OmniSpace: Efficient Geometry Awareness for Autonomous Vehicles MLLMs
Pith reviewed 2026-06-26 10:56 UTC · model grok-4.3
The pith
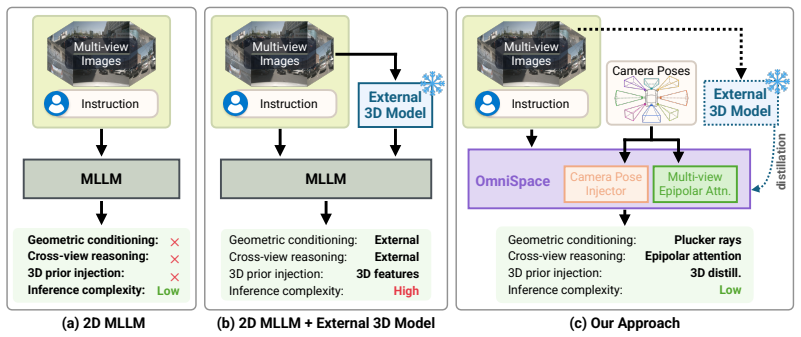
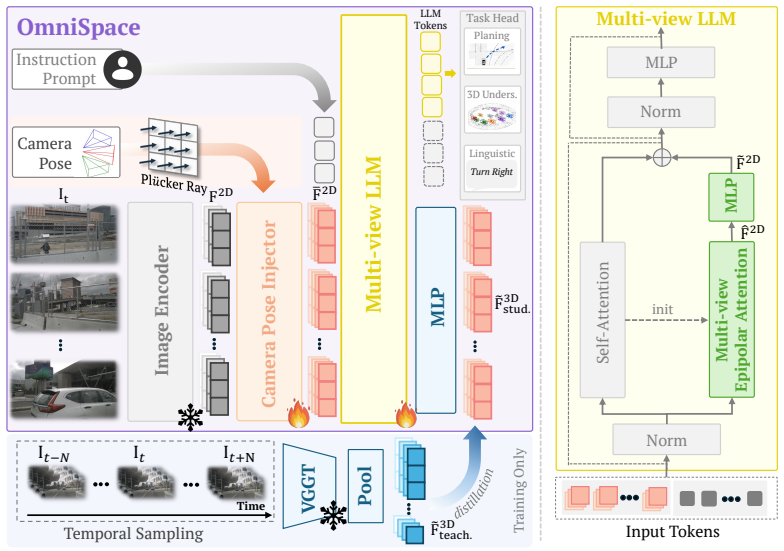
OmniSpace adds a Camera Pose Injector, Multi-view Epipolar Attention, and 3D Geometric Distillation to MLLMs so they can reason about 3D space for autonomous driving using only 2D images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniSpace is a plug-and-play method that transfers geometric knowledge into MLLMs from purely 2D observations. It does so by injecting camera poses, applying multi-view epipolar attention to strengthen cross-view correspondence, and using a 3D geometric distillation objective to improve depth estimation. The result is higher performance on planning, risk detection, language, and generalization benchmarks without auxiliary 3D models at inference.
What carries the argument
The joint action of the Camera Pose Injector, Multi-view Epipolar Attention module, and 3D Geometric Distillation objective, which together target cross-view correspondence and depth estimation.
If this is right
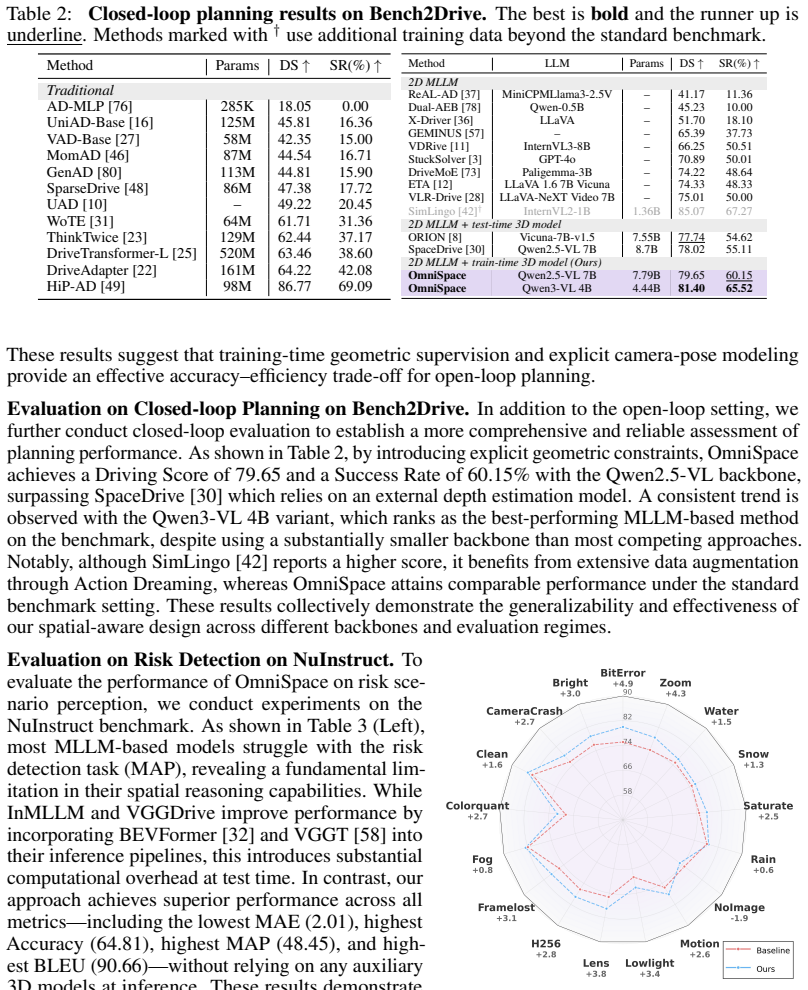
- Planning accuracy rises on nuScenes and Bench2Drive because the model now handles depth and view consistency better.
- Risk detection improves on nuInstruct since geometric cues help identify hazards from language descriptions.
- Language performance increases on Omnidrive because spatial relations are represented more reliably inside the model.
- Generalization strengthens on DriveBench as the injected geometry reduces reliance on dataset-specific patterns.
- The overall pipeline avoids cascading failures that occur when an external 3D model is required at runtime.
Where Pith is reading between the lines
- The same three modules could be tested on non-driving 3D tasks such as indoor navigation or robotic manipulation where only 2D images are available.
- If the distillation step proves stable, similar objectives might be applied to other multimodal models that need implicit 3D structure.
- Deployment cost drops because inference no longer requires running a separate depth or pose network alongside the language model.
Load-bearing premise
That the main bottlenecks in current MLLMs for spatial AV tasks are weak cross-view correspondence and depth estimation, and that the three modules can transfer the missing geometric knowledge without creating new failure modes.
What would settle it
A controlled test in which the three modules are added to the same base MLLM yet produce no gain (or a loss) on the nuScenes planning metric or introduce measurable new errors in cross-view point matching.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable performance on 2D visual tasks, yet enhancing their spatial intelligence for real-world applications such as Autonomous Vehicles (AV) remains an open challenge. Existing geometry-aware MLLMs typically rely on auxiliary 3D models at inference time, introducing pipeline complexity and the risk of cascading failures. In this paper, we present OmniSpace, a simple yet effective plug-and-play paradigm for geometry-aware spatial reasoning from purely 2D observations. Motivated by our finding that current MLLMs are bottlenecked by weak cross-view correspondence and depth estimation, OmniSpace introduces a Camera Pose Injector, a Multi-view Epipolar Attention module, and a 3D Geometric Distillation objective that jointly address these two limitations by transferring geometric knowledge into the model. Extensive experiments show that OmniSpace surpasses existing methods on planning benchmarks (nuScenes, Bench2Drive), risk detection (nuInstruct), language (Omnidrive), and generalization (DriveBench).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OmniSpace, a plug-and-play approach to add geometry awareness to MLLMs for autonomous vehicle tasks using only 2D observations. It identifies weak cross-view correspondence and depth estimation as primary bottlenecks, then introduces three components (Camera Pose Injector, Multi-view Epipolar Attention module, and 3D Geometric Distillation objective) to transfer geometric knowledge. The abstract claims that extensive experiments demonstrate superiority over prior methods on planning (nuScenes, Bench2Drive), risk detection (nuInstruct), language (Omnidrive), and generalization (DriveBench) benchmarks.
Significance. If the claimed performance gains are substantiated with proper controls and the modules are shown not to introduce compensating errors, the work would offer a practical alternative to auxiliary 3D models at inference time. The explicit avoidance of cascading failures from external 3D pipelines is a clear practical strength if the results hold.
major comments (3)
- Abstract: the claim of surpassing existing methods on five named benchmarks is stated without any quantitative numbers, baselines, error bars, or ablation tables, so the central empirical claim cannot be evaluated from the provided text.
- Motivation section (implied by 'Motivated by our finding'): the premise that cross-view correspondence and depth estimation are the dominant bottlenecks is presented as an established finding, yet no supporting analysis, diagnostic experiments, or citations to prior measurements are referenced, leaving the justification for the three modules unsupported.
- Method description: the three invented modules (Camera Pose Injector, Multi-view Epipolar Attention, 3D Geometric Distillation) are asserted to jointly solve the stated limitations, but no ablation isolating each module's contribution or testing for new failure modes is mentioned, which is required to substantiate the transfer claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the presentation of empirical claims, motivation, and validation. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim of surpassing existing methods on five named benchmarks is stated without any quantitative numbers, baselines, error bars, or ablation tables, so the central empirical claim cannot be evaluated from the provided text.
Authors: We agree that the abstract would be strengthened by including quantitative highlights. In the revision we will add specific performance deltas (with baseline references) drawn from the experimental tables to make the superiority claims directly evaluable while remaining within abstract length constraints. revision: yes
-
Referee: Motivation section (implied by 'Motivated by our finding'): the premise that cross-view correspondence and depth estimation are the dominant bottlenecks is presented as an established finding, yet no supporting analysis, diagnostic experiments, or citations to prior measurements are referenced, leaving the justification for the three modules unsupported.
Authors: The stated motivation rests on observations from our preliminary diagnostics. To address the gap, the revised manuscript will include an expanded motivation subsection with the supporting diagnostic experiments, metrics, and visualizations that identified weak cross-view correspondence and depth estimation as primary limitations. revision: yes
-
Referee: Method description: the three invented modules (Camera Pose Injector, Multi-view Epipolar Attention, 3D Geometric Distillation) are asserted to jointly solve the stated limitations, but no ablation isolating each module's contribution or testing for new failure modes is mentioned, which is required to substantiate the transfer claim.
Authors: We acknowledge that isolating each module's contribution and checking for introduced failure modes strengthens the transfer claim. The revision will add dedicated ablation tables and failure-mode analysis experiments that separately evaluate the Camera Pose Injector, Multi-view Epipolar Attention, and 3D Geometric Distillation components. revision: yes
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper describes OmniSpace as introducing three independent modules (Camera Pose Injector, Multi-view Epipolar Attention, 3D Geometric Distillation) motivated by an external observation on MLLM bottlenecks, with performance claims validated on separate external benchmarks (nuScenes, Bench2Drive, etc.). No equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text that would reduce any result to its own inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current MLLMs are bottlenecked by weak cross-view correspondence and depth estimation
invented entities (3)
-
Camera Pose Injector
no independent evidence
-
Multi-view Epipolar Attention module
no independent evidence
-
3D Geometric Distillation objective
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[3]
Zhipeng Bao and Qianwen Li. Large language model-assisted autonomous vehicle recovery from immobi- lization.arXiv preprint arXiv:2510.26023, 2025
arXiv 2025
-
[4]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
2020
-
[5]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025
arXiv 2025
-
[6]
Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13668–13677, 2024
2024
-
[7]
Man truckscenes: A multimodal dataset for autonomous trucking in diverse conditions.Advances in Neural Information Processing Systems, 37:62062–62082, 2024
Felix Fent, Fabian Kuttenreich, Florian Ruch, Farija Rizwin, Stefan Juergens, Lorenz Lechermann, Christian Nissler, Andrea Perl, Ulrich V oll, Min Yan, et al. Man truckscenes: A multimodal dataset for autonomous trucking in diverse conditions.Advances in Neural Information Processing Systems, 37:62062–62082, 2024
2024
-
[8]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation.arXiv preprint arXiv:2503.19755, 2025
Pith/arXiv arXiv 2025
-
[9]
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, and Mohammad Akbari. Spatial reasoning with vision-language models in ego-centric multi-view scenes.arXiv preprint arXiv:2509.06266, 2025
arXiv 2025
-
[10]
End-to-end autonomous driving without costly modularization and 3d manual annotation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Mingzhe Guo, Zhipeng Zhang, Yuan He, Ke Wang, Liping Jing, and Haibin Ling. End-to-end autonomous driving without costly modularization and 3d manual annotation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[11]
Ziang Guo and Zufeng Zhang. Vdrive: Leveraging reinforced vla and diffusion policy for end-to-end autonomous driving.arXiv preprint arXiv:2510.15446, 2025
arXiv 2025
-
[12]
Eta: Efficiency through thinking ahead, a dual approach to self-driving with large models
Shadi Hamdan, Chonghao Sima, Zetong Yang, Hongyang Li, and Fatma Guney. Eta: Efficiency through thinking ahead, a dual approach to self-driving with large models. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[13]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[14]
Lora: Low-rank adaptation of large language models.ICLR, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 2022
2022
-
[15]
St-p3: End-to- end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to- end vision-based autonomous driving via spatial-temporal feature learning. InEuropean Conference on Computer Vision, 2022
2022
-
[16]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[17]
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. 3drs: Mllms need 3d-aware representation supervision for scene understanding.arXiv preprint arXiv:2506.01946, 2025
arXiv 2025
-
[18]
Robotron-drive: All-in-one large multimodal model for autonomous driving
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Robotron-drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8011–8021, 2025. 10
2025
-
[19]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[20]
Emma: End-to-end multimodal model for autonomous driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262, 2024
Pith/arXiv arXiv 2024
-
[21]
Large scale multi-view stereopsis evaluation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 406–413, 2014
2014
-
[22]
Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving
Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[23]
Think twice before driving: Towards scalable decoders for end-to-end autonomous driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[24]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 2024
2024
-
[25]
Drivetransformer: Unified transformer for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[26]
Senna: Bridging large vision-language models and end-to-end autonomous driving
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving. arXiv preprint arXiv:2410.22313, 2024
Pith/arXiv arXiv 2024
-
[27]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[28]
Vlr-driver: Large vision-language-reasoning models for embodied autonomous driving
Fanjie Kong, Yitong Li, Weihuang Chen, Chen Min, Yizhe Li, Zhiqiang Gao, Haoyang Li, Zhongyu Guo, and Hongbin Sun. Vlr-driver: Large vision-language-reasoning models for embodied autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[29]
Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[30]
Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, and Andreas Zell. Spacedrive: Infusing spatial awareness into vlm-based autonomous driving.arXiv preprint arXiv:2512.10719, 2, 2025
Pith/arXiv arXiv 2025
-
[31]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025
arXiv 2025
-
[32]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[33]
Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
2024
-
[34]
Vila: On pre- training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre- training for visual language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689–26699, 2024
2024
-
[35]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[36]
Wei Liu, Jiyuan Zhang, Binxiong Zheng, Yufeng Hu, Yingzhan Lin, and Zengfeng Zeng. X-driver: Explainable autonomous driving with vision-language models.arXiv preprint arXiv:2505.05098, 2025. 11
arXiv 2025
-
[37]
Real-ad: Towards human-like reasoning in end-to-end autonomous driving
Yuhang Lu, Jiadong Tu, Yuexin Ma, and Xinge Zhu. Real-ad: Towards human-like reasoning in end-to-end autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[38]
Yuechen Luo, Fang Li, Shaoqing Xu, Yang Ji, Zehan Zhang, Bing Wang, Yuannan Shen, Jianwei Cui, Long Chen, Guang Chen, et al. Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving.arXiv preprint arXiv:2603.01928, 2026
arXiv 2026
-
[39]
One million scenes for autonomous driving: Once dataset
Jiageng Mao, Minzhe Niu, Chenhan Jiang, Hanxue Liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, et al. One million scenes for autonomous driving: Once dataset. arXiv preprint arXiv:2106.11037, 2021
arXiv 2021
-
[40]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, 2021
2021
-
[41]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021
2021
-
[42]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[43]
A multi-view stereo benchmark with high-resolution images and multi- camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi- camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
2017
-
[44]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. In European conference on computer vision, pages 256–274. Springer, 2024
2024
-
[45]
Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021
Vincent Sitzmann, Semon Rezchikov, Bill Freeman, Josh Tenenbaum, and Fredo Durand. Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021
2021
-
[46]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[47]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[48]
Sparsedrive: End- to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End- to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[49]
Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng. Hip-ad: Hierarchical and multi- granularity planning with deformable attention for autonomous driving in a single decoder.arXiv preprint arXiv:2503.08612, 2025
arXiv 2025
-
[50]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[51]
Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
Pith/arXiv arXiv 2024
-
[52]
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
Pith/arXiv arXiv 2024
-
[53]
Drivevlm: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, XianPeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. InConference on Robot Learning, 2025. 12
2025
-
[54]
Thanh-Dat Truong, Huu-Thien Tran, Tran Thai Son, Bhiksha Raj, and Khoa Luu. Directed-tokens: A robust multi-modality alignment approach to large language-vision models.arXiv preprint arXiv:2508.14264, 2025
arXiv 2025
-
[55]
Semlt3d: Semantic-guided expert distillation for camera-only long-tailed 3d object detection
Hao V o, Khoa V o, Thinh Phan, Ngo Xuan Cuong, Gianfranco Doretto, Hien Nguyen, Anh Nguyen, and Ngan Le. Semlt3d: Semantic-guided expert distillation for camera-only long-tailed 3d object detection. arXiv preprint arXiv:2604.18476, 2026
Pith/arXiv arXiv 2026
-
[56]
Henasy: Learning to assemble scene- entities for interpretable egocentric video-language model.Advances in Neural Information Processing Systems, 37:86483–86499, 2024
Khoa V o, Thinh Phan, Kashu Yamazaki, Minh Tran, and Ngan Le. Henasy: Learning to assemble scene- entities for interpretable egocentric video-language model.Advances in Neural Information Processing Systems, 37:86483–86499, 2024
2024
-
[57]
Chi Wan, Yixin Cui, Jiatong Du, Shuo Yang, Yulong Bai, Peng Yi, Nan Li, and Yanjun Huang. Geminus: Dual-aware global and scene-adaptive mixture-of-experts for end-to-end autonomous driving.arXiv preprint arXiv:2507.14456, 2025
arXiv 2025
-
[58]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[59]
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, and Long Chen. Vggdrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving.arXiv preprint arXiv:2602.20794, 2026
arXiv 2026
-
[60]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[61]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the computer vision and pattern recognition conference, pages 22442–22452, 2025
2025
-
[62]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[63]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[64]
Para-drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024
2024
-
[65]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting.arXiv preprint arXiv:2301.00493, 2023
Pith/arXiv arXiv 2023
-
[66]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
Pith/arXiv arXiv 2025
-
[67]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
Pith/arXiv arXiv 2024
-
[68]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6585–6597, 2025
2025
-
[69]
Yi Xu, Yuxin Hu, Zaiwei Zhang, Gregory P Meyer, Siva Karthik Mustikovela, Siddhartha Srinivasa, Eric M Wolff, and Xin Huang. Vlm-ad: End-to-end autonomous driving through vision-language model supervision.arXiv preprint arXiv:2412.14446, 2024
arXiv 2024
-
[70]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 9(10):8186–8193, 2024. 13
2024
-
[71]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[72]
Cambrian-s: Towards spatial supersensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[73]
Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving
Zhenjie Yang, Yilin Chai, Xiaosong Jia, Qifeng Li, Yuqian Shao, Xuekai Zhu, Haisheng Su, and Junchi Yan. Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving. arXiv preprint arXiv:2505.16278, 2025
Pith/arXiv arXiv 2025
-
[74]
Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
Pith/arXiv arXiv 2024
-
[75]
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, Xing Wei, and Ning Guo. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving.arXiv preprint arXiv:2505.17685, 2025
Pith/arXiv arXiv 2025
-
[76]
Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes
Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes. arXiv preprint arXiv:2305.10430, 2023
Pith/arXiv arXiv 2023
-
[77]
Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, et al. Theory of space: Can foundation models construct spatial beliefs through active exploration?arXiv preprint arXiv:2602.07055, 2026
arXiv 2026
-
[78]
Dual-aeb: Synergizing rule-based and multimodal large language models for effective emergency braking
Wei Zhang, Pengfei Li, Junli Wang, Bingchuan Sun, Qihao Jin, Guangjun Bao, Shibo Rui, Yang Yu, Wenchao Ding, Peng Li, et al. Dual-aeb: Synergizing rule-based and multimodal large language models for effective emergency braking. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[79]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625, 2025
arXiv 2025
-
[80]
Genad: Generative end-to-end autonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end autonomous driving. InEuropean Conference on Computer Vision, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.