Language-Specific Sentiment Polarity Biases in Encoder and Large Language Model Classification of Product Reviews
Pith reviewed 2026-06-26 09:06 UTC · model grok-4.3
The pith
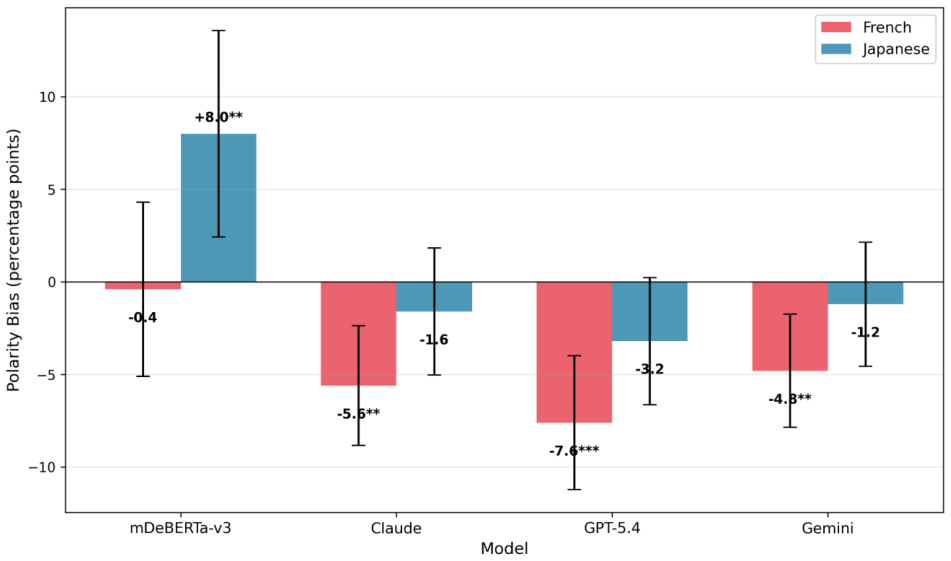
Large language models classify French product reviews with a negative bias, while encoder models miss negative Japanese reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that sentiment polarity biases are specific to both the language and the model architecture, with LLMs showing negative bias in French and encoder models showing positive bias in Japanese.
What carries the argument
Experimental evaluation of classification accuracy on positive and negative product reviews in multiple languages using both encoder models and large language models.
If this is right
- Multilingual sentiment systems may systematically misclassify sentiments in French when using LLMs.
- Encoder models may overlook criticism in Japanese reviews that is not direct.
- Business applications relying on these models could make incorrect decisions based on skewed sentiment data in certain languages.
- Adjustments or fine-tuning may be needed for different languages to correct for these biases.
Where Pith is reading between the lines
- Biases could be tested by translating reviews between languages to isolate the effect of language.
- Cultural differences in expressing negativity might contribute to the observed patterns in Japanese.
- Other languages might show similar architecture-dependent biases if tested.
Load-bearing premise
The accuracy differences are caused by language-specific polarity biases in the models rather than by differences in the product review datasets, annotation quality, or other experimental factors.
What would settle it
If the same pattern of biases is not observed when the experiment is repeated with reviews that have been translated to maintain the same content across languages, the claim of language-specific model biases would be challenged.
Figures
read the original abstract
This study investigates sentiment polarity biases, specifically, differences in how accurately AI models classify positive versus negative reviews across languages and model architectures. Large language models show a negative bias in French and are more accurate on negative reviews, while encoder models exhibit positive bias in Japanese, missing negative reviews that use indirect criticism. These language-specific polarity biases have implications in both social and business domains deploying multilingual sentiment analysis systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study of sentiment classification on product reviews, claiming that large language models exhibit a negative polarity bias in French (higher accuracy on negative reviews) while encoder models show a positive bias in Japanese (failing to detect indirect negative criticism).
Significance. If the central attribution to model biases can be isolated from dataset confounds, the findings would be relevant for multilingual NLP deployment in social media monitoring and e-commerce, as they identify architecture- and language-specific failure modes.
major comments (2)
- [Experimental Setup / Results] The attribution of accuracy differences to language-specific model polarity biases (abstract and §4) requires explicit controls; without per-language, per-class statistics on review length, positive/negative balance, lexical indirectness, and annotation reliability, the patterns could arise from unmatched corpora rather than model properties.
- [Abstract / Results] No information is supplied on dataset sizes, statistical significance tests, or error bars for the reported accuracy gaps (abstract and §3), preventing assessment of whether the observed French/Japanese differences are reliable or practically meaningful.
minor comments (1)
- [Abstract] The abstract sentence beginning 'specifically, differences...' is grammatically awkward and should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas where additional controls and statistical reporting will strengthen the attribution of results to model biases. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experimental Setup / Results] The attribution of accuracy differences to language-specific model polarity biases (abstract and §4) requires explicit controls; without per-language, per-class statistics on review length, positive/negative balance, lexical indirectness, and annotation reliability, the patterns could arise from unmatched corpora rather than model properties.
Authors: We agree that isolating model-specific polarity biases from potential dataset confounds requires these controls. In the revised version, we will add per-language, per-class statistics on review length distributions, positive/negative class balance, quantitative proxies for lexical indirectness (such as frequency of negation and indirect phrasing patterns), and annotation reliability metrics (e.g., inter-annotator agreement where available or consistency checks). These additions will be presented in a new subsection or table to support the claims in the abstract and §4. revision: yes
-
Referee: [Abstract / Results] No information is supplied on dataset sizes, statistical significance tests, or error bars for the reported accuracy gaps (abstract and §3), preventing assessment of whether the observed French/Japanese differences are reliable or practically meaningful.
Authors: We acknowledge the absence of these details in the current version. The revised manuscript will explicitly report the number of reviews per language and class, include statistical significance tests (e.g., McNemar's test for paired accuracy differences or bootstrap resampling) with p-values, and add error bars or 95% confidence intervals to the accuracy results in the abstract, §3, and associated figures. This will allow readers to evaluate the reliability and practical importance of the reported gaps. revision: yes
Circularity Check
No circularity: empirical measurement study with no derivations or self-referential predictions
full rationale
The paper is an empirical measurement study reporting accuracy differences in sentiment classification across languages and model architectures on product review datasets. It contains no equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations. The central claims rest on direct experimental results that are falsifiable against external data and do not reduce to the paper's own inputs by construction. No enumerated circularity patterns apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vaswani, A., et al. “Attention is all you need.” Advances in Neural Information Processing Systems, 30 (2017). doi:10.48550/arXiv.1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[2]
Overview of the Transformer-based Models for NLP Tasks,
Gillioz, A., et al. "Overview of the Transformer-based Models for NLP Tasks," 15th Conference on Computer Science and Information Systems, pp. 179-183, 2020, https://doi.org/10.15439/2020F20
-
[3]
Sentiment Analysis and Opinion Mining
Liu, B. Sentiment Analysis and Opinion Mining. Synthesis Lectures on Human Language Technologies, 5(1), 1–167 (2012). doi:10.2200/S00416ED1V01Y201204HLT016
-
[4]
How multilingual is Multilingual BERT?
Pires, Telmo, et al. “How multilingual is multilingual BERT?” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4996–5001 (2019). https://doi.org/10.48550/arXiv.1906.01502
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.01502 2019
-
[5]
Zhu, Xingyi, et al. “The model arena for cross-lingual sentiment analysis: A comparative study in the era of large language models.” arXiv preprint arXiv:2406.19358 (2024). https://doi.org/10.48550/arXiv.2406.19358
-
[6]
Sentiment analysis in the age of generative AI
Krugmann, Jan Oliver, and Jochen Hartmann. "Sentiment analysis in the age of generative AI." Customer Needs and Solutions, vol. 11, no. 1, 2024, article 3. https://doi.org/10.1007/s40547-024-00143-4
-
[7]
Beyond Culture
Hall, Edward T. “Beyond Culture”. Anchor Books/Doubleday, 1976
1976
-
[8]
Politeness Strategies Used by Japanese and Indonesian Speakers on Social Media
Sarila et al., “Politeness Strategies Used by Japanese and Indonesian Speakers on Social Media”, Chi e Journal of Japanese Learning and Teaching, 2023, https://doi.org/10.15294/chie.v11i2.74051
-
[9]
The Culture Map: Breaking Through the Invisible Boundaries of Global Business. PublicAffairs
Meyer, Erin. “The Culture Map: Breaking Through the Invisible Boundaries of Global Business. PublicAffairs”, 2014
2014
-
[10]
Sentiment analysis of French movie reviews
Ghorbel, Hatem, and David Jacot. "Sentiment analysis of French movie reviews." Advances in Distributed Agent-Based Retrieval Tools, Studies in Computational Intelligence, vol 361. Springer, 2011, https://doi.org/10.1007/978-3-642-21384-7_7
-
[11]
Benchmarking Zero-shot Text Classification
Yin, Wenpeng, et al. "Benchmarking Zero-shot Text Classification." *EMNLP*, 2019. https://doi.org/10.48550/arXiv.1909.00161
-
[12]
Dong, Zhen, "Exploring cross-cultural communication content adaptability through advanced natural language processing and sentiment analysis." Systems and Soft Computing, vol. 7, 2025, 200290. https://doi.org/10.1016/j.sasc.2025.200290
-
[13]
Training language models to follow instructions with human feedback
Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744. https://doi.org/10.48550/arXiv.2203.02155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[14]
Conversing Across Cultures East-West communication styles in work and nonwork contexts
Sanchez-Burks, J., et al. "Conversing Across Cultures East-West communication styles in work and nonwork contexts" Journal of Personality and Social Psychology, 85(2), 363– 372, 2003, https://doi.org/10.1037/0022-3514.85.2.363
-
[15]
The multilingual Amazon reviews corpus
Keung, Phillip, et al. "The multilingual Amazon reviews corpus." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020, pp. 4563-4568. https://doi.org/10.48550/arXiv.2010.02573
-
[16]
He, P., Gao, J., & Chen, W. “DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing”, 2021, https://doi.org/10.48550/arXiv.2111.09543
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2111.09543 2021
-
[17]
XNLI: Evaluating Cross-lingual Sentence Representations
Alexis, C., et al. XNLI: Evaluating Cross-lingual Sentence Representations. Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, pages 2475–2485, 2018, https://doi.org/10.48550/arXiv.1809.05053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1809.05053 2018
-
[18]
Statistical Power Analysis for the Behavioral Sciences
Cohen, Jacob. Statistical Power Analysis for the Behavioral Sciences. 2nd ed., Lawrence Erlbaum Associates, 1988
1988
-
[19]
SciPy 1.0: Fundamental algorithms for scientific computing in Python
Virtanen, Pauli, et al. "SciPy 1.0: Fundamental algorithms for scientific computing in Python." Nature Methods, vol. 17, 2020, pp. 261-272. https://doi.org/10.1038/s41592-019- 0686-2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.