Rethinking Prototype-based Similarity Learning for Few-Shot Object Detection
Pith reviewed 2026-06-30 10:35 UTC · model grok-4.3
The pith
Text-anchored semantic masks and stage-aligned regression resolve inter-class confusion and localization issues in prototype-based few-shot object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
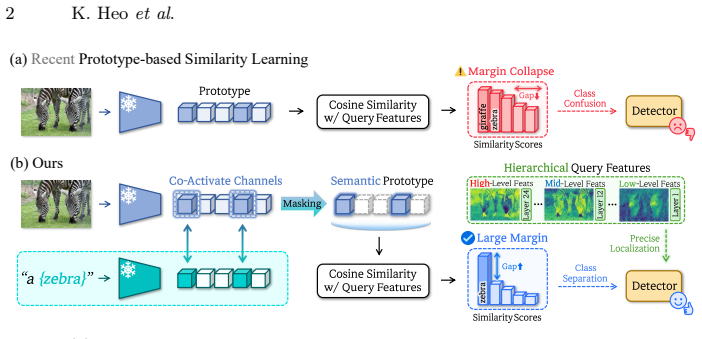
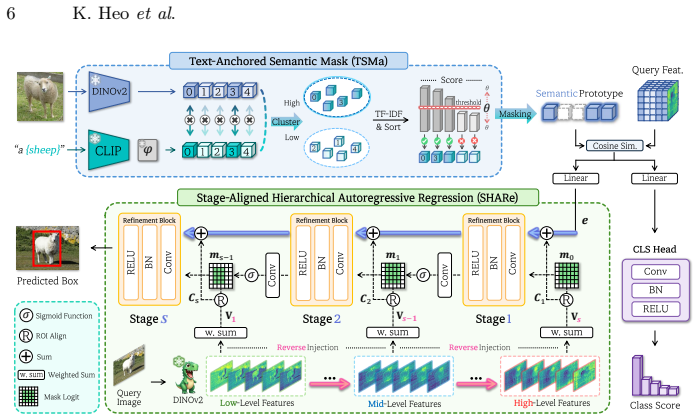
By using class-level text features as semantic anchors to identify aligned visual channels, suppress style-induced noise, and enlarge inter-class similarity margins, and by reformulating localization as a hierarchical autoregressive process that aligns deeper ViT layers with early coarse regression and shallower layers with later spatial refinement, prototype-based similarity learning overcomes class confusion and insufficient spatial cues to reach new state-of-the-art few-shot detection performance.
What carries the argument
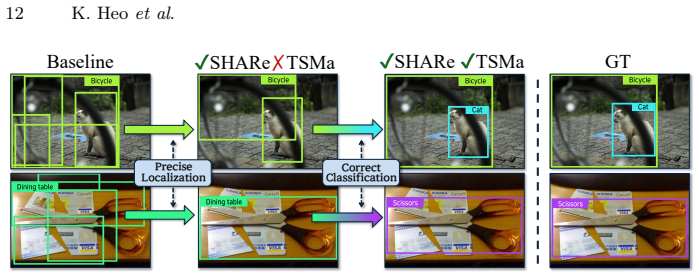
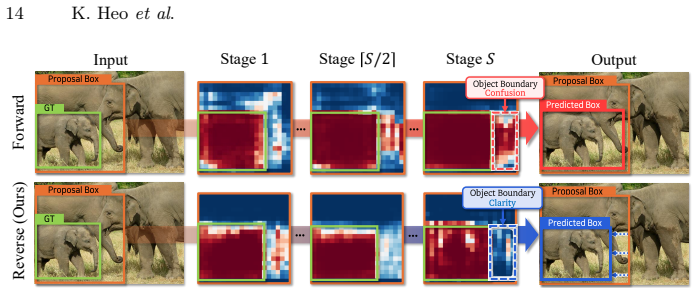
Text-Anchored Semantic Mask (TSMa) selects class-intrinsic channels through visual-text channel interaction, while Stage-Aligned Hierarchical Autoregressive Regression (SHARe) progressively updates bounding boxes across ViT abstraction levels from deep to shallow.
If this is right
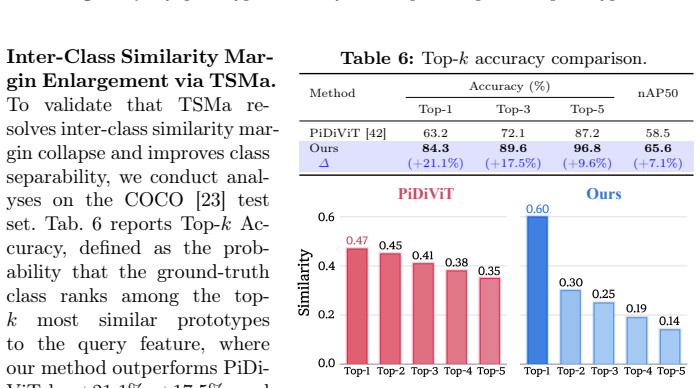
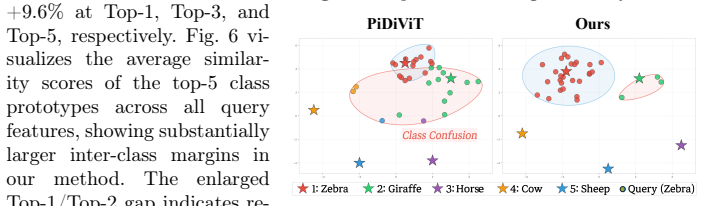
- TSMa reduces class confusion by enlarging similarity margins between prototypes.
- SHARe supplies the missing spatial information by using layer-specific cues at each regression stage.
- The two components together enable training-free adaptation to novel classes with both higher classification and localization accuracy.
- The gains are measured as a 10.1 point increase in normalized AP on the COCO few-shot benchmark.
Where Pith is reading between the lines
- The same text-visual channel selection could be tested on other few-shot tasks such as instance segmentation where semantic alignment matters.
- The autoregressive stage progression might be applied to standard detectors outside the few-shot regime to improve box quality.
- If ViT layers naturally match task granularity, similar alignment could be explored for other vision pipelines that combine classification and localization.
Load-bearing premise
Class-level text features can reliably act as semantic anchors to select aligned visual channels and enlarge inter-class margins, and ViT layer-wise abstraction levels can be aligned with regression stages such that deeper layers guide coarse localization while shallower layers refine spatial details.
What would settle it
A controlled test in which removing the text-anchoring step leaves inter-class margins unchanged or in which swapping the ViT layer-to-stage assignment yields no drop in localization accuracy would falsify the claimed mechanisms.
Figures

read the original abstract
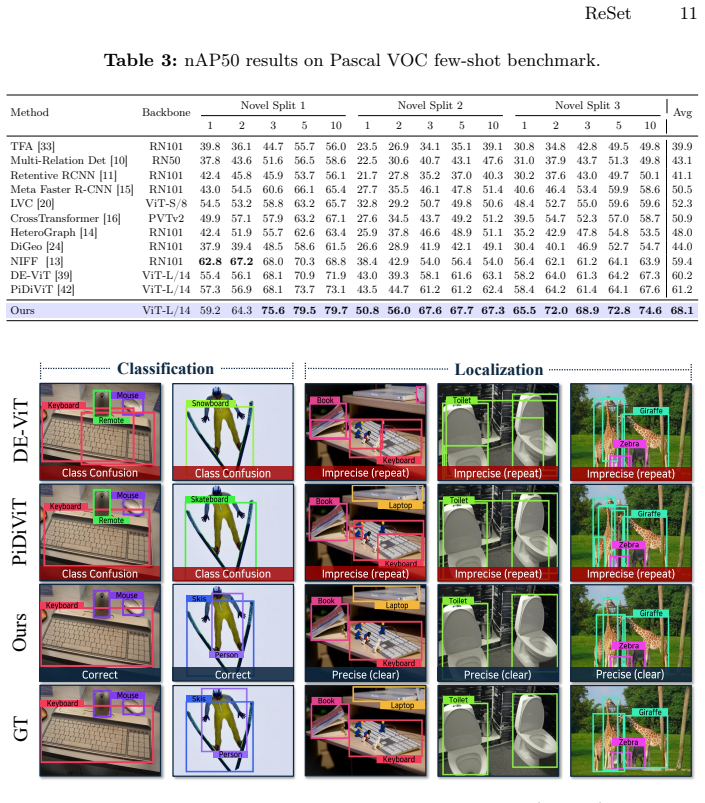
Few-shot object detection aims to detect novel object categories from only a few labeled examples, avoiding costly large-scale annotation. Recent prototype-based similarity learning approaches enable training-free adaptation by matching query features with class prototypes. However, they suffer from two fundamental limitations: (i) class confusion arising from inter-class similarity margin collapse, and (ii) insufficient visual cues for precise localization, as similarity scores capture only class-level semantic affinity while providing limited spatial information. To address these issues, we introduce two complementary components. Text-Anchored Semantic Mask (TSMa) leverages class-level text features as semantic anchors to identify semantically aligned channels through channel-wise interaction between visual and text features. By suppressing style-induced spurious responses and emphasizing class-intrinsic signals, TSMa enlarges inter-class similarity margins and mitigates class confusion. We further propose Stage-Aligned Hierarchical Autoregressive Regression (SHARe), which reformulates localization as a hierarchical autoregressive process that progressively refines bounding boxes across multiple stages. SHARe leverages the layer-wise characteristics of ViT representations by aligning feature abstraction levels with regression stages: deeper layers guide early coarse localization, while shallower layers rich in edge and texture cues refine spatial details in later stages. Experiments on COCO demonstrate a new state of the art, outperforming the previous best by +10.1 nAP, with extensive analysis validating each component. The code is available at https://github.com/VisualScienceLab-KHU/ReSet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Text-Anchored Semantic Mask (TSMa) and Stage-Aligned Hierarchical Autoregressive Regression (SHARe) to mitigate inter-class similarity margin collapse and insufficient spatial cues in prototype-based few-shot object detection. TSMa uses class-level text features (e.g., from CLIP) as semantic anchors for channel-wise interaction to suppress spurious responses and enlarge margins; SHARe reformulates localization as a hierarchical autoregressive process aligned with ViT layer abstraction levels. Experiments on COCO are reported to achieve new SOTA performance with a +10.1 nAP gain over prior best, supported by component analysis; code is released.
Significance. If the reported gains prove robust, the work would represent a meaningful advance in few-shot object detection by demonstrating effective integration of text-visual channel alignment and stage-wise regression with ViT features. The public code release strengthens reproducibility and enables direct follow-up.
major comments (3)
- [Abstract, §4] Abstract and §4 (experiments): The central +10.1 nAP claim is presented without tabulated baseline details, exact prior method name, shot setting (e.g., 1/5/10-shot), or error bars; this makes it impossible to verify whether the margin is driven by TSMa/SHARe or by unstated protocol choices.
- [§3.1] §3.1 (TSMa): The channel-selection mechanism assumes class-name text embeddings reliably identify semantically aligned visual channels for novel COCO categories; no ablation isolates performance under domain shift or when text-visual misalignment occurs, leaving the margin-enlargement claim load-bearing yet untested against the skeptic's concern.
- [§3.2] §3.2 (SHARe): The alignment of ViT layer abstraction levels with regression stages (deeper for coarse, shallower for refinement) is presented as a design choice without quantitative justification that this hierarchy outperforms standard multi-stage regression heads on the same backbone.
minor comments (2)
- [Abstract] Notation for nAP should be defined on first use (novel-class average precision).
- [§4] Figure captions for qualitative results should explicitly state the shot setting and whether TSMa/SHARe are ablated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and proposed revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experiments): The central +10.1 nAP claim is presented without tabulated baseline details, exact prior method name, shot setting (e.g., 1/5/10-shot), or error bars; this makes it impossible to verify whether the margin is driven by TSMa/SHARe or by unstated protocol choices.
Authors: We agree that the presentation lacks sufficient detail for verification. In the revised manuscript, we will expand §4 with a comprehensive table listing the exact prior best method name, results broken down by 1-shot/5-shot/10-shot settings on COCO, and error bars from multiple runs. This will explicitly attribute the +10.1 nAP gain to the proposed components under standard protocols. revision: yes
-
Referee: [§3.1] §3.1 (TSMa): The channel-selection mechanism assumes class-name text embeddings reliably identify semantically aligned visual channels for novel COCO categories; no ablation isolates performance under domain shift or when text-visual misalignment occurs, leaving the margin-enlargement claim load-bearing yet untested against the skeptic's concern.
Authors: The COCO novel-class experiments already evaluate TSMa on categories outside typical CLIP training distributions, providing evidence of robustness. However, we acknowledge the absence of an explicit misalignment ablation. We will add a targeted discussion in §3.1 and a supplementary ablation using generic or mismatched text prompts to quantify sensitivity, while noting that full domain-shift experiments fall outside the current scope. revision: partial
-
Referee: [§3.2] §3.2 (SHARe): The alignment of ViT layer abstraction levels with regression stages (deeper for coarse, shallower for refinement) is presented as a design choice without quantitative justification that this hierarchy outperforms standard multi-stage regression heads on the same backbone.
Authors: We will add a new ablation study in §4 that directly compares SHARe against a standard multi-stage regression head applied to the identical ViT backbone features (without layer alignment). This will provide quantitative evidence supporting the hierarchical alignment choice. revision: yes
Circularity Check
No circularity: claims rest on external benchmark validation, not internal definitions or self-citations
full rationale
The paper introduces TSMa and SHARe as new modules for prototype-based few-shot detection, with performance asserted via COCO experiments (+10.1 nAP over prior best) rather than any derivation that reduces to fitted inputs or self-referential equations. No load-bearing steps invoke self-citations, uniqueness theorems from the same authors, or ansatzes smuggled via prior work; the text features and hierarchical regression are presented as design choices validated externally. The derivation chain is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Class-level text features from a pre-trained model can serve as reliable semantic anchors to identify aligned visual channels and suppress style-induced responses.
- domain assumption ViT representations exhibit layer-wise characteristics in which deeper layers supply coarse localization cues and shallower layers supply edge and texture cues suitable for progressive refinement.
Reference graph
Works this paper leans on
-
[1]
ACM computing surveys (CSUR)54(11s), 1–37 (2022)
Antonelli, S., Avola, D., Cinque, L., Crisostomi, D., Foresti, G.L., Galasso, F., Marini, M.R., Mecca, A., Pannone, D.: Few-shot object detection: A survey. ACM computing surveys (CSUR)54(11s), 1–37 (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Barsellotti,L.,Bianchi,L.,Messina,N.,Carrara,F.,Cornia,M.,Baraldi,L.,Falchi, F., Cucchiara, R.: Talking to dino: Bridging self-supervised vision backbones with language for open-vocabulary segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22025–22035 (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bulat, A., Guerrero, R., Martinez, B., Tzimiropoulos, G.: Fs-detr: Few-shot detec- tion transformer with prompting and without re-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11793–11802 (2023)
2023
-
[4]
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition
Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Thing and stuff classes in context. In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition. pp. 1209–1218 (2018)
2018
-
[5]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, D.J., Hsieh, H.Y., Liu, T.L.: Adaptive image transformer for one-shot object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12247–12256 (2021)
2021
-
[8]
In: World Confer- ence on Explainable Artificial Intelligence
Dorszewski, T., Tětková, L., Jenssen, R., Hansen, L.K., Wickstrøm, K.K.: From colors to classes: Emergence of concepts in vision transformers. In: World Confer- ence on Explainable Artificial Intelligence. pp. 28–47. Springer (2025)
2025
-
[9]
Everingham,M.,VanGool,L.,Williams,C.K.,Winn,J.,Zisserman,A.:Thepascal visualobjectclasses(voc)challenge.Internationaljournalofcomputervision88(2), 303–338 (2010)
2010
-
[10]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Fan, Q., Zhuo, W., Tang, C.K., Tai, Y.W.: Few-shot object detection with attention-rpn and multi-relation detector. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 4013–4022 (2020)
2020
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, Z., Ma, Y., Li, Z., Sun, J.: Generalized few-shot object detection without forgetting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4527–4536 (2021)
2021
-
[12]
In: European Conference on Computer Vision
Fu, Y., Wang, Y., Pan, Y., Huai, L., Qiu, X., Shangguan, Z., Liu, T., Fu, Y., Van Gool, L., Jiang, X.: Cross-domain few-shot object detection via enhanced open-set object detector. In: European Conference on Computer Vision. pp. 247–
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guirguis, K., Meier, J., Eskandar, G., Kayser, M., Yang, B., Beyerer, J.: Niff: Alleviating forgetting in generalized few-shot object detection via neural instance feature forging. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24193–24202 (2023) 16 K. Heoet al
2023
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Han, G., He, Y., Huang, S., Ma, J., Chang, S.F.: Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3263–3272 (2021)
2021
-
[15]
In: Proceedings of the AAAI conference on artificial intelligence
Han, G., Huang, S., Ma, J., He, Y., Chang, S.F.: Meta faster r-cnn: Towards ac- curate few-shot object detection with attentive feature alignment. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 780–789 (2022)
2022
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Han, G., Ma, J., Huang, S., Chen, L., Chang, S.F.: Few-shot object detection with fully cross-transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5321–5330 (2022)
2022
-
[17]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
2017
-
[18]
Advances in neural information processing systems32 (2019)
Hsieh, T.I., Lo, Y.C., Chen, H.T., Liu, T.L.: One-shot object detection with co- attention and co-excitation. Advances in neural information processing systems32 (2019)
2019
-
[19]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kang, B., Liu, Z., Wang, X., Yu, F., Feng, J., Darrell, T.: Few-shot object detection via feature reweighting. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8420–8429 (2019)
2019
-
[20]
Kaul, P., Xie, W., Zisserman, A.: Label, verify, correct: A simple few shot object detectionmethod.In:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition. pp. 14237–14247 (2022)
2022
-
[21]
arXiv preprint arXiv:2509.17401 (2025)
Kim,J.,Kim,J.,Shim,Y.,Kim,J.,Jung,S.,Hwang,S.J.:Interpretingvisiontrans- formers via residual replacement model. arXiv preprint arXiv:2509.17401 (2025)
-
[22]
IEEE transactions on neural networks and learning systems35(9), 11958–11978 (2023)
Köhler, M., Eisenbach, M., Gross, H.M.: Few-shot object detection: A compre- hensive survey. IEEE transactions on neural networks and learning systems35(9), 11958–11978 (2023)
2023
-
[23]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ma, J., Niu, Y., Xu, J., Huang, S., Han, G., Chang, S.F.: Digeo: Discriminative geometry-aware learning for generalized few-shot object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3208–3218 (2023)
2023
-
[25]
Syngress Publishing, (2008)
Manning, C.D.: Introduction to information retrieval. Syngress Publishing, (2008)
2008
-
[26]
One-Shot Instance Segmentation
Michaelis, C., Ustyuzhaninov, I., Bethge, M., Ecker, A.S.: One-shot instance seg- mentation. arXiv preprint arXiv:1811.11507 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qiao, L., Zhao, Y., Li, Z., Qiu, X., Wu, J., Zhang, C.: Defrcn: Decoupled faster r- cnn for few-shot object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8681–8690 (2021)
2021
-
[30]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[31]
Advances in neural information processing systems28(2015) ReSet 17
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. Advances in neural information processing systems28(2015) ReSet 17
2015
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, B., Li, B., Cai, S., Yuan, Y., Zhang, C.: Fsce: Few-shot object detection via contrastive proposal encoding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7352–7362 (2021)
2021
-
[33]
arXiv preprint arXiv:2003.06957 (2020)
Wang, X., Huang, T.E., Darrell, T., Gonzalez, J.E., Yu, F.: Frustratingly simple few-shot object detection. arXiv preprint arXiv:2003.06957 (2020)
-
[34]
IEEE transactions on pattern analysis and machine intelligence45(3), 3090–3106 (2022)
Xiao, Y., Lepetit, V., Marlet, R.: Few-shot object detection and viewpoint estima- tion for objects in the wild. IEEE transactions on pattern analysis and machine intelligence45(3), 3090–3106 (2022)
2022
-
[35]
Information Fusion107, 102307 (2024)
Xin, Z., Chen, S., Wu, T., Shao, Y., Ding, W., You, X.: Few-shot object detection: Research advances and challenges. Information Fusion107, 102307 (2024)
2024
-
[36]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yan, X., Chen, Z., Xu, A., Wang, X., Liang, X., Lin, L.: Meta r-cnn: Towards gen- eral solver for instance-level low-shot learning. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9577–9586 (2019)
2019
-
[37]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, H., Cai, S., Sheng, H., Deng, B., Huang, J., Hua, X.S., Tang, Y., Zhang, Y.: Balanced and hierarchical relation learning for one-shot object detection. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7591–7600 (2022)
2022
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(12), 14832–14845 (2022)
Zhang, G., Luo, Z., Cui, K., Lu, S., Xing, E.P.: Meta-detr: Image-level few-shot detection with inter-class correlation exploitation. IEEE Transactions on Pattern Analysis and Machine Intelligence45(12), 14832–14845 (2022)
2022
-
[39]
arXiv preprint arXiv:2309.12969 (2023)
Zhang, X., Liu, Y., Wang, Y., Boularias, A.: Detect everything with few examples. arXiv preprint arXiv:2309.12969 (2023)
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Y., Guo, X., Lu, Y.: Semantic-aligned fusion transformer for one-shot object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7601–7611 (2022)
2022
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L.H., Zhou, L., Dai, X., Yuan, L., Li, Y., et al.: Regionclip: Region-based language-image pretraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 16793–16803 (2022)
2022
-
[42]
Uniform Average
Zhou, H., Liu, Y., Mo, C., Li, W., Peng, B., Liu, L.: When pixel difference patterns meet vit: Pidivit for few-shot object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24309–24318 (2025) Rethinking Prototype-based Similarity Learning for Few-Shot Object Detection Supplementary Material A Implementation Detail...
2025
-
[43]
21. 22. 23. Input Image Input Image
-
[44]
21. 22. 23. Low - Level Features Mid - Level Features High - Level Features Fig.S2:Layer-wise similarity maps of ViT-L features. B.6 Layer-wise ViT Feature Visualization Fig. S2 visualizes the cosine similarity between the CLS token and patch tokens at each of the 24 layers of ViT-L, where the CLS token serves as a global rep- resentation of the image. Th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.