EHR-Complex: Benchmarking Medical Agents for Complex Clinical Reasoning
Pith reviewed 2026-06-26 08:20 UTC · model grok-4.3
The pith
Top model reaches only 62.3 percent exact-match accuracy on interactive EHR reasoning benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
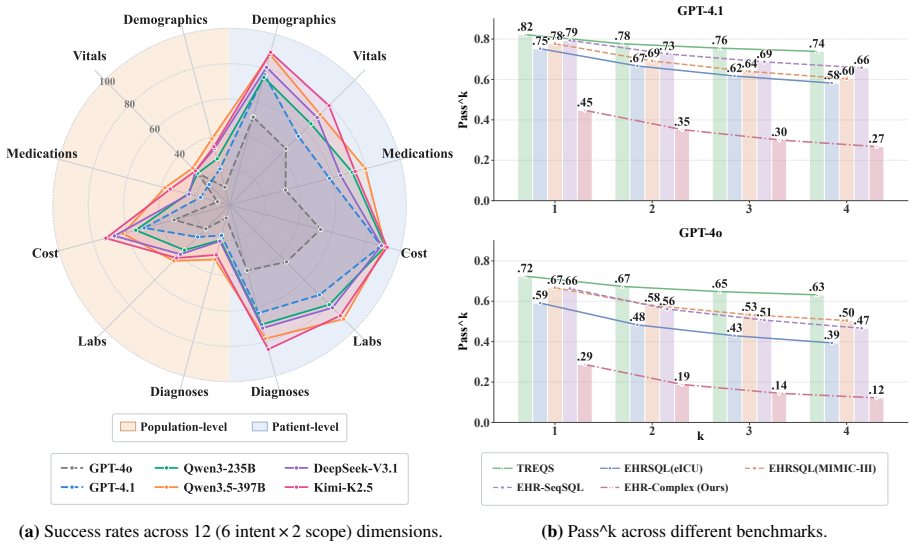
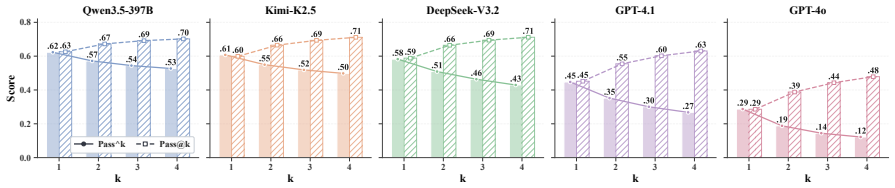
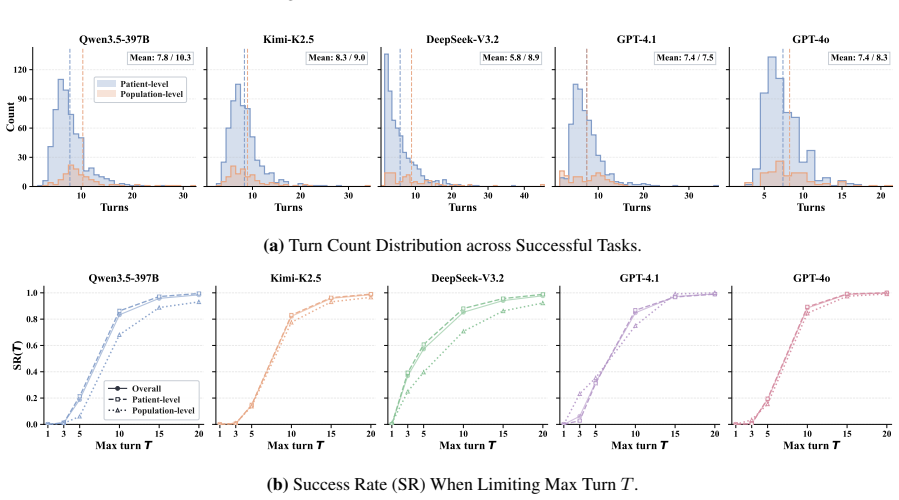
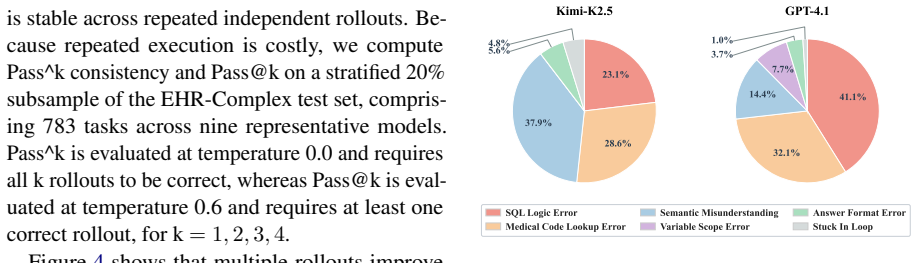
EHR-Complex reveals the clinical difficulty of these EHR reasoning scenarios, with the top-performing model achieving only 62.3% exact-match accuracy. Pass^k consistency drops below 50% for nearly all evaluated models at k=4, exposing broad stochastic fragility. A fine-grained analysis of more than 3,800 failed trajectories reveals three dominant failure modes: SQL logic errors, medical-code lookup failures, and semantic misunderstandings.
What carries the argument
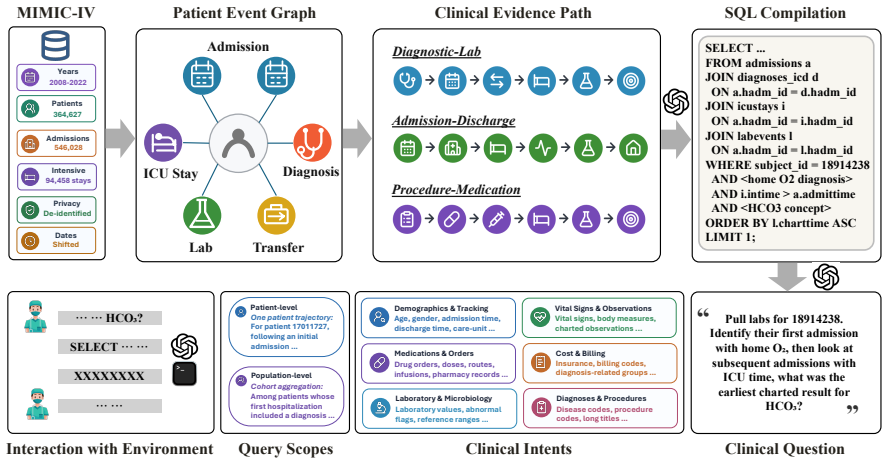
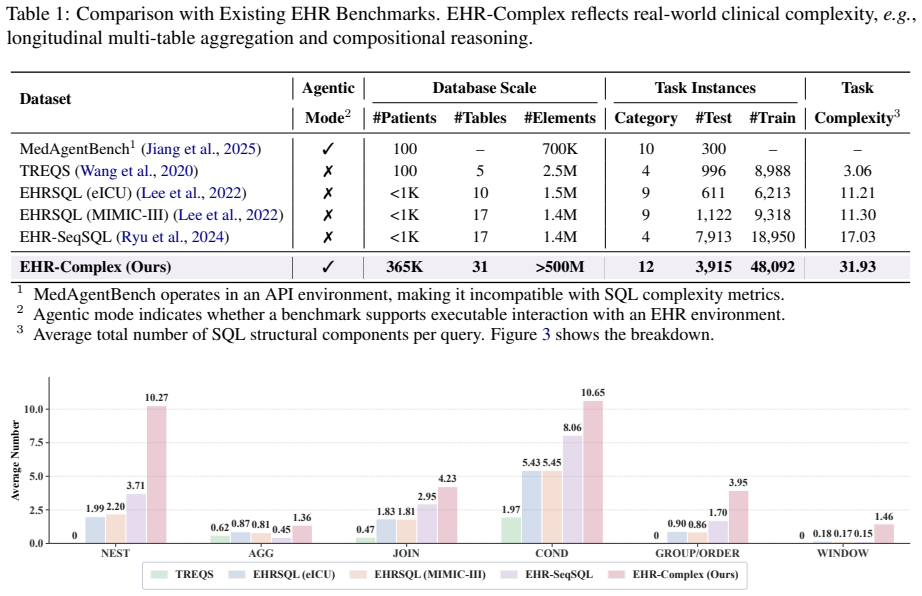
Interactive clinical database reasoning benchmark of 52K tasks on MIMIC-IV, each requiring multi-turn SQL or Python execution against 31 tables with average structural complexity of 31.93 components per query.
If this is right
- Top-performing model achieves only 62.3% exact-match accuracy on the benchmark.
- Pass^k consistency falls below 50% for nearly all models once k reaches 4.
- Three dominant failure modes account for most errors: SQL logic mistakes, medical-code lookup failures, and semantic misunderstandings of the query.
- Existing benchmarks that use static SQL on idealized data do not match the interactive, compositional demands of real EHR work.
Where Pith is reading between the lines
- Targeted improvements in medical terminology handling could reduce one of the three main failure modes.
- Training regimens that emphasize longitudinal multi-table joins might lower the rate of SQL logic errors.
- Adding explicit verification steps inside the agent loop could improve consistency without changing base model accuracy.
Load-bearing premise
The 52K tasks and their six clinical intents accurately capture the complexity and distribution of practical EHR analysis that clinicians and researchers actually perform.
What would settle it
A model achieving above 80 percent exact-match accuracy with pass^4 consistency above 70 percent across the full set of 52K tasks would indicate the benchmark scenarios are less difficult than claimed.
Figures
read the original abstract
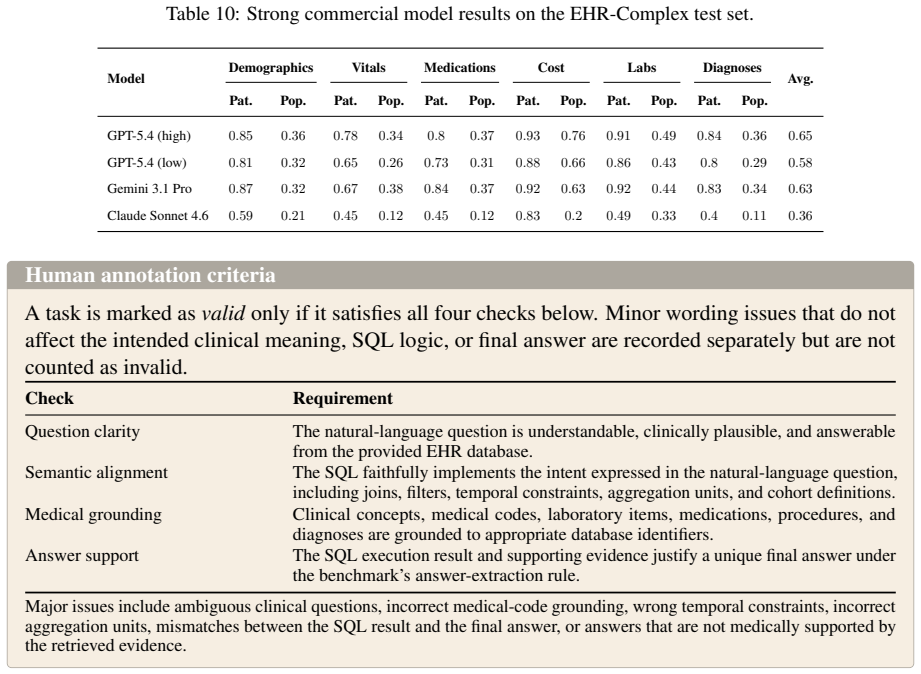
Clinical agents promise to democratize access to electronic health records (EHRs), yet existing benchmarks fail to reflect the complexity of practical EHR analysis, e.g., often operating on idealized, clean EHRs via static SQL generation rather than interactive execution. In this work, we introduce EHR-Complex, a large-scale benchmark designed for interactive clinical database reasoning. Built on the large MIMIC-IV substrate (365K patients, 31 tables, 500M+ records), EHR-Complex comprises about 52K tasks spanning six clinical intents, supporting both patient-level and population-level queries, where each task requires an agent to interact with a sandboxed environment by executing SQL queries or Python code. Notably, EHR-Complex considers the real-world SQL task complexity for longitudinal multi-table aggregation and compositional reasoning, resulting in 31.93 SQL structural components per query on average. Evaluation results on EHR-Complex reveal the clinical difficulty of these EHR reasoning scenarios, with the top-performing model achieving only 62.3% exact-match accuracy. Pass^k consistency drops below 50% for nearly all evaluated models at k=4, exposing broad stochastic fragility. A fine-grained analysis of more than 3,800 failed trajectories for representative LLMs reveals three dominant failure modes: SQL logic errors, medical-code lookup failures, and semantic misunderstandings. EHR-Complex provides a rigorous testbed for clinical agents and highlights remaining gaps in robust reasoning for large-scale EHR analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EHR-Complex, a benchmark of ~52K interactive tasks built on MIMIC-IV (365K patients, 31 tables) spanning six clinical intents. Each task requires agents to execute SQL or Python in a sandboxed environment, with average query complexity of 31.93 structural components. Evaluation of LLMs shows a top exact-match accuracy of 62.3%, Pass^k consistency below 50% at k=4, and three dominant failure modes (SQL logic errors, medical-code lookup failures, semantic misunderstandings) identified from >3,800 trajectories.
Significance. If the tasks are representative of real clinical workflows, the benchmark would provide a valuable large-scale testbed exposing concrete gaps in robust EHR reasoning for agents. The scale, concrete performance numbers, and failure-mode breakdown from thousands of trajectories are strengths; the work ships direct measurements against held-out tasks rather than fitted parameters.
major comments (1)
- [benchmark design] Abstract (paragraph on benchmark design): the central claim that results 'reveal the clinical difficulty' of EHR reasoning scenarios rests on the assumption that the 52K tasks accurately capture the complexity and distribution of practical EHR analysis. The manuscript provides no clinician validation, inter-annotator agreement metrics, or comparison against logged real-world query distributions from MIMIC-IV or clinical logs; without this, the 62.3% exact-match figure and failure-mode analysis could reflect benchmark construction artifacts rather than genuine clinical gaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark design and validation. We address the single major comment point-by-point below and will revise the manuscript to improve transparency.
read point-by-point responses
-
Referee: [benchmark design] Abstract (paragraph on benchmark design): the central claim that results 'reveal the clinical difficulty' of EHR reasoning scenarios rests on the assumption that the 52K tasks accurately capture the complexity and distribution of practical EHR analysis. The manuscript provides no clinician validation, inter-annotator agreement metrics, or comparison against logged real-world query distributions from MIMIC-IV or clinical logs; without this, the 62.3% exact-match figure and failure-mode analysis could reflect benchmark construction artifacts rather than genuine clinical gaps.
Authors: We agree that the absence of clinician validation, inter-annotator agreement, or direct comparison to real-world query logs is a limitation that could affect claims about representativeness. The 52K tasks were generated programmatically from six clinical intents using templates over the MIMIC-IV schema (365K patients, 31 tables) to produce queries with measured structural complexity averaging 31.93 components; the intents target common patient- and population-level analyses. However, the manuscript does not describe clinician review or log-based calibration. In revision we will (1) expand the methods section with a detailed account of intent selection and template construction, (2) report objective complexity statistics as the primary evidence of difficulty, and (3) add an explicit limitations paragraph acknowledging the lack of clinician validation and real-log comparison. These changes will qualify the central claim without altering the reported performance numbers or failure-mode analysis. revision: partial
Circularity Check
No circularity: benchmark paper reports direct empirical measurements on held-out tasks
full rationale
The paper introduces EHR-Complex as a constructed benchmark on MIMIC-IV and reports model performance (e.g., 62.3% exact-match) as measured outcomes against those tasks. There are no derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce claims to the paper's own inputs by construction. The central results are external evaluations, not self-referential quantities. This matches the default expectation for benchmark papers with no derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 52K tasks and six clinical intents accurately reflect the distribution and difficulty of practical EHR analysis performed by clinicians and researchers.
Reference graph
Works this paper leans on
-
[1]
Anthropic . 2026. https://www.anthropic.com/news/claude-sonnet-4-6 Introducing Claude Sonnet 4.6
2026
-
[2]
DeepSeek-AI . 2025. https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp Deepseek-v3.2-exp: Boosting long-context efficiency with deepseek sparse attention
2025
-
[3]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. Workarena: How capable are web agents at solving common knowledge work tasks? In International Conference on Machine Learning, pages 11642--11662. PMLR
2024
-
[4]
Google . 2026. https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ Gemini 3.1 Pro : A smarter model for your most complex tasks
2026
-
[5]
Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. 2024. Mlagentbench: Evaluating language agents on machine learning experimentation. In International Conference on Machine Learning, pages 20271--20309. PMLR
2024
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. 2025. Medagentbench: a virtual ehr environment to benchmark medical llm agents. Nejm Ai, 2(9):AIdbp2500144
2025
-
[8]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, volume 2024, pages 54107--54157
2024
-
[9]
Koray Kavukcuoglu. 2025. https://blog.google/innovation-and-ai/models-and-research/google-deepmind/gemini-model-thinking-updates-march-2025/ Gemini 2.5: Our newest gemini model with thinking
2025
-
[10]
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W Safranek, Abid A Anwar, Andrew Zhang, and 1 others. 2024. Medcalc-bench: Evaluating large language models for medical calculations. Advances in Neural Information Processing Systems, 37:84730--84745
2024
- [11]
-
[12]
Gyubok Lee, Hyeonji Hwang, Seongsu Bae, Yeonsu Kwon, Woncheol Shin, Seongjun Yang, Minjoon Seo, Jong-Yeup Kim, and Edward Choi. 2022. Ehrsql: A practical text-to-sql benchmark for electronic health records. Advances in Neural Information Processing Systems, 35:15589--15601
2022
-
[13]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
OpenAI. 2025. https://openai.com/index/gpt-4-1/ Introducing GPT -4.1 in the API
2025
-
[15]
OpenAI . 2026. https://openai.com/index/introducing-gpt-5-4/ Introducing GPT-5.4
2026
-
[16]
Qwen Team . 2025. https://qwenlm.github.io/blog/qwen3/ Qwen3: Think deeper, act faster
2025
-
[17]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5 : Towards native multimodal agents
2026
-
[18]
Preethi Raghavan, Jennifer J Liang, Diwakar Mahajan, Rachita Chandra, and Peter Szolovits. 2021. emrkbqa: A clinical knowledge-base question answering dataset. In Proceedings of the 20th workshop on biomedical language processing, pages 64--73
2021
-
[19]
Jaehee Ryu, Seonhee Cho, Gyubok Lee, and Edward Choi. 2024. Ehr-seqsql: A sequential text-to-sql dataset for interactively exploring electronic health records. In Findings of the association for computational linguistics: aCL 2024, pages 16388--16407
2024
-
[20]
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce C Ho, Carl Yang, and May Dongmei Wang. 2024. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22315--22339
2024
-
[21]
Ali Soroush, Benjamin S Glicksberg, Eyal Zimlichman, Yiftach Barash, Robert Freeman, Alexander W Charney, Girish N Nadkarni, and Eyal Klang. 2024. Large language models are poor medical coders—benchmarking of medical code querying. Nejm Ai, 1(5):AIdbp2300040
2024
-
[22]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, and 1 others. 2026. Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Ping Wang, Tian Shi, and Chandan K Reddy. 2020. Text-to-sql generation for question answering on electronic medical records. In Proceedings of The Web Conference 2020, pages 350--361
2020
-
[24]
Ran Xu, Yuchen Zhuang, Yishan Zhong, Yue Yu, Xiangru Tang, Hang Wu, May Dongmei Wang, Peifeng Ruan, Donghan Yang, Tao Wang, and 1 others. 2025. Medagentgym: Training llm agents for code-based medical reasoning at scale. In The Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance
2025
-
[25]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. -bench : A benchmark for Tool-Agent-User interaction in real-world domains. arXiv preprint arXiv:2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, and 1 others. 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 3911--3921
2018
-
[27]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, and 1 others. 2024. Webarena: A realistic web environment for building autonomous agents. In International Conference on Learning Representations, volume 2024, pages 15585--15606
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.