Natural Language-Focused Software Engineering via Code-Documentation Equivalence
Pith reviewed 2026-06-26 11:22 UTC · model grok-4.3
The pith
Documentation equivalent to its code lets LLMs predict function outputs with 12.8 to 24.5 percent higher accuracy than human-written documentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
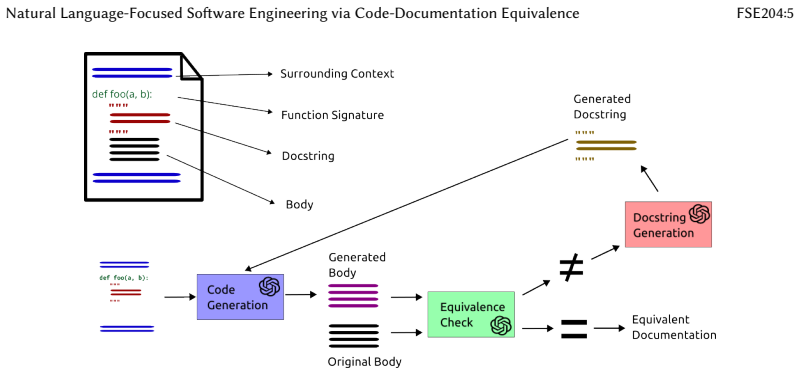
Documentation-to-code equivalence is a property that can be detected and generated automatically at the function level, and providing equivalent documentation as context measurably improves LLM performance on code understanding and editing tasks compared with human-written documentation or baseline-generated documentation.
What carries the argument
documentation-to-code equivalence, the property that documentation accurately and completely describes the code it documents
If this is right
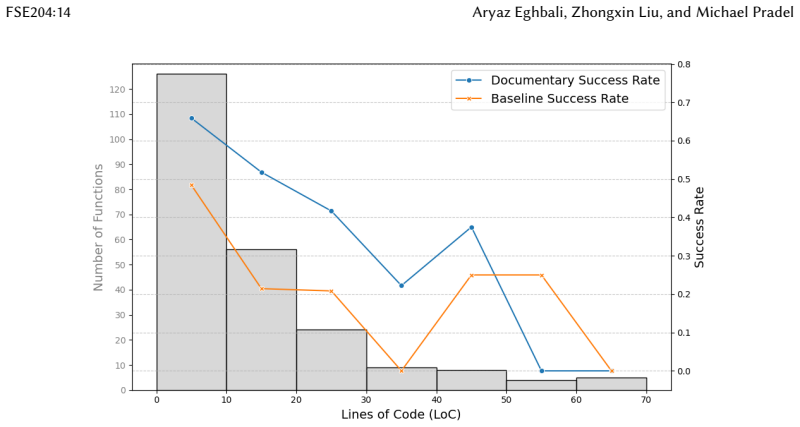
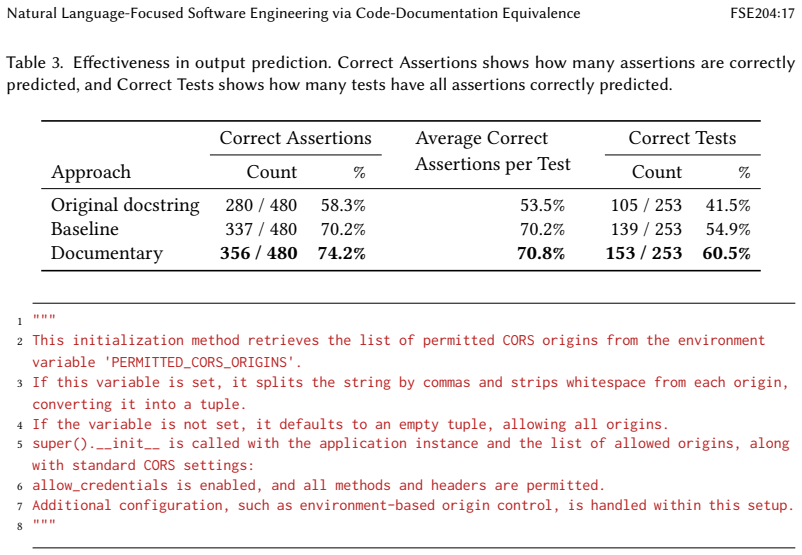
- LLMs achieve 12.8-24.5 percent higher accuracy predicting function outputs when given equivalent documentation.
- Human developers rate equivalent documentation more useful than original human-written documentation for understanding and editing code.
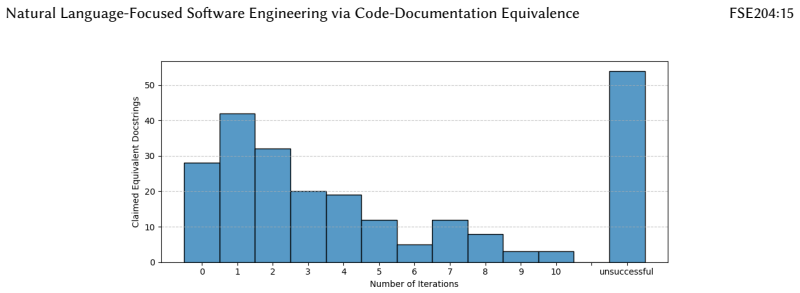
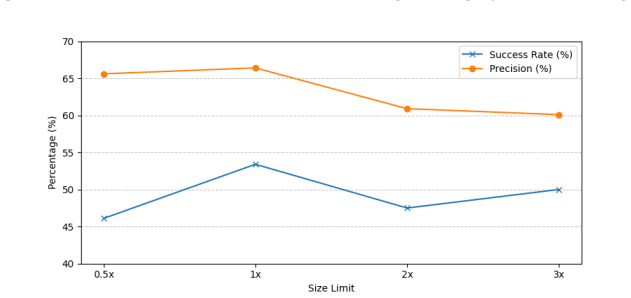
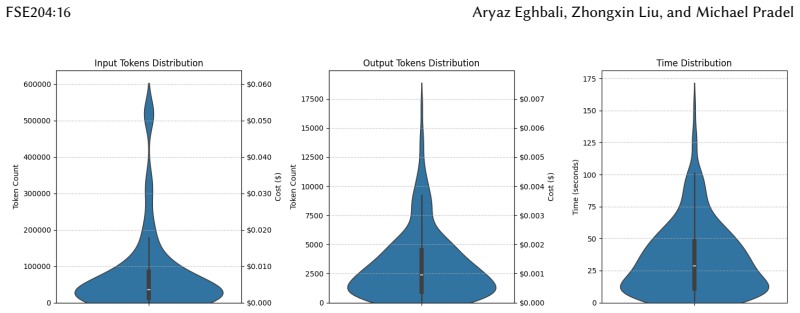
- Equivalent documentation can be generated for over half of function-level code snippets.
- The equivalence property supports both automated and human-assisted software engineering workflows.
Where Pith is reading between the lines
- The same equivalence idea could be applied to documentation for larger modules or entire repositories.
- Equivalent documentation might reduce errors in LLM-assisted code generation or refactoring beyond the tested tasks.
- Detection of non-equivalent human documentation could flag maintenance issues in existing codebases.
Load-bearing premise
The property of documentation-to-code equivalence can be reliably detected and generated at the function level in a manner that transfers to improved performance on downstream code understanding and editing tasks.
What would settle it
A controlled test in which LLMs given Documentary-generated documentation show no accuracy improvement over human-written documentation when asked to predict function outputs.
Figures









read the original abstract
Source code documentation is an integral part of software development and maintenance, as it helps in understanding the code and facilitates communication among developers. However, existing documentation is often incomplete, outdated, or inaccurate, which can lead to misunderstandings and errors. In the era of large language models (LLMs), which are being extensively used for software engineering tasks, the quality of documentation becomes even more critical, as documentation provides important context for the models. In this paper, we introduce the notion of documentation-to-code equivalence, a novel property that captures whether documentation accurately and completely describes the code it documents. We present a novel approach, called Documentary, to automatically generate equivalent documentation for a given code snippet. Our evaluation shows that Documentary can generate equivalent documentation for 53.4% of the evaluated function-level code snippets. To show the benefits of documentation-to-code equivalence, we describe and evaluate two software engineering tasks: code understanding and code editing. Our results show that documentation-to-code equivalence allows an LLM to predict the output of a function with 12.8--24.5% higher accuracy, when compared to human-written documentation and documentation generated by a baseline approach. Furthermore, human developers consider documentation generated by Documentary to be more useful for understanding and editing code than the original human-written documentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the notion of documentation-to-code equivalence and presents Documentary, an approach to automatically generate equivalent documentation for code snippets. It reports that Documentary produces equivalent documentation for 53.4% of evaluated function-level snippets. To demonstrate benefits, it evaluates two tasks (code understanding via LLM output prediction and code editing) and claims 12.8--24.5% higher LLM accuracy on output prediction versus human-written documentation and a baseline, plus higher human-rated usefulness for understanding and editing code.
Significance. If the empirical results hold under scrutiny, the work could meaningfully advance LLM-assisted software engineering by linking documentation quality (via the equivalence property) to measurable gains in downstream tasks. The concrete accuracy deltas and human study provide a falsifiable basis for the claims. However, the absence of methodological details prevents assessment of whether the gains are attributable to the proposed property or to other factors.
major comments (1)
- [Abstract] Abstract: The central performance claims (53.4% equivalence rate; 12.8--24.5% accuracy improvement) are stated without any description of the evaluation methodology, datasets, definition and measurement of equivalence, baseline approach, statistical tests, or error analysis. These omissions make the claims unverifiable and are load-bearing for the paper's empirical contribution.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater transparency in the abstract. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (53.4% equivalence rate; 12.8--24.5% accuracy improvement) are stated without any description of the evaluation methodology, datasets, definition and measurement of equivalence, baseline approach, statistical tests, or error analysis. These omissions make the claims unverifiable and are load-bearing for the paper's empirical contribution.
Authors: We agree that the abstract as currently written does not provide sufficient methodological context for the reported numbers. In the revised manuscript we will expand the abstract to include: (1) the source and size of the function-level dataset, (2) the operational definition of documentation-to-code equivalence together with the measurement procedure (human annotation protocol and inter-annotator agreement), (3) the baseline generation method, and (4) a brief statement that the accuracy improvements are statistically significant. Because abstracts are length-constrained, the added sentences will be concise yet sufficient to make the central claims verifiable at a high level; full methodological details remain in Sections 4 and 5. revision: yes
Circularity Check
No significant circularity; empirical claims are externally measured
full rationale
The paper introduces a new property (documentation-to-code equivalence) and an approach (Documentary) to generate it, then reports concrete empirical results: 53.4% equivalence rate and 12.8-24.5% accuracy lift on output prediction versus human docs and a baseline. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on observable performance deltas against external baselines rather than reducing to the definition or prior self-work by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2020. A Transformer-based Approach for Source Code Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL. 4998–5007. doi:10.18653/v1/2020.acl-main.449
-
[2]
Toufique Ahmed, Premkumar Devanbu, Christoph Treude, and Michael Pradel. 2025. Can LLMs Replace Manual Annotation of Software Engineering Artifacts?. In 2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). 526–538. doi:10.1109/MSR66628.2025.00086
-
[3]
Miltiadis Allamanis, Sheena Panthaplackel, and Pengcheng Yin. 2024. Unsupervised Evaluation of Code LLMs with Round-Trip Correctness. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview.net/forum?id=YnFuUX08CE
2024
-
[4]
Miltiadis Allamanis, Hao Peng, and Charles A. Sutton. 2016. A Convolutional Attention Network for Extreme Summarization of Source Code. In Proceedings of the 33nd International Conference on Machine Learning, ICML . 2091– 2100
2016
-
[5]
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fernández, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, André F. T. Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K. Surikuchi, Ece Takmaz, and Alberto Testoni. 2025. LLM...
-
[6]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE) . 2188–2200. doi:10.1109/ICSE55347.2025.00157
-
[7]
Islem Bouzenia, Bajaj Piyush Krishan, and Michael Pradel. 2024. DyPyBench: A Benchmark of Executable Python Software. In ACM International Conference on the Foundations of Software Engineering (FSE) . Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE204. Publication date: July 2026. Natural Language-Focused Software Engineering via Code-Documentation Eq...
2024
-
[8]
Islem Bouzenia and Michael Pradel. 2025. You Name It, I Run It: An LLM Agent to Execute Tests of Arbitrary Projects. Proceedings of the ACM on Software Engineering 2, ISSTA (June 2025), 1054–1076. doi:10.1145/3728922
-
[9]
Jizheng Chen, Kounianhua Du, Xinyi Dai, Weiming Zhang, Xihuai Wang, Yasheng Wang, Ruiming Tang, Weinan Zhang, and Yong Yu. 2025. DebateCoder: Towards Collective Intelligence of LLMs via Test Case Driven LLM Debate for Code Generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxia...
2025
-
[10]
De Souza, Nicolas Anquetil, and Káthia M
Sergio Cozzetti B. De Souza, Nicolas Anquetil, and Káthia M. De Oliveira. 2005. A Study of the Documentation Essential to Software Maintenance. In Proceedings of the 23rd Annual International Conference on Design of Communication: Documenting & Designing for Pervasive Information . ACM, Coventry United Kingdom, 68–75. doi:10.1145/1085313. 1085331
-
[11]
Beat Fluri, Michael Würsch, Emanuel Giger, and Harald C. Gall. 2009. Analyzing the Co-Evolution of Comments and Source Code. 17, 4 (2009), 367–394. doi:10.1007/s11219-009-9075-x
-
[12]
Xing Hu, Ge Li, Xin Xia, David Lo, and Zhi Jin. 2020. Deep Code Comment Generation with Hybrid Lexical and Syntactical Information. Empirical Software Engineering 25, 3 (May 2020), 2179–2217. doi:10.1007/s10664-019-09730-9
-
[13]
Matthew Jin, Syed Shahriar, Michele Tufano, Xin Shi, Shuai Lu, Neel Sundaresan, and Alexey Svyatkovskiy. 2023. InferFix: End-to-End Program Repair with LLMs. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . ACM, San Francisco CA USA, 1646–1656. doi:10.1145/3611643.3613892
-
[14]
Alexander LeClair, Aakash Bansal, and Collin McMillan. 2021. Ensemble Models for Neural Source Code Summarization of Subroutines. CoRR abs/2107.11423 (2021). arXiv:2107.11423 https://arxiv.org/abs/2107.11423
arXiv 2021
-
[15]
Bo Lin, Shangwen Wang, Zhongxin Liu, Xin Xia, and Xiaoguang Mao. 2023. Predictive Comment Updating With Heuristics and AST-Path-Based Neural Learning: A Two-Phase Approach. IEEE Transactions on Software Engineering 49, 4 (April 2023), 1640–1660. doi:10.1109/TSE.2022.3185458
-
[16]
Shangqing Liu, Yu Chen, Xiaofei Xie, Jing Kai Siow, and Yang Liu. 2021. Retrieval-Augmented Generation for Code Summarization via Hybrid GNN. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=zv-typ1gPxA
2021
-
[17]
Zhongxin Liu, Xin Xia, David Lo, Meng Yan, and Shanping Li. 2021. Just-in-time obsolete comment detection and update. IEEE Transactions on Software Engineering 49, 1 (2021), 1–23
2021
-
[18]
Zhongxin Liu, Xin Xia, Meng Yan, and Shanping Li. 2020. Automating just-in-time comment updating. In Proceedings of the 35th IEEE/ACM International conference on automated software engineering . 585–597
2020
-
[19]
Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray
Marcus J. Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray. 2023. Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain. InThe Twelfth International Conference on Learning Representations
2023
-
[20]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help With Code Understanding. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3597503.3639187
-
[21]
Kunal Pai, Premkumar Devanbu, and Toufique Ahmed. 2025. CoDocBench: A Dataset for Code-Documentation Alignment in Software Maintenance. In 2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE Computer Society, 451–455. doi:10.1109/MSR66628.2025.00077
-
[22]
Sheena Panthaplackel, Junyi Jessy Li, Milos Gligoric, and Raymond J. Mooney. 2021. Deep Just-In-Time Inconsistency Detection Between Comments and Source Code. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational...
2021
-
[23]
Sheena Panthaplackel, Pengyu Nie, Milos Gligoric, Junyi Jessy Li, and Raymond J. Mooney. 2020. Learning to Update Natural Language Comments Based on Code Changes. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020 , Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault ...
-
[24]
Abhik Roychoudhury, Corina Păsăreanu, Michael Pradel, and Baishakhi Ray. 2025. Agentic AI software engineers: programming with trust. Commun. ACM (2025)
2025
-
[25]
Kensen Shi, Deniz Altınbüken, Saswat Anand, Mihai Christodorescu, Katja Grünwedel, Alexa Koenings, Sai Naidu, Anurag Pathak, Marc Rasi, Fredde Ribeiro, Brandon Ruffin, Siddhant Sanyam, Maxim Tabachnyk, Sara Toth, Roy Tu, Tobias Welp, Pengcheng Yin, Manzil Zaheer, Satish Chandra, and Charles Sutton. 2025. Natural Language Outlines for Code: Literate Progra...
-
[26]
Beatriz Souza and Michael Pradel. 2025. Treefix: Enabling Execution with a Tree of Prefixes. arXiv:2501.12339 [cs] doi:10.48550/arXiv.2501.12339
-
[27]
Yao Wan, Zhou Zhao, Min Yang, Guandong Xu, Haochao Ying, Jian Wu, and Philip S. Yu. 2018. Improving automatic source code summarization via deep reinforcement learning. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, ASE 2018, Montpellier, France, September 3-7, 2018 , Marianne Huchard, Christian Kästner, an...
-
[28]
Yu Wang, Fengjuan Gao, and Linzhang Wang. 2021. Demystifying Code Summarization Models. CoRR (2021). https://arxiv.org/abs/2102.04625
arXiv 2021
-
[29]
Cody Watson, Michele Tufano, Kevin Moran, Gabriele Bavota, and Denys Poshyvanyk. 2020. On Learning Meaningful Assert Statements for Unit Test Cases. In ICSE
2020
-
[30]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS ’22) . Curran Associates Inc., Red Hook, NY, USA, 24824–24837
2022
-
[31]
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2020. Retrieval-based Neural Source Code Summarization. In ICSE. Received 2025-09-12; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE204. Publication date: July 2026
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.