PolicyTrim: Boosting Intrinsic Policy Efficiency of Vision-Language-Action Models
Pith reviewed 2026-06-26 10:24 UTC · model grok-4.3
The pith
PolicyTrim post-trains VLA models with reinforcement learning to extend reliable action chunk lengths and cut redundant physical steps, yielding up to 5.83 times faster end-to-end deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
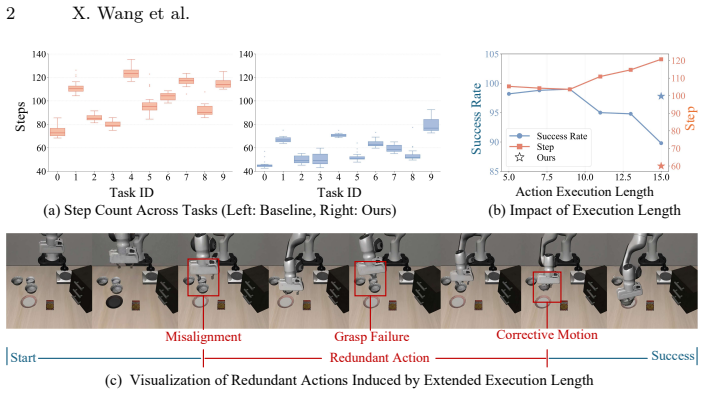
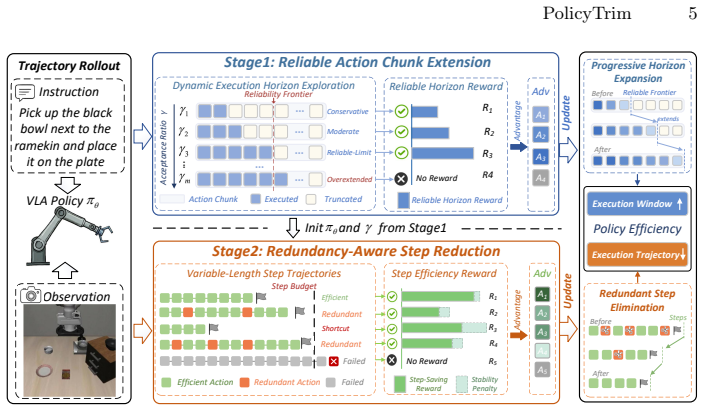
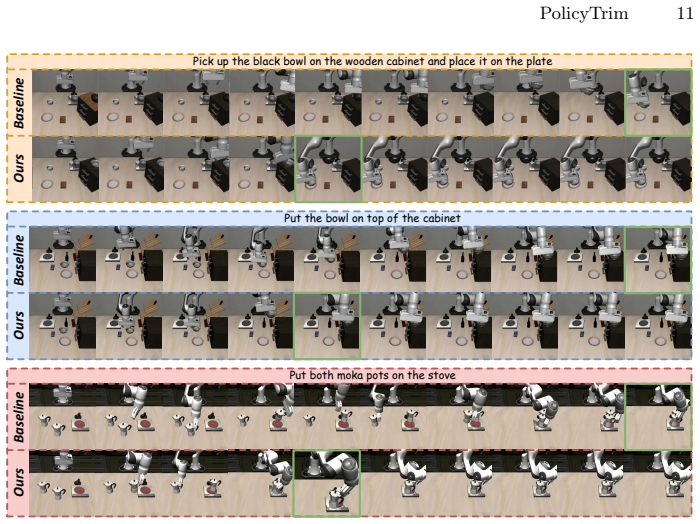
PolicyTrim is a reinforcement learning post-training framework that improves intrinsic policy efficiency in VLA models. It uses a dynamic exploration strategy to reward successful completion of longer executable action chunks, pushing the reliable prediction horizon farther. It also applies a redundancy-aware reward that favors task success with fewer physical steps and penalizes unreproducible shortcuts. These changes together raise action chunk utilization by a factor of three, cut physical execution steps by 51.4 percent, and produce up to 5.83 times faster end-to-end deployment without lowering task success rates.
What carries the argument
PolicyTrim, a reinforcement learning post-training framework that combines a dynamic exploration strategy for longer reliable chunks with a redundancy-aware reward for fewer physical steps.
If this is right
- Fewer model calls per task directly lowers the compute budget needed for real-time robotic control.
- Longer reliable chunks allow the model to plan farther ahead without repeated inference.
- Reduced physical steps shorten overall task duration while preserving the same success rate.
- The same post-training recipe can be applied to multiple existing VLA architectures without architecture changes.
Where Pith is reading between the lines
- The method may generalize to other sequence prediction settings where chunk length and step redundancy appear together.
- Lower inference counts could open the door to running VLA policies on smaller edge hardware that previously could not keep up.
- The reward design might be adapted to other efficiency metrics such as energy use or safety margins.
Load-bearing premise
The dynamic exploration strategy and redundancy-aware reward can be implemented and optimized across different VLA models without lowering task success rates or causing instability.
What would settle it
Training a new VLA model with PolicyTrim and then measuring both its task success rate and total inference calls on the same benchmarks; if success drops or the speedup disappears, the central claim does not hold.
Figures




read the original abstract
Vision-Language-Action (VLA) models provide a unified paradigm for robotic manipulation, yet their real-world deployment is often bottlenecked by execution efficiency. While existing efforts predominantly focus on compute-centric efficiency to reduce per-step inference latency, the intrinsic \textbf{policy efficiency} of these models remains largely unexplored. Policy efficiency is fundamentally affected by two factors, namely the effective executable length of predicted action chunks and the total physical steps required to complete a task. These two factors jointly determine the total number of forward inference calls during execution. We observe that current VLA policies struggle with planning unreliability and action redundancy, suffering from severe prediction degradation at the tail of action chunks and tending to generate unnecessarily redundant physical steps. To address this, we propose \textbf{PolicyTrim}, a reinforcement learning-based post-training framework that extends the reliable action chunk length and reduces redundant physical steps. For reliable chunk extension, we employ a dynamic exploration strategy that explicitly rewards the successful completion of longer executable lengths, progressively pushing the trustworthy prediction horizon to its empirical limit. For step efficiency, we design a redundancy-aware reward that directly favors successful task completions with fewer steps while penalizing unreproducible shortcuts, effectively eliminating redundant physical actions. Extensive experiments across three benchmarks and three VLA models demonstrate that PolicyTrim improves action chunk utilization by 3$\times$ and reduces physical execution steps by 51.4\%. Ultimately, our framework delivers up to a 5.83$\times$ end-to-end deployment speedup without compromising task success rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PolicyTrim, a reinforcement learning-based post-training framework for Vision-Language-Action (VLA) models. It addresses intrinsic policy efficiency by employing a dynamic exploration strategy to extend reliable action chunk lengths and a redundancy-aware reward to reduce redundant physical steps, reporting 3× improvement in action chunk utilization, 51.4% reduction in physical execution steps, and up to 5.83× end-to-end deployment speedup across three benchmarks and three VLA models without loss in task success rates.
Significance. If the reported gains are robustly supported, the work targets an important deployment bottleneck in VLA models beyond per-step inference latency, with potential to improve real-world robotic efficiency through better policy utilization.
major comments (1)
- [Abstract] Abstract: The abstract reports quantitative improvements from experiments across three benchmarks and three models but provides no details on experimental setup, baselines, statistical significance, or controls, making it impossible to assess support for the claims. This is load-bearing for the central empirical claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding our experimental claims. We agree this is important and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports quantitative improvements from experiments across three benchmarks and three models but provides no details on experimental setup, baselines, statistical significance, or controls, making it impossible to assess support for the claims. This is load-bearing for the central empirical claims.
Authors: We agree that the abstract would benefit from additional context to allow readers to better evaluate the reported gains. In the revised version, we will expand the abstract to briefly specify the three benchmarks and three VLA models used, note the primary baselines (standard VLA inference without post-training), and indicate that results are averaged over multiple random seeds with reported variance to convey statistical reliability. These additions will be kept concise to preserve abstract length while directly addressing the concern. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical RL post-training method (PolicyTrim) whose central claims—3× chunk utilization, 51.4% fewer physical steps, and 5.83× speedup—are presented as measured experimental outcomes on three benchmarks and three VLA models rather than as mathematical derivations. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the supplied abstract or reader summary; the dynamic exploration and redundancy-aware reward are design choices validated by ablation and success-rate tables, not quantities that reduce to their own inputs by construction. The derivation chain is therefore self-contained as standard empirical validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Lim, J., Song, S., Park, H.W
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachowicz, K., Tanner,...
2025
-
[2]
InProceedings of Robotics: Science and Systems, DOI: 10.15607/RSS
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L.X., Smith, L., Tanner, J., Vuong, Q., Walling, A., Wang, H., Zhilinsky, U.:π0: A Vision-Language-Action Flow Model for General Robot Contr...
-
[3]
Brohan, A., Brown, N., Carbajal, J., et al.: RT-1: Robotics transformer for real- world control at scale (2022), arXiv preprint arXiv:2212.06817 1
Pith/arXiv arXiv 2022
-
[4]
In: Conference on Robot Learning (CoRL) (2023), arXiv preprint arXiv:2307.15818 1, 3
Brohan, A., et al.: RT-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning (CoRL) (2023), arXiv preprint arXiv:2307.15818 1, 3
Pith/arXiv arXiv 2023
-
[5]
Budzianowski, P., Maa, W., Freed, M., Mo, J., Hsiao, W., Xie, A., et al.: Edgevla: Efficient vision-language-action models (2025), arXiv preprint arXiv:2507.14049 4
arXiv 2025
-
[6]
arXiv preprint arXiv:2504.18579 (2025) 4
Chen, F., He, Y., Lin, L., Gou, C., Liu, J., Zhuang, B., Wu, Q.: Sparsity forcing: Reinforcing token sparsity of mllms. arXiv preprint arXiv:2504.18579 (2025) 4
arXiv 2025
-
[7]
arXiv preprint arXiv:2510.25889 (2025) 15
Chen, K., Liu, Z., Zhang, T., Guo, Z., Xu, S., Lin, H., Zang, H., Zhang, Q., Yu, Z., Fan, G., et al.:πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models. arXiv preprint arXiv:2510.25889 (2025) 15
arXiv 2025
-
[8]
In: Proceedings of Robotics: Science and Systems
Chen, Y., Tian, S., Liu, S., Zhou, Y., Li, H., Zhao, D.: Conrft: A reinforced fine- tuning method for vla models via consistency policy. In: Proceedings of Robotics: Science and Systems. Los Angeles, CA, USA (June 2025).https://doi.org/10. 15607/RSS.2025.XXI.0194
2025
-
[9]
In: Robotics: Science and Systems (RSS) (2023), arXiv preprint arXiv:2303.04137 3
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. In: Robotics: Science and Systems (RSS) (2023), arXiv preprint arXiv:2303.04137 3
Pith/arXiv arXiv 2023
-
[10]
Collaboration, O.X.E., O’Neill, A., et al.: Open x-embodiment: Robotic learning datasets and rt-x models (2023), arXiv preprint arXiv:2310.08864 1
Pith/arXiv arXiv 2023
-
[11]
In: International Conference on Machine Learning (ICML)
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. In: International Conference on Machine Learning (ICML). pp. 8469–8488. PMLR (2023) 1
2023
-
[12]
In: Proceedings of Robotics: Science and Systems
Ghosh, D., Walke, H.R., Pertsch, K., et al.: Octo: An open-source generalist robot policy. In: Proceedings of Robotics: Science and Systems. Delft, Netherlands (July 2024).https://doi.org/10.15607/RSS.2024.XX.0901, 14
-
[13]
In: International Conference on Learning Representations (ICLR) (2022) 4 18 X
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: International Conference on Learning Representations (ICLR) (2022) 4 18 X. Wang et al
2022
-
[14]
Huang, D., Fang, Z., Zhang, T., Li, Y., Zhao, L., Xia, C.: Co-rft: Efficient fine- tuning of vision-language-action models through chunked offline reinforcement learning (2025), arXiv preprint arXiv:2508.02219 4
arXiv 2025
-
[15]
arXiv preprint arXiv:2504.19854 (2025) 4
Hung, C.Y., Sun, Q., Hong, P., Zadeh, A., Li, C., Tan, U., Majumder, N., Poria, S., et al.: Nora: A small open-sourced generalist vision language action model for embodied tasks. arXiv preprint arXiv:2504.19854 (2025) 4
Pith/arXiv arXiv 2025
-
[16]
arXiv preprint arXiv:2509.12594 (2025) 4
Jiang, T., Jiang, X., Ma, Y., Wen, X., Li, B., Zhan, K., Jia, P., Liu, Y., Sun, S., Lang, X.: The better you learn, the smarter you prune: Towards efficient vision-language-action models via differentiable token pruning. arXiv preprint arXiv:2509.12594 (2025) 4
arXiv 2025
-
[17]
Jing, D., Wang, G., Liu, J., Tang, W., Sun, Z., Yao, Y., Wei, Z., Liu, Y., Lu, Z., Ding, M.: Mixture of horizons in action chunking (2025), arXiv preprint arXiv:2511.19433 2
Pith/arXiv arXiv 2025
-
[18]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. In: Proceedings of Robotics: Science and Systems. Los Angeles, CA, USA (June 2025).https://doi.org/10.15607/RSS.2025.XXI.017 3
-
[19]
In: Agrawal, P., Kroemer, O., Burgard, W
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: OpenVLA: An open- source vision-language-action model. In: Agrawal, P., Kroemer, O., Burgard, W. (eds.) Proceedings of The 8th Conference on ...
2025
-
[20]
Koo, J., Cho, T., Kang, H., Pyo, E., Oh, T.G., Kim, T., Choi, A.J.: RetoVLA: Reusing register tokens for spatial reasoning in vision-language-action models (2025), arXiv preprint arXiv:2509.21243 2, 4
arXiv 2025
-
[21]
Li, H., Zuo, Y., Yu, J., Zhang, Y., et al.: Simplevla-rl: Scaling vla training via reinforcement learning (2025), arXiv preprint arXiv:2509.09674 4
Pith/arXiv arXiv 2025
-
[22]
Li, Q., Liang, Y., Wang, Z., et al.: Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation (2024), arXiv preprint arXiv:2411.19650 3
Pith/arXiv arXiv 2024
-
[23]
In: International Conference on Learning Representations (ICLR) (2024) 3
Li, X., Liu, M., Zhang, H., et al.: Vision-language foundation models as effective robot imitators. In: International Conference on Learning Representations (ICLR) (2024) 3
2024
-
[24]
Li, Y., Meng, Y., Sun, Z., Ji, K., Tang, C., Fan, J., Ma, X., Xia, S., Wang, Z., Zhu, W.: Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration (2025), arXiv preprint arXiv:2506.12723 2, 4
arXiv 2025
-
[25]
In: NeurIPS Datasets and Benchmarks Track (2023), arXiv preprint arXiv:2306.03310 9
Liu, B., et al.: LIBERO: Benchmarking knowledge transfer for lifelong robot learning. In: NeurIPS Datasets and Benchmarks Track (2023), arXiv preprint arXiv:2306.03310 9
Pith/arXiv arXiv 2023
-
[26]
arXiv preprint arXiv:2503.10631 (2025) 2
Liu, J., Chen, H., An, P., Liu, Z., Zhang, R., Gu, C., Li, X., Guo, Z., Chen, S., Liu, M., et al.: Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631 (2025) 2
Pith/arXiv arXiv 2025
-
[27]
In: Interna- tional Conference on Learning Representations (ICLR) (2025) 14
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: RDT-1B: a diffusion foundation model for bimanual manipulation. In: Interna- tional Conference on Learning Representations (ICLR) (2025) 14
2025
-
[28]
Lu, G., Guo, W., Zhang, C., Zhou, Y., Jiang, H., Gao, Z., Tang, Y., Wang, Z.: Vla- rl: Towards masterful and general robotic manipulation with scalable reinforcement learning (2025), arXiv preprint arXiv:2505.18719 4 PolicyTrim 19
Pith/arXiv arXiv 2025
-
[29]
Ma, Y.J., Song, Z., Zhuang, Y., Hao, J., King, I.: A survey on vision-language- action models for embodied ai (2024), arXiv preprint arXiv:2405.14093 3
Pith/arXiv arXiv 2024
-
[30]
In: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2025) 9
McLean, R., Chatzaroulas, E., McCutcheon, L., Röder, F., Yu, T., He, Z., Zentner, K., Julian, R., Terry, J.K., Woungang, I., Farsad, N., Castro, P.S.: Meta-world+: An improved, standardized, RL benchmark. In: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2025) 9
2025
-
[31]
NVIDIA, et al.: GR00T N1: An open foundation model for generalist humanoid robots (2025), arXiv preprint arXiv:2503.14734 3
Pith/arXiv arXiv 2025
-
[32]
In: Proceedings of Robotics: Science and Systems
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: FAST: Efficient action tokenization for vision-language-action models. In: Proceedings of Robotics: Science and Systems. Los Angeles, CA, USA (June 2025).https://doi.org/10.15607/RSS.2025.XXI.0124
-
[33]
In: Proceedings of Robotics: Science and Systems
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Gu, J., Wang, Z., Ding, Y., Zhao, B., Wang, D., Li, X.: Spatialvla: Exploring spatial representations for visual-language- action models. In: Proceedings of Robotics: Science and Systems. Los Angeles, CA, USA (June 2025).https://doi.org/10.15607/RSS.2025.XXI.01114
-
[34]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms (2017), arXiv preprint arXiv:1707.06347 4
Pith/arXiv arXiv 2017
-
[35]
Shao, R., Li, W., Zhang, L., Zhang, R., Liu, Z., Chen, R., Nie, L.: Large vlm-based vision-language-action models for robotic manipulation: A survey (2025), arXiv preprint arXiv:2508.13073 3
Pith/arXiv arXiv 2025
-
[36]
Shao, Z., Wang, P., Zhu, Q., et al.: Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models (2024), arXiv preprint arXiv:2402.03300 3, 4
Pith/arXiv arXiv 2024
-
[37]
Shukor,M.,Aubakirova,D.,Capuano,F.,Kooijmans,P.,Palma,S.,etal.:Smolvla: A vision-language-action model for affordable and efficient robotics (2025), arXiv preprint arXiv:2506.01844 4
Pith/arXiv arXiv 2025
-
[38]
Song, W., Chen, J., Ding, P., Huang, Y., Zhao, H., Wang, D., Li, H.: CEED-VLA: Consistency vision-language-action model with early-exit decoding (2025), arXiv preprint arXiv:2506.13725 4
arXiv 2025
-
[39]
Song, W., Chen, J., Ding, P., Zhao, H., Zhao, W., Zhong, Z., Ge, Z., Ma, J., Li, H.: PD-VLA: Accelerating vision-language-action model integrated with action chunking via parallel decoding (2025), arXiv preprint arXiv:2503.02310 4
arXiv 2025
-
[40]
Tan, S., Dou, K., Zhao, Y., Krähenbühl, P.: Interactive post-training for vision- language-action models (2025) 15
2025
-
[41]
Robotics: Science and Systems (2025), arXiv preprint arXiv:2410.00425 9
Tao, S., Xiang, F., Shukla, A., Qin, Y., Hinrichsen, X., Yuan, X., Bao, C., Lin, X., Liu, Y., Chan, T.k., Gao, Y., Li, X., Mu, T., Xiao, N., Gurha, A., Viswesh, N.R., Choi, Y.W., Chen, Y.R., Huang, Z., Calandra, R., Chen, R., Luo, S., Su, H.: Man- iskill3: Gpu parallelized robotics simulation and rendering for generalizable em- bodied ai. Robotics: Scienc...
arXiv 2025
-
[42]
Team,R.,etal.:RDT-1B:Adiffusionfoundationmodelforbimanualmanipulation. In: International Conference on Learning Representations (ICLR) (2025), arXiv preprint arXiv:2410.07864 1
Pith/arXiv arXiv 2025
-
[43]
arXiv preprint arXiv:2509.05614 (2025) 4
Wang, H., Xu, J., Pan, J., Zhou, Y., Dai, G.: Specprune-vla: Accelerating vision- language-action models via action-aware self-speculative pruning. arXiv preprint arXiv:2509.05614 (2025) 4
Pith/arXiv arXiv 2025
-
[44]
Wang, H., et al.: Vla knows its limits (2026), arXiv preprint arXiv:2602.21445 2
Pith/arXiv arXiv 2026
-
[45]
Wang, H., Xiong, C., Wang, R., Chen, X.: Bitvla: 1-bit vision-language-action models for robotics manipulation (2025), arXiv preprint arXiv:2506.07530 4 20 X. Wang et al
arXiv 2025
-
[46]
Wang, S., Yu, R., Yuan, Z., Yu, C., Gao, F., Wang, Y., Wong, D.F.: Spec-vla: Speculative decoding for vision-language-action models with relaxed acceptance (2025), arXiv preprint arXiv:2507.22424 4
arXiv 2025
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, Y., Zhu, H., Liu, M., Yang, J., Fang, H.S., He, T.: VQ-VLA: Improv- ing vision-language-action models via scaling vector-quantized action tokenizers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11089–11099 (October 2025) 4
2025
-
[48]
arXiv preprint arXiv:2509.25681 (2025) 2
Wen, J., Zhu, M., Liu, J., Liu, Z., Yang, Y., Zhang, L., Zhang, S., Zhu, Y., Xu, Y.: dvla: Diffusion vision-language-action model with multimodal chain-of-thought. arXiv preprint arXiv:2509.25681 (2025) 2
arXiv 2025
-
[49]
IEEE Robotics and Automation Letters (2025) 4
Wen, J., Zhu, Y., Li, J., Zhu, M., Tang, Z., Wu, K., Xu, Z., Liu, N., Cheng, R., Shen, C., et al.: Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters (2025) 4
2025
-
[50]
Wu, H., Jing, Y., Cheang, C., et al.: GR-1: Unleashing large-scale video generative pre-training for visual robot manipulation (2023), arXiv preprint arXiv:2312.13139 3
Pith/arXiv arXiv 2023
-
[51]
Xu, S., Wang, Y., Xia, C., Zhu, D., Huang, T., Xu, C.: Vla-cache: Efficient vision- language-action manipulation via adaptive token caching (2025), arXiv preprint arXiv:2502.02175 4
arXiv 2025
-
[52]
Xu, W., Zhuang, L.: Kv-efficient vla: A method of speed up vision language model with rnn-gated chunked kv cache (2025), arXiv preprint arXiv:2509.21354 2, 4
arXiv 2025
-
[53]
Xu, Y., Yang, Y., Fan, Z., Liu, Y., Li, Y., Li, B., Zhang, Z.: Qvla: Not all channels are equal in vision-language-action model’s quantization (2026), arXiv preprint arXiv:2602.03782 4
arXiv 2026
-
[54]
Yang, Y., Wang, Y., Wen, Z., Liu, Z., Zou, C., Zhang, Z., Wen, C., Zhang, L.: Efficientvla: Training-free acceleration and compression for vision-language-action models (2025), arXiv preprint arXiv:2506.10100 4
arXiv 2025
-
[55]
arXiv preprint arXiv:2509.15965 (2025) 9
Yu, C., Wang, Y., Guo, Z., Lin, H., Xu, S., Zang, H., Zhang, Q., Wu, Y., Zhu, C., Hu, J., et al.: Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation. arXiv preprint arXiv:2509.15965 (2025) 9
arXiv 2025
-
[56]
Yu, Z., Wang, B., Zeng, P., Zhang, H., Zhang, J., Gao, L., Song, J., Sebe, N., Shen, H.T.: A survey on efficient vision-language-action models (2025), arXiv preprint arXiv:2510.24795 4
arXiv 2025
-
[57]
Zhang, J., Hsieh, Y., Wang, Z., Lin, H., Wang, X., Wang, Z., Lei, Y., Zhang, M.: Quantvla: Scale-calibrated post-training quantization for vision-language-action models (2026), arXiv preprint arXiv:2602.20309 4
Pith/arXiv arXiv 2026
-
[58]
Zhang, Y., et al.: Sqap-vla: Saliency-aware quantization and pruning for vision- language-action models (2025), arXiv preprint arXiv:2512.08813 4
arXiv 2025
-
[59]
In: Robotics: Science and Systems (RSS) (2023), introduces Action Chunking with Transformers (ACT) 3
Zhao,T.Z.,etal.:Learningfine-grainedbimanualmanipulationwithlow-costhard- ware. In: Robotics: Science and Systems (RSS) (2023), introduces Action Chunking with Transformers (ACT) 3
2023
-
[60]
Zheng, W., Li, B., Xu, B., Feng, E., Gu, J., Chen, H.: Leveraging os-level primitives for robotic action management. arXiv preprint (2025), arXiv preprint arXiv:2508.10259 2 PolicyTrim 21 A PolicyTrim Training Algorithm A.1 PolicyTrim Training Algorithm We summarize the two-stage optimization procedure of PolicyTrim below. Poli- cyTrim improves intrinsic ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.