Apple Neural Engine: Architecture, Programming, and Performance
Pith reviewed 2026-06-26 10:06 UTC · model grok-4.3
The pith
The Apple Neural Engine functions as a fixed-function matrix accelerator with a direct but undocumented programming path below Core ML.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
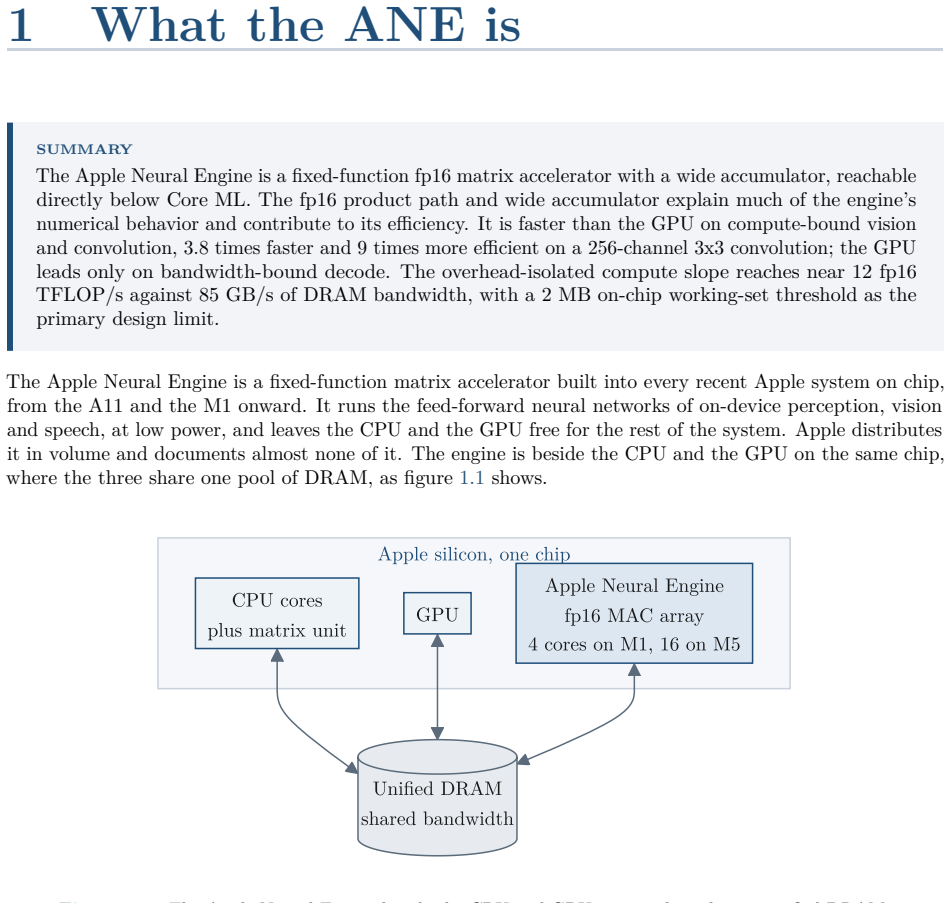
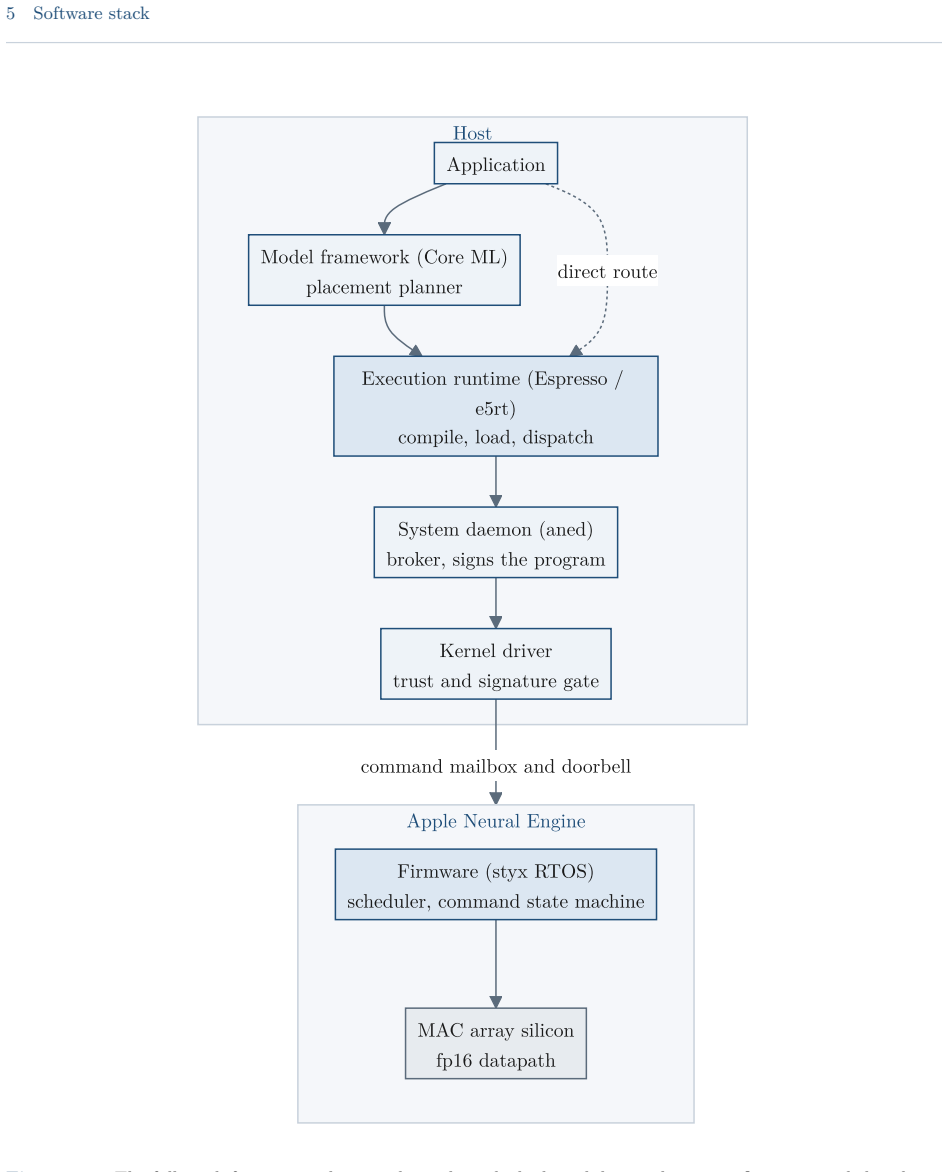
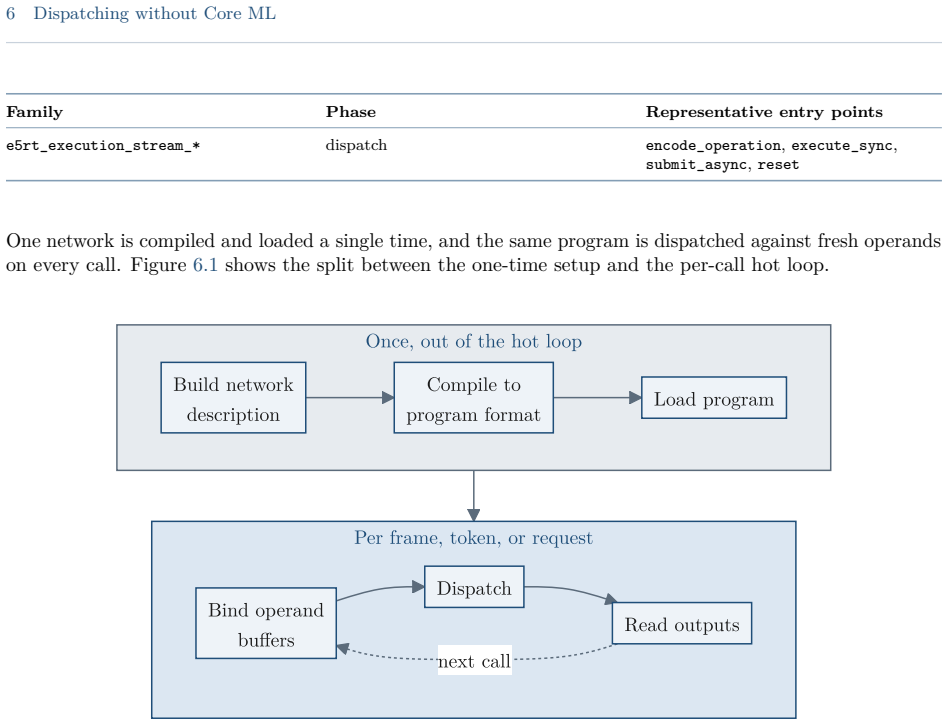
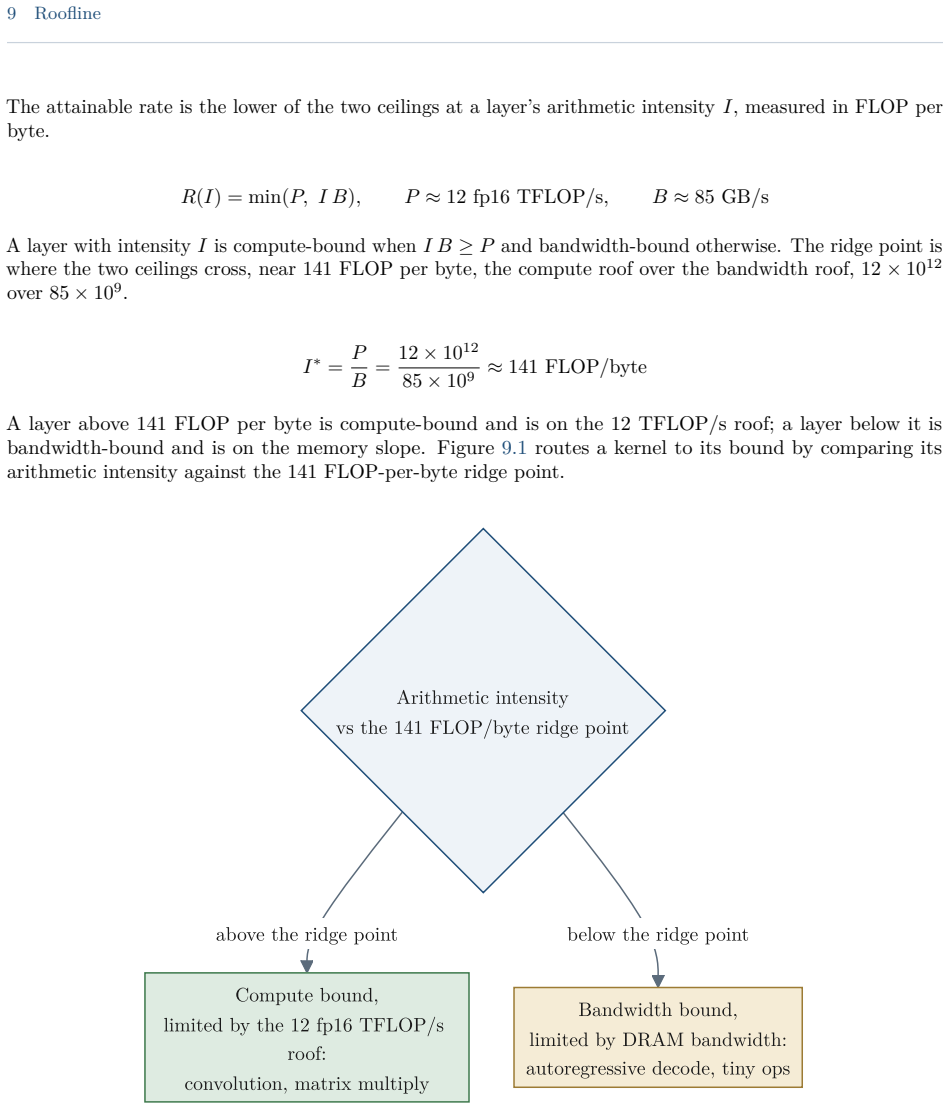
The Apple Neural Engine is a fixed-function matrix accelerator exposed only through Core ML. Static analysis of the private runtime, compiler, kernel driver, and firmware combined with direct measurements on M1 and M5 chips reconstructs the datapath, roofline bounds, on-disk program format, weight-compression scheme, and the full dispatch route from user space down to the command protocol. Per-chip target tables document variations across the covered device families.
What carries the argument
The reverse-engineered command protocol and on-disk program format that together allow direct dispatch of matrix operations to the engine without Core ML.
If this is right
- Direct user-space calls to the engine become feasible for measurement and custom workloads.
- The roofline provides concrete upper bounds on throughput and energy for any matrix size on each chip.
- Knowledge of the program format and compression scheme allows construction of alternative compilers or loaders.
- Version-specific tables make it possible to target the correct interfaces on each hardware generation.
Where Pith is reading between the lines
- Alternative machine-learning runtimes could be built that bypass the supported framework entirely.
- The documented weight-compression and dispatch details could inform energy models for similar fixed-function accelerators.
- The fragility of the direct route implies that any production use would require ongoing updates as firmware changes.
Load-bearing premise
The information gathered from static analysis of private software and from direct measurements accurately and completely reflects the hardware behavior and software interfaces.
What would settle it
Execute a known matrix operation on an A18 device using the documented command protocol and compare the measured throughput and energy against the roofline bounds given in the account.
Figures

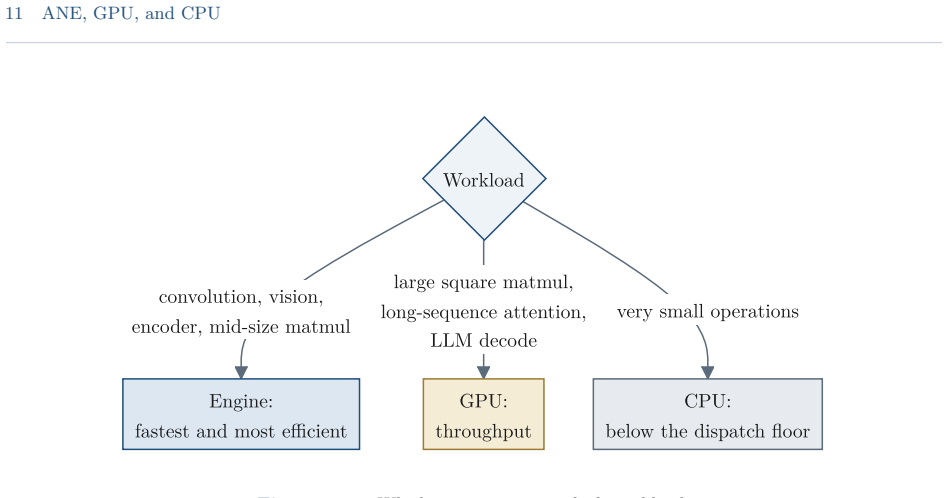
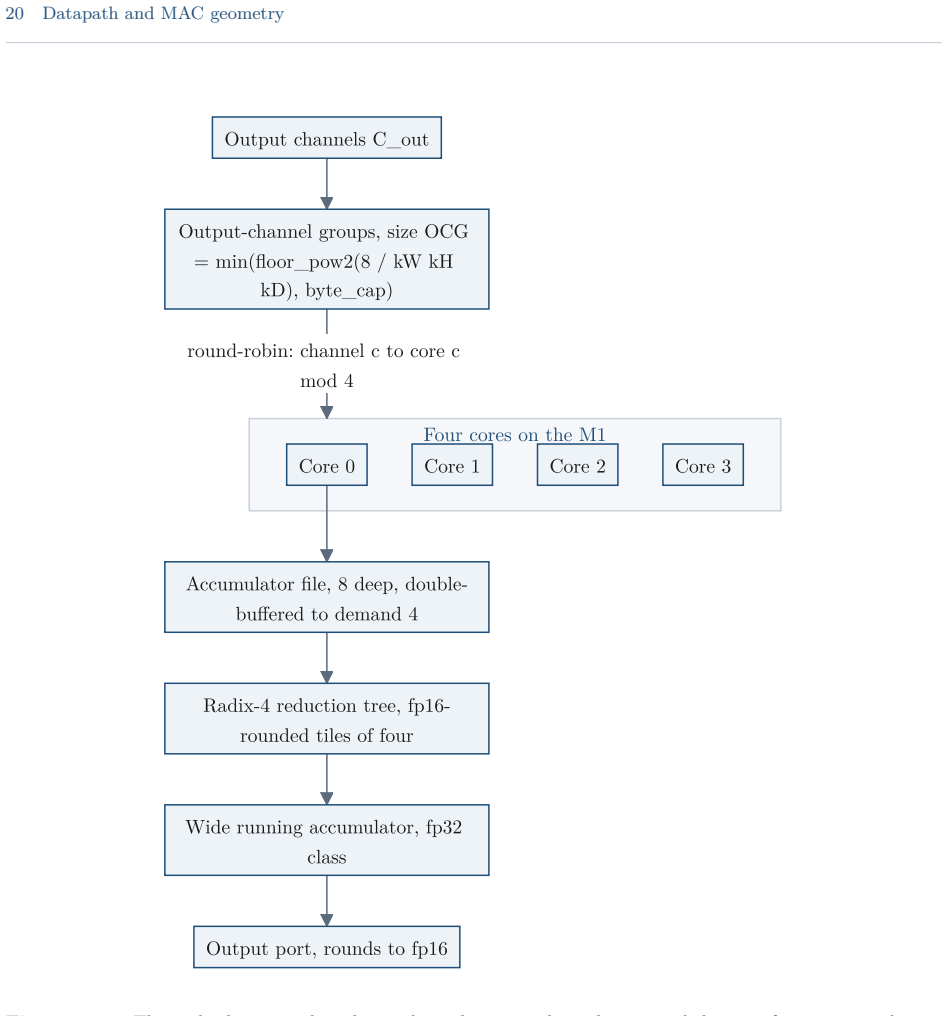
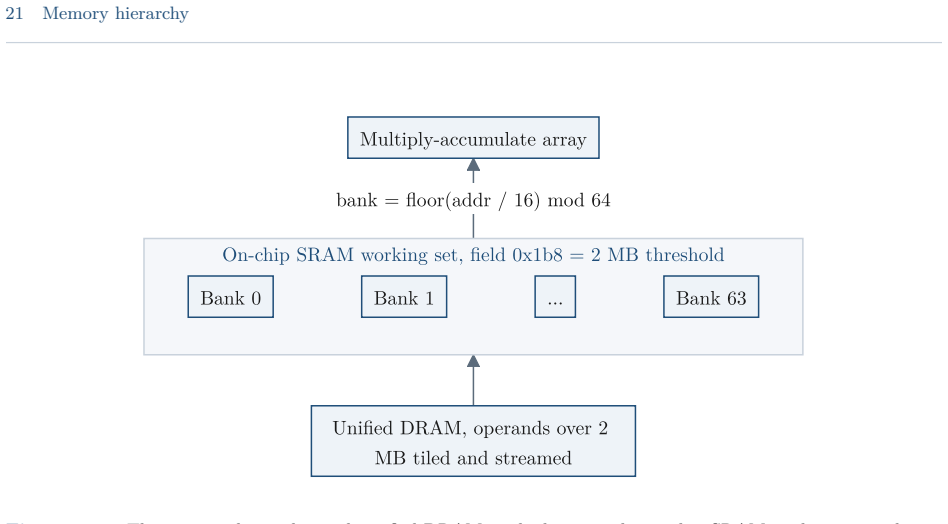
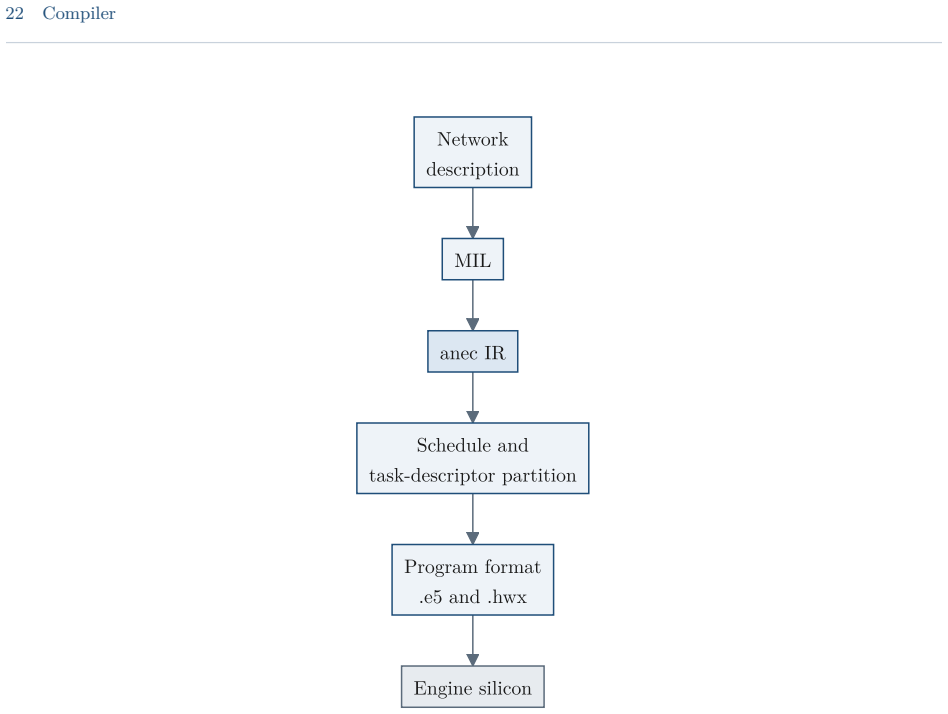
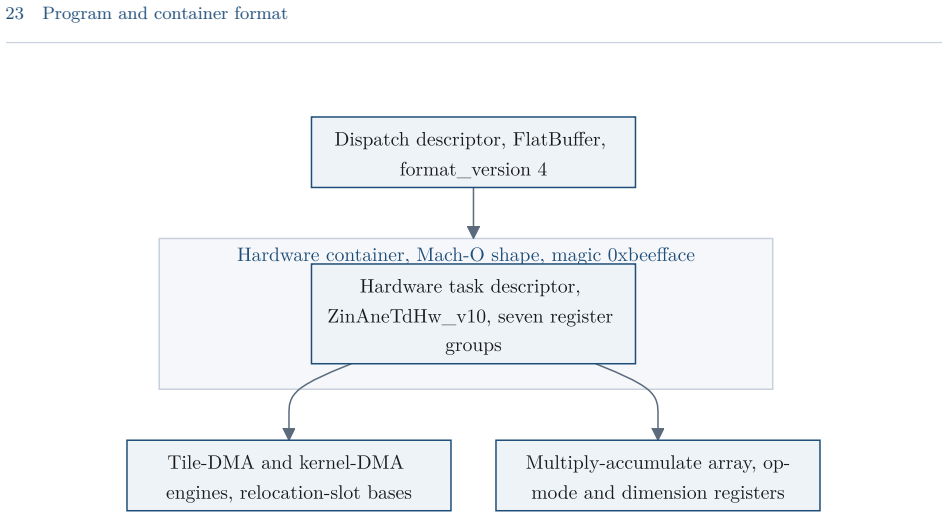
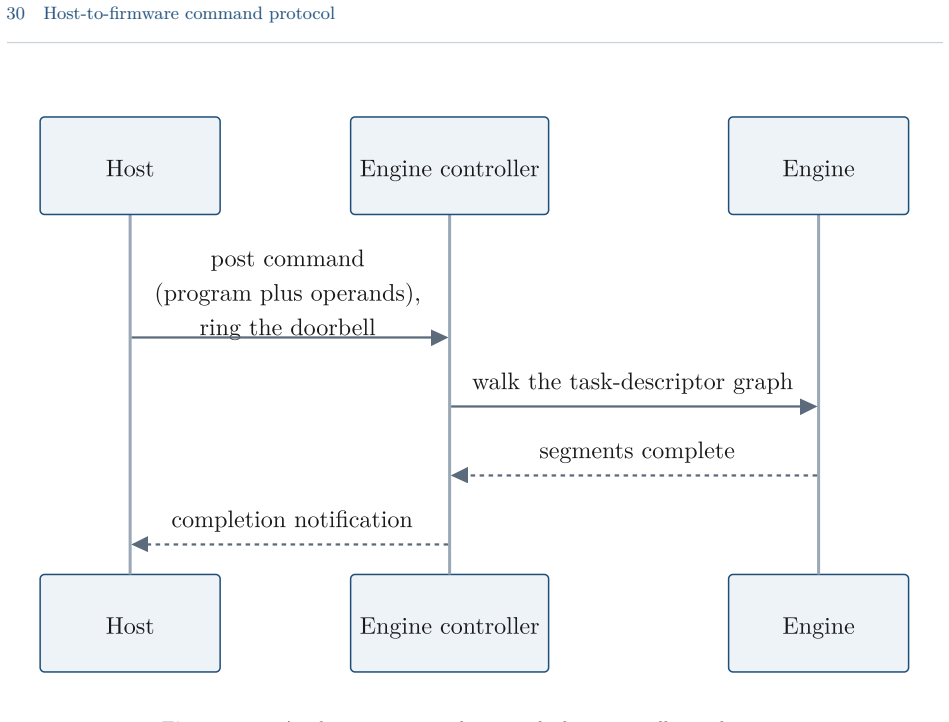
read the original abstract
The Apple Neural Engine (ANE) is the fixed-function matrix accelerator that has shipped in Apple systems-on-chip since the A11-class iPhone and iPad chips and the M1-class Mac chips, exposed to applications only through the Core ML model framework. This guide reports a reverse-engineered account of the engine, based on direct measurement on Apple silicon and static analysis of the private runtime, compiler, kernel driver, and firmware. It documents the datapath and the roofline that bound the engine's throughput and energy, the dispatch route that reaches it below Core ML, the compiler and on-disk program format, the weight-compression scheme, and the kernel driver, firmware, and command protocol beneath them. The account covers the A11 through A18 and M1 through M5 families, with per-chip target tables and an operation-by-device matrix; the direct measurements are on the M1 and M5. Claims are labeled as measured, decompile-derived, or predicted, and the methodology and open questions are recorded. The direct route is callable from ordinary user space but remains undocumented, unsupported, and version-fragile; it is intended for measurement, research, and on-device work, not for shipping software, where Core ML remains the supported path.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript provides a reverse-engineered account of the Apple Neural Engine (ANE) datapath, roofline bounds, dispatch route below Core ML, compiler and on-disk program format, weight-compression scheme, kernel driver, firmware, and command protocol. It covers A11–A18 and M1–M5 families via per-chip target tables and an operation-by-device matrix, with direct measurements on M1 and M5; all claims are explicitly labeled measured, decompile-derived, or predicted, and the methodology plus open questions are recorded.
Significance. If the decompile-derived and predicted elements hold, the work supplies the first public, detailed reference for a widely deployed commercial fixed-function matrix accelerator, enabling targeted research on its interfaces and performance. The explicit provenance labeling of claims, the direct M1/M5 measurements, and the per-chip tables are concrete strengths that increase the manuscript's utility as a technical resource beyond typical reverse-engineering reports.
major comments (1)
- [Abstract] Abstract and the section describing the per-chip target tables: the central claim that the account 'accurately reflects the actual hardware behavior and software interfaces' for the full set of chips rests on direct measurements only for M1 and M5; the remaining entries are decompile-derived or predicted from static analysis of private binaries. No additional cross-validation, error bounds, or independent confirmation is supplied to bound the risk of misinterpretation in the datapath, command protocol, or operation-by-device matrix, which is load-bearing for the manuscript's primary contribution.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the importance of clear provenance in the per-chip tables. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section describing the per-chip target tables: the central claim that the account 'accurately reflects the actual hardware behavior and software interfaces' for the full set of chips rests on direct measurements only for M1 and M5; the remaining entries are decompile-derived or predicted from static analysis of private binaries. No additional cross-validation, error bounds, or independent confirmation is supplied to bound the risk of misinterpretation in the datapath, command protocol, or operation-by-device matrix, which is load-bearing for the manuscript's primary contribution.
Authors: We agree that the abstract phrasing risks overstating the uniformity of validation. The manuscript already qualifies every entry in the per-chip tables and operation-by-device matrix by explicit labels (measured on M1/M5, decompile-derived, or predicted) and documents the methodology plus open questions in a dedicated section. Direct measurements were obtained on M1 and M5 as representatives of the two primary architectural generations; entries for A11–A18 and other M-series chips are derived from static analysis of the private runtime, compiler, kernel driver, and firmware binaries, with cross-references to observed dispatch behavior where possible. We will revise the abstract to state explicitly that direct hardware validation is limited to M1 and M5 while the tables supply the best publicly derivable information for the full range, each claim carrying its provenance label. Additional cross-validation or quantitative error bounds for the decompile-derived portions is not feasible without official specifications, which are unavailable. revision: partial
Circularity Check
No circularity: reverse-engineering report relies on external binaries and measurements
full rationale
The paper is a reverse-engineered hardware description derived from static analysis of shipped binaries and direct measurements on M1/M5 chips. No equations, fitted parameters, or derivations are present that reduce any claim to an input defined inside the paper. Claims are explicitly labeled measured/decompile-derived/predicted with methodology recorded; no self-citation chains, ansatzes, or renamings create load-bearing circularity. The central account is self-contained against external artifacts rather than internally defined quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static analysis of private runtime, compiler, kernel driver, and firmware combined with direct hardware measurements yields accurate information about the ANE datapath and interfaces.
Reference graph
Works this paper leans on
-
[1]
In-Datacenter Performance Analysis of a Tensor Processing Unit
Jouppi, N. P., Young, C., Patil, N., Patterson, D. A., et al. “In-Datacenter Performance Analysis of a Tensor Processing Unit.” International Symposium on Computer Architecture (ISCA), 1-12, 2017. Also arXiv:1704.04760
Pith/arXiv arXiv 2017
-
[2]
Orion: Characterizing and Programming Apple’s Neural Engine for LLM Training and Inference
Kumaresan, R. “Orion: Characterizing and Programming Apple’s Neural Engine for LLM Training and Inference.” Preprint, arXiv:2603.06728, 2026
arXiv 2026
-
[3]
Programmatic Energy Consumption Measurement on Apple Silicon (macOS)
ML.ENERGY / Zeus. “Programmatic Energy Consumption Measurement on Apple Silicon (macOS).” Project issue report (#159), 2025
2025
-
[4]
Hybe: GPU-NPU Hybrid System for Efficient LLM Inference with Million-Token Context Window
Moon, S., Cha, J., Park, H., and Kim, J. “Hybe: GPU-NPU Hybrid System for Efficient LLM Inference with Million-Token Context Window.” International Symposium on Computer Architecture (ISCA), 808-820, 2025. DOI 10.1145/3695053.3731051
-
[5]
Decoupling Machine Intelligence from Application in IoT Devices
Plyenkov, B. “Decoupling Machine Intelligence from Application in IoT Devices.” Master’s thesis, Aalto University, 2019
2019
-
[6]
Pagoda: An Energy and Time Roofline Study for DNN Workloads on Edge Accelerators
Prashanthi, S. K., Sahoo, K. K., Saikia, A. R., Gupta, P., Joshi, A. V., Pansari, P., and Simmhan, Y. “Pagoda: An Energy and Time Roofline Study for DNN Workloads on Edge Accelerators.” Preprint, arXiv:2509.20189, 2025
arXiv 2025
-
[7]
Inside the M4 Apple Neural Engine, Part 1: Reverse Engineering
Singh, M. “Inside the M4 Apple Neural Engine, Part 1: Reverse Engineering.” Blog post and repository, 2026, https://github.com/maderix/ANE
2026
-
[8]
Tummalapalli, P., Arayakandy, S., Pal, R., and Kundan, K. “LLM Inference at the Edge: Mobile, NPU, and GPU Performance Efficiency Trade-offs Under Sustained Load.” Preprint, arXiv:2603.23640, 2026
Pith/arXiv arXiv 2026
-
[9]
How to Keep Pushing ML Accelerator Performance? Know Your Rooflines!
Verhelst, M., Benini, L., and Verma, N. “How to Keep Pushing ML Accelerator Performance? Know Your Rooflines!” IEEE Journal of Solid-State Circuits, 2025. DOI 10.1109/JSSC.2025.3553765
-
[10]
Williams, S., Waterman, A., and Patterson, D. A. “Roofline: An Insightful Visual Performance Model for Multicore Architectures.” Communications of the ACM, 52(4), 65-76, 2009. DOI 10.1145/1498765.1498785
-
[11]
Fast on-device llm inference with npus,
Xu, D., Zhang, H., Yang, L., Liu, R., Huang, G., Xu, M., and Liu, X. “Fast On-device LLM Inference with NPUs.” ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025. arXiv:2407.05858, DOI 10.1145/3669940.3707239
-
[12]
Yang, C., Kurth, T., and Williams, S. “Hierarchical Roofline Analysis for GPUs: Accelerating Perfor- mance Optimization for the NERSC-9 Perlmutter System.” Concurrency and Computation: Practice and Experience, 32(20), e5547, 2020. DOI 10.1002/cpe.5547
-
[13]
ane: a reverse-engineered Linux driver for the Apple Neural Engine, with anecc
Yoon, E. “ane: a reverse-engineered Linux driver for the Apple Neural Engine, with anecc.” Repository, 2022, https://github.com/eiln/ane. 296
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.