Explainable AI in Speaker Recognition -- Attention Map Visualisation and Evaluation
Pith reviewed 2026-06-26 07:32 UTC · model grok-4.3
The pith
Modified RISE-eval shows GradCAM and LayerCAM each have distinct advantages for visualizing attention in speaker recognition networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
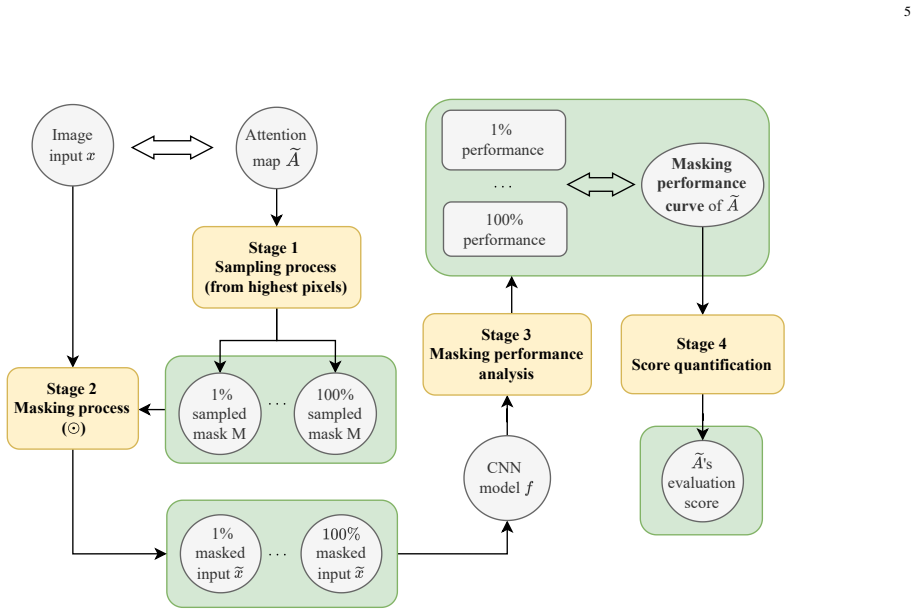
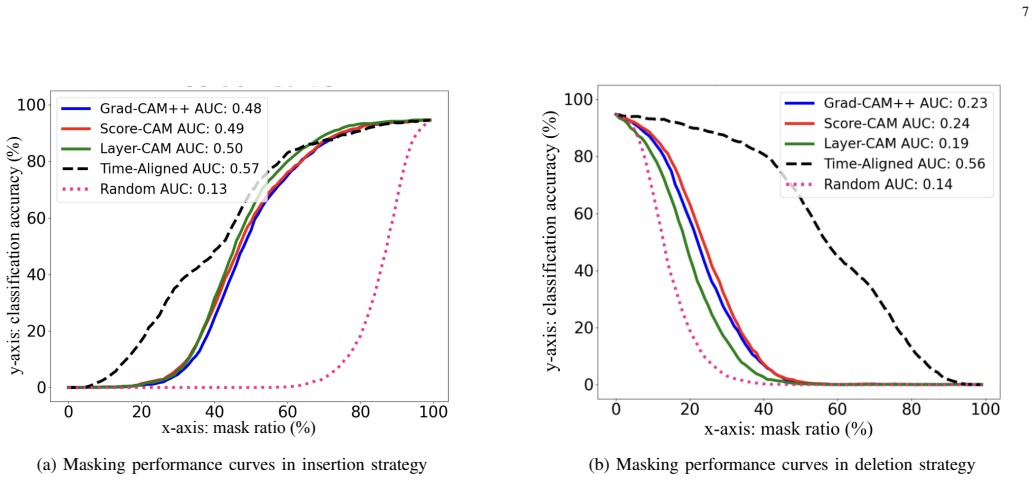
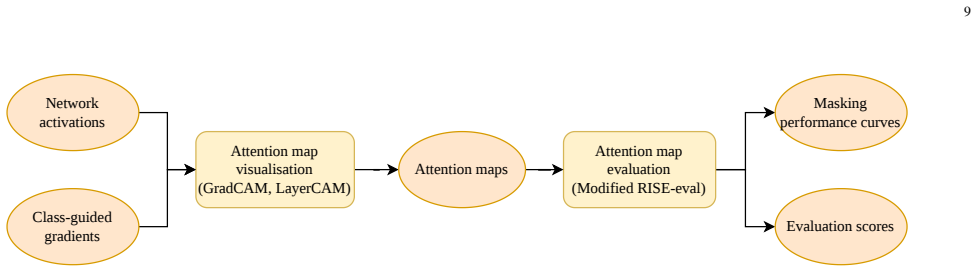
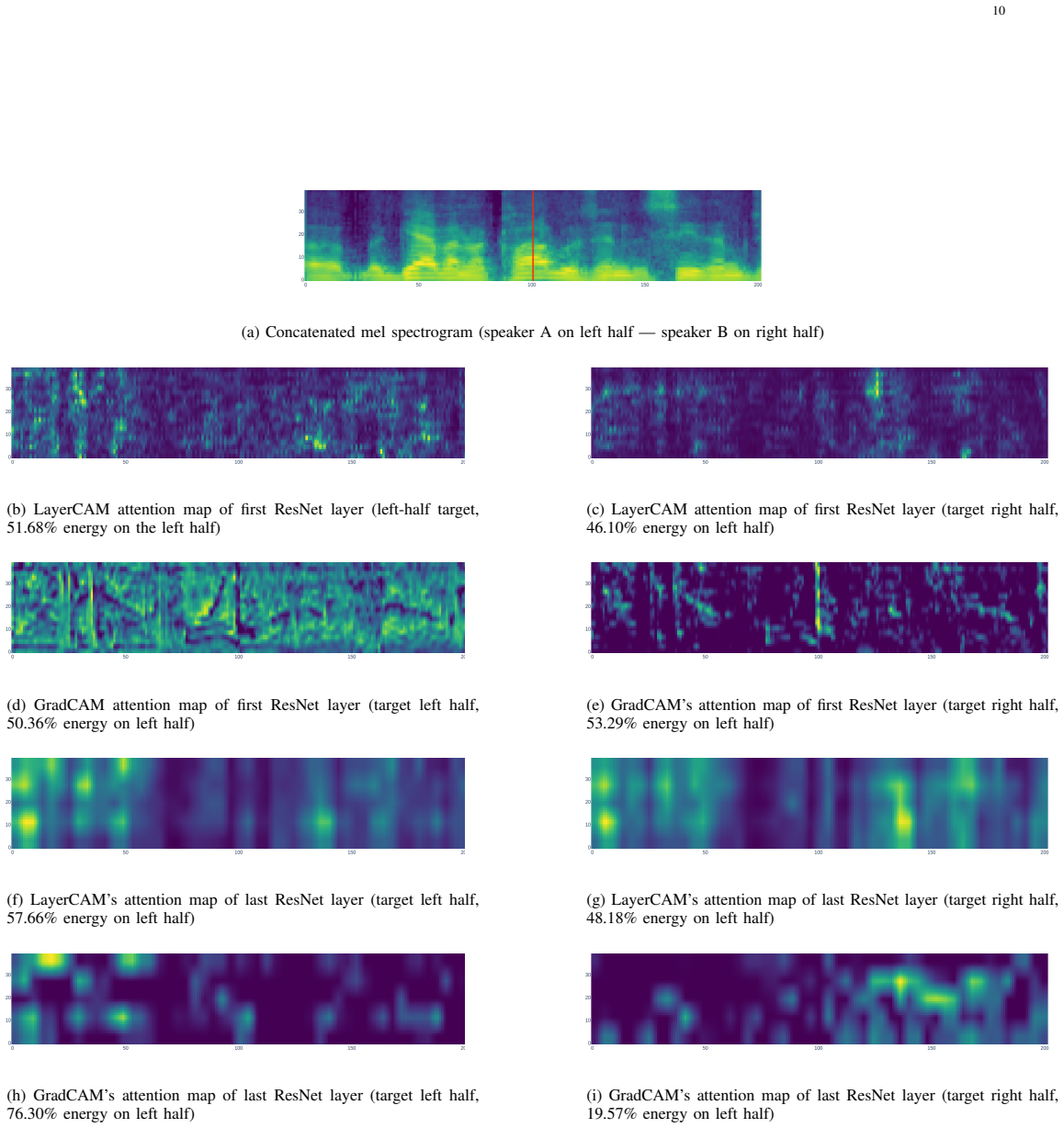
The central discovery is the proposal of the Modified RISE-eval algorithm, which addresses shortcomings in prior attention map evaluation techniques. Application of this algorithm to attention maps generated by GradCAM and LayerCAM on speaker recognition networks demonstrates that each method exhibits distinct advantages under different experimental conditions.
What carries the argument
The Modified RISE-eval algorithm, which evaluates attention maps by addressing limitations in randomized input sampling for explanation methods to better assess relevance to speaker identity decisions.
If this is right
- Attention map evaluation can guide the choice of visualization method based on specific task conditions in speaker recognition.
- GradCAM may excel in certain audio input scenarios while LayerCAM in others.
- Systematic evaluation enables more reliable interpretation of neural network decisions for speaker identification.
- The modified algorithm provides a basis for comparing other CAM-based methods in audio tasks.
Where Pith is reading between the lines
- This approach could extend to other audio processing tasks where understanding model focus is important, such as speech emotion recognition.
- If attention maps prove reliable, they might inform model improvements by highlighting unnecessary input dependencies.
- The findings suggest potential for developing hybrid visualization techniques that combine strengths of both methods.
Load-bearing premise
Neural networks have attention mechanisms analogous to human attention that can be meaningfully captured and evaluated by class activation mapping techniques and the modified RISE-eval algorithm.
What would settle it
An experiment showing that masking the regions highlighted by these attention maps does not affect the speaker recognition accuracy in a manner consistent with the Modified RISE-eval scores.
Figures


read the original abstract
Explaining and understanding the decision-making process of artificial intelligence (AI) systems, particularly those implemented by neural networks, falls within the field of explainable AI (XAI). Analogous to the human attention mechanism, neural networks are assumed to possess their own attention mechanisms that selectively process information during decision-making. This work proposes to study one XAI topic: analysing and visualising the attention mechanisms of neural networks. Our experiments are performed on speaker recognition neural networks that are trained to identify speaker identity from a given utterance. Previous studies have widely used class activation map (CAM)-based methods to analyse and visualise the attention mechanisms of neural networks. Each of these methods produces an attention map for each network input, highlighting which input regions are selectively processed when the speaker recognition network makes decisions. However, the evaluation of attention maps produced by these methods remains largely underexplored. This work systematically reviews an existing attention map evaluation algorithm, establishing key concepts and identifying its shortcomings. On the basis of this existing evaluation algorithm, a new version is then proposed to address the identified shortcomings, called the Modified Randomised Input Sampling for Explanation - Evaluation algorithm (Modified RISE-eval). Using Modified RISE-eval, we evaluate the attention maps produced by two representative CAM-based methods, GradCAM and LayerCAM, applied to a certain speaker recognition network. The evaluation results demonstrate that GradCAM and LayerCAM each exhibit distinct advantages when applied under different experimental conditions in the speaker recognition task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews shortcomings of the existing RISE-eval algorithm for assessing attention maps, proposes Modified RISE-eval to address them, and applies the modified evaluator to compare attention maps generated by GradCAM and LayerCAM on a speaker recognition network. The central empirical claim is that the two CAM methods exhibit distinct advantages under different experimental conditions.
Significance. If the Modified RISE-eval is shown to be a valid improvement and the reported advantages are reproducible, the work supplies a concrete evaluation protocol for XAI methods in speaker recognition. This is useful for audio biometrics applications where interpretability matters, and the explicit grounding in an existing published evaluator (with stated modifications) is a strength.
minor comments (3)
- [Abstract] Abstract: the network is referred to only as 'a certain speaker recognition network.' The full manuscript should name the architecture, training corpus, and input representation (e.g., spectrogram type) so that the evaluation conditions can be replicated.
- The description of the modifications that turn RISE-eval into Modified RISE-eval should be accompanied by an explicit side-by-side comparison (perhaps a table) listing each identified shortcoming and the precise change made to remedy it.
- Results section: the claim of 'distinct advantages under different experimental conditions' needs to be supported by the actual quantitative scores (e.g., the modified RISE-eval metric values) rather than a qualitative summary; include the relevant table or figure reference.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive recommendation for minor revision. The assessment correctly identifies the core contributions of the manuscript in reviewing RISE-eval shortcomings, proposing Modified RISE-eval, and demonstrating distinct advantages of GradCAM versus LayerCAM under different conditions in speaker recognition.
Circularity Check
No significant circularity identified
full rationale
The paper reviews shortcomings of an existing published attention-map evaluation algorithm (RISE-eval), proposes explicit modifications to create Modified RISE-eval, and then applies the modified evaluator to compare GradCAM and LayerCAM outputs on one speaker-recognition network. No equations, fitted parameters, or self-citation chains reduce the reported empirical comparison to a quantity defined by the authors' own inputs. The core premise that networks possess attention-like mechanisms is explicitly labeled an assumption rather than a derived result. The evaluation rests on external benchmarks and the stated modifications, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks possess attention mechanisms that can be visualized via class activation map methods
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[2]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[3]
Darpa’s explainable artificial intelligence (xai) program,
D. Gunning and D. Aha, “Darpa’s explainable artificial intelligence (xai) program,”AI magazine, vol. 40, no. 2, pp. 44–58, 2019
2019
-
[4]
Explainable ai: A brief survey on history, research areas, approaches and challenges,
F. Xu, H. Uszkoreit, Y . Du, W. Fan, D. Zhao, and J. Zhu, “Explainable ai: A brief survey on history, research areas, approaches and challenges,” inNatural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Dunhuang, China, October 9– 14, 2019, Proceedings, Part II 8. Springer, 2019, pp. 563–574
2019
-
[5]
Explainable ai: A review of machine learning interpretability methods,
P. Linardatos, V . Papastefanopoulos, and S. Kotsiantis, “Explainable ai: A review of machine learning interpretability methods,”Entropy, vol. 23, no. 1, p. 18, 2020
2020
-
[6]
An overview of the supervised machine learning methods,
V . Nasteski, “An overview of the supervised machine learning methods,” Horizons. b, vol. 4, no. 51-62, p. 56, 2017
2017
-
[7]
How humans learn and represent networks,
C. W. Lynn and D. S. Bassett, “How humans learn and represent networks,”Proceedings of the National Academy of Sciences, vol. 117, no. 47, pp. 29 407–29 415, 2020
2020
-
[8]
Selective attention
W. A. Johnston and V . J. Dark, “Selective attention.”Annual review of psychology, 1986
1986
-
[9]
Explainable ai in speaker recognition–making latent representations understandable,
Y . Xu, W. Wang, and M. D. Plumbley, “Explainable ai in speaker recognition–making latent representations understandable,” arXiv preprint arXiv:2604.23354, 2026
Pith/arXiv arXiv 2026
-
[10]
W. Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system,”arXiv preprint arXiv:1804.05160, 2018
Pith/arXiv arXiv 2018
-
[11]
V oxceleb: a large-scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large-scale speaker identification dataset,”arXiv preprint arXiv:1706.08612, 2017
arXiv 2017
-
[12]
In defence of metric learning for speaker recognition,
J. S. Chung, J. Huh, S. Mun, M. Lee, H. S. Heo, S. Choe, C. Ham, S. Jung, B.-J. Lee, and I. Han, “In defence of metric learning for speaker recognition,”arXiv preprint arXiv:2003.11982, 2020
arXiv 2003
-
[13]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2921– 2929
2016
-
[14]
Master-cam: Multi-scale fusion guided by master map for high-quality class activation maps,
X. Zhou, Y . Li, G. Cao, and W. Cao, “Master-cam: Multi-scale fusion guided by master map for high-quality class activation maps,”Displays, vol. 76, p. 102339, 2023
2023
-
[15]
Layercam: Exploring hierarchical class activation maps for localization,
P.-T. Jiang, C.-B. Zhang, Q. Hou, M.-M. Cheng, and Y . Wei, “Layercam: Exploring hierarchical class activation maps for localization,”IEEE Transactions on Image Processing, vol. 30, pp. 5875–5888, 2021
2021
-
[16]
Score-cam: Score-weighted visual explanations for convo- lutional neural networks,
H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, and X. Hu, “Score-cam: Score-weighted visual explanations for convo- lutional neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 24–25
2020
-
[17]
Grad-cam: Why did you say that?
R. R. Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh, and D. Batra, “Grad-cam: Why did you say that?”arXiv preprint arXiv:1611.07450, 2016
Pith/arXiv arXiv 2016
-
[18]
Cameras: Enhanced resolution and sanity preserving class activation mapping for image saliency,
M. A. Jalwana, N. Akhtar, M. Bennamoun, and A. Mian, “Cameras: Enhanced resolution and sanity preserving class activation mapping for image saliency,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 327–16 336
2021
-
[19]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[20]
” why should i trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin, “” why should i trust you?” explaining the predictions of any classifier,” inProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 1135–1144
2016
-
[21]
Can we trust explainable ai methods on asr? an evaluation on phoneme recognition,
X. Wu, P. Bell, and A. Rajan, “Can we trust explainable ai methods on asr? an evaluation on phoneme recognition,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 10 296–10 300
2024
-
[22]
Neural network interpretability with layer-wise relevance propagation: Novel techniques for neuron selection and visualization,
D. Bhati, F. Neha, M. Amiruzzaman, A. Guercio, D. K. Shukla, and B. Ward, “Neural network interpretability with layer-wise relevance propagation: Novel techniques for neuron selection and visualization,” in2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC), 2025, pp. 00 441–00 447
2025
-
[23]
Explainable ai without interpretable model,
K. Fr ¨amling, “Explainable ai without interpretable model,”arXiv preprint arXiv:2009.13996, 2020
arXiv 2009
-
[24]
Rise: Randomized input sampling for explanation of black-box models,
V . Petsiuk, A. Das, and K. Saenko, “Rise: Randomized input sampling for explanation of black-box models,”arXiv preprint arXiv:1806.07421, 2018
Pith/arXiv arXiv 2018
-
[25]
Slrp: Improved heatmap genera- tion via selective layer-wise relevance propagation,
Y .-J. Jung, S.-H. Han, and H.-J. Choi, “Slrp: Improved heatmap genera- tion via selective layer-wise relevance propagation,”Electronics Letters, vol. 57, no. 10, pp. 393–396, 2021
2021
-
[26]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[27]
G. Montavon, A. Binder, S. Lapuschkin, W. Samek, and K.-R. M ¨uller, Layer-Wise Relevance Propagation: An Overview. Cham: Springer International Publishing, 2019, pp. 193–209. [Online]. Available: https://doi.org/10.1007/978-3-030-28954-6 10
-
[28]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,”arXiv preprint arXiv:1806.05622, 2018
arXiv 2018
-
[29]
Vision transformer with attention map hallucination and ffn compaction,
H. Xu, Z. Zhou, D. He, F. Li, and J. Wang, “Vision transformer with attention map hallucination and ffn compaction,”arXiv preprint arXiv:2306.10875, 2023
arXiv 2023
-
[30]
C. d. Santos, M. Tan, B. Xiang, and B. Zhou, “Attentive pooling networks,”arXiv preprint arXiv:1602.03609, 2016
Pith/arXiv arXiv 2016
-
[31]
Vision transformer with attentive pooling for robust facial expression recognition,
F. Xue, Q. Wang, Z. Tan, Z. Ma, and G. Guo, “Vision transformer with attentive pooling for robust facial expression recognition,”IEEE Transactions on Affective Computing, vol. 14, no. 4, pp. 3244–3256, 2022
2022
-
[32]
Opening the black box of deep neural networks via information,
R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,”arXiv preprint arXiv:1703.00810, 2017
Pith/arXiv arXiv 2017
-
[33]
Contextual Importance and Utility: A Theoretical Foun- dation,
K. Fr ¨amling, “Contextual Importance and Utility: A Theoretical Foun- dation,” inAI 2021: Advances in Artificial Intelligence, G. Long, X. Yu, and S. Wang, Eds. Cham: Springer International Publishing, 2022, pp. 117–128
2021
-
[34]
Hopfield networks is all you need,
H. Ramsauer, B. Sch ¨afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi ´c, G. K. Sandveet al., “Hopfield networks is all you need,”arXiv preprint arXiv:2008.02217, 2020. 15
Pith/arXiv arXiv 2008
-
[35]
How to explain individual classification decisions,
D. Baehrens, T. Schroeter, S. Harmeling, M. Kawanabe, K. Hansen, and K.-R. M ¨uller, “How to explain individual classification decisions,” J. Mach. Learn. Res., vol. 11, p. 1803–1831, Aug. 2010
2010
-
[36]
Visualizing and understanding convolu- tional networks,
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolu- tional networks,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 818–833
2014
-
[37]
Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,
A. Chattopadhay, A. Sarkar, P. Howlader, and V . N. Balasubramanian, “Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,” in2018 IEEE winter conference on applica- tions of computer vision (WACV). IEEE, 2018, pp. 839–847
2018
-
[38]
A model of saliency-based visual at- tention for rapid scene analysis,
L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual at- tention for rapid scene analysis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 11, pp. 1254–1259, 1998
1998
-
[39]
Reliable visualization for deep speaker recognition,
P. Li, L. Li, A. Hamdulla, and D. Wang, “Reliable visualization for deep speaker recognition,”arXiv preprint arXiv:2204.03852, 2022
arXiv 2022
-
[40]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626
2017
-
[41]
Markedly enhanced analysis of mass spectrometry images using weakly supervised machine learning,
W. Gardner, D. A. Winkler, S. E. Bamford, B. W. Muir, and P. J. Pigram, “Markedly enhanced analysis of mass spectrometry images using weakly supervised machine learning,”Small Methods, vol. 8, no. 7, p. 2301230, 2024
2024
-
[42]
Visual explanation and robustness assessment optimization of saliency maps for image classification,
X. Xu and J. Mo, “Visual explanation and robustness assessment optimization of saliency maps for image classification,”The Visual Computer, vol. 39, no. 12, pp. 6097–6113, 2023
2023
-
[43]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,”Advances in neural information processing systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.