The Origins of Stochasticity: Comprehensive Investigations on Uncertainty Quantification for Large Language Models
Pith reviewed 2026-06-26 09:02 UTC · model grok-4.3
The pith
Consensus-based uncertainty quantification methods outperform other approaches for large language models, with larger models showing lower uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
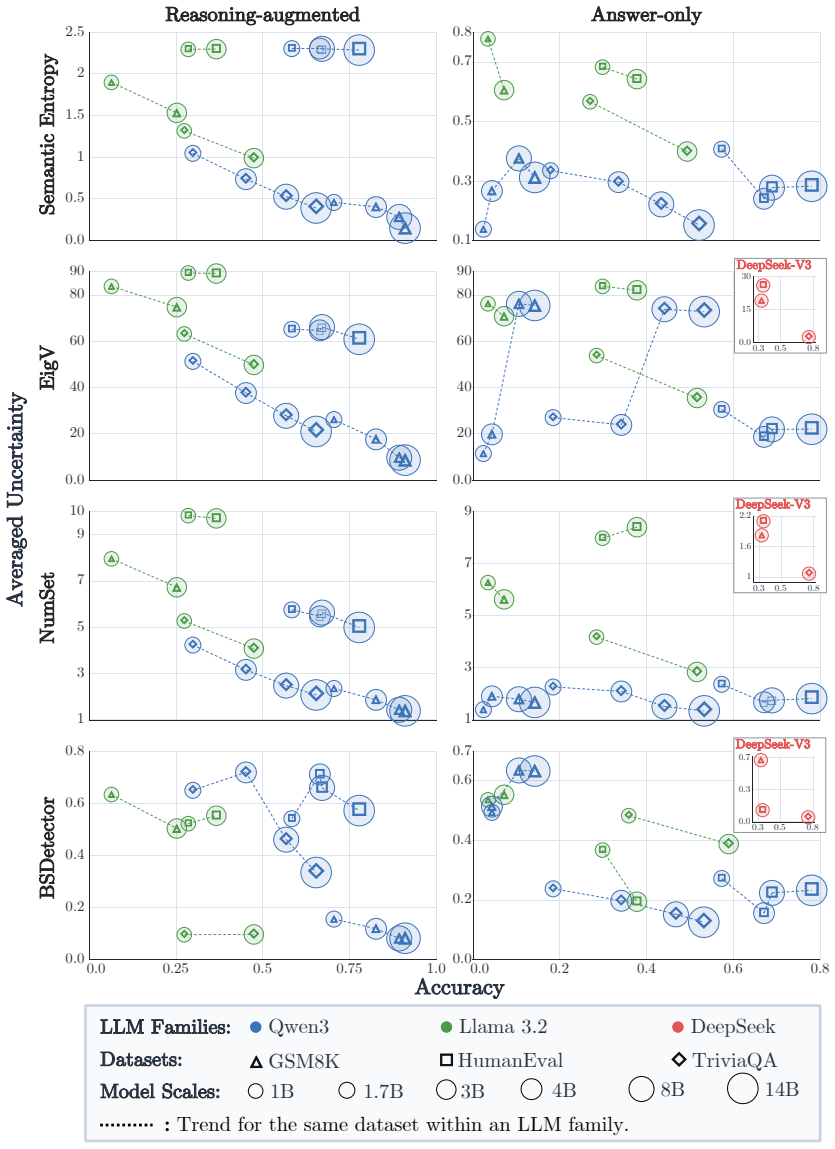
The paper claims that its four-source uncertainty taxonomy allows for a systematic categorization of UQ methods, and that experiments demonstrate consensus-based methods outperform others while larger model scales correlate with lower uncertainty estimates, suggesting an empirical scaling law.
What carries the argument
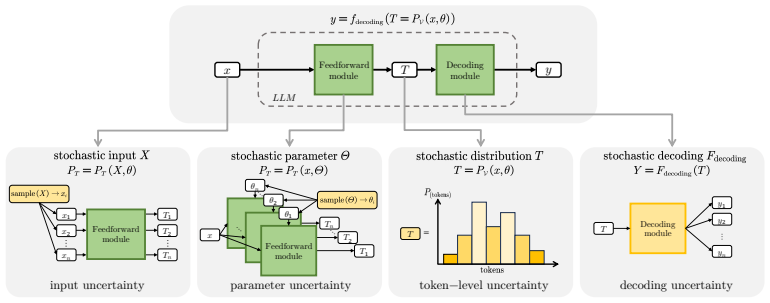
The four-source uncertainty taxonomy (input, parameter, token, decoding-process) that supports categorizing and evaluating UQ methods.
If this is right
- Effectiveness of UQ methods is sensitive to task types and generation settings.
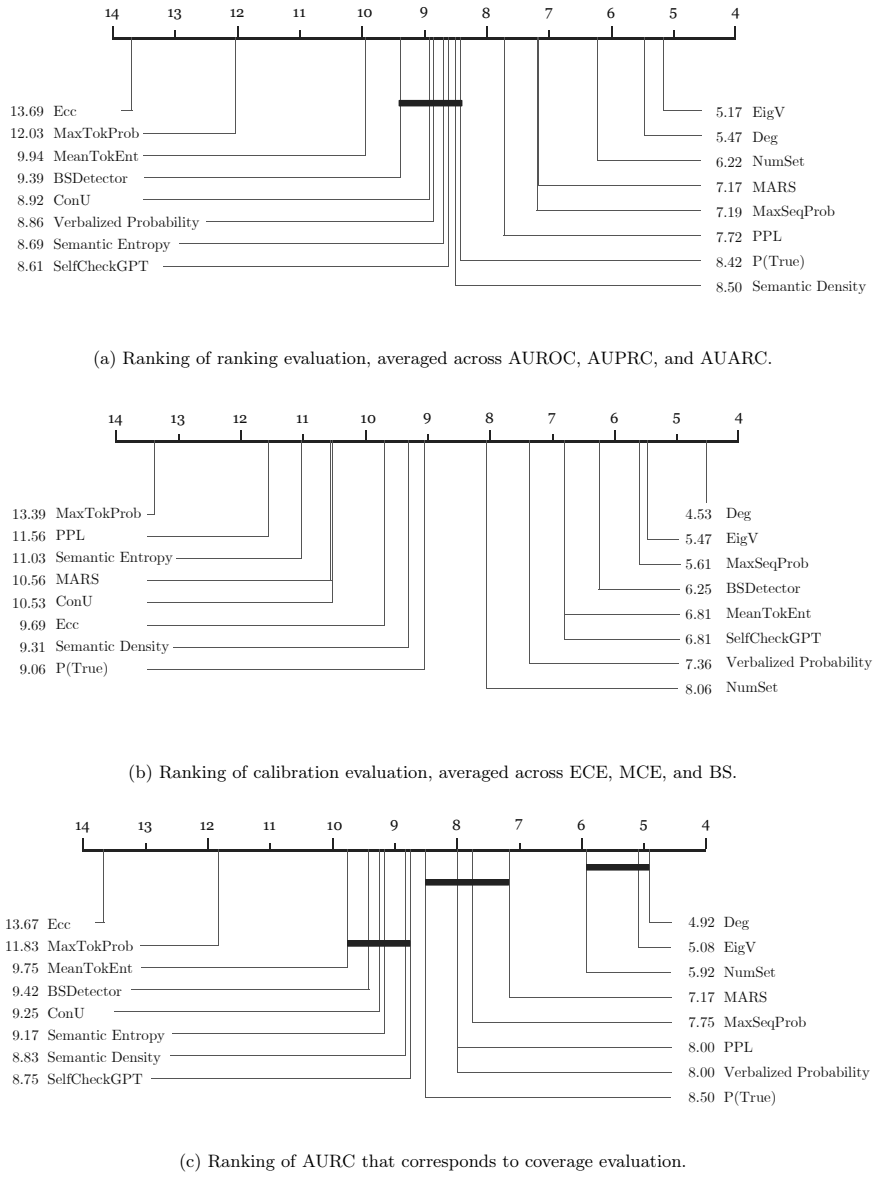
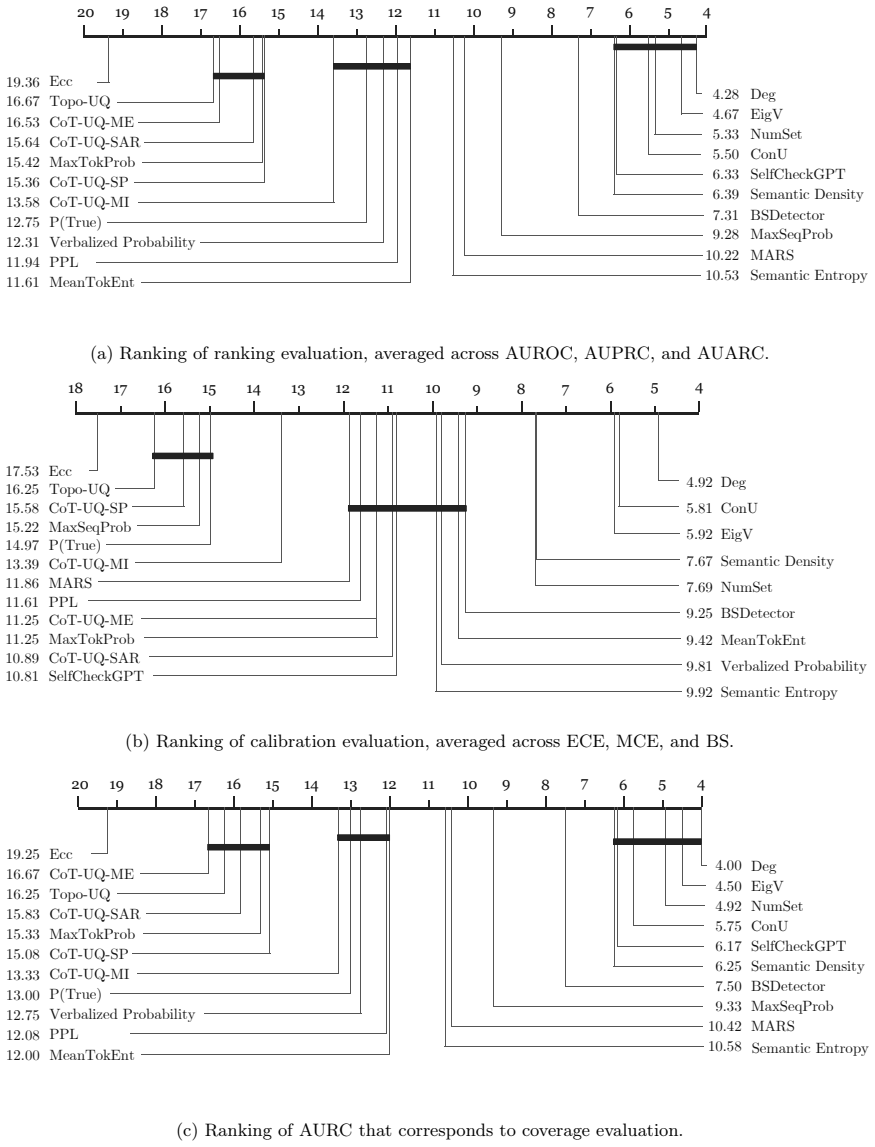
- Consensus-based methods like Deg and EigV consistently outperform other UQ approaches.
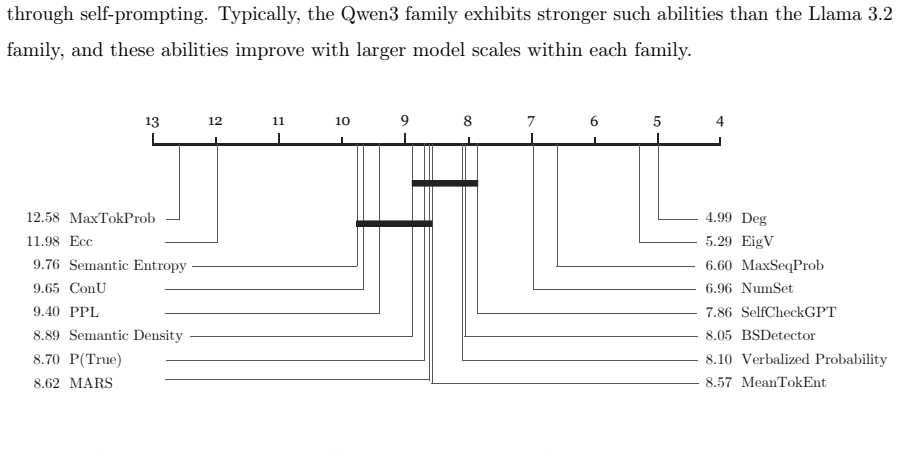
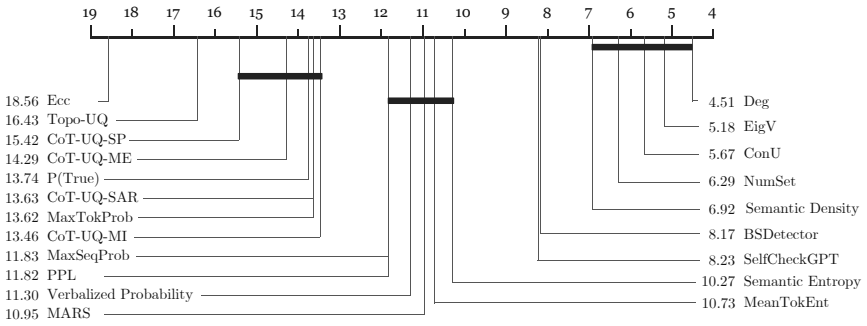
- Larger model scales correlate with lower uncertainty estimates.
- This indicates an empirical scaling law for LLM uncertainty.
Where Pith is reading between the lines
- The taxonomy might enable targeted improvements in UQ by addressing specific sources separately.
- The scaling observation could imply that uncertainty issues diminish naturally with model advancement.
- Consensus methods may be preferred in applications where reliability is critical.
Load-bearing premise
The proposed four-source taxonomy systematically and non-overlappingly attributes uncertainty sources in LLM generation.
What would settle it
An observation that the uncertainty sources overlap significantly or that consensus-based methods fail to outperform on new tasks would falsify the main results.
Figures
read the original abstract
Recent advancements in Large Language Models (LLMs) have enabled sophisticated reasoning and content generation, yet their inherent stochasticity poses significant challenges for ensuring predictive credibility. While traditional uncertainty taxonomy paradigms, such as the dichotomy of aleatoric and epistemic uncertainties, provide conceptual foundations, they often fail to capture the multi-component and multi-stage nature of LLM generation and struggle to evaluate the effectiveness of various Uncertainty Quantification (UQ) methods. In this paper, we propose a granular uncertainty taxonomy that systematically attributes LLM uncertainty into input-level, parameter-level, token-level, and decoding-process sources. Correspondingly, we categorize existing UQ methods into Bayesian, ensemble, consensus-based, and single-pass approaches. Furthermore, we introduce a comprehensive evaluation framework covering diverse generation settings and metrics. We empirically evaluate 21 typical UQ methods across three prominent LLM families, including Qwen3, Llama 3.2, and DeepSeek-V3, on benchmarks such as TriviaQA, GSM8K, and HumanEval. Our experimental results demonstrate that (i) the effectiveness of UQ methods is sensitive to task types and generation settings; (ii) consensus-based methods, typed Deg and EigV, consistently outperform other UQ approaches; and (iii) larger model scales correlate with lower uncertainty estimates, suggesting an empirical scaling law for LLM uncertainty. This work bridges the gap between theoretical origins and practical deployment, providing a versatile diagnostic tool for systematically quantifying uncertainty in LLM applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a four-source taxonomy for uncertainty in LLMs (input-level, parameter-level, token-level, decoding-process sources) and correspondingly categorizes 21 UQ methods into Bayesian, ensemble, consensus-based, and single-pass approaches. It presents an evaluation framework and reports empirical results on Qwen3, Llama 3.2, and DeepSeek-V3 across TriviaQA, GSM8K, and HumanEval, claiming that (i) UQ effectiveness is sensitive to task type and generation settings, (ii) consensus-based methods (Deg, EigV) consistently outperform the other categories, and (iii) larger model scales correlate with lower uncertainty estimates, suggesting an empirical scaling law.
Significance. If the taxonomy can be shown to provide a non-overlapping partition and the empirical comparisons are placed on a statistically sound footing, the work would supply a structured diagnostic lens for LLM uncertainty that could guide method selection and connect theoretical sources to practical UQ performance. The reported scaling observation would also be of interest if replicated.
major comments (2)
- [Abstract and taxonomy section] Abstract and taxonomy section: the claim that the four sources 'systematically attribute' uncertainty without overlap is load-bearing for the subsequent categorization of the 21 methods and for the interpretation that consensus-based methods outperform because they target a distinct source; no formal disjointness argument, exhaustive mapping, or check for re-interpretability (e.g., a single-pass method also being parameter-level) is supplied.
- [Experimental results section] Experimental results section: the statement that Deg and EigV 'consistently outperform' other approaches requires, at minimum, per-benchmark tables with means, standard deviations or error bars, and a statistical test across the three model families; the abstract supplies none of these, leaving open whether observed gaps are significant or artifacts of implementation details within each category.
minor comments (2)
- [Notation and tables] Ensure every abbreviation (Deg, EigV, etc.) is defined on first use and that the exact assignment of each of the 21 methods to one of the four categories is tabulated for reproducibility.
- [Evaluation framework] Clarify the precise generation settings (temperature, top-p, etc.) and the exact metrics used for each benchmark so that the sensitivity claim in (i) can be verified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our taxonomy and strengthen the empirical claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and taxonomy section] Abstract and taxonomy section: the claim that the four sources 'systematically attribute' uncertainty without overlap is load-bearing for the subsequent categorization of the 21 methods and for the interpretation that consensus-based methods outperform because they target a distinct source; no formal disjointness argument, exhaustive mapping, or check for re-interpretability (e.g., a single-pass method also being parameter-level) is supplied.
Authors: We agree that the manuscript does not supply a formal proof of disjointness or an exhaustive re-interpretability check. The taxonomy is motivated by the sequential stages of LLM generation (input encoding, parameter sampling during inference, per-token distribution, and decoding strategy), which we treat as primary attribution sources. While conceptual overlaps are possible in edge cases, the categorization of the 21 methods follows these primary attributions. We will add a dedicated subsection in the taxonomy section that discusses potential overlaps, provides an explicit mapping table, and acknowledges limitations in strict disjointness. revision: yes
-
Referee: [Experimental results section] Experimental results section: the statement that Deg and EigV 'consistently outperform' other approaches requires, at minimum, per-benchmark tables with means, standard deviations or error bars, and a statistical test across the three model families; the abstract supplies none of these, leaving open whether observed gaps are significant or artifacts of implementation details within each category.
Authors: We acknowledge that the current presentation of results does not include the requested statistical rigor in the reported tables or abstract. The full experimental section contains per-benchmark scores, but we will revise it to include (i) expanded tables with means and standard deviations computed over multiple runs, (ii) error bars in figures, and (iii) paired statistical tests (e.g., Wilcoxon signed-rank) across the three model families to assess whether performance gaps are significant. These additions will be reflected in both the results section and a revised abstract. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks and standard models
full rationale
The paper proposes a four-source taxonomy and corresponding four-way categorization of UQ methods, then reports empirical performance on public benchmarks (TriviaQA, GSM8K, HumanEval) and standard model families (Qwen3, Llama 3.2, DeepSeek-V3). No equations, fitted parameters, or self-citations are shown to reduce the central claims (consensus-based methods outperform; scaling law) to the taxonomy by construction. The taxonomy is presented as a proposed attribution scheme rather than a self-definitional mapping, and the evaluation framework uses independent data and metrics. This satisfies the default expectation of a self-contained empirical study against external references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM generation involves distinct and attributable uncertainty sources at input, parameter, token, and decoding stages
Reference graph
Works this paper leans on
-
[1]
Abbasi-Yadkori, Y., Kuzborskij, I., György, A., and Szepesvári, C. (2024). To believe or not to believe your LLM: Iterative prompting for estimating epistemic uncertainty. InAdvances in Neural Information Processing Systems 37, pages 58077–58117
2024
-
[2]
K., Pleiss, G., Zemel, R
Abe, T., Buchanan, E. K., Pleiss, G., Zemel, R. S., and Cunningham, J. P. (2022). Deep ensembles work, but are they necessary? InAdvances in Neural Information Processing Systems 35, pages 33646–33660
2022
-
[3]
Ao, S., Rueger, S., and Siddharthan, A. (2024). CSS: Contrastive semantic similarity for uncertainty quantification of LLMs.arXiv preprint arXiv:2406.03158
arXiv 2024
-
[4]
Baba, K., Liu, C., Kurita, S., and Sannai, A. (2025). Prover agent: An agent-based framework for formal mathematical proofs.arXiv preprint arXiv:2506.19923
arXiv 2025
-
[5]
F., Kang, S., Huang, Z., Yaldiz, D
Bakman, Y. F., Kang, S., Huang, Z., Yaldiz, D. N., Belém, C. G., Zhu, C., Kumar, A., Samuel, A., Avestimehr, S., Liu, D., and Karimireddy, S. P. (2025). Uncertainty as feature gaps: Epistemic uncertainty quantification of LLMs in contextual question-answering.arXiv preprint arXiv:2510.02671
arXiv 2025
-
[6]
F., Yaldiz, D
Bakman, Y. F., Yaldiz, D. N., Buyukates, B., Tao, C., Dimitriadis, D., and Avestimehr, S. (2024). MARS: Meaning-aware response scoring for uncertainty estimation in generative LLMs. InProceed- ings of the 20th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 7752–7767
2024
-
[7]
Balabanov, O. and Linander, H. (2024). Uncertainty quantification in fine-tuned LLMs using LoRA ensembles.arXiv preprint arXiv:2402.12264
arXiv 2024
-
[8]
Band, N., Li, X., Ma, T., and Hashimoto, T. (2024). Linguistic calibration of long-form generations. InProceedings of the 41st International Conference on Machine Learning, pages 2732–2778
2024
-
[9]
Becker, E. and Soatto, S. (2024). Cycles of thought: Measuring LLM confidence through stable explanations.arXiv preprint arXiv:2406.03441
arXiv 2024
-
[10]
Blundell, C., Cornebise, J., Kavukcuoglu, K., and Wierstra, D. (2015). Weight uncertainty in neural network. InProceedings of the 32nd International Conference on Machine Learning, pages 1613–1622
2015
-
[11]
Brier, W. G. (1950). Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3
1950
-
[12]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, 40 R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radfor...
2020
-
[13]
Chen, C., Liu, K., Chen, Z., Gu, Y., Wu, Y., Tao, M., Fu, Z., and Ye, J. (2024). INSIDE: LLMs’ internal states retain the power of hallucination detection. InProceedings of the 12th International Conference on Learning Representations
2024
-
[14]
and Mueller, J
Chen, J. and Mueller, J. (2024). Quantifying uncertainty in answers from any language model and enhancing their trustworthiness. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 5186–5200
2024
-
[15]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Ch...
Pith/arXiv arXiv 2021
-
[16]
Chen, Q., Qin, L., Liu, J., Peng, D., Guan, J., Wang, P., Hu, M., Zhou, Y., Gao, T., and Che, W. (2025a). Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567
-
[17]
Chen, T., Liu, X., Da, L., Chen, J., Papalexakis, V., and Wei, H. (2025b). Uncertainty quantification of large language models through multi-dimensional responses.arXiv preprint arXiv:2502.16820
-
[18]
and Li, Y
Chen, W. and Li, Y. (2023). Calibrating transformers via sparse gaussian processes. InProceedings of the 11th International Conference on Learning Representations
2023
-
[19]
J., Gibbs, I., and Candès, E
Cherian, J. J., Gibbs, I., and Candès, E. J. (2024). Large language model validity via enhanced conformal prediction methods. InAdvances in Neural Information Processing Systems 37, pages 114812–114842
2024
-
[20]
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. (2021). Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168. 41
Pith/arXiv arXiv 2021
-
[21]
Da, L., Chen, T., Cheng, L., and Wei, H. (2024). LLM uncertainty quantification through directional entailment graph and claim level response augmentation.arXiv preprint arXiv:2407.00994
arXiv 2024
-
[22]
Da, L., Liu, X., Dai, J., Cheng, L., Wang, Y., and Wei, H. (2025). Understanding the uncertainty of LLM explanations: A perspective based on reasoning topology. InProceedings of the 2nd Conference on Language Modeling
2025
-
[23]
CanlinearprobesmeasureLLMuncertainty? arXiv preprint arXiv:2510.04108
Dakhmouche, R., Letellier, A., andGorji, M.H.(2025). CanlinearprobesmeasureLLMuncertainty? arXiv preprint arXiv:2510.04108
arXiv 2025
-
[24]
Darrin, M., Piantanida, P., and Colombo, P. (2023). RainProof: An umbrella to shield text generator from out-of-distribution data. InProceedings of the 28th Conference on Empirical Methods in Natural Language Processing, pages 5831–5857
2023
-
[25]
and Goadrich, M
Davis, J. and Goadrich, M. H. (2006). The relationship between precision-recall and ROC curves. InProceedings of the 23rd International Conference on Machine Learning, pages 233–240
2006
-
[26]
DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437
DeepSeek-AI (2024). DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437
Pith/arXiv arXiv 2024
-
[27]
Dinh, T. A. and Niehues, J. (2025). Are generative models underconfident? better quality estimation with boosted model probability. InProceedings of the 30th Conference on Empirical Methods in Natural Language Processing, pages 3364–3382
2025
-
[28]
Du, X., Xiao, C., and Li, S. (2024). HaloScope: Harnessing unlabeled LLM generations for hallucination detection. InAdvances in Neural Information Processing Systems 37, pages 102948– 102972
2024
-
[29]
Duan, J., Cheng, H., Wang, S., Zavalny, A., Wang, C., Xu, R., Kailkhura, B., and Xu, K. (2024). Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 5050–5063
2024
-
[30]
Fadeeva, E., Rubashevskii, A., Shelmanov, A., Petrakov, S., Li, H., Mubarak, H., Tsymbalov, E., Kuzmin, G., Panchenko, A., Baldwin, T., Nakov, P., and Panov, M. (2024). Fact-checking the output of large language models via token-level uncertainty quantification. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pag...
2024
-
[31]
Fan, A., Lewis, M., and Dauphin, Y. N. (2018). Hierarchical neural story generation. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 889–898
2018
-
[32]
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y. (2024). Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630. 42
2024
-
[33]
Unsupervisedqualityestimationforneuralmachinetranslation.Transactions of the Association for Computational Linguistics, 8:539–555
Fomicheva, M., Sun, S., Yankovskaya, L., Blain, F., Guzmán, F., Fishel, M., Aletras, N., Chaudhary, V., andSpecia, L.(2020). Unsupervisedqualityestimationforneuralmachinetranslation.Transactions of the Association for Computational Linguistics, 8:539–555
2020
-
[34]
and Ghahramani, Z
Gal, Y. and Ghahramani, Z. (2016). Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of The 33rd International Conference on Machine Learning, pages 1050–1059
2016
-
[35]
Gao, X., Zhang, J., Mouatadid, L., and Das, K. (2024). SPUQ: Perturbation-based uncertainty quantification for large language models. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, pages 2336–2346
2024
-
[36]
Geifman, Y., Uziel, G., and El-Yaniv, R. (2019). Bias-reduced uncertainty estimation for deep neural classifiers. InProceedings of the 7th International Conference on Learning Representations
2019
-
[37]
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. (2017). On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning, pages 1321–1330
2017
-
[38]
He, J., Gong, Y., Chen, K., Lin, Z., Wei, C., and Zhao, Y. (2023). LLM factoscope: Uncovering LLMs’ factual discernment through inner states analysis.arXiv preprint arXiv:2312.16374
arXiv 2023
-
[39]
He, P., Liu, X., Gao, J., and Chen, W. (2021). DeBERTa: Decoding-enhanced BERT with disen- tangled attention. InProceedings of the 9th International Conference on Learning Representations
2021
-
[40]
Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y. (2020). The curious case of neural text degeneration. InProceedings of the 8th International Conference on Learning Representations
2020
-
[41]
Hou, B., Liu, Y., Qian, K., Andreas, J., Chang, S., and Zhang, Y. (2024). Decomposing uncer- tainty for large language models through input clarification ensembling. InProceedings of the 35th International Conference on Machine Learning, pages 19023–19042
2024
-
[42]
and Waegeman, W
Hüllermeier, E. and Waegeman, W. (2021). Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods.Machine Learning, 110(3):457–506
2021
-
[43]
S., and Zettlemoyer, L
Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. (2017). TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611
2017
-
[44]
V., Laga, H., Boussaïd, F., Buntine, W
Jospin, L. V., Laga, H., Boussaïd, F., Buntine, W. L., and Bennamoun, M. (2022). Hands-on bayesian neural networks - A tutorial for deep learning users.IEEE Computational Intelligence Magazine, 17(2):29–48. 43
2022
-
[45]
and Yuki, A
Junya, T. and Yuki, A. (2019). Relevant and informative response generation using pointwise mutual information. InProceedings of the 1st Workshop on NLP for Conversational AI, pages 133–138
2019
-
[46]
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield- Dodds, Z., DasSarma, N., Tran-Johnson, E., Johnston, S., Showk, S. E., Jones, A., Elhage, N., Hume, T., Chen, A., Bai, Y., Bowman, S., Fort, S., Ganguli, D., Hernandez, D., Jacobson, J., Kernion, J., Kravec, S., Lovitt, L., Ndousse, K., Olsson, C., Ringer, S...
Pith/arXiv arXiv 2022
-
[47]
B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. (2020). Scaling laws for neural language models.arXiv preprint arXiv:2001.08361
Pith/arXiv arXiv 2020
-
[48]
and Gal, Y
Kendall, A. and Gal, Y. (2017). What uncertainties do we need in bayesian deep learning for computer vision? InAdvances in Neural Information Processing Systems 30, pages 5574–5584
2017
-
[49]
Kharbanda, A. and Chandorkar, A. (2024). Divergent ensemble networks: Enhancing uncertainty estimation with shared representations and independent branching.arXiv preprint arXiv:2412.01193
arXiv 2024
-
[50]
Kossen, J., Han, J., Razzak, M., Schut, L., Malik, S. A., and Gal, Y. (2024). Semantic entropy probes: Robust and cheap hallucination detection in LLMs.arXiv preprint arXiv:2406.15927
Pith/arXiv arXiv 2024
-
[51]
Kumar, B., Lu, C., Gupta, G., Palepu, A., Bellamy, D. R., Raskar, R., and Beam, A. (2023). Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404
arXiv 2023
-
[52]
Lakshminarayanan, B., Pritzel, A., and Blundell, C. (2017). Simple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems 30, pages 6402–6413
2017
-
[53]
Laurent, O., Lafage, A., Tartaglione, E., Daniel, G., Martinez, J., Bursuc, A., and Franchi, G. (2023). Packed ensembles for efficient uncertainty estimation. InProceedings of the 11th International Conference on Learning Representations
2023
-
[54]
Lee, K., Lee, K., Lee, H., and Shin, J. (2018). A simple unified framework for detecting out-of- distribution samples and adversarial attacks. InAdvances in Neural Information Processing Systems 31, pages 7167–7177
2018
-
[55]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. (2020). Retrieval-augmented generation for 44 knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems 33, pages 9459–9474
2020
-
[56]
Li, Y., Qiang, R., Moukheiber, L., and Zhang, C. (2025). Language model uncertainty quantification with attention chain.arXiv preprint arXiv:2503.19168
arXiv 2025
-
[57]
Liang, S., Lu, X., Liu, Z., Wang, M., Lyu, Y., and Zhang, S. (2026). On the impact of weight quantization on deep neural network uncertainty. InProceedings of the 40th AAAI Conference on Artificial Intelligence, pages 23425–23432
2026
-
[58]
Lin, S., Hilton, J., and Evans, O. (2022). Teaching models to express their uncertainty in words. Transactions on Machine Learning Research
2022
-
[59]
Lin, Z., Trivedi, S., and Sun, J. (2024a). Contextualized sequence likelihood: Enhanced confidence scores for natural language generation. InProceedings of the 29th Conference on Empirical Methods in Natural Language Processing, pages 10351–10368
-
[60]
Lin, Z., Trivedi, S., and Sun, J. (2024b). Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research
-
[61]
Ling, C., Zhao, X., Zhang, X., Cheng, W., Liu, Y., Sun, Y., Oishi, M., Osaki, T., Matsuda, K., Ji, J., Bai, G., Zhao, L., and Chen, H. (2024). Uncertainty quantification for in-context learning of large language models. InProceedings of the 20th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techn...
2024
-
[62]
Liu, L., Pan, Y., Li, X., and Chen, G. (2024a). Uncertainty estimation and quantification for LLMs: A simple supervised approach.arXiv preprint arXiv:2404.15993
-
[63]
F., Chao, L
Liu, S., Li, Z., Liu, X., Zhan, R., Wong, D. F., Chao, L. S., and Zhang, M. (2024b). Can LLMs learn uncertainty on their own? expressing uncertainty effectively in a self-training manner. In Proceedings of the 29th Conference on Empirical Methods in Natural Language Processing, pages 21635–21645
-
[64]
Liu, X., Chen, T., Da, L., Chen, C., Lin, Z., and Wei, H. (2025). Uncertainty quantification and confidence calibration in large language models: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, pages 6107–6117
2025
-
[65]
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692
Pith/arXiv arXiv 2019
-
[66]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783
Llama (2024). The Llama 3 herd of models.arXiv preprint arXiv:2407.21783. 45
Pith/arXiv arXiv 2024
-
[67]
T., Yamada, Y., Hu, S., Foerster, J., Ha, D., and Clune, J
Lu, C., Lu, C., Lange, R. T., Yamada, Y., Hu, S., Foerster, J., Ha, D., and Clune, J. (2026). Towards end-to-end automation of AI research.Nature, 651(8107):914–919
2026
-
[68]
J., Izmailov, P., Garipov, T., Vetrov, D
Maddox, W. J., Izmailov, P., Garipov, T., Vetrov, D. P., and Wilson, A. G. (2019). A simple baseline for bayesian uncertainty in deep learning. InAdvances in Neural Information Processing Systems 32, pages 13132–13143
2019
-
[69]
and Gales, M
Malinin, A. and Gales, M. J. F. (2021). Uncertainty estimation in autoregressive structured prediction. InProceedings of the 9th International Conference on Learning Representations
2021
-
[70]
Manakul, P., Liusie, A., and Gales, M. J. F. (2023). SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 28th Conference on Empirical Methods in Natural Language Processing, pages 9004–9017
2023
-
[71]
Michelmore, R., Kwiatkowska, M., and Gal, Y. (2018). Evaluating uncertainty quantification in end-to-end autonomous driving control.arXiv preprint arXiv:1811.06817
Pith/arXiv arXiv 2018
-
[72]
Min, S., Michael, J., Hajishirzi, H., and Zettlemoyer, L. (2020). AmbigQA: Answering ambiguous open-domain questions. InProceedings of the 25th Conference on Empirical Methods in Natural Language Processing, pages 5783–5797
2020
-
[73]
and Xin, M
Mo, S. and Xin, M. (2024). Tree of uncertain thoughts reasoning for large language models. In Proceedings of the 51st International Conference on Acoustics, Speech, and Signal Processing, pages 12742–12746
2024
-
[74]
Nadeem, M. S. A., Zucker, J.-D., and Hanczar, B. (2009). Accuracy-rejection curves (ARCs) for comparing classification methods with a reject option. InProceedings of the 3rd International Workshop on Machine Learning in Systems Biology, pages 65–81
2009
-
[75]
Nemani, V., Biggio, L., Huan, X., Hu, Z., Fink, O., Tran, A., Wang, Y., Zhang, X., and Hu, C. (2023). Uncertainty quantification in machine learning for engineering design and health prognostics: A tutorial.Mechanical Systems and Signal Processing, 205:110796
2023
-
[76]
Nikitin, A., Kossen, J., Gal, Y., and Marttinen, P. (2024). Kernel language entropy: Fine-grained uncertainty quantification for LLMs from semantic similarities. InAdvances in Neural Information Processing Systems 37, pages 8901–8929
2024
-
[77]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774
OpenAI (2023). Gpt-4 technical report.arXiv preprint arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[78]
Piray, P. (2026). Not all uncertainty is alike: volatility, stochasticity, and exploration.arXiv preprint arXiv:2605.19215. 46
Pith/arXiv arXiv 2026
-
[79]
Semanticdensity: Uncertaintyquantificationforlargelanguage models through confidence measurement in semantic space
Qiu, X.andMiikkulainen, R.(2024). Semanticdensity: Uncertaintyquantificationforlargelanguage models through confidence measurement in semantic space. InAdvances in Neural Information Processing Systems 37, pages 134507–134533
2024
-
[80]
H., Jaakkola, T
Quach, V., Fisch, A., Schuster, T., Yala, A., Sohn, J. H., Jaakkola, T. S., and Barzilay, R. (2024). Conformal language modeling. InProceedings of the 12th International Conference on Learning Representations
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.