Parallelized contraction of tensor trains or matrix product operators
Pith reviewed 2026-06-26 06:12 UTC · model grok-4.3
The pith
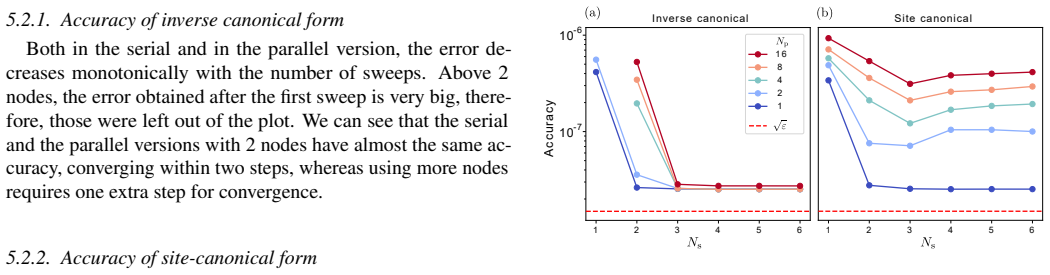
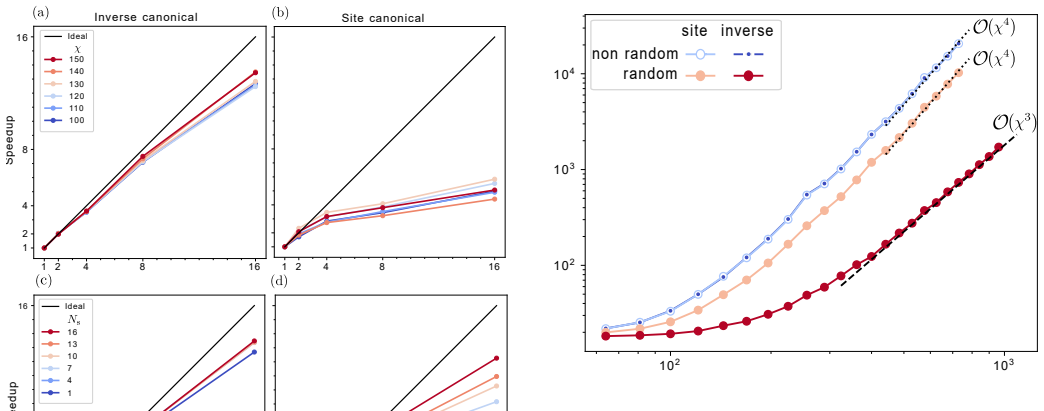
Inverse canonical gauge yields near-ideal parallel speedup for MPO-MPO fit contractions across all sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present two strategies for accelerating the fit algorithm, usable in combination: (1) MPI-based distributed-memory parallelization tailored for MPO-MPO contractions, employing the inverse canonical gauge, which yields near-ideal parallelization speedup across all problem sizes; and (2) randomized projections to reduce the cost of local updates from 2-site to 1-site costs while retaining 2-site accuracy, and to speed up contractions of environment tensors with MPO tensors.
What carries the argument
The inverse canonical gauge choice together with randomized projections inside the fit algorithm for contracting two MPOs.
If this is right
- Near-ideal parallel speedup holds for any problem size when the inverse canonical gauge is used.
- Local update cost drops from two-site to one-site scaling while the final contraction accuracy remains the same.
- Site-canonical gauge still delivers excellent speedup once the problem is large enough to need multiple sweeps.
- Environment-tensor contractions with MPO tensors become cheaper under the same randomized-projection treatment.
Where Pith is reading between the lines
- The same gauge and projection techniques could be tested on contractions involving more than two MPOs or on other tensor-network algorithms that rely on similar sweeps.
- If the one-site randomized version matches two-site accuracy on a wider set of physical operators, existing MPO-based codes could adopt it with only local changes to the update step.
- For very large problems the site-canonical gauge may become preferable once communication overhead dominates over the extra consistency work.
Load-bearing premise
Randomized projections preserve the accuracy of the original 2-site fit algorithm when applied to MPO-MPO contractions.
What would settle it
A side-by-side run on a small exactly solvable MPO-MPO contraction where the error or number of sweeps required with randomized projections exceeds the error obtained by the standard 2-site fit.
Figures











read the original abstract
Tensor Trains (TT), also known as Matrix Product States (MPS) and Matrix Product Operators (MPO), provide a compact and structured representation for high-dimensional data and operators. One of the most expensive manipulations involving tensor trains is the contraction of two MPOs. A popular and accurate method for mitigating this cost is the fit algorithm. However, it is still comparatively costly since it involves 2-site updates. Moreover, the parallelization of the fit algorithm when used for MPO-MPO contractions has received comparatively little attention. In this work, we present two strategies for accelerating the fit algorithm, usable in combination: (1) We use MPI-based distributed-memory parallelization tailored for MPO-MPO contractions, employing one of two MPO gauge choices: (1a) the inverse canonical gauge, which yields near-ideal parallelization speedup across all problem sizes; and (1b) the site-canonical gauge, which avoids the inversion of singular values but requires extra computations to ensure global consistency, thus yielding excellent parallelization speedup only for large problems requiring several sweeps before convergence. (2) We use randomized projections to reduce the cost of local updates from 2-site to 1-site costs while retaining 2-site accuracy, and to speed up contractions of environment tensors with MPO tensors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two strategies to accelerate the fit algorithm for contracting matrix product operators (MPOs): MPI-based distributed parallelization using either the inverse canonical gauge (near-ideal speedup across sizes) or site-canonical gauge (good speedup for large problems), and randomized projections that reduce local 2-site updates to 1-site costs while retaining 2-site accuracy and accelerating environment contractions.
Significance. If the accuracy-retention claim for randomized projections holds with supporting validation, the combined approach would offer practical speedups for MPO-MPO contractions in tensor-network applications; the parallelization strategy builds directly on established gauge choices without introducing new parameters.
major comments (1)
- [Abstract] Abstract: the central claim that randomized projections 'retain 2-site accuracy' for MPO-MPO contractions is asserted without error bounds, convergence rates, or numerical validation on operator contractions; this is load-bearing because the 1-site speedup is only useful if the accuracy guarantee transfers from the MPS-MPS case to the MPO setting with its distinct environment structure.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the need for stronger support of the randomized-projection claim in the MPO-MPO setting. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that randomized projections 'retain 2-site accuracy' for MPO-MPO contractions is asserted without error bounds, convergence rates, or numerical validation on operator contractions; this is load-bearing because the 1-site speedup is only useful if the accuracy guarantee transfers from the MPS-MPS case to the MPO setting with its distinct environment structure.
Authors: We agree that the original manuscript asserted retention of 2-site accuracy for randomized projections without providing explicit error bounds, convergence rates, or numerical validation on MPO-MPO contractions. While the underlying randomized-projection technique is mathematically the same as in the MPS-MPS literature and the environment tensors share the same low-rank structure (differing only by the presence of operator indices), we did not demonstrate transfer of the accuracy guarantee in the operator setting. To address this, the revised manuscript will include (i) a short theoretical paragraph clarifying why the projection error analysis carries over to the MPO environment contractions and (ii) a new numerical subsection with direct comparisons of 2-site versus randomized 1-site updates on representative MPO-MPO problems, reporting relative errors, sweep convergence, and wall-time speedups. These additions will be placed in the results section and referenced from the abstract. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes algorithmic improvements (MPI parallelization with specific MPO gauges and randomized projections for 1-site updates) to the standard fit algorithm for MPO-MPO contractions. These build on established tensor network techniques without any claimed first-principles derivation, uniqueness theorem, or prediction that reduces by construction to fitted parameters or self-citations defined within the paper. Performance claims rest on implementation details and numerical tests rather than self-referential logic, satisfying the criteria for a non-circular methods contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
I. V . Oseledets, Tensor-train decomposition, SIAM Journal on Scientific Computing 33 (5) (2011) 2295–2317. doi: 10.1137/090752286
-
[2]
B. N. Khoromskij, O(d log n)-quantics approximation of n-d tensors in high-dimensional numerical modeling, Springer Nature 34 (2011) 257–280. doi:10.1007/ s00365-011-9131-1. 11
2011
-
[3]
M. K. Ritter, Y . Núñez Fernández, M. Wallerberger, J. von Delft, H. Shinaoka, X. Waintal, Quantics tensor cross in- terpolation for high-resolution parsimonious representa- tions of multivariate functions, Phys. Rev. Lett. 132 (2024) 056501.doi:10.1103/PhysRevLett.132.056501
-
[4]
Available: https://doi.org/10.1016/j.aop.2010.09.012
U. Schollwöck, The density-matrix renormalization group in the age of matrix product states, Annals of Physics 326 (2011) 96–192.doi:10.1016/j.aop.2010.09.012
-
[5]
E. M. Stoudenmire, S. R. White, Minimally entangled typical thermal state algorithms, New Journal of Physics 12 (5) (2010) 055026. doi:10.1088/1367-2630/12/5/ 055026
-
[6]
B.-B. Chen, L. Chen, Z. Chen, W. Li, A. Weichselbaum, Exponential thermal tensor network approach for quantum lattice models, Phys. Rev. X 8 (2018) 031082. doi:10. 1103/PhysRevX.8.031082
2018
-
[7]
Y . Núñez Fernández, M. K. Ritter, M. Jeannin, J.-W. Li, T. Kloss, T. Louvet, S. Terasaki, O. Parcollet, J. von Delft, H. Shinaoka, X. Waintal, Learning tensor net- works with tensor cross interpolation: New algorithms and libraries, SciPost Physics 18 (3) (Mar. 2025). doi: 10.21468/scipostphys.18.3.104
-
[8]
F. Verstraete, J. I. Cirac, Renormalization algorithms for quantum-many body systems in two and higher di- mensions, arXiv: Strongly Correlated Electrons (2004). arXiv:cond-mat/0407066
Pith/arXiv arXiv 2004
-
[9]
Camano, E
C. Camano, E. N. Epperly, J. A. Tropp, Successive ran- domized compression: A randomized algorithm for the compressed mpo-mps product, Quantum 10 (2025) 2022
2025
-
[10]
Z. Meng, Y . Khoo, J. Li, E. M. Stoudenmire, Recursive sketched interpolation: Efficient hadamard products of tensor trains (2026).arXiv:2602.17974
arXiv 2026
-
[11]
M. K. Ritter, Fast elementwise operations on tensor trains with alternating cross interpolation (2026). arXiv:2604. 00037
2026
-
[12]
E. M. Stoudenmire, S. R. White, Real-space parallel den- sity matrix renormalization group, Phys. Rev. B 87 (2013) 155137.doi:10.1103/PhysRevB.87.155137
-
[13]
A. Gleis, J.-W. Li, J. von Delft, Controlled bond expan- sion for density matrix renormalization group ground state search at single-site costs, Phys. Rev. Lett. 130 (2023) 246402.doi:10.1103/PhysRevLett.130.246402
-
[14]
I. P. McCulloch, J. Osborne, Comment on "controlled bond expansion for density matrix renormalization group ground state search at single-site costs" (extended version) (2024). arXiv:2403.00562
arXiv 2024
-
[15]
Efficient Classical Simulation of Slightly Entangled Quantum Computations
G. Vidal, Efficient classical simulation of slightly entangled quantum computations, Phys. Rev. Lett. 91 (2003) 147902. doi:10.1103/PhysRevLett.91.147902
-
[16]
M. B. Hastings, An area law for one-dimensional quantum systems, Journal of Statistical Mechanics: Theory and Experiment 2007 (08) (2007) P08024–P08024. doi:10. 1088/1742-5468/2007/08/p08024
2007
-
[17]
Martinsson, J
P.-G. Martinsson, J. A. Tropp, Randomized nu- merical linear algebra: Foundations and algorithms, Acta Numerica 29 (2020) 403–572. doi:10.1017/ S0962492920000021
2020
-
[18]
N. Halko, P. G. Martinsson, J. A. Tropp, Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions, SIAM Review 53 (2) (2011) 217–288.doi:10.1137/090771806
- [19]
-
[20]
P. Secular, N. Gourianov, M. Lubasch, S. Dolgov, S. R. Clark, D. Jaksch, Parallel time-dependent variational prin- ciple algorithm for matrix product states, Phys. Rev. B 101 (2020) 235123.doi:10.1103/PhysRevB.101.235123
-
[21]
Tensor4all,https://tensor4all.org. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.