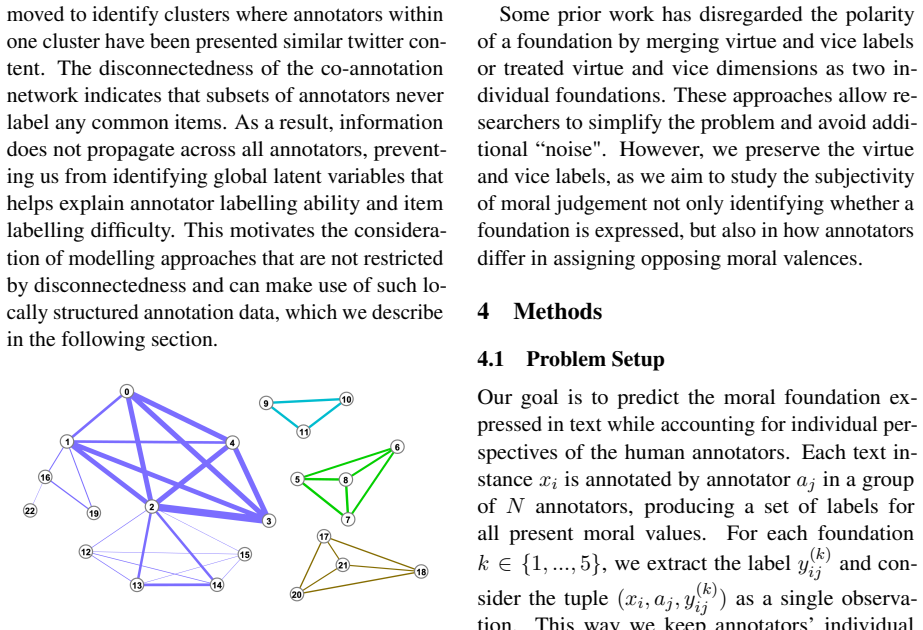
Learning Moral Diversity: Modelling Individual Perspectives in Moral Classification of Texts
Pith reviewed 2026-06-26 08:59 UTC · model grok-4.3
The pith
Adding an annotator-specific layer to language models captures individual moral perspectives in text classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
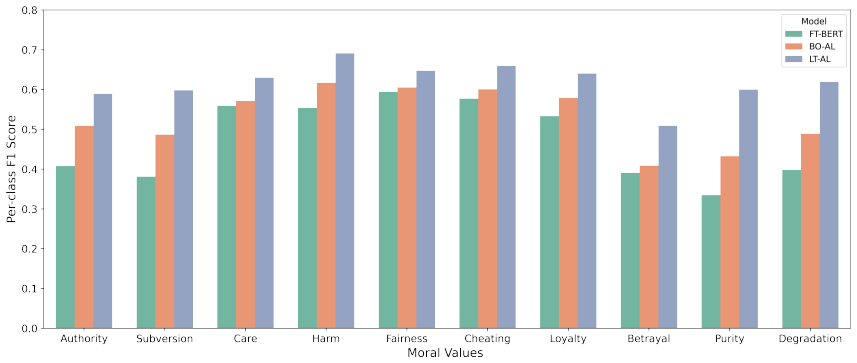
We extend a pretrained language model with a layer that learns annotator-specific features. This model improves predictions of individual annotations and yields representations that reveal meaningful insights into annotators' moral perspectives. Models trained on aggregated labels may hide variation and give a misleading impression of performance. Disagreement reflects the inherent subjectivity of the task and modelling individual perspectives creates benefits for moral classification of texts.
What carries the argument
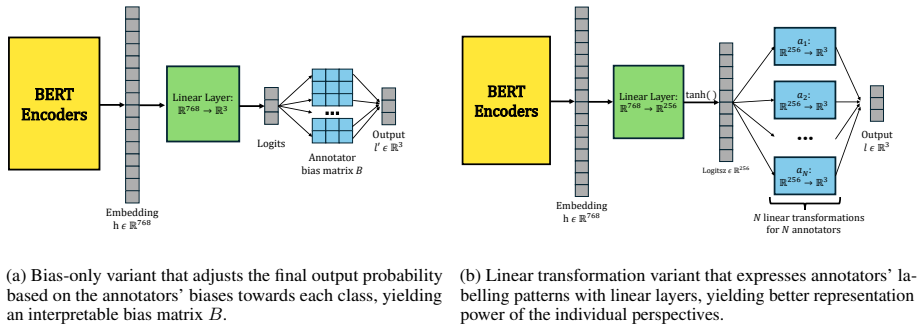
An annotator-specific layer added to a pretrained language model that learns individual features from crowdsourced annotations.
If this is right
- Predictions for how a particular annotator would label a text become more accurate.
- Representations from the model can be used to understand differences in moral perspectives among annotators.
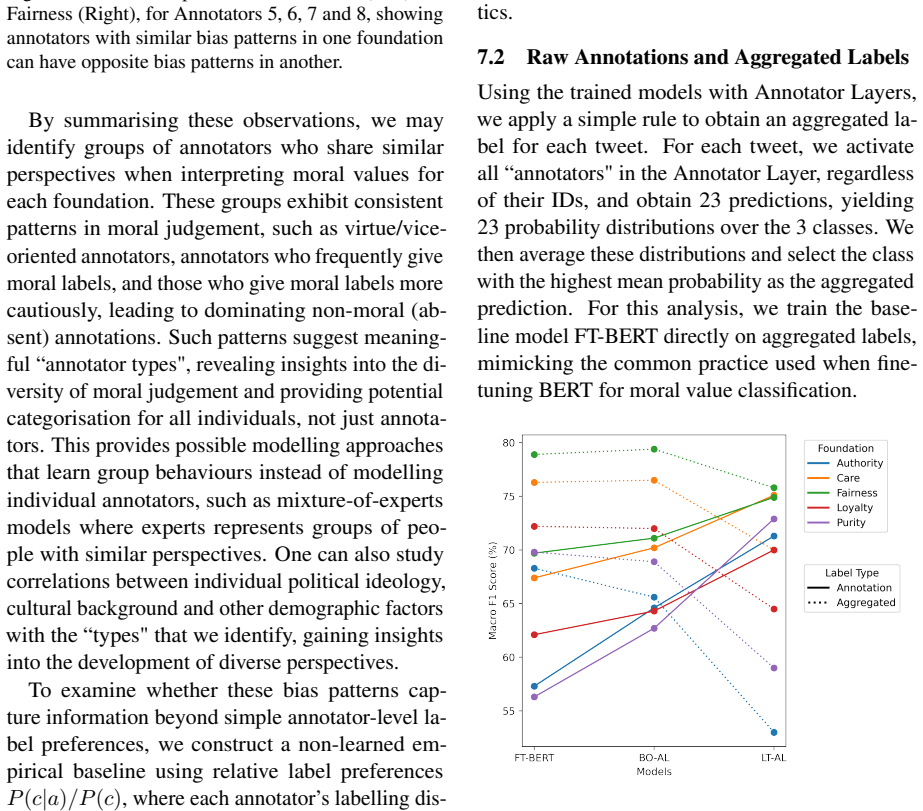
- Aggregating labels into a single ground truth can conceal real variation and overestimate model performance.
- Disagreements in annotations are better treated as signals of subjectivity rather than noise to be averaged out.
Where Pith is reading between the lines
- This method could be tested on other subjective labeling tasks such as emotion detection or hate speech identification to see if individual modeling consistently helps.
- If annotator features correlate with demographic or survey data on values, it would strengthen the case that they capture real perspectives.
- Practitioners might need to collect multiple annotations per item and retain them rather than aggregate, changing data collection practices for value-laden tasks.
Load-bearing premise
The features learned by the annotator-specific layer represent genuine differences in moral perspectives instead of merely capturing random noise or ambiguities in the task.
What would settle it
If the performance improvement from the annotator layer disappears when tested on new annotators not seen during training, or if the learned features do not align with independent measures of annotators' moral beliefs.
Figures



read the original abstract
Understanding moral values in social media text offers insight into moral judgement formation, and supervised NLP models trained on crowdsourced data have achieved strong classification performance. However, most approaches simplify the problem by aggregating multiple annotators' labels into a single "ground truth", overlooking the inherent subjectivity of the task. In practice, there are disagreements between annotators caused by personal viewpoint or inherent ambiguities, particularly for short tweets. Here, we extend a pretrained language model with a layer that learns annotator-specific features. Our model improves predictions of individual annotations and yields representations that reveal meaningful insights into annotators' moral perspectives. We show that models trained on aggregated labels may hide variation and give a misleading impression of performance. Overall, we demonstrate that disagreement reflects the inherent subjectivity of the task and that modelling individual perspectives creates benefits for moral classification of texts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that extending a pretrained language model with an annotator-specific layer allows better prediction of individual annotator labels on moral classification of tweets, produces representations that reveal meaningful insights into annotators' moral perspectives, and demonstrates that aggregating labels into a single ground truth can hide variation and give a misleading impression of performance; overall, it argues that disagreement reflects inherent subjectivity and that modeling individual perspectives benefits the task.
Significance. If the central results hold after proper validation, the work would strengthen the case for treating moral judgment as inherently subjective in NLP rather than assuming a single ground truth, with potential implications for more accurate modeling of annotator variation in crowdsourced datasets.
major comments (2)
- [§3] §3 (Model Architecture): The claim that the annotator-specific layer 'learns annotator-specific features' and yields 'meaningful insights into annotators' moral perspectives' is load-bearing for the central argument, yet the manuscript provides no external validation (e.g., correlation of learned embeddings with independent moral-value inventories or tests on unseen annotators) to distinguish genuine perspective modeling from memorization of per-annotator label patterns or task ambiguities.
- [§5] §5 (Experiments and Results): The reported improvements in predicting individual annotations are presented without error bars, statistical significance tests against strong baselines that also condition on annotator ID, or ablation showing that gains are not reducible to increased model capacity; this undermines the assertion that modeling subjectivity creates benefits beyond aggregated-label approaches.
minor comments (2)
- [Abstract] The abstract and introduction use 'moral classification of texts' and 'moral judgement formation' interchangeably without clarifying the precise label taxonomy or annotation guidelines.
- [Figures] Figure captions and axis labels in the results section should explicitly state whether performance metrics are macro- or micro-averaged and whether they are computed per-annotator or aggregated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (Model Architecture): The claim that the annotator-specific layer 'learns annotator-specific features' and yields 'meaningful insights into annotators' moral perspectives' is load-bearing for the central argument, yet the manuscript provides no external validation (e.g., correlation of learned embeddings with independent moral-value inventories or tests on unseen annotators) to distinguish genuine perspective modeling from memorization of per-annotator label patterns or task ambiguities.
Authors: We agree that external validation against independent moral inventories or generalization tests on unseen annotators would strengthen the interpretation. The manuscript currently supports the claim through improved per-annotator prediction accuracy and qualitative patterns in the learned embeddings. In revision we will add an explicit limitations discussion on this point and, where annotator metadata permits, report correlations with demographic variables as indirect evidence. We do not claim the embeddings have been externally validated beyond the reported experiments. revision: partial
-
Referee: [§5] §5 (Experiments and Results): The reported improvements in predicting individual annotations are presented without error bars, statistical significance tests against strong baselines that also condition on annotator ID, or ablation showing that gains are not reducible to increased model capacity; this undermines the assertion that modeling subjectivity creates benefits beyond aggregated-label approaches.
Authors: We accept that the experimental reporting lacks the requested statistical elements. The revised manuscript will include error bars across runs, significance tests against annotator-ID-conditioned baselines, and an ablation that isolates the contribution of the annotator-specific layer from added capacity. These additions will directly address whether the observed gains exceed what can be obtained by simply increasing model capacity or by conditioning on annotator identity without a dedicated perspective layer. revision: yes
Circularity Check
No significant circularity; empirical modeling claims are self-contained
full rationale
The paper presents an empirical NLP modeling approach: extending a pretrained LM with an annotator-specific layer to capture individual moral perspectives, with performance gains shown via experiments on crowdsourced data. No equations, derivations, or self-citation chains appear in the abstract or described claims that reduce predictions or insights to fitted inputs by construction. Central assertions rely on experimental validation rather than self-referential definitions or uniqueness theorems imported from prior author work. This matches the default expectation of non-circularity for papers without load-bearing mathematical reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Disagreements between annotators are caused by personal viewpoint or inherent ambiguities in the task
invented entities (1)
-
annotator-specific layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2012 , publisher=
The Righteous Mind: Why Good People are Divided by Politics and Religion , author=. 2012 , publisher=
2012
-
[2]
Moral Foundations Theory: The pragmatic validity of moral pluralism
Graham, Jesse and Haidt, Jonathan and Koleva, Sena and Motyl, Matt and Iyer, Ravi and Wojcik, Sean P and Ditto, Peter H. Moral Foundations Theory: The pragmatic validity of moral pluralism. Advances in Experimental Social Psychology
-
[3]
Mapping the moral domain
Graham, Jesse and Nosek, Brian A and Haidt, Jonathan and Iyer, Ravi and Koleva, Spassena and Ditto, Peter H. Mapping the moral domain. J. Pers. Soc. Psychol
-
[4]
Morality beyond the WEIRD : How the nomological network of morality varies across cultures
Atari, Mohammad and Haidt, Jonathan and Graham, Jesse and Koleva, Sena and Stevens, Sean T and Dehghani, Morteza. Morality beyond the WEIRD : How the nomological network of morality varies across cultures. J. Pers. Soc. Psychol
-
[5]
When morality opposes justice: Conservatives have moral intuitions that liberals may not recognize
Haidt, Jonathan and Graham, Jesse. When morality opposes justice: Conservatives have moral intuitions that liberals may not recognize. Soc. Justice Res
-
[6]
The extended Moral Foundations Dictionary ( eMFD) : Development and applications of a crowd-sourced approach to extracting moral intuitions from text
Hopp, Frederic R and Fisher, Jacob T and Cornell, Devin and Huskey, Richard and Weber, Ren \'e. The extended Moral Foundations Dictionary ( eMFD) : Development and applications of a crowd-sourced approach to extracting moral intuitions from text. Behav. Res. Methods
-
[7]
2012 , howpublished =
Graham, Jesse and Haidt, Jonathan , title =. 2012 , howpublished =
2012
-
[8]
Frimer, J. A. and Boghrati, R. and Haidt, J. and Graham, J. and Dehgani, M. , title =. 2019 , howpublished =
2019
-
[9]
MoralStrength : Exploiting a moral lexicon and embedding similarity for moral foundations prediction
Araque, Oscar and Gatti, Lorenzo and Kalimeri, Kyriaki. MoralStrength : Exploiting a moral lexicon and embedding similarity for moral foundations prediction. Knowl. Based Syst
-
[10]
Acquiring background knowledge to improve moral value prediction , year=
Lin, Ying and Hoover, Joe and Portillo-Wightman, Gwenyth and Park, Christina and Dehghani, Morteza and Ji, Heng , booktitle=. Acquiring background knowledge to improve moral value prediction , year=
-
[11]
Measuring moral dimensions in social media with Mformer
Nguyen, Tuan Dung and Chen, Ziyu and Carroll, Nicholas George and Tran, Alasdair and Klein, Colin and Xie, Lexing. Measuring moral dimensions in social media with Mformer. Proceedings of the International AAAI Conference on Web and Social Media
-
[12]
Proceedings of the 2024 International Conference on Information Technology for Social Good , pages =
Preniqi, Vjosa and Ghinassi, Iacopo and Ive, Julia and Saitis, Charalampos and Kalimeri, Kyriaki , title =. Proceedings of the 2024 International Conference on Information Technology for Social Good , pages =. 2024 , publisher =. doi:10.1145/3677525.3678694 , abstract =
-
[13]
BERT: Pre-training of deep bidirectional transformers for language understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[14]
Moral narratives around the vaccination debate on Facebook , year =
Beir\'. Moral narratives around the vaccination debate on Facebook , year =. Proceedings of the ACM Web Conference 2023 , pages =. doi:10.1145/3543507.3583865 , abstract =
-
[15]
Learning to adapt domain shifts of moral values via instance weighting
Huang, Xiaolei and Wormley, Alexandra and Cohen, Adam. Learning to adapt domain shifts of moral values via instance weighting. Proceedings of the 33rd ACM Conference on Hypertext and Social Media
-
[16]
arXiv preprint arXiv:2208.05545 , year=
The Moral Foundations Reddit Corpus , author=. arXiv preprint arXiv:2208.05545 , year=
-
[17]
Moral Foundations Twitter Corpus: A collection of 35k tweets annotated for moral sentiment
Hoover, Joe and Portillo-Wightman, Gwenyth and Yeh, Leigh and Havaldar, Shreya and Davani, Aida Mostafazadeh and Lin, Ying and Kennedy, Brendan and Atari, Mohammad and Kamel, Zahra and Mendlen, Madelyn and Moreno, Gabriela and Park, Christina and Chang, Tingyee E and Chin, Jenna and Leong, Christian and Leung, Jun Yen and Mirinjian, Arineh and Dehghani, M...
-
[18]
A data fusion framework for multi-domain morality learning
Guo, Siyi and Mokhberian, Negar and Lerman, Kristina. A data fusion framework for multi-domain morality learning. Proceedings of the International AAAI Conference on Web and Social Media
-
[19]
Moral values underpinning COVID-19 online communication patterns
Jiang, Julie and Luceri, Luca and Ferrara, Emilio. Moral values underpinning COVID-19 online communication patterns. Companion Proceedings of the ACM on Web Conference 2025
2025
-
[20]
PyTorch: An imperative style, high-performance deep learning library , journal =
Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas K. PyTorch: An imperative style, high-performance deep learning library , journal =. 2019 , url =. 1912.01703 , timestamp =
Pith/arXiv arXiv 2019
-
[21]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[22]
Alvin Zhou and Wenlin Liu and Hye Min Kim and Eugene Lee and Jieun Shin and Yafei Zhang and Ke M. Huang-Isherwood and Chuqing Dong and Aimei Yang , title = "Moral foundations, ideological divide, and public engagement with U.S. government agencies’. Mass Communication and Society , volume =. 2024 , publisher =. doi:10.1080/15205436.2022.2151919 , URL =
-
[23]
The emotional dog and its rational tail: A social intuitionist approach to moral judgment
Haidt, Jonathan. The emotional dog and its rational tail: A social intuitionist approach to moral judgment. Psychol. Rev
-
[24]
Affect, culture, and morality, or is it wrong to eat your dog?
Haidt, J and Koller, S H and Dias, M G. Affect, culture, and morality, or is it wrong to eat your dog?. J. Pers. Soc. Psychol
-
[25]
Groups as moral anchors
Ellemers, Naomi and Van der Toorn, Jojanneke. Groups as moral anchors. Curr. Opin. Psychol
-
[26]
Tracing the threads: How five moral concerns (especially Purity ) help explain culture war attitudes
Koleva, Spassena P and Graham, Jesse and Iyer, Ravi and Ditto, Peter H and Haidt, Jonathan. Tracing the threads: How five moral concerns (especially Purity ) help explain culture war attitudes. J. Res. Pers
-
[27]
Scikit-learn: Machine learning in
Pedregosa, Fabian and Varoquaux, Ga\". Scikit-learn: Machine learning in. J. Mach. Learn. Res. , month = nov, pages =. 2011 , issue_date =
2011
-
[28]
Liberals and conservatives rely on different sets of moral foundations
Graham, Jesse and Haidt, Jonathan and Nosek, Brian A. Liberals and conservatives rely on different sets of moral foundations. J. Pers. Soc. Psychol
-
[29]
, title =
Rodrigues, Filipe and Pereira, Francisco C. , title =. Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence , articleno =. 2018 , publisher =
2018
-
[30]
and Araque, Oscar
Alvarez Nogales, Anny D. and Araque, Oscar. Moral Disagreement over Serious Matters: Discovering the Knowledge Hidden in the Perspectives. Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024. 2024
2024
-
[31]
and Gead a u, Andrei and Jonker, Catholijn M
Liscio, Enrico and Dondera, Alin E. and Gead a u, Andrei and Jonker, Catholijn M. and Murukannaiah, Pradeep K. Cross-Domain Classification of Moral Values. Findings of the Association for Computational Linguistics: NAACL 2022. 2022. doi:10.18653/v1/2022.findings-naacl.209
-
[32]
What If Ground Truth Is Subjective? Personalized Deep Neural Hate Speech Detection
Kanclerz, Kamil and Gruza, Marcin and Karanowski, Konrad and Bielaniewicz, Julita and Milkowski, Piotr and Kocon, Jan and Kazienko, Przemyslaw. What If Ground Truth Is Subjective? Personalized Deep Neural Hate Speech Detection. Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022. 2022
2022
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Toward a Perspectivist Turn in Ground Truthing for Predictive Computing , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i6.25840 , abstractNote=
-
[34]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Davani, Aida Mostafazadeh and D \'i az, Mark and Prabhakaran, Vinodkumar. Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00449
-
[35]
Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Mokhberian, Negar and Marmarelis, Myrl and Hopp, Frederic and Basile, Valerio and Morstatter, Fred and Lerman, Kristina. Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Lo...
-
[36]
Cost-Efficient Subjective Task Annotation and Modeling through Few-Shot Annotator Adaptation
Golazizian, Preni and Salkhordeh Ziabari, Alireza and Omrani, Ali and Dehghani, Morteza. Cost-Efficient Subjective Task Annotation and Modeling through Few-Shot Annotator Adaptation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.199
-
[37]
URL https: //aclanthology.org/2025.acl-long.104/
Orlikowski, Matthias and Pei, Jiaxin and R. Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.104
-
[38]
2018 , publisher=
Content Analysis: An Introduction to Its Methodology , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.