Efficient Multimodal Clinical Question Answering for Pulmonary Embolism Risk Assessment
Pith reviewed 2026-06-26 11:08 UTC · model grok-4.3
The pith
Compact multimodal models perform better on pulmonary embolism tasks when both CT images and electronic health records are available.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the INSPECT dataset, models such as Gemma4 E4B and Gemma4 E2B achieve stronger results in the CTPA+EHR setting than in single-modality conditions, with diagnosis tasks outperforming prognostic tasks; this pattern indicates that compact multimodal models hold potential for early-stage PE risk detection and explanation.
What carries the argument
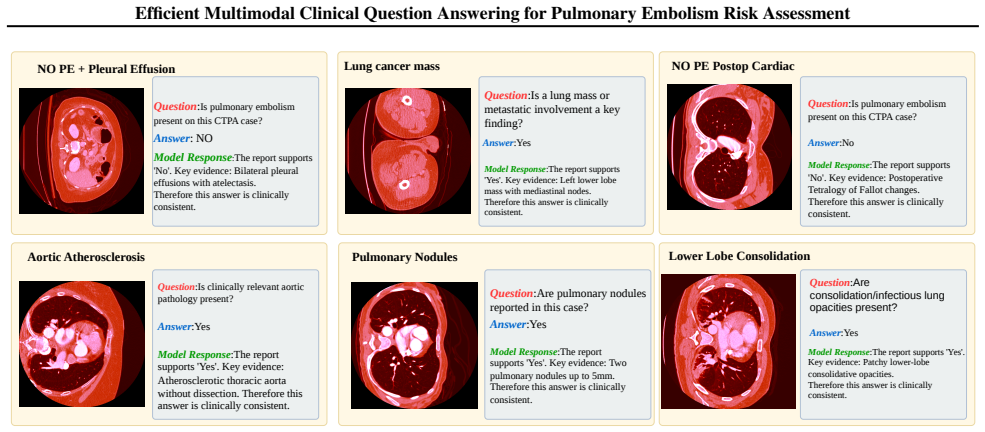
Eight structured clinical question-answering tasks evaluated across CTPA-Only, EHR-Only, and CTPA+EHR input combinations with zero-shot and few-shot prompting.
If this is right
- Combining CTPA and EHR inputs improves model performance over either modality alone.
- Diagnosis tasks reach higher accuracy than prognostic tasks such as readmission prediction.
- Efficient models show their strongest results under the combined CTPA+EHR condition.
- The observed pattern supports use of compact multimodal models for early PE risk assessment.
Where Pith is reading between the lines
- The same task formulation could be applied to other conditions that combine imaging with longitudinal records, such as heart failure.
- Real-world deployment would require testing whether the QA format integrates into existing radiology reporting systems.
- If the advantage of combined inputs holds across model families, it would favor multimodal training over separate unimodal pipelines.
Load-bearing premise
The eight chosen QA tasks and the zero/few-shot prompting setups are sufficient to show the true capabilities of the models without further controls for model size or prompt design.
What would settle it
A controlled experiment in which larger non-multimodal models or differently engineered prompts match or exceed the reported performance on the same eight tasks would undermine the claim that compact multimodal models are particularly promising.
Figures
read the original abstract
Pulmonary embolism (PE) is a high risk cardiopulmonary condition whose management requires both timely diagnosis and reliable assessment of future clinical risk. Because PE care routinely combines computed tomography pulmonary angiography (CTPA), radiology interpretation, and longitudinal electronic health record (EHR) evidence, it provides a clinically meaningful setting for evaluating compact multimodal language models. In this work, we build a benchmark using efficient multimodal large language models (MLLMs) on INSPECT, a multimodal PE dataset containing 23,248 CTPA studies from 19,402 patients. We formulate eight diagnostic and prognostic tasks as structured clinical question answering problems and evaluate on typical efficient MLLMs under CTPA-Only, EHR-Only, and CTPA+EHR settings with zero-shot and few-shot prompting. Results show that Gemma4 E4B and Gemma4 E2B perform more strongly when EHR evidence is available, especially under CTPA+EHR input. Task level analysis further shows that PE diagnosis achieves higher performance than prognostic tasks, particularly readmission prediction. These observations suggest that compact multimodal models have the great potential in early stage PE risk detection and explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark for evaluating compact multimodal large language models (MLLMs) on pulmonary embolism (PE) risk assessment using the INSPECT dataset of 23,248 CTPA studies. It formulates eight diagnostic and prognostic tasks as clinical QA problems and evaluates models such as Gemma4 E4B and E2B under CTPA-only, EHR-only, and combined settings with zero- and few-shot prompting. The central claim is that these efficient models show stronger performance when EHR evidence is added (especially in CTPA+EHR), that diagnostic tasks outperform prognostic ones (e.g., readmission prediction), and that compact MLLMs therefore have great potential for early-stage PE detection and explanation.
Significance. If the empirical results were supported by absolute metrics, statistical tests, and appropriate baselines, the work could usefully demonstrate the viability of parameter-efficient multimodal models for a clinically relevant multimodal task where both imaging and longitudinal records matter. The creation of structured QA tasks on a large PE dataset is a concrete contribution that could support future reproducible evaluations.
major comments (3)
- [Abstract] Abstract: only directional statements are supplied ("perform more strongly", "higher performance", "great potential") with no absolute accuracy/F1 scores, confidence intervals, statistical significance tests, or data tables. This prevents any assessment of whether the observed trends are large enough to support the clinical-potential claim.
- [Abstract] Abstract / evaluation setup: no non-LLM baselines (rule-based PE risk scores such as Wells or Geneva criteria, or standard tabular EHR classifiers) are reported. Without these controls it is impossible to determine whether any advantage is attributable to the compact MLLMs themselves rather than to the QA task formulation or prompting.
- [Abstract] Abstract: the eight QA tasks and zero/few-shot CTPA/EHR protocols are presented without ablations on prompt variants, model-scale controls, or confounding factors. Consequently the directional trends cannot be confidently attributed to the multimodal compact models rather than setup artifacts.
minor comments (2)
- [Abstract] The manuscript should include a table or figure summarizing the eight QA tasks with their exact question templates and label definitions.
- Dataset statistics (patient demographics, label distributions per task) are referenced but not shown; these should appear in a dedicated table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation design. We address each major comment below, indicating revisions where appropriate to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: only directional statements are supplied ("perform more strongly", "higher performance", "great potential") with no absolute accuracy/F1 scores, confidence intervals, statistical significance tests, or data tables. This prevents any assessment of whether the observed trends are large enough to support the clinical-potential claim.
Authors: We agree that the abstract would benefit from quantitative support. The full manuscript contains the underlying metrics; we will revise the abstract to report representative accuracy and F1 scores (with confidence intervals) for the main CTPA+EHR setting and key tasks. revision: yes
-
Referee: [Abstract] Abstract / evaluation setup: no non-LLM baselines (rule-based PE risk scores such as Wells or Geneva criteria, or standard tabular EHR classifiers) are reported. Without these controls it is impossible to determine whether any advantage is attributable to the compact MLLMs themselves rather than to the QA task formulation or prompting.
Authors: The work centers on benchmarking compact MLLMs for multimodal clinical QA rather than claiming superiority over all clinical tools. Wells and Geneva scores apply primarily to diagnosis and do not map directly to the prognostic tasks. We will nevertheless add a simple tabular EHR baseline (logistic regression on structured features) in the revised experiments section for context. revision: yes
-
Referee: [Abstract] Abstract: the eight QA tasks and zero/few-shot CTPA/EHR protocols are presented without ablations on prompt variants, model-scale controls, or confounding factors. Consequently the directional trends cannot be confidently attributed to the multimodal compact models rather than setup artifacts.
Authors: The manuscript already details the task formulations and prompting protocols. To address potential setup artifacts, we will include additional ablations on prompt phrasing and a model-scale comparison (E4B vs. E2B) in the revised results section. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential fits
full rationale
The paper formulates eight QA tasks on the INSPECT dataset and reports directional performance trends for Gemma4 models under different input settings and prompting regimes. No equations, fitted parameters, uniqueness theorems, or derivation chains appear in the provided text. Conclusions rest on observed empirical patterns (EHR improves results; diagnosis outperforms prognosis) that are directly testable against external baselines or larger models, with no reduction of outputs to inputs by construction. Self-citation is absent from the abstract and described content, so the evaluation chain remains independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
European Heart Journal , volume=
2019 ESC Guidelines for the diagnosis and management of acute pulmonary embolism developed in collaboration with the European Respiratory Society (ERS) , author=. European Heart Journal , volume=
2019
-
[2]
BMJ Open , volume=
Clinical characteristics associated with diagnostic delay of pulmonary embolism in primary care: a retrospective observational study , author=. BMJ Open , volume=
-
[3]
npj Digital Medicine , volume=
Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines , author=. npj Digital Medicine , volume=
-
[4]
Scientific Reports , volume=
Multimodal fusion with deep neural networks for leveraging CT imaging and electronic health record: a case study in pulmonary embolism detection , author=. Scientific Reports , volume=
-
[5]
arXiv preprint arXiv:2111.11665 , year=
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR , author=. arXiv preprint arXiv:2111.11665 , year=
-
[6]
Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis , author=. Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[7]
Archives of Internal Medicine , volume=
Pulmonary embolism mortality in the United States, 1979--1998: an analysis using multiple-cause mortality data , author=. Archives of Internal Medicine , volume=. 2003 , publisher=
1979
-
[8]
European Journal of Internal Medicine , volume=
Delay and misdiagnosis in sub-massive and non-massive acute pulmonary embolism , author=. European Journal of Internal Medicine , volume=. 2010 , publisher=
2010
-
[9]
BMJ Open , volume=
Clinical characteristics associated with diagnostic delay of pulmonary embolism in primary care: a retrospective observational study , author=. BMJ Open , volume=. 2017 , publisher=
2017
-
[10]
Journal of Thrombosis and Haemostasis , volume=
Diagnosing pulmonary embolism: running after the decreasing prevalence of cases among suspected patients , author=. Journal of Thrombosis and Haemostasis , volume=. 2004 , publisher=
2004
-
[11]
The British Journal of Radiology , volume=
The influence of clinical information on the reporting of CT by radiologists , author=. The British Journal of Radiology , volume=. 2000 , publisher=
2000
-
[12]
Journal of the American College of Radiology , volume=
Accuracy of information on imaging requisitions: does it matter? , author=. Journal of the American College of Radiology , volume=. 2007 , publisher=
2007
-
[13]
Scientific Reports , volume=
Multimodal fusion with deep neural networks for leveraging CT imaging and electronic health record: a case-study in pulmonary embolism detection , author=. Scientific Reports , volume=. 2020 , publisher=
2020
-
[14]
Radiology: Artificial Intelligence , volume=
The RSNA pulmonary embolism CT dataset , author=. Radiology: Artificial Intelligence , volume=. 2021 , publisher=
2021
-
[15]
Artificial Intelligence in Medicine , volume=
Comparative effectiveness of convolutional neural network (CNN) and recurrent neural network (RNN) architectures for radiology text report classification , author=. Artificial Intelligence in Medicine , volume=. 2019 , publisher=
2019
-
[16]
arXiv preprint arXiv:2201.11838 , year=
Clinical-Longformer and Clinical-BigBird: Transformers for long clinical sequences , author=. arXiv preprint arXiv:2201.11838 , year=
-
[17]
Scientific reports , volume=
Deep learning for pulmonary embolism detection on computed tomography pulmonary angiogram: a systematic review and meta-analysis , author=. Scientific reports , volume=. 2021 , publisher=
2021
-
[18]
European radiology , volume=
Evaluation of acute pulmonary embolism and clot burden on CTPA with deep learning , author=. European radiology , volume=. 2020 , publisher=
2020
-
[19]
NPJ digital medicine , volume=
PENet—a scalable deep-learning model for automated diagnosis of pulmonary embolism using volumetric CT imaging , author=. NPJ digital medicine , volume=. 2020 , publisher=
2020
-
[20]
La radiologia medica , volume=
Prognostic value of CT pulmonary angiography parameters in acute pulmonary embolism , author=. La radiologia medica , volume=. 2021 , publisher=
2021
-
[21]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[22]
Towards visual question answering on pathology images , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) , pages=
-
[23]
2021 IEEE 18th international symposium on biomedical imaging (ISBI) , pages=
Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering , author=. 2021 IEEE 18th international symposium on biomedical imaging (ISBI) , pages=. 2021 , organization=
2021
-
[24]
Machine learning for health (ML4H) , pages=
Med-flamingo: a multimodal medical few-shot learner , author=. Machine learning for health (ML4H) , pages=. 2023 , organization=
2023
-
[25]
Advances in Neural Information Processing Systems , volume=
Llava-med: Training a large language-and-vision assistant for biomedicine in one day , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[27]
Nejm Ai , volume=
Towards generalist biomedical AI , author=. Nejm Ai , volume=. 2024 , publisher=
2024
-
[28]
Nature medicine , volume=
Privacy in the age of medical big data , author=. Nature medicine , volume=. 2019 , publisher=
2019
-
[29]
Communications medicine , volume=
The future landscape of large language models in medicine , author=. Communications medicine , volume=. 2023 , publisher=
2023
-
[30]
International Journal of Emerging Trends in Computer Science and Information Technology , pages=
AI and Data Privacy in Healthcare: Compliance with HIPAA, GDPR, and emerging regulations , author=. International Journal of Emerging Trends in Computer Science and Information Technology , pages=
-
[31]
NPJ digital medicine , volume=
Vision-language model for report generation and outcome prediction in CT pulmonary angiogram , author=. NPJ digital medicine , volume=. 2025 , publisher=
2025
-
[32]
arXiv preprint arXiv:2509.01554 , year=
Unified Supervision For Vision-Language Modeling in 3D Computed Tomography , author=. arXiv preprint arXiv:2509.01554 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.