Foresight: Failure Detection for Long-Horizon Robotic Manipulation with Action-Conditioned World Model Latents
Pith reviewed 2026-06-26 08:41 UTC · model grok-4.3
The pith
Action-conditioned world model latents enable reliable failure detection in long-horizon robotic manipulation using only final task success labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
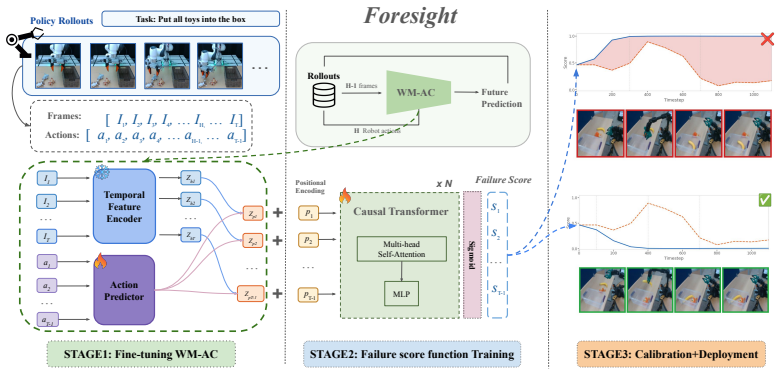
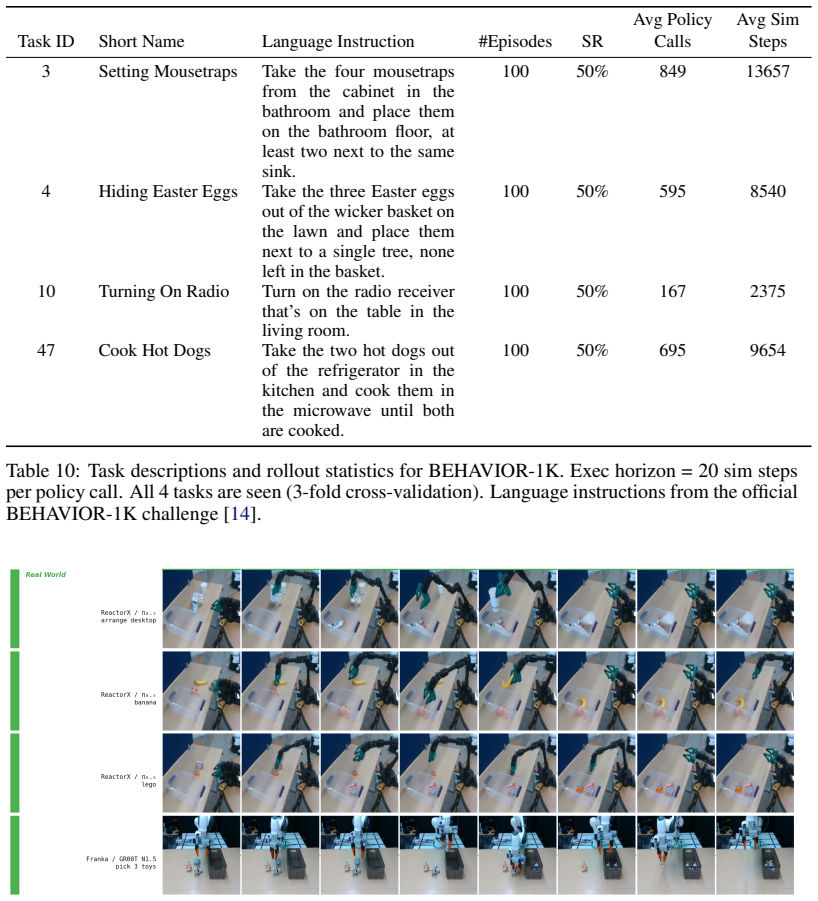
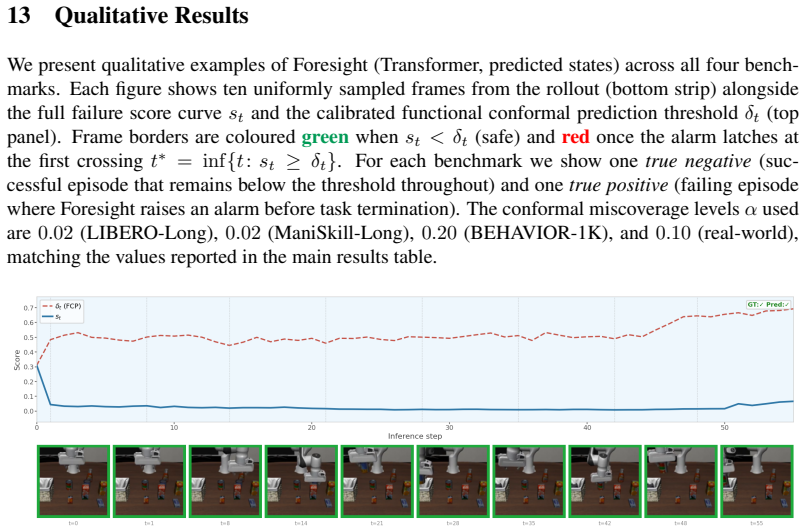
Foresight monitors manipulation trajectories using latent representations from an action-conditioned world model. Foresight is trained using only final task-level success or failure labels. By leveraging predictive world-model embeddings, the method provides a unified framework for failure detection across different policies and further uses functional conformal prediction to calibrate detection thresholds adaptively, with evaluation on state-of-the-art vision-language-action policies in simulation on LIBERO-Long, ManiSkill-Long, and BEHAVIOR-1K plus real-robot validation on a ReactorX-200 arm and a Franka arm.
What carries the argument
Action-conditioned world-model embeddings, which serve as scalable predictive representations of future states given actions and are used to monitor trajectories for signals of failure onset.
If this is right
- Failure detection becomes feasible for long-horizon tasks without requiring dense temporal annotations.
- A single monitoring method applies across multiple vision-language-action policies.
- Functional conformal prediction supplies policy-specific adaptive thresholds.
- The same embeddings support both simulation benchmarks and real-robot hardware validation.
Where Pith is reading between the lines
- Detection signals could be used to trigger online policy recovery or replanning during execution.
- The embeddings might be inspected to classify distinct failure modes rather than only binary detection.
- Similar latent monitoring could transfer to other sequential domains such as autonomous driving or game agents.
Load-bearing premise
Latent representations from an action-conditioned world model trained only on final task success or failure labels contain enough information to detect the onset of ambiguous failures.
What would settle it
A controlled test in which replacing the action-conditioned world model with a non-action-conditioned version or removing the success/failure labels causes detection performance to fall to chance level on the same long-horizon benchmarks.
Figures




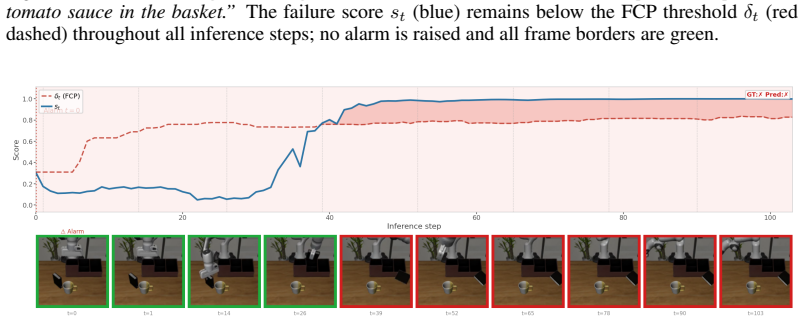
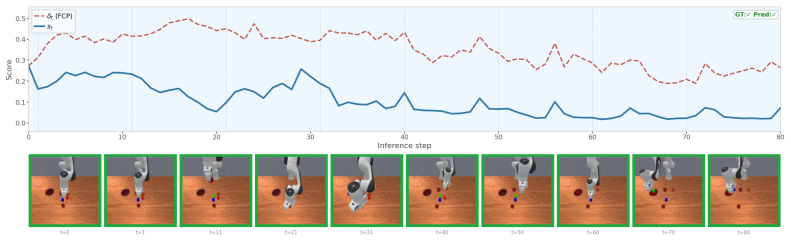
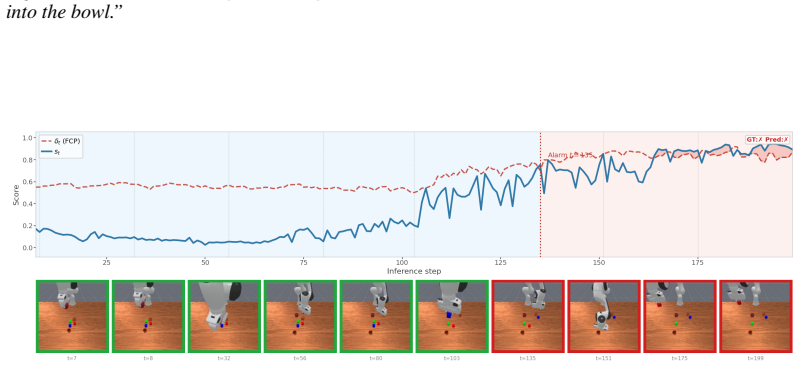
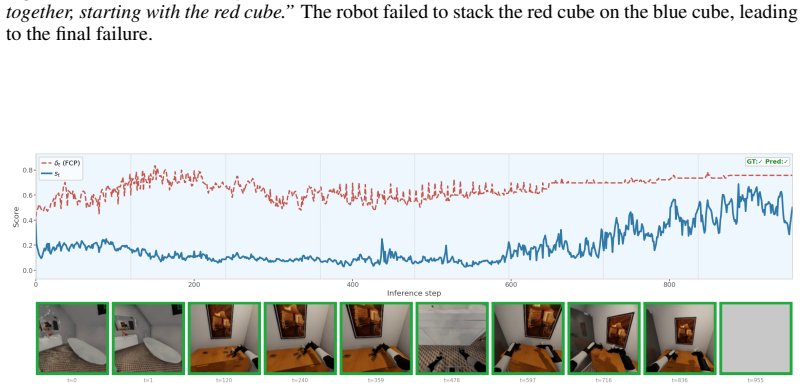
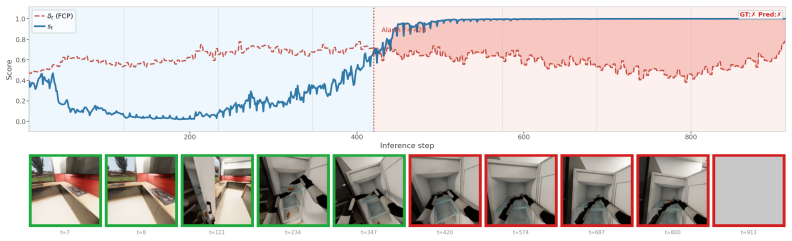
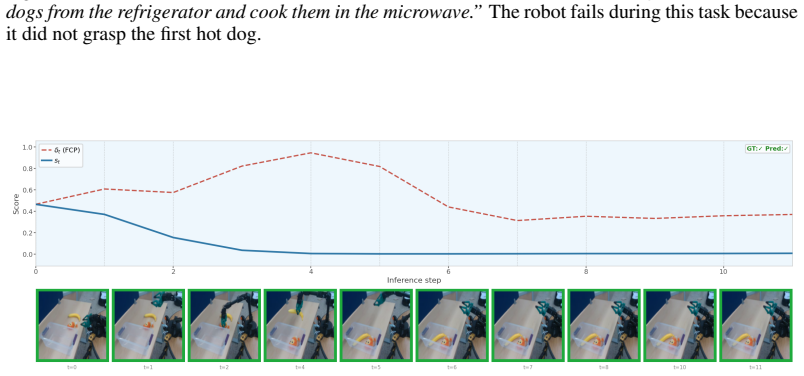

read the original abstract
Long-horizon tasks are common in real-world robotic deployments, yet failure detection for such tasks remains underexplored. Detecting failures in long-horizon robotic tasks is particularly challenging because failure onset is often ambiguous and dense temporal annotations are typically unavailable. We present Foresight, a failure detection framework that monitors manipulation trajectories using latent representations from an action-conditioned world model. Foresight is trained using only final task-level success or failure labels. By leveraging predictive world-model embeddings, our method provides a unified framework for failure detection across different policies. We further use functional conformal prediction (FCP) to calibrate detection thresholds adaptively. We evaluate Foresight with state-of-the-art vision-language-action policies in simulation on LIBERO-Long, ManiSkill-Long, and BEHAVIOR-1K, compare it against state-of-the-artfailure detection methods, and validate it on real robots with three long-horizon tasks on a ReactorX-200 arm and one task on a Franka arm. Our results suggest that action-conditioned world-model embeddings provide a scalable representation for reliable failure monitoring in long-horizon manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Foresight, a failure detection framework for long-horizon robotic manipulation that monitors trajectories using latent representations from an action-conditioned world model. The framework is trained solely on final task-level success/failure labels (no dense temporal annotations) and uses functional conformal prediction (FCP) to calibrate detection thresholds adaptively. It is evaluated in simulation against SOTA failure detection baselines on LIBERO-Long, ManiSkill-Long, and BEHAVIOR-1K using vision-language-action policies, and validated on real robots (ReactorX-200 arm with three tasks; Franka arm with one task). The central claim is that action-conditioned world-model embeddings supply a scalable, policy-agnostic representation for reliable failure monitoring when failure onset is ambiguous.
Significance. If the empirical results and ablations hold, the work would be significant for robotics because it directly tackles an underexplored but practically critical problem: failure detection in long-horizon tasks without expensive dense labels. The unified treatment across policies and the grounding in predictive world-model latents could improve safety and reliability in real deployments. The combination of world-model embeddings with FCP for calibration is a coherent and externally grounded approach that avoids circularity in the stated construction.
minor comments (2)
- [Abstract] Abstract: The abstract states the method, training regime, and evaluation setup but supplies no quantitative results, ablation details, or key performance numbers. Including at least the main comparative metrics (e.g., detection rates or AUC on the simulation benchmarks) would allow readers to assess the strength of the central claim directly from the summary.
- The manuscript should clarify in the methods or experiments section how the world-model latents are extracted at inference time (e.g., which layer or timestep) and whether any additional fine-tuning occurs beyond the terminal-label training described.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work, including the recognition of its significance for long-horizon failure detection without dense labels and the coherent use of world-model latents with functional conformal prediction. We appreciate the recommendation for minor revision and will incorporate any suggested improvements accordingly.
Circularity Check
No significant circularity detected
full rationale
The paper describes a standard pipeline: train an action-conditioned world model, extract latents, and train a failure detector using only terminal success/failure labels, with FCP for calibration. No equations, derivations, or self-citations are shown that reduce the claimed performance or representations to quantities defined by the method itself. The central hypothesis (that these latents carry failure signal) is presented as the claim under test rather than presupposed, and evaluation uses external benchmarks and real-robot tasks. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Action-conditioned world model latents contain information sufficient to detect failure onset from task-level labels only
invented entities (1)
-
Foresight framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies.arXiv preprint arXiv:2503.08558, 2025
arXiv 2025
-
[2]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. Safe: Multitask failure detection for vision-language-action models.arXiv preprint arXiv:2506.09937, 2025
arXiv 2025
-
[3]
Yeh, K.-H
J.-F. Yeh, K.-H. Hung, P.-C. Lo, C.-M. Chung, T.-H. Wu, H.-T. Su, Y .-T. Chen, and W. H. Hsu. Aed: Adaptable error detection for few-shot imitation policy. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[4]
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Man- dlekar, and Y . Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation.arXiv preprint arXiv:2410.00371, 2024
arXiv 2024
-
[5]
N. He, S. Li, Z. Li, Y . Liu, and Y . He. ReDiffuser: Reliable decision-making using a diffuser with confidence estimation. In R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pag...
2024
-
[6]
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471, 2024
Pith/arXiv arXiv 2024
-
[7]
M. Ho, M. F. Ginting, I. R. Ward, A. Reinke, M. J. Kochenderfer, A.-a. Agha-Mohammadi, and S. Omidshafiei. World model failure classification and anomaly detection for autonomous inspection, 2026. URLhttps://arxiv.org/abs/2602.16182
arXiv 2026
-
[8]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. Robert Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self- superv...
Pith/arXiv arXiv 2025
-
[9]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InProceedings of the 31st International Conference on Neu- ral Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
2017
-
[10]
Algorithmic Learning in a Random World
V . V ovk, A. Gammerman, and G. Shafer.Algorithmic Learning in a Random World. Springer, New York, NY , 2005. ISBN 978-0-387-00152-4. doi:10.1007/b106715
-
[11]
Diquigiovanni, M
J. Diquigiovanni, M. Fontana, and S. Vantini. The importance of being a band: Finite-sample exact distribution-free prediction sets for functional data.Statistica Sinica, 35(2):853–871,
-
[12]
doi:10.5705/ss.202022.0087
-
[13]
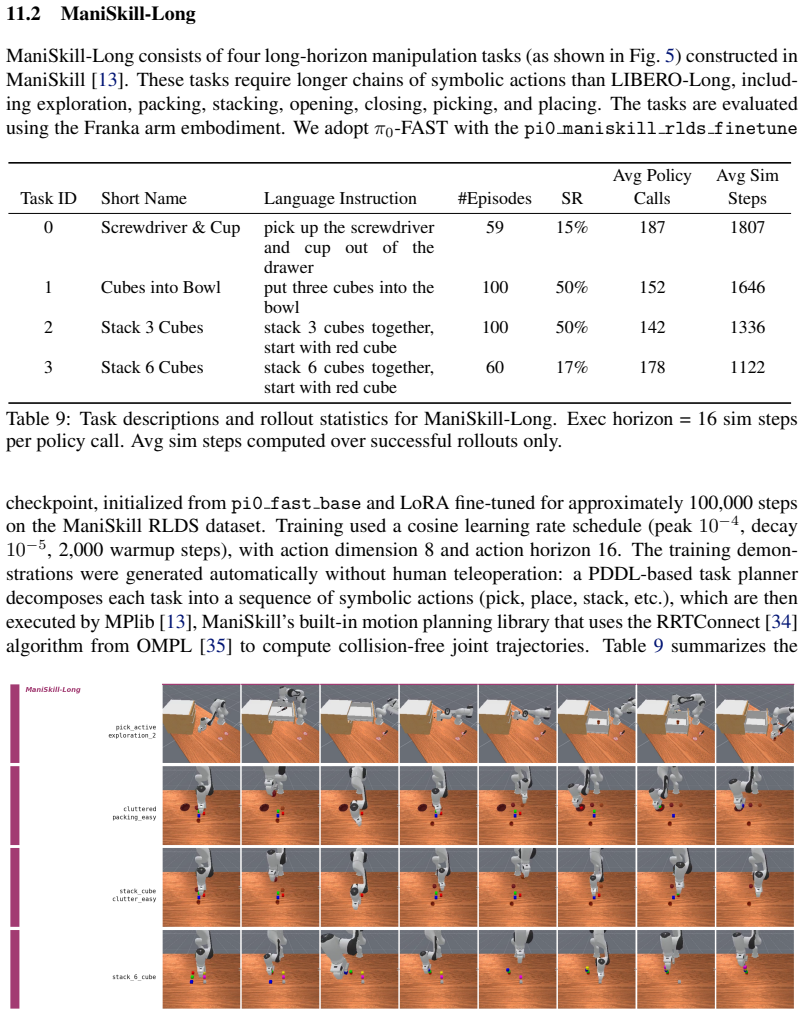
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
Pith/arXiv arXiv 2023
-
[14]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
2025
-
[15]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Ay- din, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon...
Pith/arXiv arXiv 2024
-
[16]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[17]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Ar- actingi, C. Pascal, M. Russi, A. Marafioti, S. Alibert, M. Cord, T. Wolf, and R. Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[18]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[19]
doi:10.48550/arXiv.2410.24164
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164
-
[20]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025. doi:10.48550/arXiv.2501.09747
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.09747 2025
-
[21]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[22]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 10
Pith/arXiv arXiv 2023
-
[23]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
2025
-
[24]
C. Agia, R. Sinha, J. Yang, Z. Cao, R. Antonova, M. Pavone, and J. Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 689–723. PMLR, 2025
2025
-
[25]
Pacaud, R
P. Pacaud, R. Garcia, S. Chen, and C. Schmid. Scaling cross-environment failure reasoning data for vision-language robotic manipulation, 2026. URLhttps://arxiv.org/abs/2512. 01946
2026
-
[26]
P. Yi, Y . Ma, W. Xu, Y . Hao, S. Gan, W. Li, and S. Zhong. Critic in the loop: A tri-system vla framework for robust long-horizon manipulation, 2026. URLhttps://arxiv.org/abs/ 2603.05185
arXiv 2026
-
[27]
E. Zhou, Q. Su, C. Chi, Z. Zhang, Z. Wang, T. Huang, L. Sheng, and H. Wang. Code-as- monitor: Constraint-aware visual programming for reactive and proactive robotic failure de- tection, 2025. URLhttps://arxiv.org/abs/2412.04455
arXiv 2025
-
[28]
C. Grislain, H. Rahimi, O. Sigaud, and M. Chetouani. I-failsense: Towards general robotic failure detection with vision-language models. InProceedings of the International Conference on Robotics and Automation (ICRA), 2026. URLhttps://arxiv.org/abs/2509.16072
arXiv 2026
-
[29]
I. R. Ward, M. Ho, H. Liu, A. Feldman, J. Vincent, L. Kruse, S. Cheong, D. Eddy, M. J. Kochenderfer, and M. Schwager. Foundational world models accurately detect bimanual ma- nipulator failures, 2026. URLhttps://arxiv.org/abs/2603.06987
arXiv 2026
-
[30]
H. Liu, Y . Zhang, V . Betala, E. Zhang, J. Liu, C. Ding, and Y . Zhu. Multi-task interactive robot fleet learning with visual world models, 2024. URLhttps://arxiv.org/abs/2410.22689
arXiv 2024
-
[31]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[32]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[33]
B. Wang, N. Sridhar, C. Feng, M. Van der Merwe, A. Fishman, N. Fazeli, and J. J. Park. This&that: Language-gesture controlled video generation for robot planning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12842–12849. IEEE, 2025
2025
-
[34]
NVIDIA, A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, P. Chattopadhyay, M. Chen, Y . Chen, Y . Chen, S. Cheng, Y . Cui, J. Diamond, Y . Ding, J. Fan, L. Fan, L. Feng, F. Ferroni, S. Fidler, X. Fu, R. Gao, Y . Ge, J. Gu, A. Gupta, S. Gururani, I. El Hanafi, A. Hassani, Z. Hao, J. Huffman, J. Jang, P. Jannaty...
Pith/arXiv arXiv 2025
-
[35]
I. Larchenko, G. Zarin, and A. Karnatak. Task adaptation of vision-language-action model: 1st place solution for the 2025 behavior challenge, 2025. URLhttps://arxiv.org/abs/ 2512.06951
arXiv 2025
-
[36]
J. J. Kuffner and S. M. LaValle. Rrt-connect: An efficient approach to single-query path planning. InProceedings 2000 IEEE International Conference on Robotics and Automation (ICRA), volume 2, pages 995–1001, 2000. doi:10.1109/ROBOT.2000.844730
-
[37]
I. A. S ¸ucan, M. Moll, and L. E. Kavraki. The Open Motion Planning Library.IEEE Robotics & Automation Magazine, 19(4):72–82, December 2012. doi:10.1109/MRA.2012.2205651. https://ompl.kavrakilab.org. 12 Appendix 7 More Implementation Details World-model feature extraction.We use V-JEPA 2-AC [8] as the action-conditioned world- model backbone, initialized ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.