MotionMAR: Multi-scale Auto-Regressive Human Motion Reconstruction from Sparse Observations
Pith reviewed 2026-06-26 09:25 UTC · model grok-4.3
The pith
A multi-scale autoregressive model in tokenized latent space reconstructs full human motion from sparse observations by building global structure first then adding details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
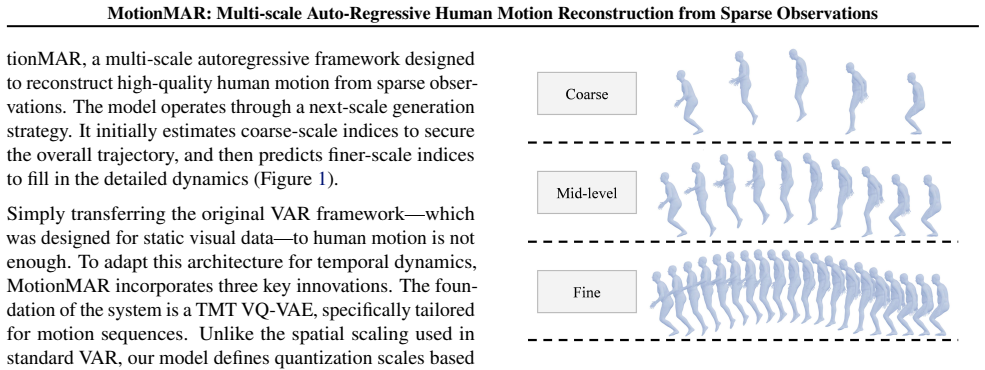
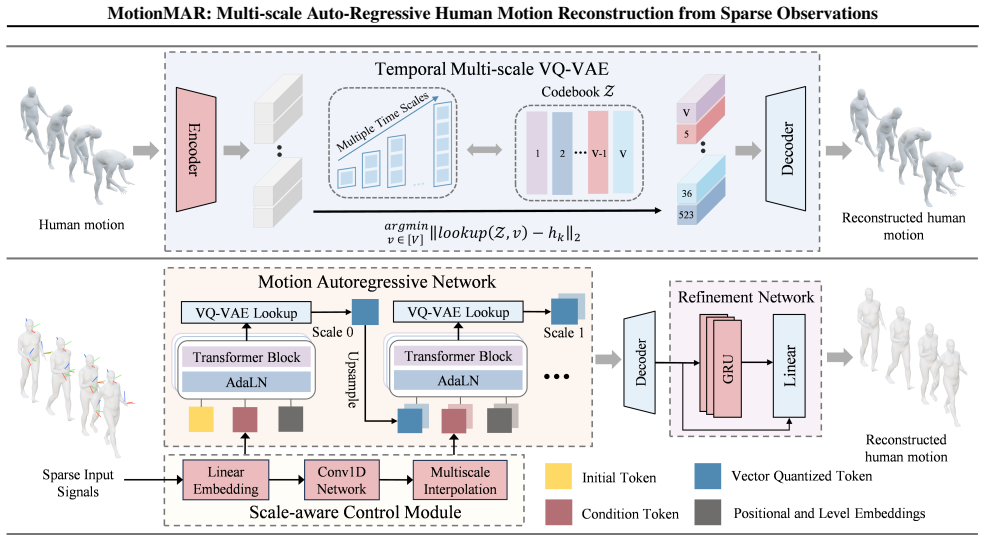
MotionMAR is a coarse-to-fine framework whose four components—Temporal Multi-scale Tokenization VQ-VAE, Motion Autoregressive Network, Scale-Aware Control module, and Motion Refinement Network—jointly encode motion at multiple temporal resolutions, predict latent indices from coarse global structure to fine details, condition the output on sparse observations, and remove quantization artifacts to reach state-of-the-art accuracy on the AMASS dataset.
What carries the argument
The Motion Autoregressive Network, which predicts motion indices level by level in the multi-scale VQ-VAE latent space, first fixing coarse global indices then generating finer indices for temporal details.
If this is right
- Sparse tracking data is integrated at each scale through the Scale-Aware Control module so that generated motion stays consistent with the actual observations.
- Semantic content is isolated from minor jitters because the VQ-VAE operates at multiple temporal resolutions.
- Consecutive poses become smooth and quantization errors are removed by the final Motion Refinement Network.
- Overall accuracy reaches state-of-the-art levels on the AMASS benchmark.
Where Pith is reading between the lines
- The same staged prediction could be continued autoregressively to forecast future frames beyond the observed window.
- Sensor layouts might be optimized by placing devices to capture the dominant scales identified by the tokenization process.
- If the low-to-high frequency separation proves stable, the architecture could transfer to reconstructing trajectories of non-human articulated systems such as robots or animals.
Load-bearing premise
Human motion has a clean temporal hierarchical structure that can be separated into low-frequency global trajectories and high-frequency details and modeled by multi-level autoregressive prediction inside a VQ-VAE latent space.
What would settle it
Ablating the multi-scale tokenization and level-by-level autoregressive prediction on the AMASS dataset and measuring whether reconstruction error rises above that of a single-scale autoregressive baseline.
Figures

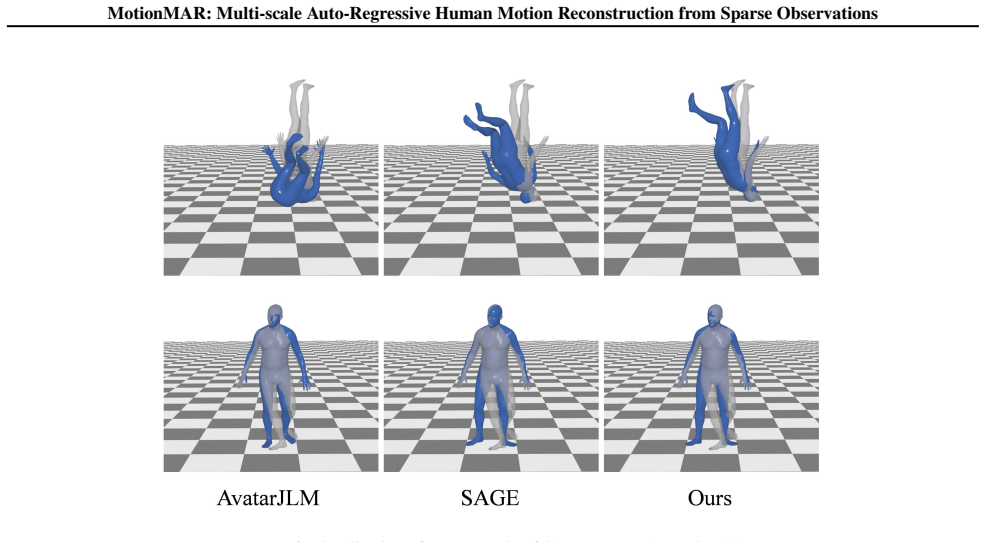
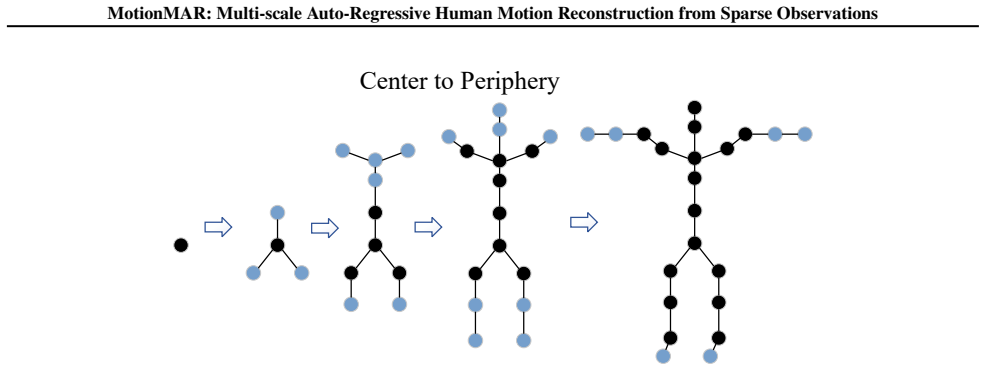
read the original abstract
Human motion follows a temporal hierarchical structure, transitioning from low-frequency global trajectories to high-frequency details. Inspired by the success of multi-level autoregressive models in computer vision, we propose MotionMAR, a coarse-to-fine framework for motion reconstruction from sparse observations. It first estimates the global trajectory of human motion and then gradually refines the temporal details. This architecture consists of four integrated components. The Temporal Multi-scale Tokenization (TMT) VQ-VAE encodes the data at multiple temporal resolutions, separating semantic motion from minor jitters. The Motion Autoregressive Network (MAN) operates in this latent space, predicting motion across scales. It first establishes the global structure through coarse indices and then generates finer indices to recover specific details. Meanwhile, the Scale-Aware Control (SAC) module integrates sparse tracking data to ensure the generated output aligns with actual observations. The Motion Refinement Network (MRN) subsequently smooths consecutive poses and eliminates quantization artifacts. Experiments show that MotionMAR achieves state-of-the-art accuracy on the AMASS dataset, providing a reliable and structure-aware approach for motion reconstruction. The source code is publicly available at http://www.lidarhumanmotion.net/motionmar/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MotionMAR, a coarse-to-fine framework for human motion reconstruction from sparse observations. It encodes motion via a Temporal Multi-scale Tokenization (TMT) VQ-VAE that separates semantic content from jitter at multiple temporal resolutions, uses a Motion Autoregressive Network (MAN) to predict coarse-to-fine indices in the latent space, incorporates sparse observations through a Scale-Aware Control (SAC) module, and applies a Motion Refinement Network (MRN) to remove quantization artifacts and ensure smoothness. The central claim is that this architecture achieves state-of-the-art accuracy on the AMASS dataset by exploiting the temporal hierarchical structure of human motion.
Significance. If the performance claims are substantiated, the work contributes a structure-aware autoregressive pipeline that explicitly models global trajectories before local details in a VQ-VAE latent space. Public release of the source code is a positive factor for reproducibility and follow-up work in sparse motion capture.
major comments (1)
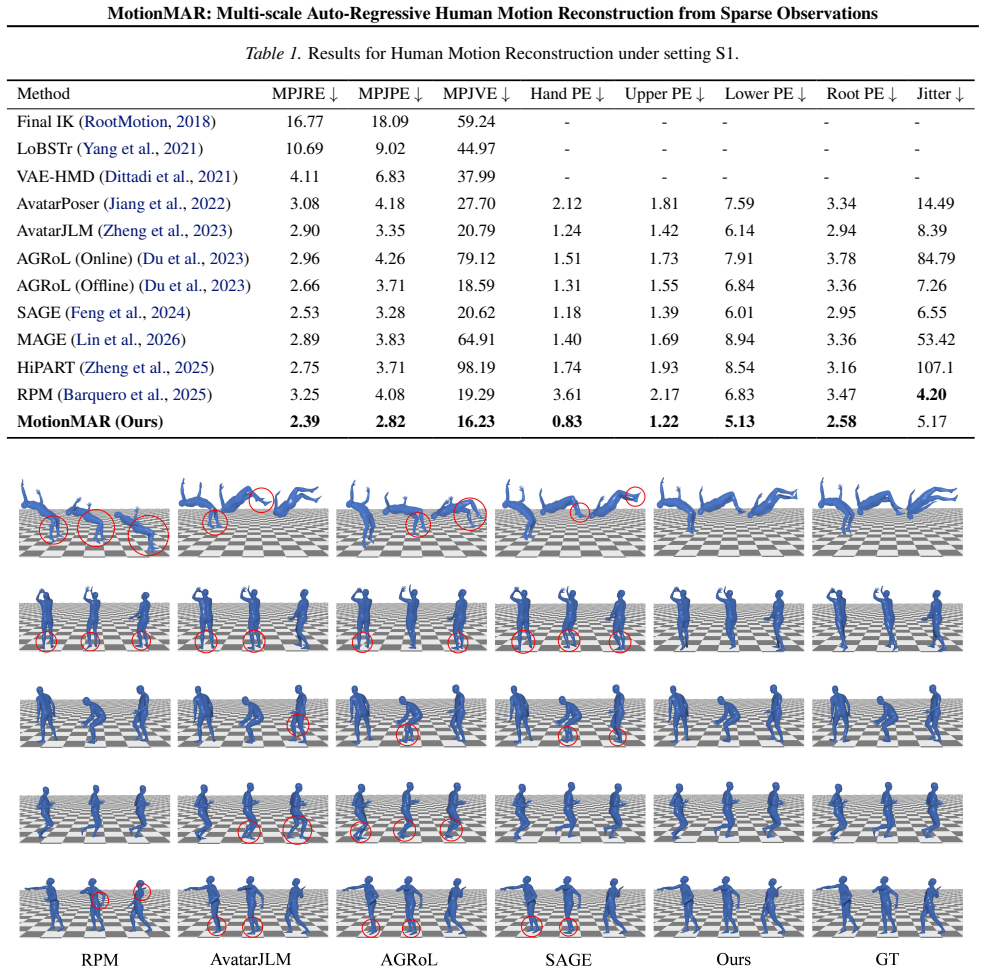
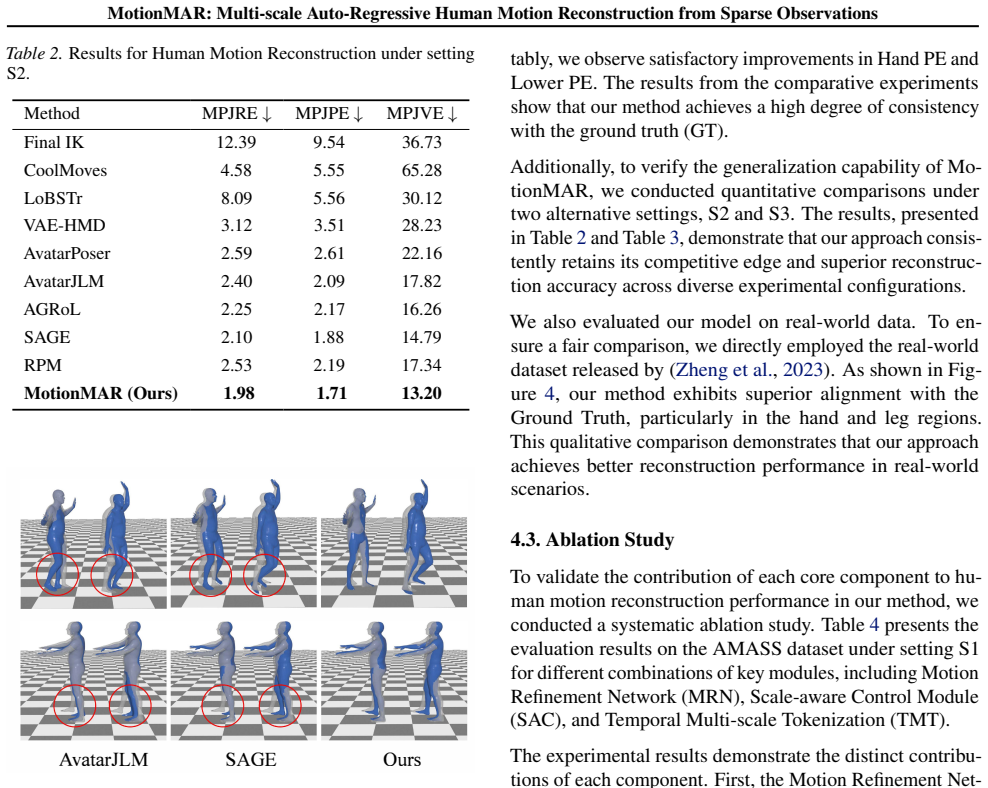
- [Abstract] Abstract: the assertion that MotionMAR 'achieves state-of-the-art accuracy on the AMASS dataset' is presented without any quantitative metrics (e.g., MPJPE, acceleration error), baseline comparisons, error bars, or ablation results. This absence prevents verification of the central empirical claim.
minor comments (1)
- [Abstract] The high-level description of the four components (TMT VQ-VAE, MAN, SAC, MRN) and their integration would benefit from an explicit diagram or pseudocode showing data flow between modules.
Simulated Author's Rebuttal
We thank the referee for their comment. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that MotionMAR 'achieves state-of-the-art accuracy on the AMASS dataset' is presented without any quantitative metrics (e.g., MPJPE, acceleration error), baseline comparisons, error bars, or ablation results. This absence prevents verification of the central empirical claim.
Authors: We agree that the abstract would benefit from including key quantitative results to allow immediate verification of the SOTA claim. The manuscript body contains the requested evaluations (MPJPE, acceleration error, baseline comparisons, error bars, and ablations on AMASS). We will revise the abstract to incorporate the primary metrics and comparisons from the experiments section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline (TMT VQ-VAE + MAN + SAC + MRN) whose SOTA claim on AMASS rests on measured reconstruction accuracy rather than any equation that reduces a prediction to a fitted input or self-citation by construction. No load-bearing derivation step is shown to be equivalent to its own inputs; the architecture is presented as a standard coarse-to-fine autoregressive model whose validity is tested externally.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Temporal Multi-scale Tokenization (TMT) VQ-VAE
no independent evidence
-
Motion Autoregressive Network (MAN)
no independent evidence
-
Scale-Aware Control (SAC) module
no independent evidence
-
Motion Refinement Network (MRN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
HiSC4D: Human-Centered Interaction and 4D Scene Capture in Large-Scale Space Using Wearable IMUs and LiDAR , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
FlashCap: Millisecond-Accurate Human Motion Capture via Flashing LEDs and Event-Based Vision , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
-
[9]
European Conference on Computer Vision , pages=
Gimo: Gaze-informed human motion prediction in context , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hmd-poser: On-device real-time human motion tracking from scalable sparse observations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
European Conference on Computer Vision , pages=
Egoposer: Robust real-time egocentric pose estimation from sparse and intermittent observations everywhere , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[12]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
End-to-end recovery of human shape and pose , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Neural descent for visual 3d human pose and shape , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
Seminal Graphics Papers: Pushing the Boundaries, Volume 2 , pages=
SMPL: A skinned multi-person linear model , author=. Seminal Graphics Papers: Pushing the Boundaries, Volume 2 , pages=
-
[15]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
HuMoR: 3D Human Motion Model for Robust Pose Estimation , author=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2021
-
[16]
2019 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Learning to Reconstruct 3D Human Pose and Shape via Model-Fitting in the Loop , author=. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2019
-
[17]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
VIBE: Video Inference for Human Body Pose and Shape Estimation , author=. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2020
-
[18]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
LiDARCap: Long-range Markerless 3D Human Motion Capture with LiDAR Point Clouds , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Reli11d: A comprehensive multimodal human motion dataset and method , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
CIMI4D: A Large Multimodal Climbing Motion Dataset under Human-scene Interactions , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2023
-
[21]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[22]
European Conference on Computer Vision , year=
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing , author=. European Conference on Computer Vision , year=
-
[23]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Stratified Avatar Generation from Sparse Observations , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[24]
ArXiv , year=
Pose2Mesh: Graph Convolutional Network for 3D Human Pose and Mesh Recovery from a 2D Human Pose , author=. ArXiv , year=
-
[25]
British Machine Vision Conference , year=
Hierarchical Graph Networks for 3D Human Pose Estimation , author=. British Machine Vision Conference , year=
-
[26]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
HiPART: Hierarchical Pose AutoRegressive Transformer for Occluded 3D Human Pose Estimation , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Diffusiondet: Diffusion model for object detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[29]
Journal of Machine Learning Research , volume=
Cascaded diffusion models for high fidelity image generation , author=. Journal of Machine Learning Research , volume=
-
[30]
Proceedings of the 30th ACM International Conference on Multimedia , pages=
Prodiff: Progressive fast diffusion model for high-quality text-to-speech , author=. Proceedings of the 30th ACM International Conference on Multimedia , pages=
-
[31]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Diffsound: Discrete diffusion model for text-to-sound generation , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2023 , publisher=
2023
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Bodiffusion: Diffusing sparse observations for full-body human motion synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
European Conference on Computer Vision , pages=
Posegpt: Quantization-based 3d human motion generation and forecasting , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[34]
Advances in Neural Information Processing Systems , volume=
Motiongpt: Human motion as a foreign language , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Generating human motion from textual descriptions with discrete representations , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Realistic full-body tracking from sparse observations via joint-level modeling , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[40]
Eyes Japan MoCap Dataset , author=
-
[41]
CMU MoCap Dataset , author=
-
[42]
Journal of Vision , year=
Decomposing biological motion: A linear model for analysis and synthesis of human gait patterns , author=. Journal of Vision , year=
-
[43]
Institut f
Mocap database hdm05 , author=. Institut f
-
[44]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[45]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[46]
arXiv preprint arXiv:2305.10403 , year=
Palm 2 technical report , author=. arXiv preprint arXiv:2305.10403 , year=
-
[47]
arXiv preprint arXiv:2203.15556 , year=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
-
[48]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[49]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[50]
arXiv preprint arXiv:2211.05100 , year=
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
-
[51]
arXiv preprint arXiv:2107.02137 , year=
Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation , author=. arXiv preprint arXiv:2107.02137 , year=
-
[52]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[53]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
arXiv preprint arXiv:2110.04627 , year=
Vector-quantized image modeling with improved vqgan , author=. arXiv preprint arXiv:2110.04627 , year=
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
On the continuity of rotation representations in neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[58]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Full-body motion from a single head-mounted device: Generating smpl poses from partial observations , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[59]
Computer Graphics Forum , volume=
Lobstr: Real-time lower-body pose prediction from sparse upper-body tracking signals , author=. Computer Graphics Forum , volume=. 2021 , organization=
2021
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Flag: Flow-based 3d avatar generation from sparse observations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
Computer Graphics Forum , volume=
MOVIN: Real-time Motion Capture using a Single LiDAR , author=. Computer Graphics Forum , volume=. 2023 , organization=
2023
-
[62]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
AMASS: Archive of motion capture as surface shapes , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[63]
SIGGRAPH Asia 2022 Conference Papers , pages=
Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation , author=. SIGGRAPH Asia 2022 Conference Papers , pages=
2022
-
[64]
Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao , booktitle=. Vi
-
[65]
2019 , howpublished =
Vicon Motion Capture , author=. 2019 , howpublished =
2019
-
[66]
2019 , howpublished =
Xsens Motion Capture , author=. 2019 , howpublished =
2019
-
[67]
2021 , howpublished =
Noitom Motion Capture , author=. 2021 , howpublished =
2021
-
[68]
2024 , howpublished =
Latitude Climbing , title =. 2024 , howpublished =
2024
-
[69]
2021 , howpublished =
Abhinav Tyagi , title =. 2021 , howpublished =
2021
-
[70]
Continuous-Time Human Motion Field from Events , journal =
Ziyun Wang and Ruijun Zhang and Zi. Continuous-Time Human Motion Field from Events , journal =. 2024 , url =. doi:10.48550/ARXIV.2412.01747 , eprinttype =. 2412.01747 , timestamp =
-
[71]
Current Issues in Sport Science (CISS) , volume=
Comparison of joint kinematics from optical marker-based and inertial sensor-based motion capture during change-of-direction movements , author=. Current Issues in Sport Science (CISS) , volume=
-
[72]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Spikegs: 3d gaussian splatting from spike streams with high-speed camera motion , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[73]
ACM SIGGRAPH 2024 Conference Papers , pages=
Ultra inertial poser: Scalable motion capture and tracking from sparse inertial sensors and ultra-wideband ranging , author=. ACM SIGGRAPH 2024 Conference Papers , pages=
2024
-
[74]
Nature , year=
Low-latency automotive vision with event cameras , author=. Nature , year=
-
[75]
A Benchmark Dataset for Event-Guided Human Pose Estimation and Tracking in Extreme Conditions , author=
-
[76]
Weakly Supervised 3D Multi-Person Pose Estimation for Large-Scale Scenes Based on Monocular Camera and Single LiDAR , booktitle =
Peishan Cong and Yiteng Xu and Yiming Ren and Juze Zhang and Lan Xu and Jingya Wang and Jingyi Yu and Yuexin Ma , noeditor =. Weakly Supervised 3D Multi-Person Pose Estimation for Large-Scale Scenes Based on Monocular Camera and Single LiDAR , booktitle =
-
[77]
2019 , url =
Shoushun Chen and Menghan Guo , title =. 2019 , url =
2019
-
[78]
Patrick Lichtsteiner and Christoph Posch and Tobi Delbr. A 128. 2008 , url =. doi:10.1109/JSSC.2007.914337 , timestamp =
-
[79]
In: 2020 25th International Conference on Pattern Recognition (ICPR)
Michael F. 25th International Conference on Pattern Recognition,. 2020 , url =. doi:10.1109/ICPR48806.2021.9412785 , timestamp =
-
[80]
Wenjun Jiang and Hongfei Xue and Chenglin Miao and Shiyang Wang and Sen Lin and Chong Tian and Srinivasan Murali and Haochen Hu and Zhi Sun and Lu Su , title =. MobiCom '20: The 26th Annual International Conference on Mobile Computing and Networking, London, United Kingdom, September 21-25, 2020 , pages =. 2020 , url =. doi:10.1145/3372224.3380900 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.