Enhancing LLMs for Graph Tasks via Graph-aware LoRA Generation
Pith reviewed 2026-06-26 10:57 UTC · model grok-4.3
The pith
GaRA generates low-rank weight updates conditioned on graph structures to inject whole-graph information into LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GaRA constructs low-rank weight updates conditioned on the original graph structures and constrains the norm of the generated updates, thus injecting whole-graph information and avoiding the optimization bias in the weight generation.
What carries the argument
GaRA, the Graph-aware LoRA generation model that builds task-specific low-rank weight updates directly from input graph structures.
If this is right
- GaRA enables language models to handle graph tasks with better transferability across datasets than graph neural networks.
- The norm constraint prevents optimization bias during generation of the weight updates.
- Whole-graph information reaches the model's hidden representations through direct interaction with the generated updates.
- Performance improves consistently on zero-shot graph learning tasks compared to existing adaptation baselines.
Where Pith is reading between the lines
- The same conditioning approach could extend to other low-rank adaptation variants beyond LoRA.
- If the paradigm holds, it suggests a general route for injecting structured data modalities into frozen language models without full retraining.
Load-bearing premise
Generating and applying low-rank weight updates conditioned on graph structure will successfully encode whole-graph information into the LLM's hidden representations without the information loss seen in prior adaptation methods.
What would settle it
A controlled test where GaRA-adapted LLMs still fail to distinguish isomorphic graphs or show no gain over standard LoRA on whole-graph classification metrics.
Figures
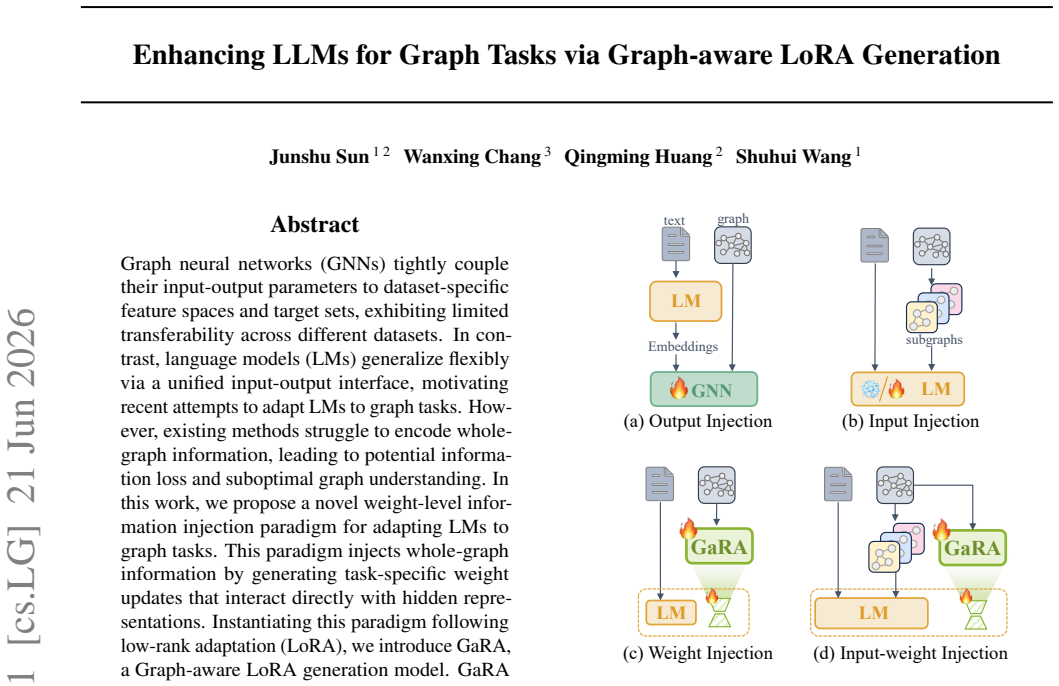
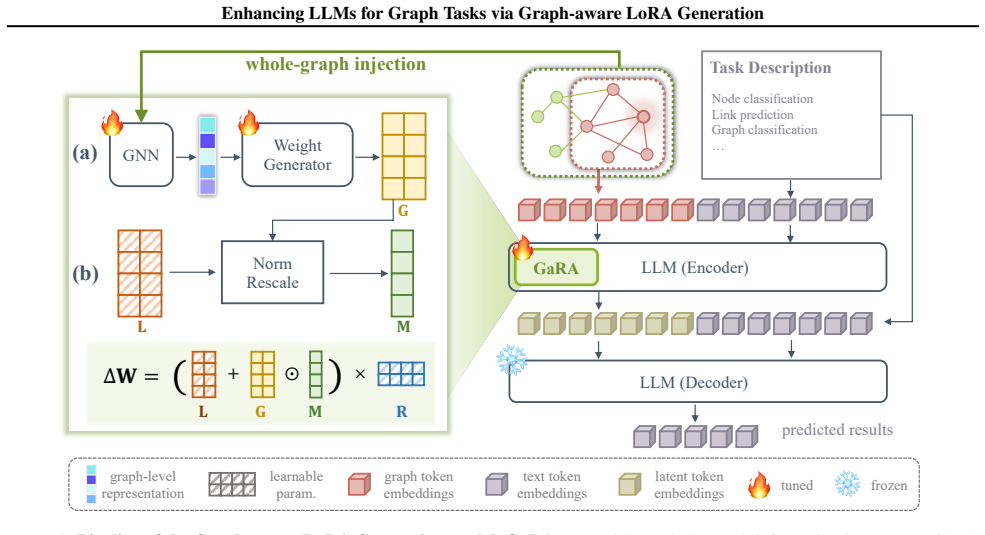
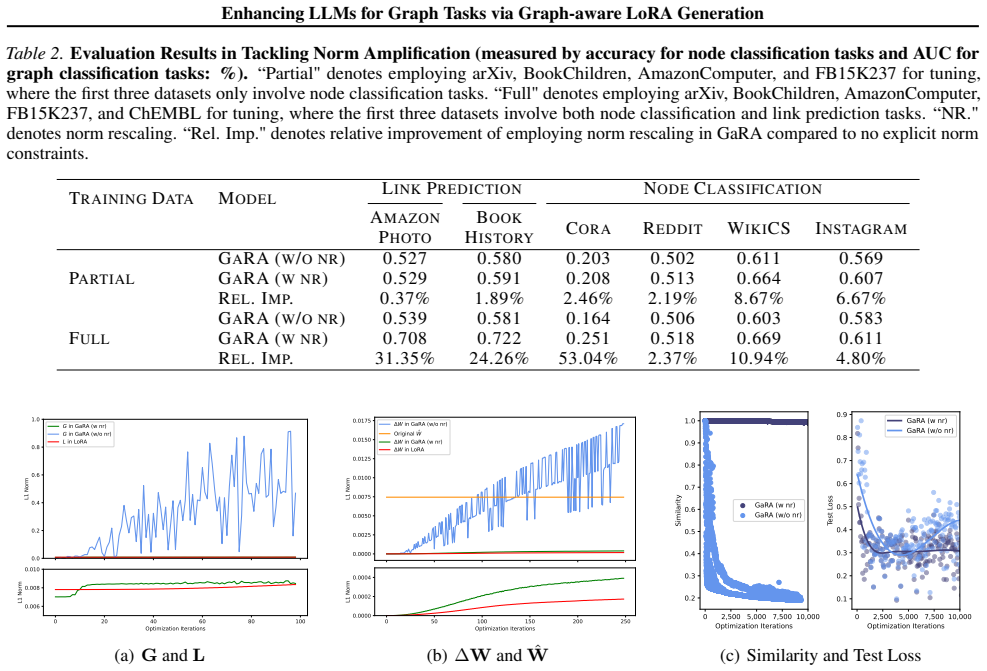
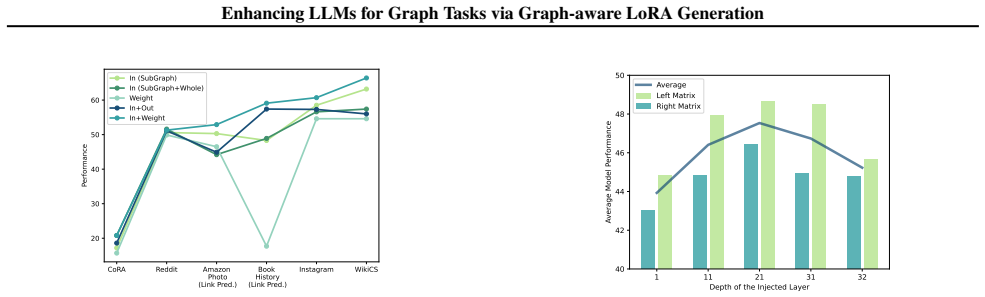
read the original abstract
Graph neural networks (GNNs) tightly couple their input-output parameters to dataset-specific feature spaces and target sets, exhibiting limited transferability across different datasets. In contrast, language models (LMs) generalize flexibly via a unified input-output interface, motivating recent attempts to adapt LMs to graph tasks. However, existing methods struggle to encode whole-graph information, leading to potential information loss and suboptimal graph understanding. In this work, we propose a novel weight-level information injection paradigm for adapting LMs to graph tasks. This paradigm injects whole-graph information by generating task-specific weight updates that interact directly with hidden representations. Instantiating this paradigm following low-rank adaptation (LoRA), we introduce GaRA, a Graph-aware LoRA generation model. GaRA constructs low-rank weight updates conditioned on the original graph structures and constrains the norm of the generated updates, thus injecting whole-graph information and avoiding the optimization bias in the weight generation. Empirical studies demonstrate that GaRA consistently outperforms baselines on zero-shot graph learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a weight-level information injection paradigm for adapting language models to graph tasks. It instantiates this as GaRA, which generates low-rank (LoRA) weight updates conditioned on the input graph structure and applies a norm constraint on the generated updates. The central claim is that this construction injects whole-graph information into the LLM hidden representations while avoiding the information loss and optimization bias of prior adaptation methods, leading to consistent outperformance on zero-shot graph learning tasks.
Significance. If the empirical claims hold under rigorous evaluation, the work would be significant for the graph+LLM literature by offering a concrete mechanism for direct whole-graph conditioning at the parameter-update level rather than through input augmentation or prompt engineering. The norm-constrained generation step is a potentially reusable design choice that could be tested on other adaptation settings.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the claim that the norm constraint 'avoids the optimization bias in the weight generation' is stated at a high level without a derivation, ablation, or analysis showing how the constraint interacts with the graph-conditioned generator to preserve whole-graph information. This is load-bearing for the central mechanistic claim.
- [Abstract] Abstract: the statement of 'consistent outperformance on zero-shot graph learning tasks' is presented without any quantitative results, dataset names, baseline descriptions, or statistical details. Because the soundness of the empirical support cannot be assessed, the central claim that GaRA solves the information-loss problem remains unevaluated.
minor comments (1)
- [§3] Notation for the graph-conditioned generator and the norm constraint should be introduced with explicit equations rather than prose descriptions to allow readers to verify the construction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the claim that the norm constraint 'avoids the optimization bias in the weight generation' is stated at a high level without a derivation, ablation, or analysis showing how the constraint interacts with the graph-conditioned generator to preserve whole-graph information. This is load-bearing for the central mechanistic claim.
Authors: We agree that the current presentation of the norm constraint's role is high-level. In the revised manuscript we will expand §3 to include a derivation of how the norm constraint regularizes the graph-conditioned generator, preventing collapse to solutions that discard structural information, and add an ablation study (with and without the constraint) to quantify its contribution to whole-graph information preservation. revision: yes
-
Referee: [Abstract] Abstract: the statement of 'consistent outperformance on zero-shot graph learning tasks' is presented without any quantitative results, dataset names, baseline descriptions, or statistical details. Because the soundness of the empirical support cannot be assessed, the central claim that GaRA solves the information-loss problem remains unevaluated.
Authors: We acknowledge that the abstract's high-level claim would benefit from concrete support for evaluation. We will revise the abstract to include key quantitative highlights (e.g., average gains, dataset names, and main baselines) while respecting length constraints, thereby allowing direct assessment of the empirical claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces GaRA as a novel weight-level injection paradigm for adapting LMs to graphs via graph-conditioned LoRA generation with norm constraints. The provided abstract and description contain no equations, derivations, or load-bearing self-citations. The central claim is presented as a design choice supported by empirical outperformance on zero-shot tasks, without any reduction of predictions or uniqueness results to fitted inputs or prior author work by construction. The derivation chain is self-contained at the level of high-level method description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Whole-graph information can be injected via generated weight updates that interact with hidden representations
invented entities (1)
-
GaRA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[2]
Meta AI , urldate =
Introducing. Meta AI , urldate =
-
[3]
Visual Perception by Large Language Model's Weights , booktitle =
Ma, Feipeng and Xue, Hongwei and Zhou, Yizhou and Wang, Guangting and Rao, Fengyun and Yan, Shilin and Zhang, Yueyi and Wu, Siying and Shou, Mike Zheng and Sun, Xiaoyan , year = 2024, volume =. Visual Perception by Large Language Model's Weights , booktitle =
2024
-
[4]
A Universal Approximation Theorem of Deep Neural Networks for Expressing Probability Distributions , booktitle =
Lu, Yulong and Lu, Jianfeng , year =. A Universal Approximation Theorem of Deep Neural Networks for Expressing Probability Distributions , booktitle =
-
[5]
2023 , publisher=
Matrix analysis and applied linear algebra , author=. 2023 , publisher=
2023
-
[6]
Instance
Fortin, Jean-Michel and Gamache, Olivier and Grondin, Vincent and Pomerleau, Fran. Instance. 2022 , pages =
2022
-
[7]
International Journal of Computer Vision , volume =
Zhang, Libo and Jiang, Lutao and Ji, Ruyi and Fan, Heng , year =. International Journal of Computer Vision , volume =
-
[8]
Chen, Mark and Tworek, Jerry and Jun, Heewoo et al. , year =. Evaluating. 2107.03374 , primaryclass =
-
[9]
Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt , year =. The
-
[10]
2009 , pages =
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and. 2009 , pages =
2009
-
[11]
Measuring
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , year =. Measuring. International
-
[12]
Diffusion
Klicpera, Johannes and. Diffusion. International. 2019 , volume =
2019
-
[13]
Adaptive
Chien, Eli and Peng, Jianhao and Li, Pan and Milenkovic, Olgica , year =. Adaptive. International
-
[14]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention Is All You Need , booktitle =. 2017 , pages =
2017
-
[15]
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , year =. Deep
-
[16]
, year =
Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E. , year =. Communications of the ACM , volume =
-
[17]
Predict Then
Gasteiger, Johannes and Bojchevski, Aleksandar and G. Predict Then. International. 2018 , address =
2018
-
[18]
Simplifying
Wu, Felix and Souza, Amauri and Zhang, Tianyi and Fifty, Christopher and Yu, Tao and Weinberger, Kilian , year =. Simplifying. International
-
[19]
Huang, Zhongyu and Wang, Yingheng and Li, Chaozhuo and He, Huiguang , year =. Going. International
-
[20]
and Tang, Jian , year =
Zhao, Jianan and Zhu, Zhaocheng and Galkin, Mikhail and Mostafa, Hesham and Bronstein, Michael M. and Tang, Jian , year =. Fully-Inductive. The
-
[21]
Hou, Zhenyu and He, Yufei and Cen, Yukuo and Liu, Xiao and Dong, Yuxiao and Kharlamov, Evgeny and Tang, Jie , year =. Proceedings of the. doi:10.1145/3543507.3583379 , urldate =
-
[22]
and Ventola, Pamela and Duncan, James S
Li, Xiaoxiao and Zhou, Yuan and Dvornek, Nicha and Zhang, Muhan and Gao, Siyuan and Zhuang, Juntang and Scheinost, Dustin and Staib, Lawrence H. and Ventola, Pamela and Duncan, James S. , year =. Medical Image Analysis , volume =
-
[23]
Li, Jintang and Wu, Ruofan and Sun, Wangbin and Chen, Liang and Tian, Sheng and Zhu, Liang and Meng, Changhua and Zheng, Zibin and Wang, Weiqiang , year =. What's. Proceedings of the 29th. doi:10.1145/3580305.3599546 , urldate =
-
[24]
Xia, Jun and Wu, Lirong and Chen, Jintao and Hu, Bozhen and Li, Stan Z. , year =. Proceedings of the. doi:10.1145/3485447.3512156 , urldate =
-
[25]
Graph Contrastive Learning with Augmentations , booktitle =
You, Yuning and Chen, Tianlong and Sui, Yongduo and Chen, Ting and Wang, Zhangyang and Shen, Yang , year =. Graph Contrastive Learning with Augmentations , booktitle =
-
[26]
Yu, Xingtong and Gong, Zechuan and Zhou, Chang and Fang, Yuan and Zhang, Hui , year =
-
[27]
Zhao, Jitao and Jin, Di and Ge, Meng and Shan, Lianze and Wang, Xin and He, Dongxiao and Feng, Zhiyong , year =. The
-
[28]
2019 , pages =
International. 2019 , pages =
2019
-
[29]
2017 , journal =
The Geometric Nature of Weights in Real Complex Networks , author =. 2017 , journal =
2017
-
[30]
Alon, Uri and Yahav, Eran , year =. On the. International. arxiv , langid =:2006.05205 , address =
arXiv 2006
-
[31]
Subgraph Neural Networks , booktitle =
Alsentzer, Emily and Finlayson, Samuel and Li, Michelle and Zitnik, Marinka , editor =. Subgraph Neural Networks , booktitle =. 2020 , volume =
2020
-
[32]
Learnable
Anonymous , year =. Learnable. Submitted to
-
[33]
2008 , journal =
Synchronization in Complex Networks , author =. 2008 , journal =
2008
-
[34]
Synchronization
Arenas, Alex and. Synchronization. 2006 , journal =
2006
-
[35]
Arora, Siddhant , year =. A. arXiv:2007.12374 [cs] , eprint =
arXiv 2007
-
[36]
Arvind, Vikraman and Fuhlbr. On. Fundamentals of. 2019 , pages =
2019
-
[37]
Advances in Neural Information Processing Systems , author =
Diffusion-. Advances in Neural Information Processing Systems , author =. 2016 , eprint =
2016
- [38]
-
[39]
Breaking the
Balcilar, Muhammet and Heroux, Pierre and Gauzere, Benoit and Vasseur, Pascal and Adam, Sebastien and Honeine, Paul , year =. Breaking the. Proceedings of the 38th
-
[40]
Balcilar, Muhammet and Renton, Guillaume and Heroux, Pierre and Gauzere, Benoit and Adam, Sebastien and Honeine, Paul , year =. Bridging the. arXiv:2003.11702 [cs, stat] , eprint =
arXiv 2003
-
[41]
Barcel. Graph. Advances in. 2021 , volume =
2021
-
[42]
Bastos, Anson and Nadgeri, Abhishek and Singh, Kuldeep and Kanezashi, Hiroki and Suzumura, Toyotaro and Mulang', Isaiah Onando , year =. How. Transactions on Machine Learning Research , issn =
-
[43]
Networks beyond Pairwise Interactions:
Battiston, Federico and Cencetti, Giulia and Iacopini, Iacopo and Latora, Vito and Lucas, Maxime and Patania, Alice and Young, Jean-Gabriel and Petri, Giovanni , year =. Networks beyond Pairwise Interactions:. Physics Reports , volume =
-
[44]
Beaini, Dominique and Passaro, Saro and L. Directional. 2020 , journal =. 2010.02863 , primaryclass =
arXiv 2020
-
[45]
Laplacian
Belkin, Mikhail and Niyogi, Partha , year =. Laplacian. Neural Computation , volume =
-
[46]
and Bahdanau, Dzmitry , year =
Bergen, Leon and O'Donnell, Timothy J. and Bahdanau, Dzmitry , year =. Systematic. Advances in
-
[47]
Bessadok, Alaa and Mahjoub, Mohamed Ali and Rekik, Islem , year =. Graph. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[48]
and Maron, Haggai , year =
Bevilacqua, Beatrice and Frasca, Fabrizio and Lim, Derek and Srinivasan, Balasubramaniam and Cai, Chen and Balamurugan, Gopinath and Bronstein, Michael M. and Maron, Haggai , year =. Equivariant. International
-
[49]
Bi, Wendong and Du, Lun and Fu, Qiang and Wang, Yanlin and Han, Shi and Zhang, Dongmei , year =. Make
-
[50]
Specformer:
Bo, Deyu and Shi, Chuan and Wang, Lele and Liao, Renjie , year =. Specformer:. The
-
[51]
and Latora, V
Boccaletti, S. and Latora, V. and Moreno, Y. and Chavez, M. and Hwang, D. -U. , year =. Complex Networks:. Physics Reports , volume =
-
[52]
Weisfeiler and
Bodnar, Cristian and Frasca, Fabrizio and Otter, Nina and Wang, Yu Guang and Li. Weisfeiler and. Advances in. 2021 , urldate =
2021
-
[53]
Bodnar, Cristian and Frasca, Fabrizio and Wang, Yuguang and Otter, Nina and Montufar, Guido F. and Li. Weisfeiler and. Proceedings of the 38th. 2021 , pages =
2021
-
[54]
Borgwardt, Karsten and Ghisu, Elisabetta and. Graph. 2020 , journal =. arxiv , langid =:2011.03854 , primaryclass =
arXiv 2020
-
[55]
Improving
Bouritsas, Giorgos and Frasca, Fabrizio and Zafeiriou, Stefanos P and Bronstein, Michael , year =. Improving. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[56]
Partition and
Bouritsas, Giorgos and Loukas, Andreas and Karalias, Nikolaos and Bronstein, Michael , year =. Partition and. Advances in
-
[57]
2022 , journal =
Flow Stability for Dynamic Community Detection , author =. 2022 , journal =
2022
-
[58]
and Welling, Max , year =
Brandstetter, Johannes and Worrall, Daniel E. and Welling, Max , year =. Message. International
-
[59]
Master Stability Functions Reveal Diffusion-Driven Pattern Formation in Networks , author =. 2018 , journal =. doi:10.1103/PhysRevE.97.032307 , urldate =
-
[60]
IEEE Signal Processing Magazine , author =
Bronstein, Michael M. and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , year =. Geometric Deep Learning: Going beyond. IEEE Signal Processing Magazine , volume =. doi:10.1109/MSP.2017.2693418 , urldate =. arxiv , langid =:1611.08097 , pages =
-
[61]
and Bruna, Joan and Cohen, Taco and Veli
Bronstein, Michael M. and Bruna, Joan and Cohen, Taco and Veli. Geometric. 2021 , journal =. arxiv , langid =:2104.13478 , primaryclass =
Pith/arXiv arXiv 2021
-
[62]
Bruna, Joan and Zaremba, Wojciech and Szlam, Arthur and LeCun, Yann , year =. Spectral. arXiv:1312.6203 [cs] , eprint =
-
[63]
Cai, Chen and Hy, Truong Son and Yu, Rose and Wang, Yusu , year =. On the. Proceedings of the 40th
-
[64]
Cai, Chen and Wang, Yusu , year =. A. arXiv:2006.13318 [cs, stat] , eprint =
arXiv 2006
-
[65]
arXiv:2103.00959 [cs, stat] , eprint =
Cen, Yukuo and Hou, Zhenyu and Wang, Yan and Chen, Qibin and Luo, Yizhen and Yao, Xingcheng and Zeng, Aohan and Guo, Shiguang and Yang, Yang and Zhang, Peng and Dai, Guohao and Wang, Yu and Zhou, Chang and Yang, Hongxia and Tang, Jie , year =. arXiv:2103.00959 [cs, stat] , eprint =
-
[66]
, year =
Chamberlain, Benjamin Paul and Rowbottom, James and Eynard, Davide and Giovanni, Francesco Di and Dong, Xiaowen and Bronstein, Michael M. , year =. Beltrami. Advances in
-
[67]
and Bronstein, Michael and Webb, Stefan and Rossi, Emanuele , year =
Chamberlain, Ben and Rowbottom, James and Gorinova, Maria I. and Bronstein, Michael and Webb, Stefan and Rossi, Emanuele , year =. Proceedings of the 38th
-
[68]
and Hansmire, Max , year =
Chamberlain, Benjamin Paul and Shirobokov, Sergey and Rossi, Emanuele and Frasca, Fabrizio and Markovich, Thomas and Hammerla, Nils Yannick and Bronstein, Michael M. and Hansmire, Max , year =. Graph. The
-
[69]
and Hansmire, Max , year =
Chamberlain, Benjamin Paul and Shirobokov, Sergey and Rossi, Emanuele and Frasca, Fabrizio and Markovich, Thomas and Hammerla, Nils Yannick and Bronstein, Michael M. and Hansmire, Max , year =. Graph. International
-
[70]
Structure-
Chang, Jianlong and Gu, Jie and Wang, Lingfeng and MENG,. Structure-. Advances in. 2018 , volume =
2018
-
[71]
Proceedings of the 38th
Chanpuriya, Sudhanshu and Musco, Cameron and Sotiropoulos, Konstantinos and Tsourakakis, Charalampos , year =. Proceedings of the 38th
-
[72]
Chen, Zhiqian and Chen, Fanglan and Zhang, Lei and Ji, Taoran and Fu, Kaiqun and Zhao, Liang and Chen, Feng and Lu, Chang-Tien , year =. Bridging the. arXiv:2002.11867 [cs, stat] , eprint =
arXiv 2002
-
[73]
Chen, Zhengdao and Chen, Lei and Villar, Soledad and Bruna, Joan , year =. Can. Advances in
-
[74]
On the Equivalence between Graph Isomorphism Testing and Function Approximation with
Chen, Zhengdao and Villar, Soledad and Chen, Lei and Bruna, Joan , year =. On the Equivalence between Graph Isomorphism Testing and Function Approximation with. Advances in
-
[75]
FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling
Chen, Jie and Ma, Tengfei and Xiao, Cao , year =. doi:10.48550/arXiv.1801.10247 , urldate =. 1801.10247 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1801.10247
-
[76]
Chen, Haochen and Perozzi, Bryan and Hu, Yifan and Skiena, Steven , year =. Proceedings of the. doi:10.1609/aaai.v32i1.11849 , urldate =
-
[77]
Chen, Kai and Niu, Meng and Chen, Qingcai , year =. A. arXiv:2012.11960 [cs] , eprint =
arXiv 2012
-
[78]
Measuring and
Chen, Deli and Lin, Yankai and Li, Wei and Li, Peng and Zhou, Jie and Sun, Xu , year =. Measuring and. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[79]
Chen, Weiqi and Chen, Ling and Xie, Yu and Cao, Wei and Gao, Yusong and Feng, Xiaojie , year =. Multi-. Proceedings of the 34th. doi:10/gk9mtt , urldate =
-
[80]
International
Chen, Jinsong and Gao, Kaiyuan and Li, Gaichao and He, Kun , year =. International
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.