From Complaint Narratives to Monetary Relief: A Hybrid Machine Learning Framework for CFPB Consumer Complaints
Pith reviewed 2026-06-26 09:23 UTC · model grok-4.3
The pith
A hybrid machine learning framework predicts which CFPB complaints receive monetary relief by combining text, topics, and company data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
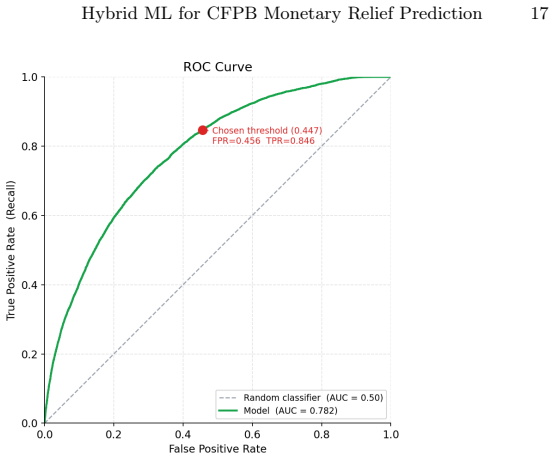
The proposed hybrid framework integrates complaint narrative text, LDA-based topic representations, interpretable text-engineered features, and structured categorical attributes such as company and state. An XGBoost classifier trained using a temporal train-test split achieves an AUC-ROC of 0.78 compared to 0.69 for a TF-IDF baseline, with improved PR-AUC under imbalance. Feature importance analysis indicates that textual signals, latent complaint topics, and company identity all contribute meaningful predictive information, revealing systematic variation in complaint resolution across institutions.
What carries the argument
The hybrid feature set fed into an XGBoost classifier, where complaint narratives, LDA topics, text features, and categorical variables are combined to classify complaints as receiving monetary relief or not.
If this is right
- Textual signals from narratives supply predictive information beyond bag-of-words baselines.
- Company identity captures systematic differences in how institutions resolve complaints.
- Latent topics extracted via LDA help surface underlying complaint issues that correlate with relief.
- The combined framework improves performance on the minority class of monetary relief cases.
- Complaint data can serve as a source for monitoring consumer harm and firm-level operational patterns.
Where Pith is reading between the lines
- Regulators could apply similar models to flag high-risk complaints for faster review.
- Company-specific effects might guide targeted oversight of financial institutions with lower relief rates.
- Adding time-based features such as complaint volume trends could further improve temporal robustness.
- The approach might transfer to complaint systems maintained by other agencies or countries.
Load-bearing premise
The temporal train-test split, using earlier complaints for training and later ones for testing, provides a reliable estimate of real-world performance without significant distribution shifts.
What would settle it
A substantial drop in AUC-ROC or PR-AUC when the same model is evaluated on complaints filed after the original test period, or evidence of large shifts in narrative language or company resolution rates between periods.
Figures
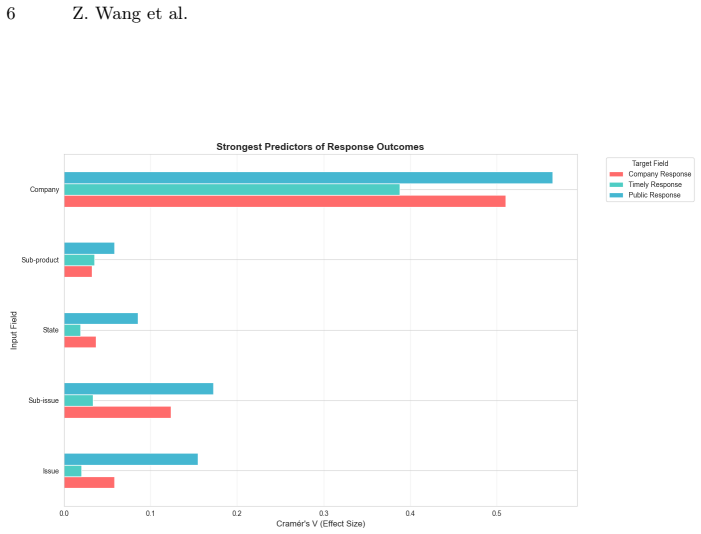
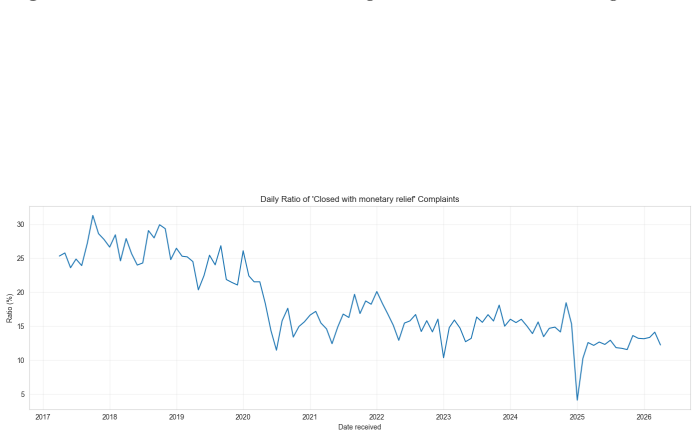
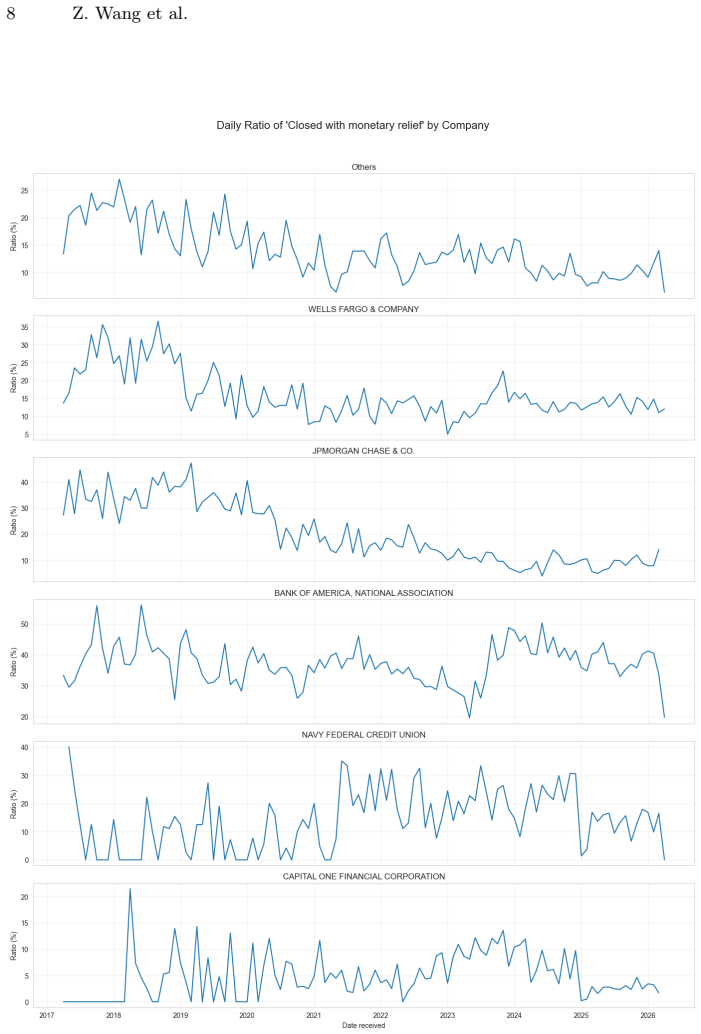
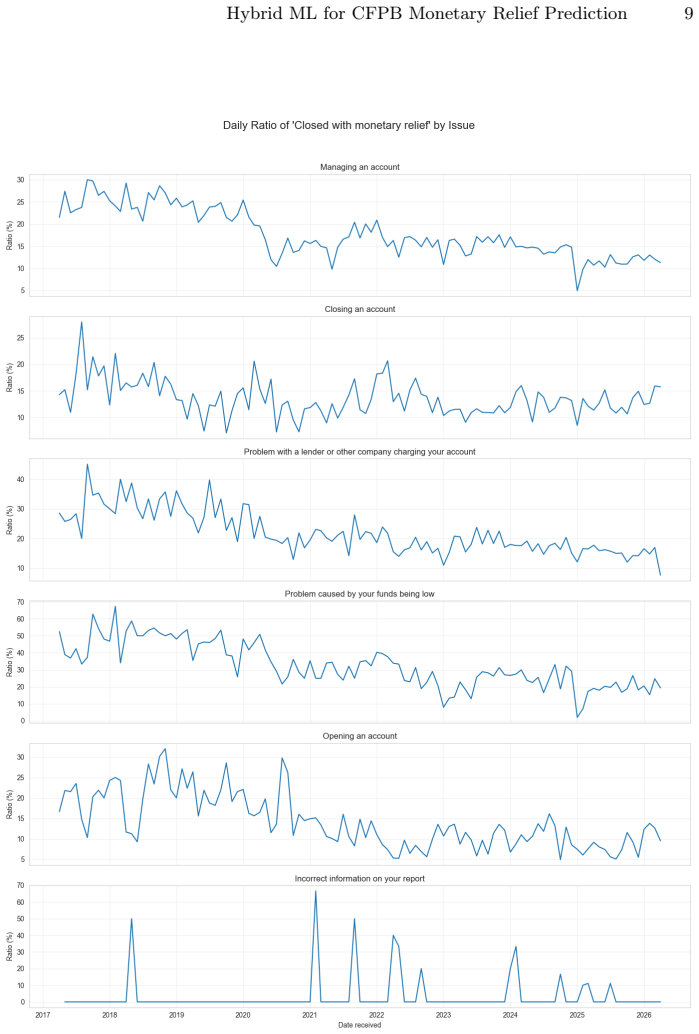
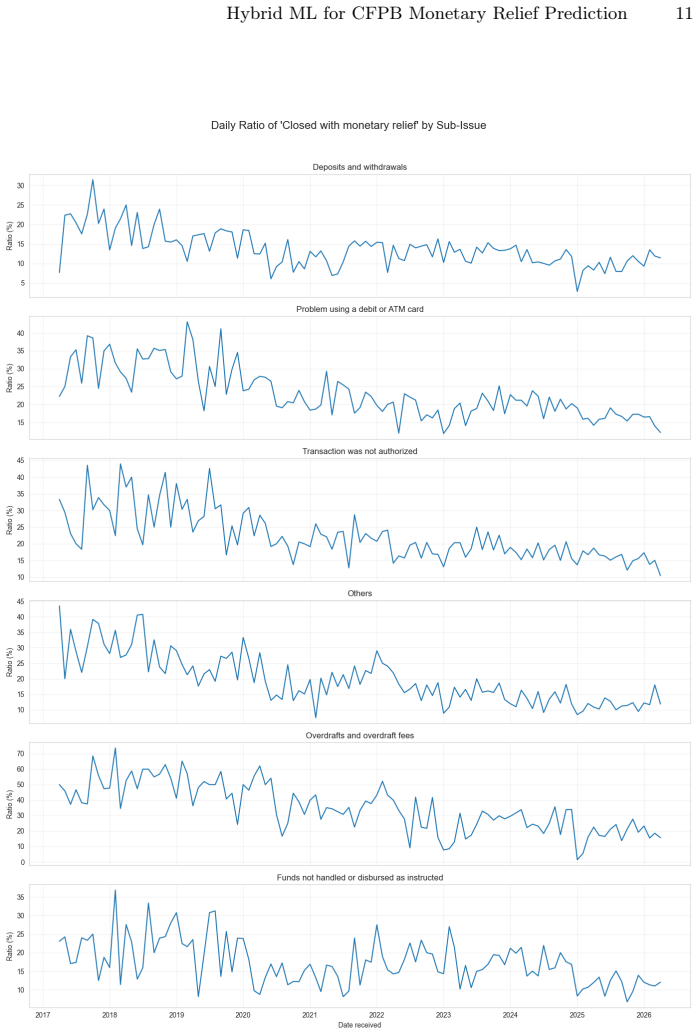
read the original abstract
Consumer financial complaints provide a valuable source of information for identifying service failures, dispute frictions, and operational deficiencies in consumer-facing financial institutions. This paper proposes a hybrid machine learning framework for predicting monetary relief outcomes using Consumer Financial Protection Bureau complaint data. We formulate the task as an imbalanced binary classification problem, where complaints closed with monetary relief are treated as compensable outcomes. The proposed framework integrates multiple sources of predictive information, including complaint narrative text, LDA-based topic representations, interpretable text-engineered features, and structured categorical attributes such as company and state. An XGBoost classifier is trained using a temporal train-test split, with earlier complaints used for model development and more recent complaints reserved for out-of-sample evaluation. Compared with a TF-IDF baseline, the proposed framework substantially improves predictive performance, increasing AUC-ROC from 0.69 to 0.78 and improving PR-AUC under class imbalance. Feature importance analysis shows that textual signals, latent complaint topics, and company identity all contribute meaningful predictive information. In particular, company-level effects reveal systematic variation in complaint resolution patterns across financial institutions. These findings suggest that consumer complaint narratives can serve as alternative data for monitoring consumer harm, identifying firm-level operational weaknesses, and supporting early-stage risk surveillance in consumer finance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid machine learning framework for predicting monetary relief outcomes on CFPB consumer complaints. It integrates complaint narrative text, LDA topic representations, interpretable text-engineered features, and categorical attributes (company, state) into an XGBoost classifier. Using a temporal train-test split (earlier complaints for development, later for evaluation), the framework is reported to raise AUC-ROC from 0.69 (TF-IDF baseline) to 0.78 while improving PR-AUC under imbalance; feature importance analysis attributes value to textual signals, topics, and company identity.
Significance. If the performance lift is robust, the work offers a practical approach to leveraging complaint narratives for firm-level risk surveillance and operational monitoring in consumer finance. The temporal split and use of PR-AUC address key aspects of the imbalanced, time-ordered setting. The explicit combination of multiple information sources is a constructive contribution, though its value depends on confirmation that the reported gains are not artifacts of unexamined temporal non-stationarity.
major comments (2)
- [temporal train-test split description] The temporal train-test split (described in the methods) is presented as delivering a reliable out-of-sample estimate, yet no diagnostics for distribution shift are reported (e.g., Kolmogorov-Smirnov tests on LDA topic proportions, narrative length distributions, or company complaint frequencies before/after the split date). Because company identity is highlighted as an important feature and regulatory or economic events could alter resolution patterns, this omission directly affects the credibility of the 0.69-to-0.78 AUC-ROC claim.
- [feature importance analysis] The abstract states that the hybrid framework 'substantially improves' performance and that 'textual signals, latent complaint topics, and company identity all contribute meaningful predictive information,' but the manuscript provides no quantitative breakdown (e.g., ablation results removing each component or permutation importance scores with confidence intervals) to substantiate the relative contributions. Without these, the central claim that the hybrid design, rather than any single source, drives the lift cannot be fully evaluated.
minor comments (2)
- [model training] The handling of class imbalance (e.g., XGBoost scale_pos_weight, sampling strategy, or threshold selection for PR-AUC) is mentioned only at a high level; a short methods paragraph or table entry would improve reproducibility.
- [LDA topic modeling] LDA topic count and hyperparameter selection procedure are not detailed; stating the number of topics and the criterion used (perplexity, coherence, or cross-validation) would clarify the topic representation step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [temporal train-test split description] The temporal train-test split (described in the methods) is presented as delivering a reliable out-of-sample estimate, yet no diagnostics for distribution shift are reported (e.g., Kolmogorov-Smirnov tests on LDA topic proportions, narrative length distributions, or company complaint frequencies before/after the split date). Because company identity is highlighted as an important feature and regulatory or economic events could alter resolution patterns, this omission directly affects the credibility of the 0.69-to-0.78 AUC-ROC claim.
Authors: We agree that explicit distribution-shift diagnostics would increase confidence in the temporal split. In the revised manuscript we will add Kolmogorov-Smirnov tests comparing LDA topic proportions, narrative-length distributions, and company-level complaint frequencies across the split date, together with a brief discussion of any detected shifts and their implications for the reported performance. revision: yes
-
Referee: [feature importance analysis] The abstract states that the hybrid framework 'substantially improves' performance and that 'textual signals, latent complaint topics, and company identity all contribute meaningful predictive information,' but the manuscript provides no quantitative breakdown (e.g., ablation results removing each component or permutation importance scores with confidence intervals) to substantiate the relative contributions. Without these, the central claim that the hybrid design, rather than any single source, drives the lift cannot be fully evaluated.
Authors: We acknowledge that the current feature-importance discussion lacks the quantitative component-wise breakdown requested. We will add ablation experiments that successively remove each information source (narrative embeddings, LDA topics, engineered text features, and categorical attributes) and report permutation-importance scores with bootstrap confidence intervals. These results will be presented in a new table or figure to directly support the claim that the hybrid combination drives the observed lift. revision: yes
Circularity Check
No circularity; empirical evaluation on temporal hold-out is independent
full rationale
The paper reports an empirical ML pipeline: XGBoost trained on earlier complaints and evaluated on later ones, with performance lift measured against a TF-IDF baseline on the held-out set. No equations, derivations, or self-citations appear in the provided text. The AUC improvement (0.69 to 0.78) is a direct out-of-sample metric, not a fitted quantity renamed as prediction. The temporal split and feature-importance analysis are standard and do not reduce to self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
free parameters (1)
- XGBoost hyperparameters
axioms (2)
- domain assumption The temporal split avoids data leakage and concept drift
- domain assumption Complaints can be treated as independent samples suitable for standard supervised classification
Reference graph
Works this paper leans on
-
[1]
Expert Systems with Applications 127, 256–271 (2019)
Bastani, K., Namavari, H., Shaffer, J.: Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Systems with Applications 127, 256–271 (2019). https://doi.org/10.1016/j.eswa.2019.03.001
-
[2]
In: Chiruzzo, L., Ritter, A., Wang, L
Schroeder, K., Wood-Doughty, Z.: Reliability of topic modeling. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) Proceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Computational Linguis- tics: Human Language Technologies (Volume 1: Long Papers), pp. 2649–2662. Association for Computational Linguistics, Albuquer...
-
[3]
International Journal of E-Business Re- search19(1) (2023)
Alarifi, G., Rahman, M.F., Hossain, M.S.: Prediction and analysis of customer com- plaints using machine learning techniques. International Journal of E-Business Re- search19(1) (2023). https://doi.org/10.4018/IJEBR.319716
-
[4]
Data and Information Management7(4), 100046 (2023)
Oyewola, D.O., Omotehinwa, T.O., Dada, E.G.: Consumer complaints of Consumer Financial Protection Bureau via two-stage residual one-dimensional convolutional neural network (TSR1DCNN). Data and Information Management7(4), 100046 (2023). https://doi.org/10.1016/j.dim.2023.100046
-
[5]
Roumeliotis, K.I., Tselikas, N.D., Nasiopoulos, D.K.: Think before you classify: the rise of reasoning large language models for consumer complaint detection and clas- sification. Electronics14(6), 1070 (2025). https://doi.org/10.3390/electronics14061070
-
[6]
Pradhan, M., Vemprala, N., Gudigantala, N.: Beyond zero-shot: enhancing LLM fi- nancial complaint classification with relevancy-driven RAG-based few-shot prompt- ing. In: Bui, T.X. (ed.) Proceedings of the 59th Hawaii International Conference on System Sciences (HICSS), p. 1724 (2026). https://doi.org/10.24251/HICSS.2026.206
-
[7]
arXiv preprint arXiv:2407.06399 (2024)
Vaishnav, D., et al.: Predictive analysis of CFPB consumer complaints using ma- chine learning. arXiv preprint arXiv:2407.06399 (2024)
-
[8]
arXiv preprint arXiv:2506.21623 (2025)
Gao, P., Yang, C., Sun, N., Zitikis, R.: Performance of diverse evaluation metrics in NLP-based assessment and text generation of consumer complaints. arXiv preprint arXiv:2506.21623 (2025)
-
[9]
Ap- plied Science and Engineering Journal for Advanced Research4(1), 65–70 (2025)
Sudhakar, V.M.: LLM for financial services: risk analysis and fraud detection. Ap- plied Science and Engineering Journal for Advanced Research4(1), 65–70 (2025). https://doi.org/10.5281/zenodo.14928807
-
[10]
consumers’ financial exposure to fraud and scams
Fulford, S.: U.S. consumers’ financial exposure to fraud and scams. Working paper, SSRN (2026). https://doi.org/10.2139/ssrn.6396678
-
[11]
arXiv preprint arXiv:2311.16466 (2025)
Shin, M., Kim, J., Shin, J.: The adoption and efficacy of large language mod- els: evidence from consumer complaints in the financial industry. arXiv preprint arXiv:2311.16466 (2025)
-
[12]
Correa,N.,Correa,A.,Zadrozny,W.:GenerativeAIforconsumercommunications: classification, summarization, response generation. In: 2024 IEEE ANDESCON, pp. 1–6. IEEE, Cusco, Peru (2024). https://doi.org/10.1109/ANDESCON61840.2024.10755794 20 Z. Wang et al
-
[13]
The Wharton School Research Paper, SSRN (2024)
Jou, J., Kleymenova, A.V., Passalacqua, A., Sándor, L., Vijayaraghavan, R.: Dis- ciplining banks through disclosure: evidence from CFPB consumer complaints. The Wharton School Research Paper, SSRN (2024). https://doi.org/10.2139/ssrn.5041008
-
[14]
Uddin, M.N.: A regulatory governance framework for AI-driven financial fraud de- tection in U.S. banking: integrating OCC, SR 11-7, CFPB, and FinCEN compliance requirements for model development, validation, and monitoring lifecycles. Working paper, SSRN (2026). https://doi.org/10.2139/ssrn.6690439
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.