Do Sparse Autoencoders Learn Meaningful Concept Hierarchies?
Pith reviewed 2026-06-26 08:44 UTC · model grok-4.3
The pith
Feature absorption in sparse autoencoders systematically compromises the quality of learned concept hierarchies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
While SAE feature spaces generally provide a basis for sensible hierarchies, establishing good hierarchical structure remains challenging. In particular, feature absorption, both in its well-known hard form and in a continuous, soft form, systematically compromises hierarchy quality, pointing to a fundamental tension that future approaches will need to navigate.
What carries the argument
The evaluation protocol derived from key requirements for generalization/specialization hierarchies drawn from semantic net and taxonomy research.
If this is right
- SAE feature spaces can provide a basis for sensible hierarchies.
- Hard feature absorption reduces hierarchy quality.
- Soft feature absorption reduces hierarchy quality.
- Imposing hierarchical structure on SAEs creates a tension with the need to avoid absorption.
Where Pith is reading between the lines
- Training objectives that explicitly penalize both hard and soft absorption may be required to produce better hierarchies.
- The same absorption problem could limit hierarchy quality in other unsupervised feature-learning methods beyond SAEs.
- The derived protocol could be validated by comparing its scores against human judgments of feature hierarchies.
Load-bearing premise
The requirements for generalization/specialization hierarchies derived from semantic net and taxonomy research are the appropriate criteria for judging meaningful feature hierarchies in unsupervised SAE concept discovery.
What would settle it
Training an SAE that exhibits feature absorption yet achieves high scores on the hierarchy quality protocol, or one that avoids absorption but scores low, would test whether absorption systematically compromises quality.
Figures
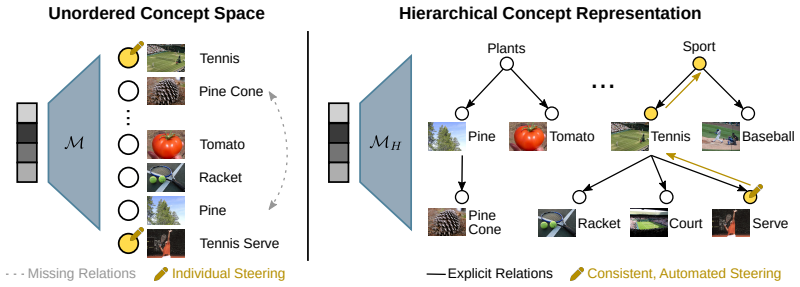
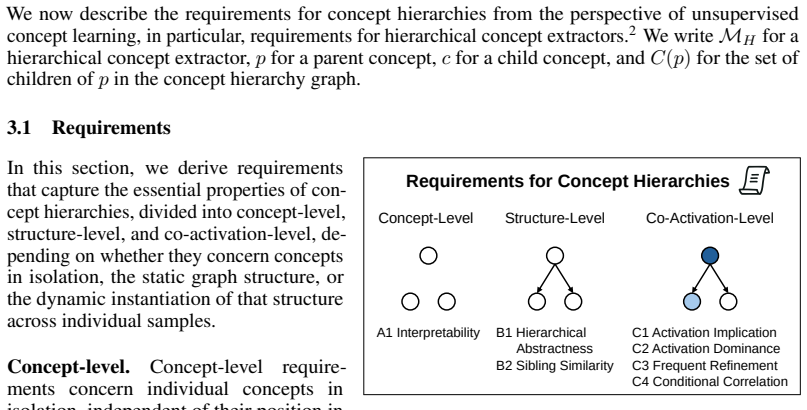
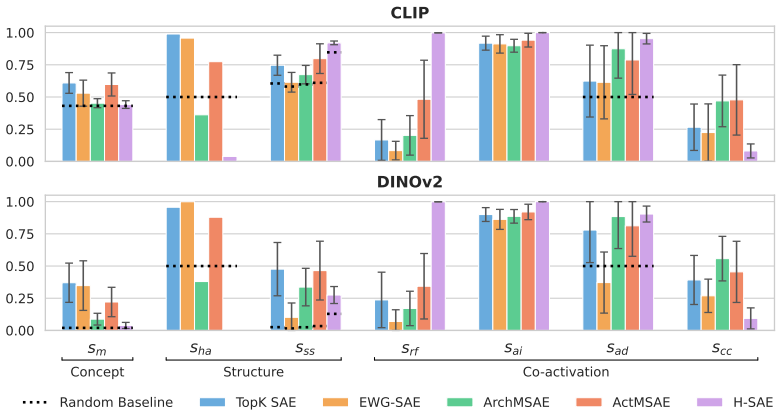
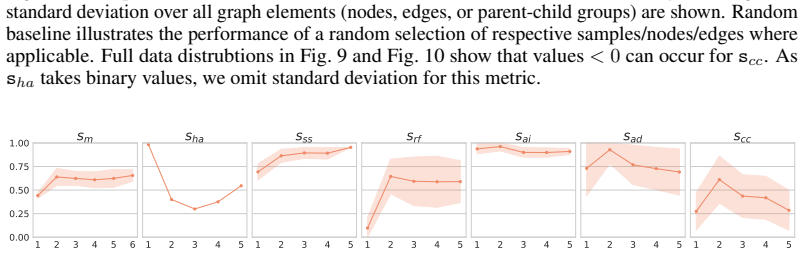
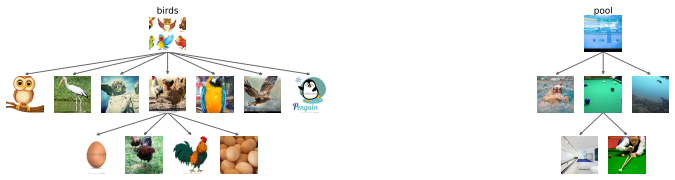

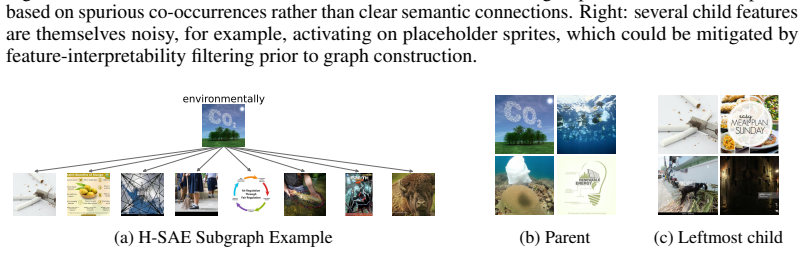

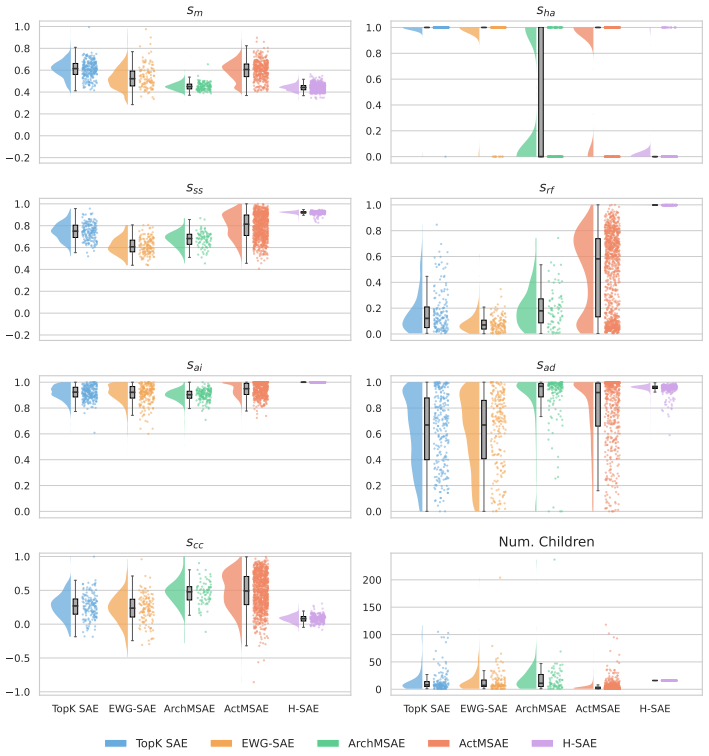
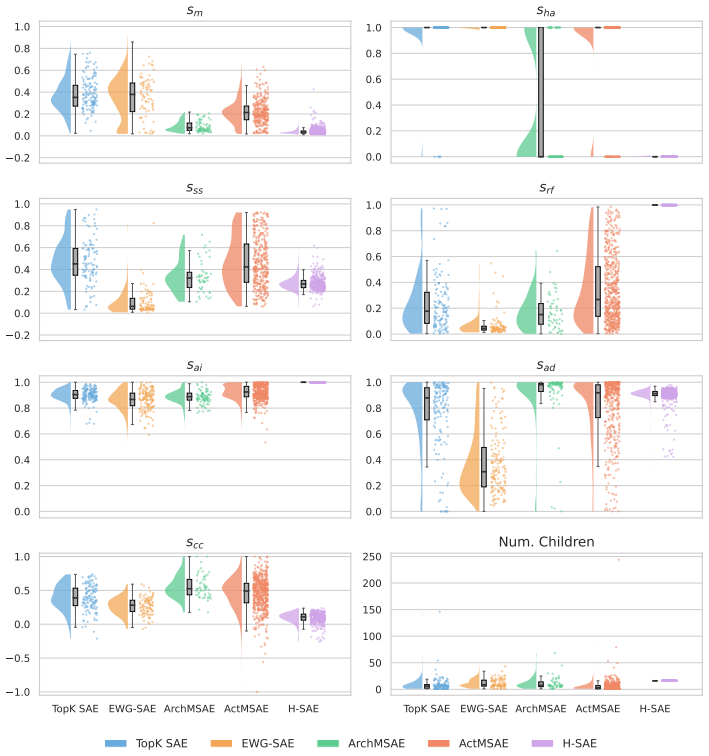
read the original abstract
Sparse autoencoders (SAEs) have become an important tool for unsupervised concept discovery in large models. To make the resulting feature spaces more interpretable and manageable, recent approaches have begun imposing hierarchical structure, either explicitly or as an implicit effect of training constraints, yet rigorous comparison remains difficult. There are no agreed-upon requirements for what a meaningful feature hierarchy should satisfy, and evaluation has largely relied on qualitative illustrations with fragmented quantitative protocols. To address this, we derive a set of key requirements for generalization/specialization hierarchies in unsupervised concept discovery, drawing on semantic net and taxonomy research alongside recent SAE work, and use them to derive a concrete evaluation protocol. Applying this protocol to current SAE approaches trained on visual data, we find that while feature spaces generally provide a basis for sensible hierarchies, establishing good hierarchical structure remains challenging. In particular, feature absorption, both in its well-known hard form and in a continuous, soft form, systematically compromises hierarchy quality, pointing to a fundamental tension that future approaches will need to navigate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a set of key requirements for generalization/specialization hierarchies from semantic net and taxonomy research, develops a concrete evaluation protocol from them, and applies the protocol to current SAE approaches trained on visual data. It concludes that while SAE feature spaces can support sensible hierarchies, feature absorption (both hard and soft forms) systematically compromises hierarchy quality, identifying a fundamental tension for future work.
Significance. If the evaluation criteria prove appropriate for the SAE setting, the work supplies a quantitative protocol that moves beyond qualitative illustrations and isolates feature absorption as a load-bearing obstacle to hierarchical structure. This could usefully inform SAE training objectives that aim for both sparsity and hierarchy.
major comments (1)
- [Abstract] Abstract: The central claim that feature absorption compromises 'meaningful' hierarchy quality rests on the untested modeling choice that requirements imported from semantic-net and taxonomy literature are the right standard for unsupervised activation-based features. The manuscript shows deviation from these criteria but provides no evidence (e.g., downstream task performance, human interpretability ratings, or ablation on utility) that hierarchies violating the criteria are less useful in the SAE context; this directly determines both the quantitative protocol and the absorption conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive assessment of the paper's contribution in proposing a quantitative protocol. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that feature absorption compromises 'meaningful' hierarchy quality rests on the untested modeling choice that requirements imported from semantic-net and taxonomy literature are the right standard for unsupervised activation-based features. The manuscript shows deviation from these criteria but provides no evidence (e.g., downstream task performance, human interpretability ratings, or ablation on utility) that hierarchies violating the criteria are less useful in the SAE context; this directly determines both the quantitative protocol and the absorption conclusion.
Authors: We agree that the choice of criteria constitutes a modeling decision and that the manuscript does not include direct empirical validation (such as downstream task performance, human ratings, or utility ablations) showing that violations reduce usefulness specifically within SAE applications. The requirements were selected because they formalize core properties of generalization/specialization hierarchies from established semantic-net and taxonomy research, providing a principled basis for evaluating unsupervised concept discovery rather than relying solely on qualitative illustrations. The paper's primary finding concerns the systematic impact of feature absorption under this protocol. We will revise the abstract and add a dedicated limitations paragraph in the discussion to explicitly frame the criteria as a proposed standard drawn from the literature, acknowledge the absence of direct utility evidence as an open question, and note that alternative criteria could yield different conclusions. This revision clarifies the scope without changing the reported results on absorption. revision: partial
Circularity Check
Requirements derived externally from semantic net/taxonomy research; no reduction to self-defined quantities or load-bearing self-citations
full rationale
The paper states it derives key requirements for hierarchies 'drawing on semantic net and taxonomy research alongside recent SAE work' and then applies the resulting evaluation protocol to existing SAE methods. No equations or claims reduce a prediction or central result to a fitted parameter or self-citation chain defined within the paper. The evaluation criteria are imported from external literature rather than constructed from the authors' own prior outputs. This is self-contained against external benchmarks and receives the default low circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Requirements drawn from semantic net and taxonomy research are suitable criteria for evaluating meaningful generalization/specialization hierarchies in SAE feature spaces.
Reference graph
Works this paper leans on
-
[1]
Domain-specific knowledge graphs: A survey.Journal of Network and Computer Applications, 185:103076, 2021
Bilal Abu-Salih. Domain-specific knowledge graphs: A survey.Journal of Network and Computer Applications, 185:103076, 2021
2021
-
[2]
Saes are good for steering–if you select the right features
Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering–if you select the right features. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 10252–10270, 2025
2025
-
[3]
The psychological nature of concepts
E James Archer. The psychological nature of concepts. InAnalyses of concept learning, pages 37–49. Elsevier, 1966
1966
-
[4]
Semeval-2016 task 13: Taxonomy extraction evaluation (texeval-2)
Georgeta Bordea, Els Lefever, and Paul Buitelaar. Semeval-2016 task 13: Taxonomy extraction evaluation (texeval-2). InProceedings of the 10th international workshop on semantic evaluation (semeval), pages 1081–1091, 2016
2016
-
[5]
Brachman
Ronald J. Brachman. What is-a is and isn’t: An analysis of taxonomic links in semantic networks.Computer;(United States), 10, 1983
1983
-
[6]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
2023
-
[7]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547, 2025
arXiv 2025
-
[8]
David Chanin, James Wilken-Smith, Tomáš Dulka, Hardik Bhatnagar, Satvik Golechha, and Joseph Bloom. A is for absorption: Studying feature splitting and absorption in sparse autoen- coders.arXiv preprint arXiv:2409.14507, 2024
arXiv 2024
-
[9]
David Chanin, Tomáš Dulka, and Adrià Garriga-Alonso. Feature hedging: Correlated features break narrow sparse autoencoders.arXiv preprint arXiv:2505.11756, 2025
arXiv 2025
-
[10]
Valérie Costa, Thomas Fel, Ekdeep Singh Lubana, Bahareh Tolooshams, and Demba Ba. From flat to hierarchical: Extracting sparse representations with matching pursuit.arXiv preprint arXiv:2506.03093, 2025
arXiv 2025
-
[11]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
Pith/arXiv arXiv 2023
-
[12]
Mechanistic understanding and validation of large ai models with semanticlens.Nature Machine Intelligence, 7(9):1572–1585, 2025
Maximilian Dreyer, Jim Berend, Tobias Labarta, Johanna Vielhaben, Thomas Wiegand, Sebas- tian Lapuschkin, and Wojciech Samek. Mechanistic understanding and validation of large ai models with semanticlens.Nature Machine Intelligence, 7(9):1572–1585, 2025
2025
-
[13]
A holistic approach to unifying automatic concept extraction and concept importance estimation.Advances in Neural Information Processing Systems, 36:54805–54818, 2023
Thomas Fel, Victor Boutin, Louis Béthune, Rémi Cadène, Mazda Moayeri, Léo Andéol, Mathieu Chalvidal, and Thomas Serre. A holistic approach to unifying automatic concept extraction and concept importance estimation.Advances in Neural Information Processing Systems, 36:54805–54818, 2023. 10
2023
-
[14]
Sparse autoencoders are topic models.arXiv preprint arXiv:2511.16309, 2025
Leander Girrbach and Zeynep Akata. Sparse autoencoders are topic models.arXiv preprint arXiv:2511.16309, 2025
Pith/arXiv arXiv 2025
-
[15]
The perception of relations.Trends in Cognitive Sciences, 25 (6):475–492, 2021
Alon Hafri and Chaz Firestone. The perception of relations.Trends in Cognitive Sciences, 25 (6):475–492, 2021
2021
-
[16]
Measuring and guiding monosemanticity.Advances in Neural Information Processing Systems (NeurIPS), 38, 2025
Ruben Härle, Felix Friedrich, Manuel Brack, Stephan Wäldchen, Björn Deiseroth, Patrick Schramowski, and Kristian Kersting. Measuring and guiding monosemanticity.Advances in Neural Information Processing Systems (NeurIPS), 38, 2025
2025
-
[17]
Automatic acquisition of hyponyms from large text corpora
Marti A Hearst. Automatic acquisition of hyponyms from large text corpora. InCOLING 1992 volume 2: The 14th international conference on computational linguistics, 1992
1992
-
[18]
Proximal methods for sparse hierarchical dictionary learning
Rodolphe Jenatton, Julien Mairal, Francis R Bach, and Guillaume R Obozinski. Proximal methods for sparse hierarchical dictionary learning. InInternational Conference on Machine Learning (ICML), pages 487–494, 2010
2010
-
[19]
Nick Jiang, Xiaoqing Sun, Lisa Dunlap, Lewis Smith, and Neel Nanda. Interpretable embed- dings with sparse autoencoders: A data analysis toolkit.arXiv preprint arXiv:2512.10092, 2025
arXiv 2025
-
[20]
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, et al. Saebench: A comprehen- sive benchmark for sparse autoencoders in language model interpretability.arXiv preprint arXiv:2503.09532, 2025
arXiv 2025
-
[21]
Representing and reasoning over a taxonomy of part– whole relations.Applied Ontology, 3(1-2):91–110, 2008
C Maria Keet and Alessandro Artale. Representing and reasoning over a taxonomy of part– whole relations.Applied Ontology, 3(1-2):91–110, 2008
2008
-
[22]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav)
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational Conference on Machine Learning (ICML), pages 2668–2677. PMLR, 2018
2018
-
[23]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational Conference on Machine Learning (ICML), pages 5338–5348. PMLR, 2020
2020
-
[24]
Sparse autoencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878, 2025
Patrick Leask, Bart Bussmann, Michael Pearce, Joseph Bloom, Curt Tigges, Noura Al Moubayed, Lee Sharkey, and Neel Nanda. Sparse autoencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878, 2025
arXiv 2025
-
[25]
Unlocking hierarchical concept discovery in language models through geometric regularization
Ed Li and Junyu Ren. Unlocking hierarchical concept discovery in language models through geometric regularization. InICLR 2025 Workshop on Building Trust in Language Models and Applications, 2025
2025
-
[26]
The geometry of concepts: Sparse autoencoder feature structure.Entropy, 27(4):344, 2025
Yuxiao Li, Eric J Michaud, David D Baek, Joshua Engels, Xiaoqing Sun, and Max Tegmark. The geometry of concepts: Sparse autoencoder feature structure.Entropy, 27(4):344, 2025
2025
-
[27]
Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, et al. Controllable text generation for large language models: A survey.arXiv preprint arXiv:2408.12599, 2024
arXiv 2024
-
[28]
Conceptnet—a practical commonsense reasoning tool-kit.BT technology journal, 22(4):211–226, 2004
Hugo Liu and Push Singh. Conceptnet—a practical commonsense reasoning tool-kit.BT technology journal, 22(4):211–226, 2004
2004
-
[29]
From atoms to trees: Building a structured feature forest with hierarchical sparse autoencoders
Yifan Luo, Yang Zhan, Jiedong Jiang, Tianyang Liu, Mingrui Wu, Zhennan Zhou, and Bin Dong. From atoms to trees: Building a structured feature forest with hierarchical sparse autoencoders. arXiv preprint arXiv:2602.11881, 2026
arXiv 2026
-
[30]
The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological review, 63(2):81, 1956
George A Miller. The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological review, 63(2):81, 1956
1956
-
[31]
Mark Muchane, Sean Richardson, Kiho Park, and Victor Veitch. Incorporating hierarchical semantics in sparse autoencoder architectures.arXiv preprint arXiv:2506.01197, 2025. 11
arXiv 2025
-
[32]
A method for taxonomy develop- ment and its application in information systems.European journal of information systems, 22 (3):336–359, 2013
Robert C Nickerson, Upkar Varshney, and Jan Muntermann. A method for taxonomy develop- ment and its application in information systems.European journal of information systems, 22 (3):336–359, 2013
2013
-
[33]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[34]
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models.arXiv preprint arXiv:2504.02821, 2025
arXiv 2025
-
[35]
Gonçalo Paulo, Alex Mallen, Caden Juang, and Nora Belrose. Automatically interpreting millions of features in large language models.arXiv preprint arXiv:2410.13928, 2024
arXiv 2024
-
[36]
Federico Pittino, Vesna Dimitrievska, and Rudolf Heer. Hierarchical concept bottleneck models for vision and their application to explainable fine classification and tracking.Engineering Applications of Artificial Intelligence, 118:105674, 2023
2023
-
[37]
Concept- based explainable artificial intelligence: A survey.ACM Computing Surveys, 2023
Eleonora Poeta, Gabriele Ciravegna, Eliana Pastor, Tania Cerquitelli, and Elena Baralis. Concept- based explainable artificial intelligence: A survey.ACM Computing Surveys, 2023
2023
-
[38]
Manipulating and measuring model interpretability
Forough Poursabzi-Sangdeh, Daniel G Goldstein, Jake M Hofman, Jennifer Wortman Wort- man Vaughan, and Hanna Wallach. Manipulating and measuring model interpretability. In Proceedings of the 2021 CHI conference on human factors in computing systems, pages 1–52, 2021
2021
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PmLR, 2021
2021
-
[40]
Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery
Sukrut Rao, Sweta Mahajan, Moritz Böhle, and Bernt Schiele. Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery. InEuropean Conference on Computer Vision (ECCV), pages 444–461. Springer, 2024
2024
-
[41]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018
2018
-
[42]
Dong Shu, Xuansheng Wu, Haiyan Zhao, Daking Rai, Ziyu Yao, Ninghao Liu, and Mengnan Du. A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models.arXiv preprint arXiv:2503.05613, 2025
arXiv 2025
-
[43]
Neural concept binder.Advances in Neural Information Processing Systems (NeurIPS), 37:71792–71830, 2024
Wolfgang Stammer, Antonia Wüst, David Steinmann, and Kristian Kersting. Neural concept binder.Advances in Neural Information Processing Systems (NeurIPS), 37:71792–71830, 2024
2024
-
[44]
Ao Sun, Yuanyuan Yuan, Pingchuan Ma, and Shuai Wang. Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning.arXiv preprint arXiv:2402.05945, 2024
arXiv 2024
-
[45]
Ontological evaluation and validation
Samir Tartir, I Budak Arpinar, and Amit P Sheth. Ontological evaluation and validation. In Theory and applications of ontology: Computer applications, pages 115–130. Springer, 2010
2010
-
[46]
Leveraging explanations in interactive machine learning: An overview.Frontiers in Artificial Intelligence, 6:1066049, 2023
Stefano Teso, Öznur Alkan, Wolfgang Stammer, and Elizabeth Daly. Leveraging explanations in interactive machine learning: An overview.Frontiers in Artificial Intelligence, 6:1066049, 2023
2023
-
[47]
A compendium and evaluation of taxonomy quality attributes.Expert Systems, 40(1):e13098, 2023
Michael Unterkalmsteiner and Waleed Abdeen. A compendium and evaluation of taxonomy quality attributes.Expert Systems, 40(1):e13098, 2023
2023
-
[48]
Automated taxonomy construction using large language models: A comparative study of fine-tuning and prompt engineering.Eng, 6(11):283, 2025
Binh Vu, Rashmi Govindraju Naik, Bao Khanh Nguyen, Sina Mehraeen, and Matthias Hemmje. Automated taxonomy construction using large language models: A comparative study of fine-tuning and prompt engineering.Eng, 6(11):283, 2025. 12
2025
-
[49]
Cfm: Language-aligned concept foundation model for vision.arXiv preprint arXiv:2601.13798, 2026
Kai Wittenmayer, Sukrut Rao, Amin Parchami-Araghi, Bernt Schiele, and Jonas Fischer. Cfm: Language-aligned concept foundation model for vision.arXiv preprint arXiv:2601.13798, 2026
arXiv 2026
-
[50]
Pascal Wullschleger, Majid Zarharan, Donnacha Daly, Marc Pouly, and Jennifer Foster. No gold standard, no problem: Reference-free evaluation of taxonomies.arXiv preprint arXiv:2505.11470, 2025
Pith/arXiv arXiv 2025
-
[51]
Sparse autoencoders for dense text embeddings reveal hierarchical feature sub-structure
Christine Ye, Charles O’Neill, John F Wu, and Kartheik G Iyer. Sparse autoencoders for dense text embeddings reveal hierarchical feature sub-structure. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning, 2024
2024
-
[52]
Interpreting clip with hierarchi- cal sparse autoencoders.arXiv preprint arXiv:2502.20578, 2025
Vladimir Zaigrajew, Hubert Baniecki, and Przemyslaw Biecek. Interpreting clip with hierarchi- cal sparse autoencoders.arXiv preprint arXiv:2502.20578, 2025
arXiv 2025
-
[53]
Chain-of-layer: Iteratively prompting large language models for taxonomy induction from limited examples
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Shangbin Feng, Zhenwen Liang, Zhihan Zhang, and Meng Jiang. Chain-of-layer: Iteratively prompting large language models for taxonomy induction from limited examples. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3093–3102, 2024. 13 A Supplementary material A.1 ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.