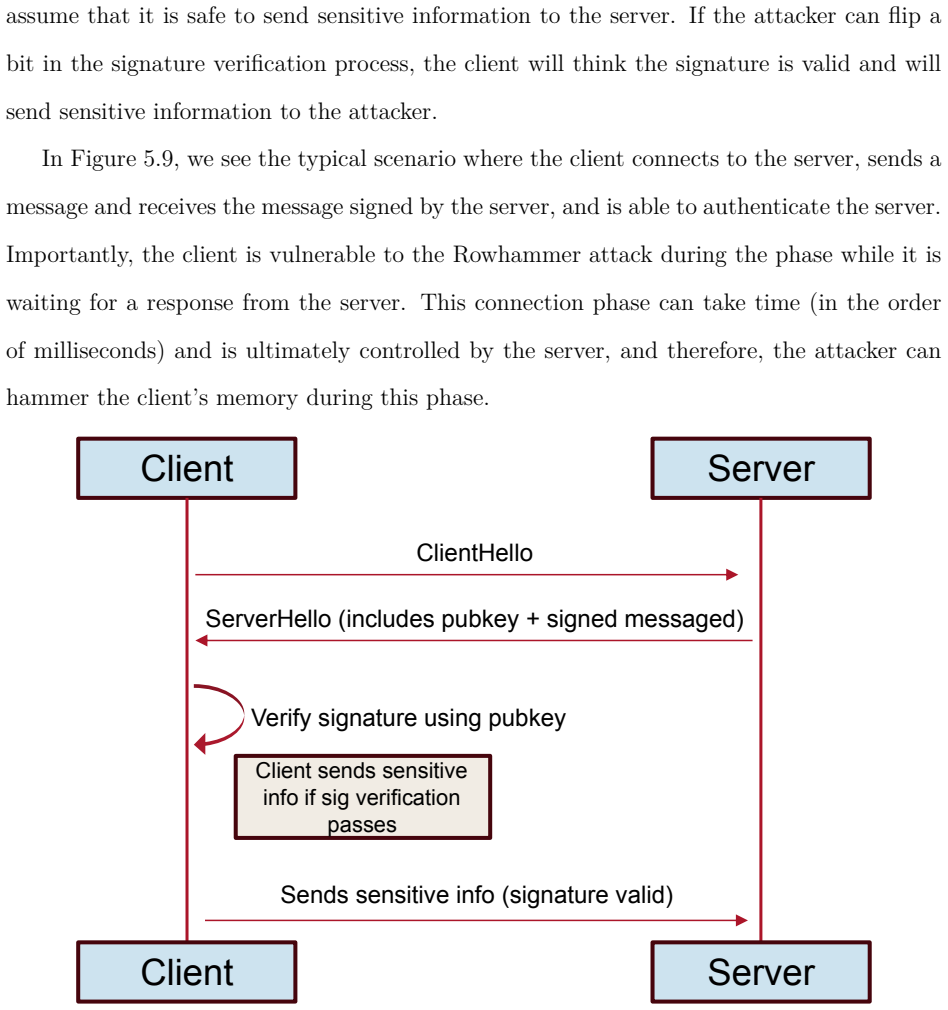
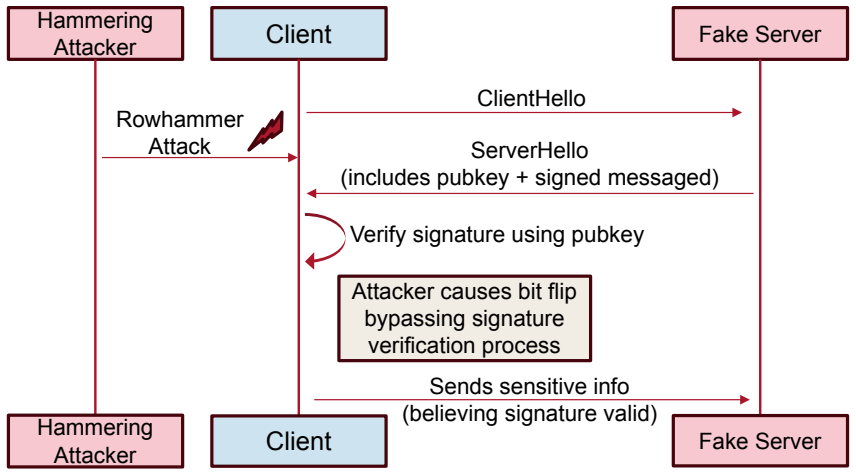

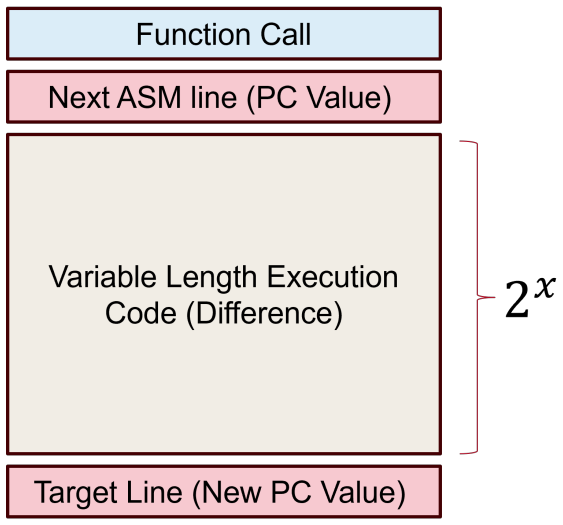
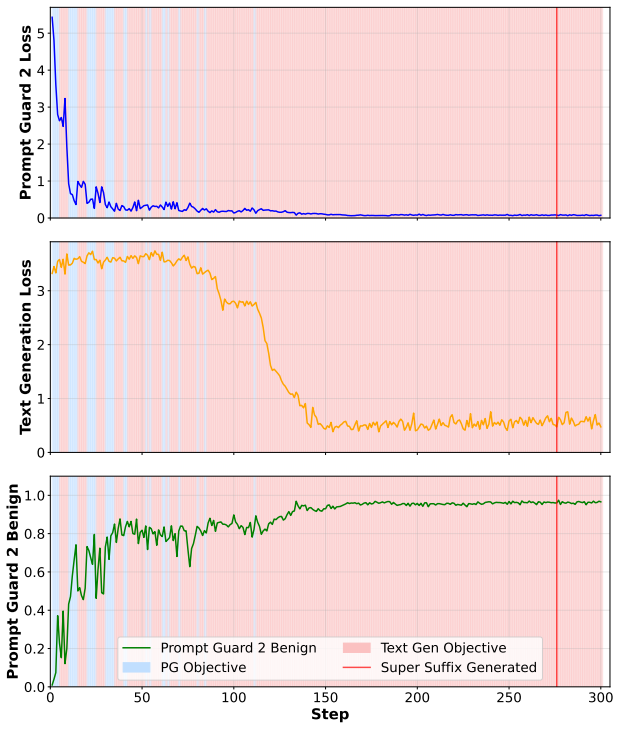
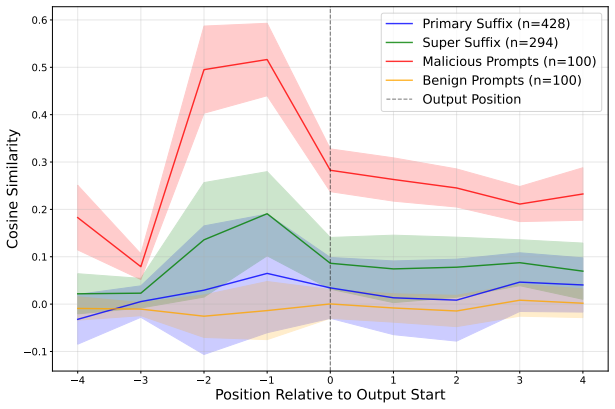
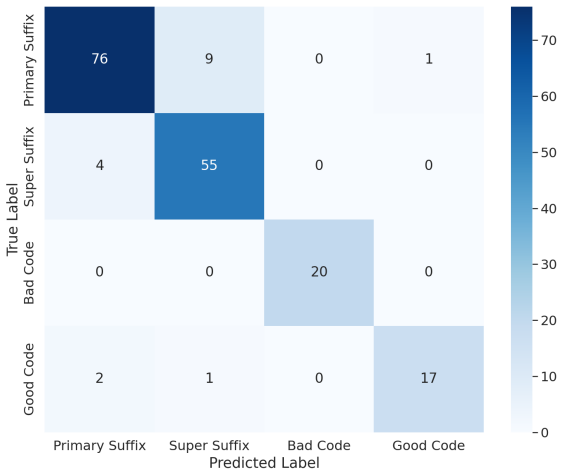
read the original abstract
The widespread deployment of Deep Neural Networks and Large Language Models (LLMs) relies on a foundational assumption of isolation that this dissertation challenges. This work systematically deconstructs security assumptions around AI and modern cloud infrastructure through a taxonomy of interaction levels that ranges from physical memory co-location to remote service interfaces. While significant research has addressed individual attack surfaces in isolation, the security community lacks a unified framework for reasoning about how physical, architectural, and algorithmic vulnerabilities manifest across the modern AI stack. This dissertation addresses that gap by demonstrating practical attacks that exploit assumptions at each layer of abstraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the deployment of DNNs and LLMs rests on an unexamined assumption of isolation; it introduces a taxonomy spanning physical memory co-location through remote service interfaces and asserts that it demonstrates practical attacks exploiting assumptions at each layer, thereby supplying the missing unified framework for cross-layer AI security vulnerabilities.
Significance. If the claimed practical attacks and taxonomy were substantiated with concrete, reproducible evidence, the work could offer a useful organizing lens for an otherwise fragmented literature on AI and cloud security. No such evidence appears in the manuscript, so the potential significance cannot be evaluated.
major comments (1)
- [Abstract] Abstract: the central claim that the work 'demonstrates practical attacks that exploit assumptions at each layer of abstraction' is unsupported; the text supplies neither attack descriptions, algorithms, experimental methodology, nor results.
Simulated Author's Rebuttal
We thank the referee for their review. We agree that the central claim in the abstract regarding demonstration of practical attacks is not supported by details in the manuscript, and this must be addressed through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the work 'demonstrates practical attacks that exploit assumptions at each layer of abstraction' is unsupported; the text supplies neither attack descriptions, algorithms, experimental methodology, nor results.
Authors: We agree with this assessment. The manuscript presents a taxonomy of interaction levels but does not include the attack descriptions, algorithms, experimental methodology, or results needed to substantiate the claim. We will revise the manuscript to add these elements in dedicated sections for each layer. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances a taxonomy of attack surfaces across physical-to-remote layers in AI/cloud stacks and claims to demonstrate practical attacks exploiting isolation assumptions. No equations, fitted parameters, derivations, or self-citation chains appear in the provided abstract or description. The central premise (unified framework for cross-layer vulnerabilities) is positioned as filling a stated gap in prior isolated research, without reducing any result to a self-definition, renamed fit, or author-prior ansatz. The work is therefore self-contained against external benchmarks of attack demonstrations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NSA Press Release, 2022
Nsa releases guidance on how to protect against software memory safety issues. NSA Press Release, 2022. A vailable at: https://www.nsa.gov
2022
-
[2]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report. arXiv preprint arXiv:2412.08905 , 2024
Pith/arXiv arXiv 2024
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anad- kat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023
Pith/arXiv arXiv 2023
-
[4]
Adiletta, M
Andrew J. Adiletta, M. Caner Tol, Yarkn Doröz, and Berk Sunar. Mayhem: Tar- geted corruption of register and stack variables. In Proceedings of the 2024 ACM Asia Conference on Computer and Communications Security , 2024
2024
-
[5]
Breaking meta’s prompt guard - why your ai needs more than just guardrails?, 2025
Repello AI. Breaking meta’s prompt guard - why your ai needs more than just guardrails?, 2025
2025
-
[6]
lattice barrier
Martin R. Albrecht and Nadia Heninger. On bounded distance decoding with predicate: Breaking the “lattice barrier” for the hidden number problem. In Anne Canteaut and François-Xavier Standaert, editors, Advances in Cryptology – EUROCRYPT 2021 , pages 528–558, Cham, 2021. Springer International Publishing
2021
-
[7]
{HyperDegrade}: From {GHz} to {MHz} effective {CPU} frequencies
Alejandro Cabrera Aldaya and Billy Bob Brumley. {HyperDegrade}: From {GHz} to {MHz} effective {CPU} frequencies. In 31st USENIX Security Symposium (USENIX Security 22) , pages 2801–2818, 2022
2022
-
[8]
Amplifying side channels through performance degradation
Thomas Allan, Billy Bob Brumley, Katrina Falkner, Joop Van de Pol, and Yuval Yarom. Amplifying side channels through performance degradation. In Proceedings of the 32nd Annual Conference on Computer Security Applications , pages 422–435, 2016
2016
-
[9]
Detecting language model attacks with perplex- ity
Gabriel Alon and Michael Kamfonas. Detecting language model attacks with perplex- ity. arXiv preprint arXiv:2308.14132 , 2023
Pith/arXiv arXiv 2023
-
[10]
Prompt injection security
Amazon. Prompt injection security. https://docs.aws.amazon.com/bedrock/late st/userguide/prompt-injection.html, 2025. Accessed: 2025-10-16
2025
-
[11]
Introducing claude, 2023
Anthropic. Introducing claude, 2023. Accessed: 2025-10-15. 162
2023
-
[12]
Foundational challenges in assuring alignment and safety of large language models
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, et al. Foundational challenges in assuring alignment and safety of large language models. arXiv preprint arXiv:2404.09932 , 2024
arXiv 2024
-
[13]
Refusal in language models is mediated by a single direction, 2024
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction, 2024
2024
-
[14]
ANVIL: Software-based protection against next-generation rowhammer attacks
Zelalem Birhanu Aweke, Salessawi Ferede Yitbarek, Rui Qiao, Reetuparna Das, Matthew Hicks, Yossi Oren, and Todd Austin. ANVIL: Software-based protection against next-generation rowhammer attacks. ACM SIGPLAN Notices , 51(4):743–755, 2016
2016
-
[15]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[16]
Training a helpful and harmless assistant with reinforcement learning from human feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova Das- Sarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 , 2022
Pith/arXiv arXiv 2022
-
[17]
Cache games - bringing access based cache attacks on AES to practice
Endre Bangerter, David Gullasch, and Stephan Krenn. Cache games - bringing access based cache attacks on AES to practice. Cryptology ePrint Archive, Paper 2010/594, 2010
2010
-
[18]
A neural probabilistic language model
Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems , 13, 2000
2000
-
[19]
Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025
Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025
2025
-
[20]
DeMillo, and Richard J
Dan Boneh, Richard A. DeMillo, and Richard J. Lipton. On the importance of elimi- nating errors in cryptographic computations. Journal of Cryptology , 14:101–119, 2015
2015
-
[21]
How practical are fault injection attacks, really? IEEE Access, 10:113122–113130, 2022
Jakub Breier and Xiaolu Hou. How practical are fault injection attacks, really? IEEE Access, 10:113122–113130, 2022
2022
-
[22]
Laser profiling for the back-side fault attacks: With a practical laser skip instruction attack on aes
Jakub Breier, Dirmanto Jap, and Chien-Ning Chen. Laser profiling for the back-side fault attacks: With a practical laser skip instruction attack on aes. In Proceedings of the 1st ACM Workshop on Cyber-Physical System Security . ACM, 2015
2015
-
[23]
Remote timing attacks are practical
David Brumley and Dan Boneh. Remote timing attacks are practical. Computer Networks, 48(5):701–716, 2005. 163
2005
-
[24]
The malicious use of artificial intelligence: Forecasting, prevention, and mitigation
Miles Brundage, Shahar A vin, Jack Clark, Helen Toner, Peter Eckersley, Ben Garfinkel, Allan Dafoe, Paul Scharre, Thomas Zeitzoff, Bobby Filar, et al. The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv preprint arXiv:1802.07228, 2018
arXiv 2018
-
[25]
Fallout: Leaking data on meltdown-resistant cpus
Claudio Canella, Daniel Genkin, Lukas Giner, Daniel Gruss, Moritz Lipp, Marina Minkin, Daniel Moghimi, Frank Piessens, Michael Schwarz, Berk Sunar, Jo Van Bulck, and Yuval Yarom. Fallout: Leaking data on meltdown-resistant cpus. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security , CCS ’19, page 769784, New York, NY, U...
2019
-
[26]
Are aligned neural networks adversarially aligned? Advances in Neural Information Processing Systems, 36:61478–61500, 2023
Nicholas Carlini, Milad Nasr, Christopher A Choquette-Choo, Matthew Jagielski, Irena Gao, Pang Wei W Koh, Daphne Ippolito, Florian Tramer, and Ludwig Schmidt. Are aligned neural networks adversarially aligned? Advances in Neural Information Processing Systems, 36:61478–61500, 2023
2023
-
[27]
Pappas, and Eric Wong
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages 23–42, 2025
2025
-
[28]
Real time detection of cache-based side-channel attacks using hardware performance counters
Marco Chiappetta, Erkay Savas, and Cemal Yilmaz. Real time detection of cache-based side-channel attacks using hardware performance counters. Applied Soft Computing , 49:1162–1174, 2016
2016
-
[29]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems , 30, 2017
2017
-
[30]
The urgent need for memory safety in software products
CISA. The urgent need for memory safety in software products. CISA Blog, 2023. A vailable at: https://www.cisa.gov
2023
-
[31]
Prisonbreak: Jailbreaking large language models with fewer than twenty-five targeted bit-flips
Zachary Coalson, Jeonghyun Woo, Shiyang Chen, Yu Sun, Lishan Yang, Prashant Nair, Bo Fang, and Sanghyun Hong. Prisonbreak: Jailbreaking large language models with fewer than twenty-five targeted bit-flips. arXiv preprint arXiv:2412.07192 , 2024
arXiv 2024
-
[32]
Are we susceptible to rowhammer? an end-to-end methodology for cloud providers
Lucian Cojocar, Jeremie Kim, Minesh Patel, Lillian Tsai, Stefan Saroiu, Alec Wolman, and Onur Mutlu. Are we susceptible to rowhammer? an end-to-end methodology for cloud providers. In 2020 IEEE Symposium on Security and Privacy (SP) , pages 712–
2020
-
[33]
Exploiting cor- recting codes: On the effectiveness of ECC memory against rowhammer attacks
Lucian Cojocar, Kaveh Razavi, Cristiano Giuffrida, and Herbert Bos. Exploiting cor- recting codes: On the effectiveness of ECC memory against rowhammer attacks. In 2019 IEEE Symposium on Security and Privacy (SP) , pages 55–71. IEEE, 2019
2019
-
[34]
Supervisor mode access prevention
Jonathan Corbet. Supervisor mode access prevention. https://lwn.net/Articles /517475/, Sep 2012. Accessed: 2024-01-10. 164
2012
-
[35]
Defending against Rowhammer in the kernel, October 2016
Jonathan Corbet. Defending against Rowhammer in the kernel, October 2016. https: //lwn.net/Articles/704920/
2016
-
[36]
Nearest neighbor pattern classification
Thomas Cover and Peter Hart. Nearest neighbor pattern classification. IEEE trans- actions on information theory , 13(1):21–27, 1967
1967
-
[37]
Glitchsnipe: Toward localized voltage fault attacks
Fatemeh Khojasteh Dana, Saleh Khalaj Monfared, Hamed Okhravi, and Shahin Tajik. Glitchsnipe: Toward localized voltage fault attacks. Cryptology ePrint Archive , 2026
2026
-
[38]
Sanjay Das, Swastik Bhattacharya, Souvik Kundu, Shamik Kundu, Anand Menon, Arnab Raha, and Kanad Basu. Attentionbreaker: Adaptive evolutionary optimiza- tion for unmasking vulnerabilities in llms through bit-flip attacks. arXiv preprint arXiv:2411.13757, 2024
arXiv 2024
-
[39]
Isomeron: Code randomization resilient to (just-in-time) return-oriented programming
Lucas Davi, Christopher Liebchen, Ahmad-Reza Sadeghi, Kevin Z Snow, and Fabian Monrose. Isomeron: Code randomization resilient to (just-in-time) return-oriented programming. In NDSS, 2015
2015
-
[40]
SMASH: Synchronized many-sided rowhammer attacks from JavaScript
Finn de Ridder, Pietro Frigo, Emanuele Vannacci, Herbert Bos, Cristiano Giuffrida, and Kaveh Razavi. SMASH: Synchronized many-sided rowhammer attacks from JavaScript. In 30th USENIX Security Symposium (USENIX Security 21) , pages 1001–
-
[41]
USENIX Association, August 2021
2021
-
[42]
Hotflip: White-box adver- sarial examples for text classification
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adver- sarial examples for text classification. arXiv preprint arXiv:1712.06751 , 2017
Pith/arXiv arXiv 2017
-
[43]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition. arXiv preprint arXiv:2209.10652 , 2022
Pith/arXiv arXiv 2022
-
[44]
Dedup est machina: Memory deduplication as an advanced exploitation vector
Herbert Bos Erik Bosman, Kaveh Razavi and Cristiano Giuffrida. Dedup est machina: Memory deduplication as an advanced exploitation vector. In Proceedings of the 37th IEEE Symposium on Security and Privacy (Oakland) , San Jose, CA, USA, May 2016. IEEE
2016
-
[45]
Safe, secure, and trustworthy development and use of artificial intelligence
Executive Office of the President. Safe, secure, and trustworthy development and use of artificial intelligence. Technical report, Federal Register, November 2023
2023
-
[46]
Bypassing prompt guards in production with controlled-release prompting
Jaiden Fairoze, Sanjam Garg, Keewoo Lee, and Mingyuan Wang. Bypassing prompt guards in production with controlled-release prompting. arXiv preprint arXiv:2510.01529, 2025
Pith/arXiv arXiv 2025
-
[47]
Discriminatory analysis: nonparametric discrimination, consistency prop- erties, volume 1
Evelyn Fix. Discriminatory analysis: nonparametric discrimination, consistency prop- erties, volume 1. USAF school of A viation Medicine, 1985
1985
-
[48]
TRRespass: Exploiting the many sides of target row refresh
Pietro Frigo, Emanuele Vannacc, Hasan Hassan, Victor Van Der Veen, Onur Mutlu, Cristiano Giuffrida, Herbert Bos, and Kaveh Razavi. TRRespass: Exploiting the many sides of target row refresh. In 2020 IEEE Symposium on Security and Privacy (SP) , pages 747–762. IEEE, 2020. 165
2020
-
[49]
Improving alignment of dialogue agents via targeted human judgements
Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022
Pith/arXiv arXiv 2022
- [50]
-
[51]
Aslr on the line: Practical cache attacks on the mmu
Ben Gras, Kaveh Razavi, Erik Bosman, Herbert Bos, and Cristiano Giuffrida. Aslr on the line: Practical cache attacks on the mmu. In NDSS, volume 17, page 26, 2017
2017
-
[52]
getchar(3p) Linux manual page
IEEE/The Open Group. getchar(3p) Linux manual page . man7.org, 2017. POSIX Programmer’s Manual
2017
-
[53]
Practical memory deduplication attacks in sandboxed javascript
Daniel Gruss, David Bidner, and Stefan Mangard. Practical memory deduplication attacks in sandboxed javascript. In Computer Security–ESORICS 2015: 20th European Symposium on Research in Computer Security, Vienna, Austria, September 21-25, 2015, Proceedings, Part I 20 , pages 108–122. Springer, 2015
2015
-
[54]
Another flip in the wall of rowham- mer defenses
Daniel Gruss, Moritz Lipp, Michael Schwarz, Daniel Genkin, Jonas Juffinger, Sioli O’Connell, Wolfgang Schoechl, and Yuval Yarom. Another flip in the wall of rowham- mer defenses. In 2018 IEEE Symposium on Security and Privacy (SP) , pages 245–261. IEEE, 2018
2018
-
[55]
Rowhammer
Daniel Gruss, Clémentine Maurice, and Stefan Mangard. Rowhammer. js: A remote software-induced fault attack in javascript. In International conference on detection of intrusions and malware, and vulnerability assessment , pages 300–321. Springer, 2016
2016
-
[56]
Flush+ Flush: a fast and stealthy cache attack
Daniel Gruss, Clémentine Maurice, Klaus Wagner, and Stefan Mangard. Flush+ Flush: a fast and stealthy cache attack. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment , pages 279–299. Springer, 2016
2016
-
[57]
Cache games – bringing access- based cache attacks on aes to practice
David Gullasch, Endre Bangerter, and Stephan Krenn. Cache games – bringing access- based cache attacks on aes to practice. In 2011 IEEE Symposium on Security and Privacy, pages 490–505, 2011
2011
-
[58]
Bypassing prompt injection and jailbreak detection in llm guardrails
William Hackett, Lewis Birch, Stefan Trawicki, Neeraj Suri, and Peter Garraghan. Bypassing prompt injection and jailbreak detection in llm guardrails. arXiv preprint arXiv:2504.11168, 2025
arXiv 2025
-
[59]
Alex Halderman, Seth D
J. Alex Halderman, Seth D. Schoen, Nadia Heninger, William Clarkson, William Paul, Joseph A. Calandrino, Ariel J. Feldman, Jacob Appelbaum, and Edward W. Felten. Lest we remember: cold-boot attacks on encryption keys. In CACM, 2008
2008
-
[60]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024. 166
2024
-
[61]
Unified memory for cuda beginners
Mark Harris. Unified memory for cuda beginners. Nvidia Technical Blog, 2017
2017
-
[62]
These are not your grand Daddys cpu performance counters–cpu hardware performance counters for security
Nishad Herath and Anders Fogh. These are not your grand Daddys cpu performance counters–cpu hardware performance counters for security. Black Hat Briefings , 2015
2015
-
[63]
Stronger universal and transfer attacks by suppressing refusals
David Huang, A vidan Shah, Alexandre Araujo, David Wagner, and Chawin Sitawarin. Stronger universal and transfer attacks by suppressing refusals. In Neurips Safe Gen- erative AI Workshop 2024 , 2024
2024
-
[64]
Llama guard: Llm-based input-output safeguard for human-ai conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674, 2023
Pith/arXiv arXiv 2023
-
[65]
MASCAT: Stopping microar- chitectural attacks before execution
Gorka Irazoqui, Thomas Eisenbarth, and Berk Sunar. MASCAT: Stopping microar- chitectural attacks before execution. IACR Cryptol. ePrint Arch. , 2016:1196, 2016
2016
-
[66]
SPOILER: Speculative load hazards boost rowhammer and cache attacks
Saad Islam, Ahmad Moghimi, Ida Bruhns, Moritz Krebbel, Berk Gulmezoglu, Thomas Eisenbarth, and Berk Sunar. SPOILER: Speculative load hazards boost rowhammer and cache attacks. In 28th USENIX Security Symposium (USENIX Security 19) , pages 621–637, Santa Clara, CA, August 2019. USENIX Association
2019
-
[67]
Blacksmith: Scalable rowhammering in the frequency domain
Patrick Jattke, Victor van der Veen, Pietro Frigo, Stijn Gunter, and Kaveh Razavi. Blacksmith: Scalable rowhammering in the frequency domain. In 2022 IEEE Sympo- sium on Security and Privacy (SP) , volume 1, 2022
2022
-
[68]
From clip to dino: Visual encoders shout in multi-modal large language models
Dongsheng Jiang, Yuchen Liu, Songlin Liu, Jin’e Zhao, Hao Zhang, Zhen Gao, Xi- aopeng Zhang, Jin Li, and Hongkai Xiong. From clip to dino: Visual encoders shout in multi-modal large language models. arXiv preprint arXiv:2310.08825 , 2023
arXiv 2023
-
[69]
Patterson John L
David A. Patterson John L. Hennessy. Computer Architecture A Quantitative Ap- proach. 2012
2012
-
[70]
Automatically auditing large language models via discrete optimization
Erik Jones, Anca Dragan, Aditi Raghunathan, and Jacob Steinhardt. Automatically auditing large language models via discrete optimization. In Proceedings of the 40th International Conference on Machine Learning , ICML’23. JMLR.org, 2023
2023
-
[71]
Automatically auditing large language models via discrete optimization
Erik Jones, Anca Dragan, Aditi Raghunathan, and Jacob Steinhardt. Automatically auditing large language models via discrete optimization. In International Conference on Machine Learning , pages 15307–15329. PMLR, 2023
2023
-
[72]
The ai-based cyber threat landscape: A survey
Nektaria Kaloudi and Jingyue Li. The ai-based cyber threat landscape: A survey. ACM Computing Surveys (CSUR) , 53(1):1–34, 2020
2020
-
[73]
A high- resolution side-channel attack on last-level cache
Mehmet Kayaalp, Nael Abu-Ghazaleh, Dmitry Ponomarev, and Aamer Jaleel. A high- resolution side-channel attack on last-level cache. In Proceedings of the 53rd Annual Design Automation Conference , pages 1–6, 2016
2016
-
[74]
sleep(3) Linux manual page
Michael Kerrisk. sleep(3) Linux manual page . man7.org, 2023. Linux man-pages 6.04. 167
2023
-
[75]
Flipping bits in memory without accessing them: An experimental study of dram disturbance errors
Yoongu Kim, Ross Daly, Jeremie Kim, Chris Fallin, Ji Hye Lee, Donghyuk Lee, Chris Wilkerson, Konrad Lai, and Onur Mutlu. Flipping bits in memory without accessing them: An experimental study of dram disturbance errors. ACM SIGARCH Computer Architecture News, 42(3):361–372, 2014
2014
-
[76]
King, Nikita Aggarwal, Mariarosaria Taddeo, and Luciano Floridi
Thomas C. King, Nikita Aggarwal, Mariarosaria Taddeo, and Luciano Floridi. Arti- ficial intelligence crime: An interdisciplinary analysis of foreseeable threats and solu- tions. Science and Engineering Ethics , feb 2019. Epub ahead of print
2019
-
[77]
Spectre mitigations in microsofts c/c++ compiler
Paul Kocher. Spectre mitigations in microsofts c/c++ compiler. Retrieved July 27, 2023 from https://www.paulkocher.com/doc/MicrosoftCompilerSpectreMitigat ion.html, 2018
2023
-
[78]
Timing attacks on implementations of diffie-hellman, rsa, dss, and other systems
Paul C Kocher. Timing attacks on implementations of diffie-hellman, rsa, dss, and other systems. In Advances in CryptologyCRYPTO96: 16th Annual International Cryptology Conference Santa Barbara, California, USA August 18–22, 1996 Proceed- ings 16 , pages 104–113. Springer, 1996
1996
-
[79]
Half-double: Hammering from the next row over
Andreas Kogler, Jonas Juffinger, Salman Qazi, Yoongu Kim, Moritz Lipp, Nicolas Boichat, Eric Shiu, Mattias Nissler, and Daniel Gruss. Half-double: Hammering from the next row over. In 31st USENIX Security Symposium: USENIX Security’22 , 2022
2022
-
[80]
Spectre returns! speculation attacks using the return stack buffer
Esmaeil Mohammadian Koruyeh, Khaled N Khasawneh, Chengyu Song, and Nael Abu-Ghazaleh. Spectre returns! speculation attacks using the return stack buffer. In 12th USENIX Workshop on Offensive Technologies (WOOT 18) , 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.