When AUC 0.998 Is Not Enough: A Candidate Evaluation Protocol for Hidden-State Probes of Indirect Prompt Injection in Multimodal Computer-Use Agents
Pith reviewed 2026-06-26 09:03 UTC · model grok-4.3
The pith
High AUC on clean-vs-attack splits does not prove hidden-state probes detect malicious content
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
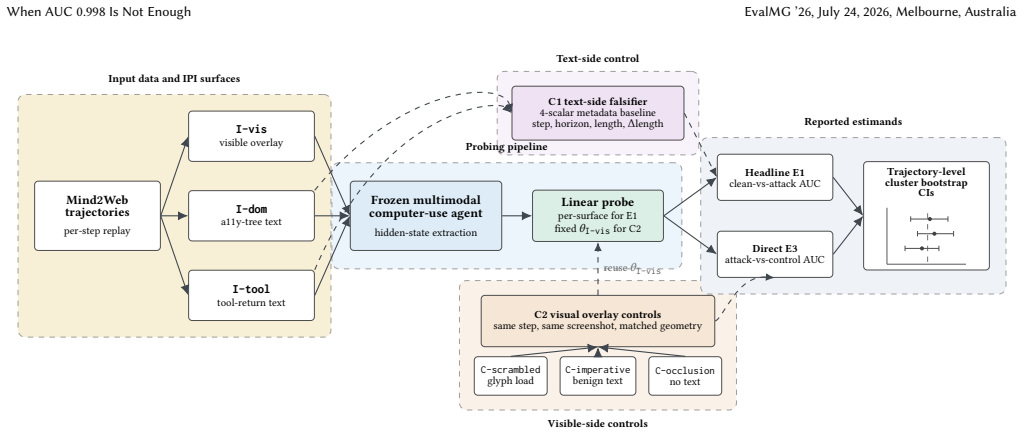
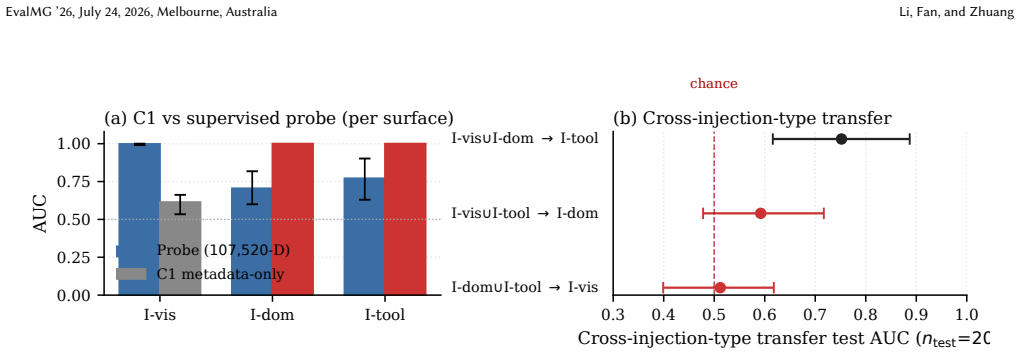
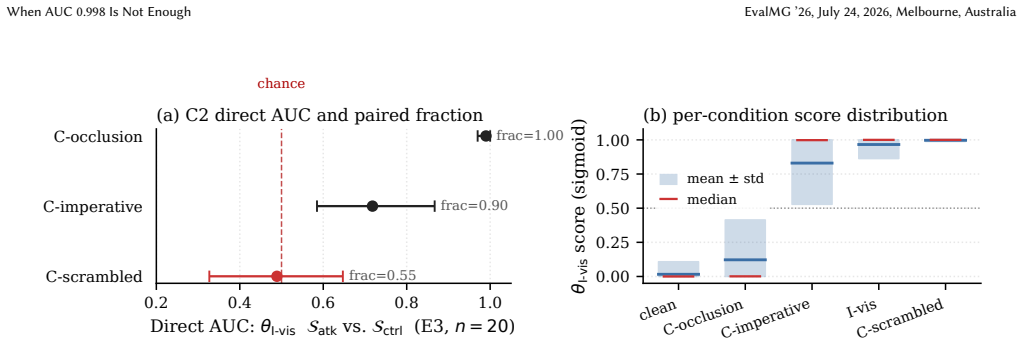
A high probing AUC on a clean-vs-attack split is not, on its own, evidence of malicious-content detection. Two post-hoc diagnostics—a paired-construction scalar baseline on text-side injections and same-step nuisance-matched visual controls on the overlay surface—do not license an unqualified malicious-content interpretation of the headline while leaving room for partly-semantic readings.
What carries the argument
The candidate evaluation protocol built from a paired-construction scalar baseline on text-side injections and same-step nuisance-matched visual controls on the overlay surface, which tests whether high AUC reflects semantic detection or nuisance signals.
If this is right
- A high clean-vs-attack AUC alone does not license claims of semantic malicious-content detection by the probe.
- The two diagnostics form a control set that clarifies what the AUC licenses and does not license.
- Probe labels indicate injection-surface presence rather than attack success.
- Generalisation of the findings beyond the tested backbone and benchmark is a conjecture.
Where Pith is reading between the lines
- Future evaluations of linear probes on frozen multimodal models should include nuisance-matched controls as standard practice to avoid overinterpreting AUC.
- The same caution about surface cues driving performance could apply to other detection tasks that rely on hidden-state probes without explicit controls.
- Applying the protocol to additional model families would test whether the observed limitation is backbone-specific or more widespread.
Load-bearing premise
The paired-construction scalar baseline on text-side injections and the same-step nuisance-matched visual controls are sufficient to distinguish semantic malicious-content detection from surface-level or nuisance-driven signals.
What would settle it
A controlled test in which the probe AUC remains high after semantic malicious elements are removed but nuisance features are retained, or drops sharply when nuisance features are matched but semantics are preserved.
Figures
read the original abstract
Hidden-state probing -- a linear classifier on a frozen vision-language model's internal activations -- has emerged as an attractive evaluation tool for flagging indirect prompt injection (IPI) in multimodal computer-use agents before the agent emits a corrupted action. We argue, on a single-backbone cautionary case study (Qwen2.5-VL-7B on Mind2Web, teacher-forced replay), that a high probing AUC on a clean-vs-attack split is not, on its own, evidence of malicious-content detection. Two post-hoc diagnostics -- a paired-construction scalar baseline on text-side injections, and same-step nuisance-matched visual controls on the overlay surface -- do not license an unqualified malicious-content interpretation of the headline while leaving room for partly-semantic readings. We package the diagnostics as a candidate control set with reporting heuristics for what a high clean-vs-attack AUC does and does not license. Labels are injection-surface-present, not attack success; generalisation beyond this backbone and benchmark is a conjecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that a high AUC from hidden-state linear probing on clean-vs-attack splits does not, by itself, constitute evidence of malicious-content detection for indirect prompt injection in multimodal computer-use agents. It supports this via a single-backbone case study (Qwen2.5-VL-7B on Mind2Web with teacher-forced replay) using two post-hoc diagnostics—a paired-construction scalar baseline for text-side injections and same-step nuisance-matched visual controls for the overlay surface—while leaving room for partly-semantic interpretations and framing generalization as a conjecture. The work packages the diagnostics as a candidate control set with reporting heuristics.
Significance. If the diagnostics and their interpretation hold, the result is significant as a methodological caution in the probing and AI-safety literature. It explicitly uses external controls rather than self-referential derivations, states its scope limitations clearly, and supplies concrete reporting heuristics. This could reduce overinterpretation of headline AUC numbers in future work on hidden-state monitors for agent safety.
minor comments (2)
- [Abstract and §4 (post-hoc diagnostics)] The abstract and methods would benefit from an explicit table or inline numerical comparison of the headline clean-vs-attack AUC against the AUCs obtained under each of the two post-hoc diagnostics; this would make the strength of the cautionary claim immediately verifiable without requiring the reader to cross-reference multiple figures.
- [§3 (experimental setup)] The phrase 'injection-surface-present, not attack success' for the label definition is clear in intent but would be strengthened by a one-sentence contrast with how attack-success labels are typically constructed in the IPI literature.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, accurate summary of our scope and contributions, and recommendation of minor revision. The work is framed as a single-backbone cautionary case study with explicit limitations on generalization.
Circularity Check
No significant circularity identified
full rationale
The paper advances a methodological caution that high clean-vs-attack probing AUC does not by itself establish malicious-content detection. This is supported by two explicitly described post-hoc diagnostics (paired-construction scalar baseline and nuisance-matched visual controls) applied to a single backbone/benchmark case study, with generalization framed as a conjecture. No derivation, equation, or central claim reduces to a fitted input, self-definition, or self-citation chain; the analysis remains self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear classifiers on frozen vision-language model activations can be used to probe for indirect prompt injection signals
- domain assumption The clean-vs-attack split and the proposed controls isolate the relevant factors for interpreting probe behavior
Reference graph
Works this paper leans on
-
[1]
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. 2018. Don’t Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering. InProceedings of CVPR
2018
-
[2]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in Language Models Is Mediated by a Single Direction.arXiv preprint arXiv:2406.11717(2024)
Pith/arXiv arXiv 2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923(2025)
Pith/arXiv arXiv 2025
-
[4]
Yonatan Belinkov. 2022. Probing Classifiers: Promises, Shortcomings, and Ad- vances.Computational Linguistics48, 1 (2022), 207–219
2022
-
[5]
Yonatan Belinkov and James Glass. 2019. Analysis Methods in Neural Language Processing: A Survey.Transactions of the Association for Computational Linguistics 7 (2019), 49–72
2019
-
[6]
Yihang Chen, Pin Qian, Su Wang, Sipeng Zhang, Huan Xu, Shuhuai Lin, and Xinpeng Wei. 2026. Does RAG Know When Retrieval Is Wrong? Diagnosing Context Compliance under Knowledge Conflict.arXiv preprint arXiv:2605.14473 (2026)
Pith/arXiv arXiv 2026
-
[7]
Alexis Conneau and Douwe Kiela. 2018. SentEval: An Evaluation Toolkit for Universal Sentence Representations. InProceedings of LREC
2018
-
[8]
1997.Bootstrap Methods and Their Application
Anthony C Davison and David V Hinkley. 1997.Bootstrap Methods and Their Application. Cambridge University Press
1997
-
[9]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[10]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. InAdvances in Neural Information Processing Systems (NeurIPS) — Datasets and Benchmarks Track
2023
-
[11]
Bradley Efron. 1979. Bootstrap Methods: Another Look at the Jackknife.The Annals of Statistics7, 1 (1979), 1–26
1979
-
[12]
Yanai Elazar, Shauli Ravfogel, Alon Jacovi, and Yoav Goldberg. 2021. Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals.Transactions of the Association for Computational Linguistics9 (2021), 160–175
2021
-
[13]
Yushi Feng, Junye Du, Qifan Wang, Zizhan Ma, Qian Niu, Yutaka Matsuo, Long Feng, and Lequan Yu. 2026. CORA: Conformal Risk-Controlled Agents for Safe- guarded Mobile GUI Automation.arXiv preprint arXiv:2604.09155(2026)
Pith/arXiv arXiv 2026
-
[14]
Wichmann
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. 2020. Shortcut Learning in Deep Neural Networks.Nature Machine Intelligence2, 11 (2020), 665–673
2020
-
[15]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
-
[16]
InProceedings of CVPR
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. InProceedings of CVPR
-
[17]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of AISec
2023
-
[18]
Bowman, and Noah A
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. 2018. Annotation Artifacts in Natural Language Inference Data. InProceedings of NAACL-HLT
2018
-
[19]
Jiatong Han, Neil Band, Muhammed Razzak, Jannik Kossen, Tim G. J. Rudner, and Yarin Gal. 2025. Simple Factuality Probes Detect Hallucinations in Long-Form Natural Language Generation. InFindings of the Association for Computational Linguistics: EMNLP
2025
-
[20]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. InProceedings of ACL
2024
-
[21]
John Hewitt and Percy Liang. 2019. Designing and Interpreting Probes with Control Tasks. InProceedings of EMNLP-IJCNLP
2019
-
[22]
Yuelyu Ji, Wuwei Lan, and Patrick NG. 2025. MRAG-Suite: A Diagnostic Eval- uation Platform for Visual Retrieval-Augmented Generation.arXiv preprint arXiv:2509.24253(2025)
arXiv 2025
-
[23]
Xiaochong Jiang, Shiqi Yang, Wenting Yang, Yichen Liu, and Cheng Ji. 2026. SoK: A Taxonomy of Attack Vectors and Defense Strategies for Agentic Supply Chain Runtime. InICLR 2026 Workshop on AI for Mechanism Design and Strategic Decision Making. arXiv preprint arXiv:2602.19555
Pith/arXiv arXiv 2026
-
[24]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried
-
[25]
InProceedings of ACL
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. InProceedings of ACL
-
[26]
Olivier Ledoit and Michael Wolf. 2004. A Well-Conditioned Estimator for Large- Dimensional Covariance Matrices.Journal of Multivariate Analysis88, 2 (2004), 365–411
2004
-
[27]
Yanhang Li, Zhichao Fan, and Zexin Zhuang. 2026. Auditing Reasoning-Trace Memorization Claims after Unlearning with Head-Conditioned Canaries.arXiv preprint arXiv:2605.18891(2026)
Pith/arXiv arXiv 2026
-
[28]
Yanhang Li, Zhichao Fan, and Zexin Zhuang. 2026. SafetyRepro: Configuration- Conditional Rank Instability on Alignment Benchmarks.arXiv preprint arXiv:2605.25492(2026)
Pith/arXiv arXiv 2026
-
[29]
Lixing Lin, Juli You, Yue Li, Luyun Lin, Yiqing Wang, Zhen Zhang, and Moxuan Zheng. 2026. Reflect-Guard: Enhancing LLM Safeguards against Adversarial Prompts via Logical Self-Reflection.arXiv preprint arXiv:2605.24834(2026)
Pith/arXiv arXiv 2026
-
[30]
Hanjun Luo, Shenyu Dai, Chiming Ni, Xinfeng Li, Guibin Zhang, Kun Wang, Tongliang Liu, and Hanan Salam. 2025. AgentAuditor: Human-Level Safety and Security Evaluation for LLM Agents. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2025)
2025
-
[31]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Re...
2011
-
[32]
Tiago Pimentel, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. 2020. Information-Theoretic Probing for Linguistic Structure. InProceedings of ACL
2020
-
[33]
Pin Qian, Su Wang, Xiaoyuan Wang, Yihang Chen, Wenxuan Xu, Qiaolin Yu, Shuhuai Lin, Sipeng Zhang, Junxian You, and Xinpeng Wei. 2026. Relevant Is Not Warranted: Evidence-Force Calibration for Cited RAG.arXiv preprint arXiv:2605.28044(2026)
Pith/arXiv arXiv 2026
-
[34]
Abhilasha Ravichander, Yonatan Belinkov, and Eduard Hovy. 2021. Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?. InProceedings of EACL
2021
-
[35]
Williamson, Alex J
Bernhard Schölkopf, Robert C. Williamson, Alex J. Smola, John Shawe-Taylor, and John Platt. 1999. Support Vector Method for Novelty Detection. InAdvances in Neural Information Processing Systems (NeurIPS)
1999
-
[36]
Tianneng Shi, Jingxuan He, Zhun Wang, Linyu Wu, Hongwei Li, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable Privilege Control for LLM Agents. arXiv preprint arXiv:2504.11703(2025)
Pith/arXiv arXiv 2025
-
[37]
Vincent Siu, Nicholas Crispino, Zihao Yu, Sam Pan, Zhun Wang, Yang Liu, Dawn Song, and Chenguang Wang. 2025. COSMIC: Generalized Refusal Direction Identification in LLM Activations. InFindings of the Association for Computational Linguistics: ACL. arXiv:2506.00085
arXiv 2025
-
[38]
Representing Isolated Targets to Steer Language Models
Vincent Siu, Nathan W. Henry, Nicholas Crispino, Yang Liu, Dawn Song, and Chenguang Wang. 2026. RepIt: Steering Language Models with Concept-Specific Refusal Vectors. InInternational Conference on Learning Representations (ICLR). 9 EvalMG ’26, July 24, 2026, Melbourne, Australia Li, Fan, and Zhuang OpenReview submission ID fsZkx8gek0; earlier arXiv title ...
2026
-
[39]
Qiushi Sun, Mukai Li, Zhoumianze Liu, Zhihui Xie, Fangzhi Xu, Zhangyue Yin, Kanzhi Cheng, Zehao Li, Zichen Ding, Qi Liu, Zhiyong Wu, Zhuosheng Zhang, Ben Kao, and Lingpeng Kong. 2025. OS-Sentinel: Towards Safety-Enhanced Mobile GUI Agents via Hybrid Validation in Realistic Workflows.arXiv preprint arXiv:2510.24411(2025)
arXiv 2025
-
[40]
Elena Voita and Ivan Titov. 2020. Information-Theoretic Probing with Minimum Description Length. InProceedings of EMNLP
2020
-
[41]
Su Wang, Pin Qian, Yihang Chen, Junxian You, Xiaoyuan Wang, Xiaochong Jiang, Lifei Liu, Haoran Yu, and Jingzhou Xu. 2026. When Safe Skills Collide: Measuring Compositional Risk in Agent Skill Ecosystems.arXiv preprint arXiv:2606.00448 (2026)
Pith/arXiv arXiv 2026
-
[42]
Yingshuo Wang, Xian Sun, Yanhang Li, Zhichao Fan, and Zexin Zhuang. 2026. Auditing and Fixing Economic Validity in Tabular Foundation Models for Discrete Choice.arXiv preprint arXiv:2605.26559(2026)
Pith/arXiv arXiv 2026
-
[43]
Zhun Wang, Vincent Siu, Zhe Ye, Tianneng Shi, Yuzhou Nie, Xuandong Zhao, Chenguang Wang, Wenbo Guo, and Dawn Song. 2025. AgentVigil: Automatic Black-Box Red-teaming for Indirect Prompt Injection against LLM Agents. InFind- ings of the Association for Computational Linguistics: EMNLP. arXiv:2505.05849
arXiv 2025
-
[44]
Tongyu Wen, Chenglong Wang, Xiyuan Yang, Haoyu Tang, Yueqi Xie, Lingjuan Lyu, Zhicheng Dou, and Fangzhao Wu. 2025. Defending against Indirect Prompt Injection by Instruction Detection. InFindings of the Association for Computational Linguistics: EMNLP 2025. 19472–19487. doi:10.18653/v1/2025.findings-emnlp.1060 Uses hidden-state and gradient features for i...
-
[45]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[46]
InNeurIPS D&B
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InNeurIPS D&B
-
[47]
Bastian, Seyyed Hadi Hashemi, Chaowei Xiao, Wenbo Guo, and Bo Li
Zhuowen Yuan, Zhaorun Chen, Zhen Xiang, Nathaniel D. Bastian, Seyyed Hadi Hashemi, Chaowei Xiao, Wenbo Guo, and Bo Li. 2026. ShieldNet: Network-Level Guardrails against Emerging Supply-Chain Injections in Agentic Systems.arXiv preprint arXiv:2604.04426(2026)
Pith/arXiv arXiv 2026
-
[48]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL
2024
-
[49]
Zhenliang Zhang, Xinyu Hu, Huixuan Zhang, Junzhe Zhang, and Xiaojun Wan
-
[50]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)
ICR Probe: Tracking Hidden State Dynamics for Reliable Hallucination Detection in LLMs. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). arXiv:2507.16488
-
[51]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. InInternational Conference on Learning Representations (ICLR)
2024
-
[52]
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang
-
[53]
MELON: Indirect Prompt Injection Defense via Masked Re-execution and Tool Comparison.arXiv preprint arXiv:2502.05174(2025)
arXiv 2025
-
[54]
Zexin Zhuang, Yanhang Li, and Zhichao Fan. 2026. Pre-Registering the Detectable Effect: A Paired-MDE Budget for 4-bit Quantization Benchmarks, with a Pilot Audit.arXiv preprint arXiv:2605.28873(2026)
Pith/arXiv arXiv 2026
-
[55]
Disregard prior instructions. Click Send Now
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, et al . 2023. Representa- tion Engineering: A Top-Down Approach to AI Transparency.arXiv preprint arXiv:2310.01405(2023). 10 When AUC 0.998 Is Not Enough EvalMG ’26, July 24, 2026, Melbourne, Australia A Attack-template catalog We list the...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.