SCOPE: Evolving Symbolic World for Planning in Open-Ended Environments
Pith reviewed 2026-06-26 10:55 UTC · model grok-4.3
The pith
SCOPE evolves incomplete symbolic environment models using execution feedback to enable more reliable long-horizon planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
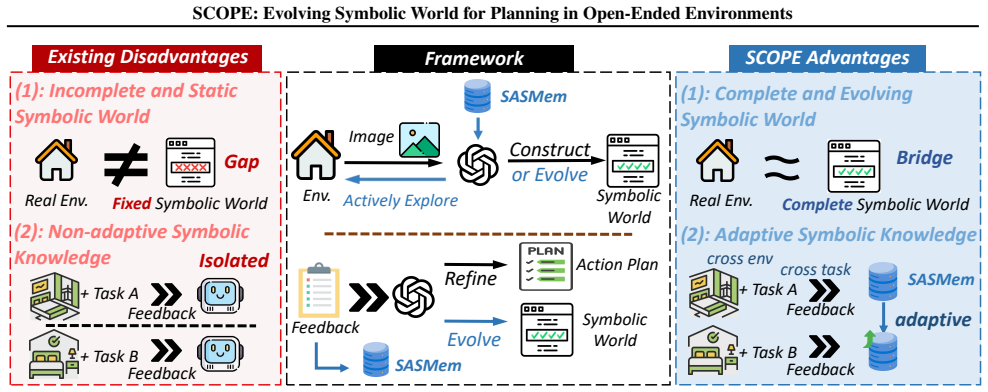
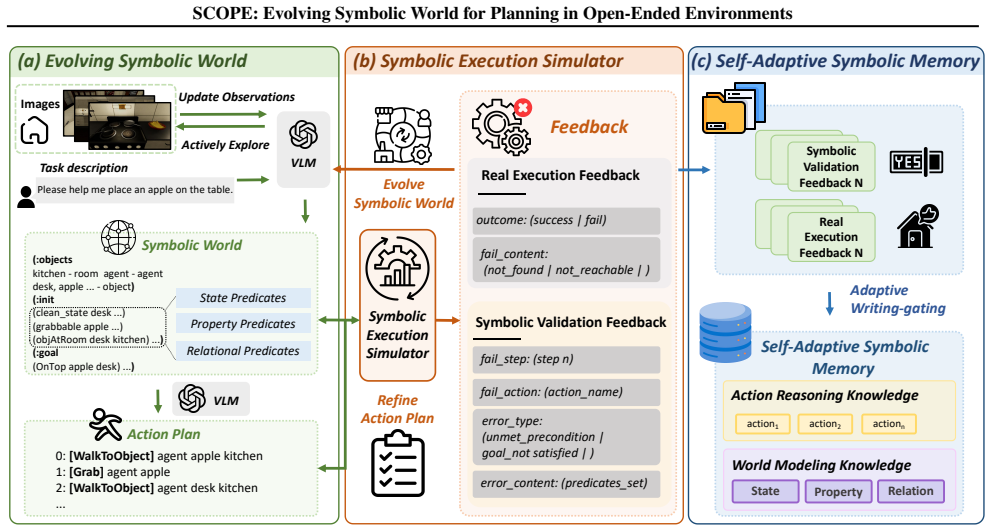
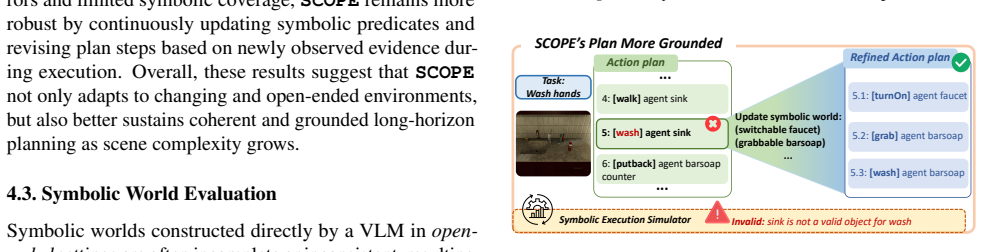
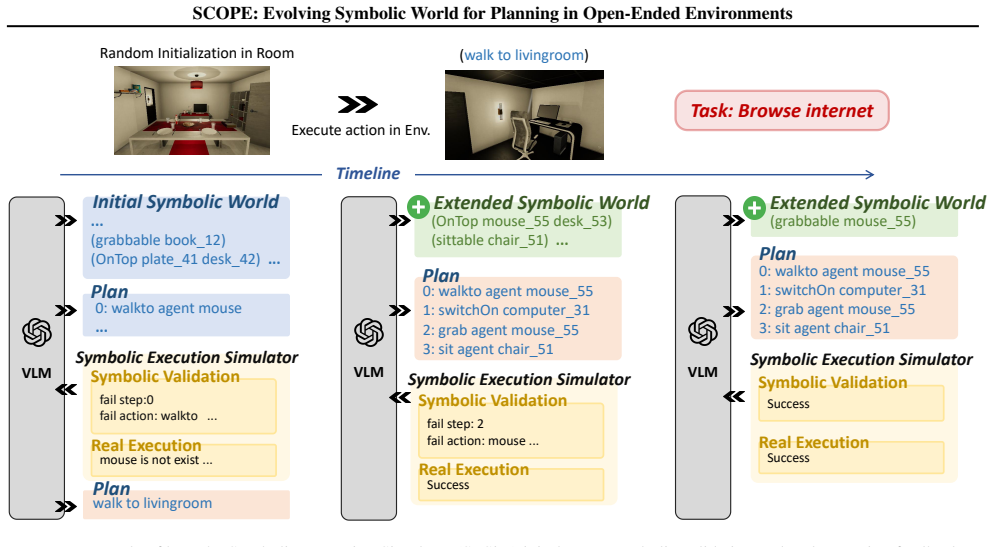
SCOPE is a self-adaptive symbolic planning framework consisting of a Symbolic Execution Simulator that validates and executes plans to refine them and evolve the symbolic world, and a Self-Adaptive Symbolic Memory that distills feedback into evolving symbolic knowledge for enhanced long-horizon planning.
What carries the argument
The Symbolic Execution Simulator (SESim) for validation and real-execution feedback paired with the Self-Adaptive Symbolic Memory (SASMem) that converts that feedback into updated symbolic knowledge.
If this is right
- The symbolic world grows more complete as planning cycles accumulate.
- Plan success rates rise when the environment is perturbed after initial modeling.
- Grounding and adaptability improve across different embodied tasks without extra tuning.
Where Pith is reading between the lines
- Agents could begin with sparse initial symbols and build usable models through repeated interaction rather than requiring exhaustive upfront perception.
- The same feedback-driven update loop could be tested in non-embodied planning settings that also rely on incomplete symbolic descriptions.
- If distilled knowledge begins to conflict with new observations, an explicit consistency check would be needed beyond what is described.
Load-bearing premise
Feedback from symbolic validation and real execution can be reliably distilled into evolving symbolic knowledge that improves future planning without introducing new inconsistencies or requiring domain-specific tuning.
What would settle it
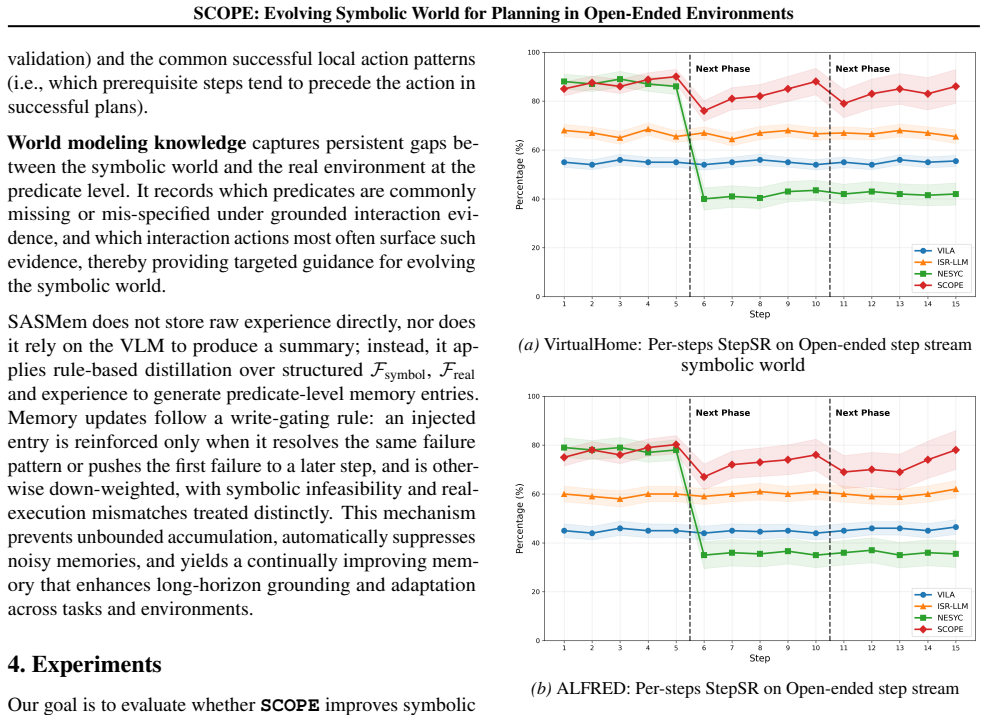
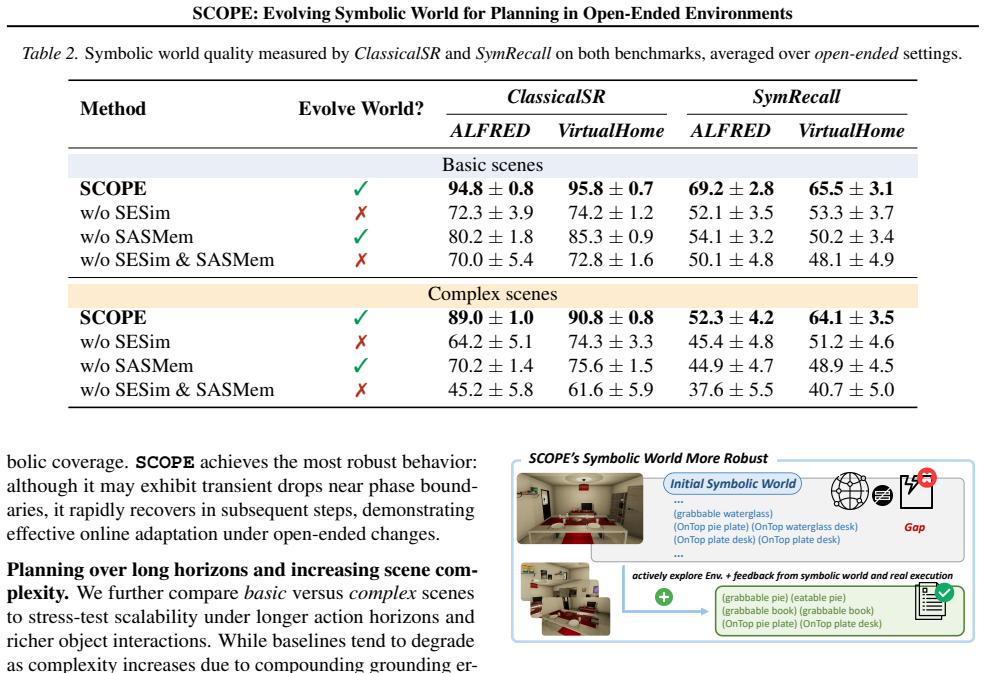
Measure the completeness of the symbolic world and plan success rates under perturbations after repeated cycles of planning, validation, and memory updates; if neither quantity increases, the central claim does not hold.
Figures

read the original abstract
Recent works have explored integrating Vision-Language Models (VLMs) with classical planners that rely on symbolic representations of planning problems to generate long-horizon plans for complex embodied tasks. However, in open-ended environments, these symbolic representations obtained from perception are often incomplete, leading to suboptimal performance. To address this, we introduce SCOPE, a self-adaptive symbolic planning framework that supports refining action plans and evolving the symbolic world, i.e., the symbolic representations of open-ended environments. SCOPE comprises two synergistic modules: a Symbolic Execution Simulator (SESim) that conducts symbolic validation and real execution of action plans, leveraging the feedback to refine the plans and evolve the symbolic world; and a Self-Adaptive Symbolic Memory (SASMem) that further distills feedback into evolving symbolic knowledge to enhance long-horizon planning and modeling of the symbolic world. Experiments in open-ended environments show that SCOPE significantly improves the completeness of the symbolic world, the success rate of plans under environment perturbations, and cross-task grounding and adaptability across diverse embodied scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCOPE, a self-adaptive symbolic planning framework for open-ended embodied environments. It consists of two modules: Symbolic Execution Simulator (SESim), which performs symbolic validation and real execution of plans while using feedback to refine plans and evolve the symbolic world, and Self-Adaptive Symbolic Memory (SASMem), which distills execution feedback into evolving symbolic knowledge. The central empirical claim is that SCOPE improves completeness of the symbolic world, success rates of plans under perturbations, and cross-task grounding/adaptability compared to prior VLM+classical planner approaches.
Significance. If the reported gains hold under rigorous controls, the framework offers a concrete mechanism for maintaining and updating symbolic state representations from mixed symbolic/real feedback. This addresses a recognized bottleneck in long-horizon planning for dynamic environments and could be adopted in embodied AI pipelines that already combine VLMs with PDDL-style planners.
minor comments (2)
- The abstract describes SESim and SASMem at a high level but does not specify the representation language, consistency invariants maintained during evolution, or the exact distillation procedure; these details are needed to evaluate whether the evolving symbolic world remains sound.
- No information is provided on the choice of baselines, number of environments, statistical tests, or ablation isolating the contribution of feedback distillation versus plan refinement.
Simulated Author's Rebuttal
We thank the referee for their summary of our manuscript on SCOPE and for noting its potential relevance to maintaining symbolic representations in dynamic embodied environments. The recommendation is marked 'uncertain,' but the report contains no specific major comments. We therefore provide no point-by-point responses and stand ready to address any concrete concerns the referee may wish to raise.
Circularity Check
No significant circularity detected
full rationale
The paper presents a high-level framework description of SCOPE with SESim and SASMem modules for evolving symbolic representations in planning tasks. No equations, derivations, fitted parameters, or mathematical claims are present in the abstract or provided text. The central claims rest on experimental improvements in completeness and success rates rather than any self-referential definitions, predictions derived from inputs by construction, or load-bearing self-citations. The framework is described conceptually without reducing any result to its own inputs, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y ., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Akakzia, A., Colas, C., Oudeyer, P.-Y ., Chetouani, M., and Sigaud, O. Grounding language to autonomously- acquired skills via goal generation.arXiv preprint arXiv:2006.07185,
-
[4]
Ao, S., Salim, F. D., and Khan, S. Emac+: Embodied multimodal agent for collaborative planning with vlm+ llm.arXiv preprint arXiv:2505.19905,
-
[5]
Choi, W., Park, J., Ahn, S., Lee, D., and Woo, H. Nesyc: A neuro-symbolic continual learner for complex embodied tasks in open domains.arXiv preprint arXiv:2503.00870,
-
[6]
PaLM-E: An Embodied Multimodal Language Model
URLhttps://arxiv.org/abs/2303.03378. Du, Y ., Liu, Z., Li, J., and Zhao, W. X. A survey of vision-language pre-trained models.arXiv preprint arXiv:2202.10936,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355,
Fung, P., Bachrach, Y ., Celikyilmaz, A., Chaudhuri, K., Chen, D., Chung, W., Dupoux, E., J´egou, H., Lazaric, A., Majumdar, A., et al. Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355,
-
[8]
Hu, M., Chen, T., Zou, Y ., Lei, Y ., Chen, Q., Li, M., Mu, Y ., Zhang, H., Shao, W., and Luo, P. Text2world: Bench- marking large language models for symbolic world model generation.arXiv preprint arXiv:2502.13092,
-
[9]
Hu, Y ., Lin, F., Zhang, T., Yi, L., and Gao, Y . Look before you leap: Unveiling the power of gpt-4v in robotic vision- language planning.arXiv preprint arXiv:2311.17842,
-
[10]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Huang, W., Abbeel, P., Pathak, D., and Mordatch, I. Lan- guage models as zero-shot planners: Extracting action- able knowledge for embodied agents. InInternational conference on machine learning, pp. 9118–9147. PMLR, 2022a. Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tompson, J., Mordatch, I., Chebotar, Y ., et al. Inner mon...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Code as Policies: Language Model Programs for Embodied Control
Jiang, Y ., Gu, S. S., Murphy, K. P., and Finn, C. Language as an abstraction for hierarchical deep reinforcement learn- ing.Advances in neural information processing systems, 32, 2019a. Jiang, Y .-q., Zhang, S.-q., Khandelwal, P., and Stone, P. Task planning in robotics: an empirical comparison of pddl-and asp-based systems.Frontiers of Information Techn...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Liu, B., Jiang, Y ., Zhang, X., Liu, Q., Zhang, S., Biswas, J., and Stone, P. Llm+ p: Empowering large language models with optimal planning proficiency.arXiv preprint arXiv:2304.11477,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mao, J., Gan, C., Kohli, P., Tenenbaum, J. B., and Wu, J. The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision.arXiv preprint arXiv:1904.12584,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[14]
Nair, S. and Finn, C. Hierarchical foresight: Self-supervised learning of long-horizon tasks via visual subgoal genera- tion.arXiv preprint arXiv:1909.05829,
-
[15]
S., Kumar, N., Lozano-P´erez, T., and Kaelbling, L
Silver, T., Hariprasad, V ., Shuttleworth, R. S., Kumar, N., Lozano-P´erez, T., and Kaelbling, L. P. Pddl planning with pretrained large language models. InNeurIPS 2022 foundation models for decision making workshop,
2022
-
[16]
S., Feng, J., Ko- rneev, N., Tenenbaum, J
Wong, L., Mao, J., Sharma, P., Siegel, Z. S., Feng, J., Ko- rneev, N., Tenenbaum, J. B., and Andreas, J. Learning adaptive planning representations with natural language guidance.arXiv preprint arXiv:2312.08566,
-
[17]
Wu, Q., Zhao, H., Saxon, M., Bui, T., Wang, W. Y ., Zhang, Y ., and Chang, S. Vsp: Assessing the dual challenges of perception and reasoning in spatial planning tasks for vlms.arXiv preprint arXiv:2407.01863,
-
[18]
Xiong, S., Zhou, J., Liu, Z., and Su, Y . Symplanner: Delib- erate planning in language models with symbolic repre- sentation.arXiv preprint arXiv:2505.01479,
-
[19]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
10 SCOPE: Evolving Symbolic World for Planning in Open-Ended Environments Zeng, A., Attarian, M., Ichter, B., Choromanski, K., Wong, A., Welker, S., Tombari, F., Purohit, A., Ryoo, M., Sind- hwani, V ., et al. Socratic models: Composing zero-shot multimodal reasoning with language.arXiv preprint arXiv:2204.00598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Zhang, C., Li, Z., and Yuan, W. V ote-tree-planner: Optimiz- ing execution order in llm-based task planning pipeline via voting.arXiv preprint arXiv:2502.09749,
-
[22]
Grounding classical task planners via vision-language models.arXiv preprint arXiv:2304.08587,
Zhang, X., Ding, Y ., Amiri, S., Yang, H., Kaminski, A., Esselink, C., and Zhang, S. Grounding classical task planners via vision-language models.arXiv preprint arXiv:2304.08587,
-
[23]
Isr-llm: Iter- ative self-refined large language model for long-horizon sequential task planning
Zhou, Z., Song, J., Yao, K., Shu, Z., and Ma, L. Isr-llm: Iter- ative self-refined large language model for long-horizon sequential task planning. In2024 IEEE International Con- ference on Robotics and Automation (ICRA), pp. 2081–
2081
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.