Flowing With Purpose: Latent Action Guided Flow Matching Policies For Robotic Manipulation
Pith reviewed 2026-06-26 08:00 UTC · model grok-4.3
The pith
Replacing fixed Gaussian sources with adaptive priors from latent action models improves robotic flow matching policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
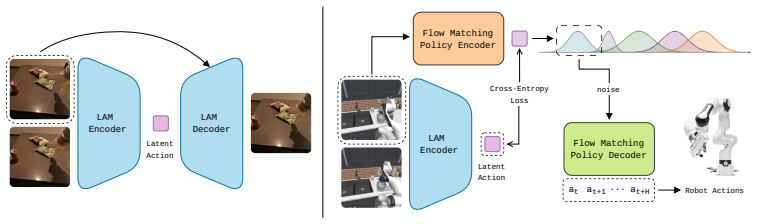
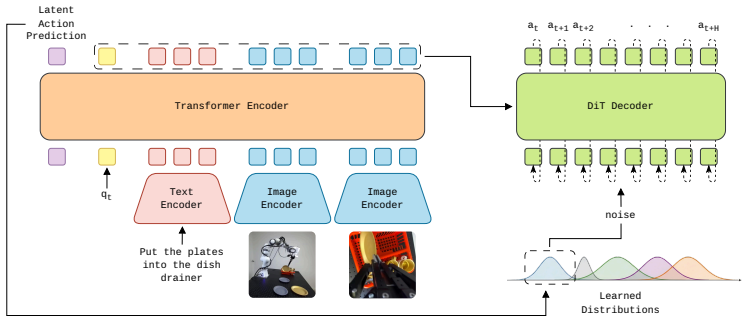
By grounding an adaptive library of learned prior distributions with a latent action model that maps observations to discrete motion primitives, LAFM provides structurally aligned initializations for the flow matching process, producing shorter and less entangled transport trajectories that accommodate the heteroscedasticity in human demonstrations.
What carries the argument
The latent action model that selects specialized base distributions from an adaptive library to initialize flow matching denoising.
Load-bearing premise
The globally fixed isotropic source distribution is the main cause of entangled vector fields in robotic flow matching, and switching to latent-action-selected adaptive priors will resolve this without introducing training instabilities.
What would settle it
A direct comparison of learned vector field entanglement metrics or transport path lengths between standard flow matching and LAFM on the same robotic tasks, where no improvement would falsify the benefit of the adaptive initialization.
Figures
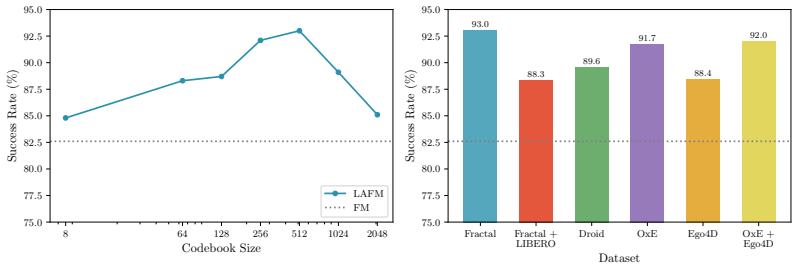


read the original abstract
Flow matching has recently become a new standard for behavior cloning in robotic manipulation. However, state-of-the-art flow matching policies suffer from a systematic structural mismatch: they rely on a globally fixed isotropic source distribution despite the strongly fragmented and heteroscedastic structure of robotic action spaces. This agnostic initialization forces the model to learn highly entangled vector fields, bottlenecking training efficiency and limiting overall policy performance. To address this limitation, we introduce Latent Action Guided Flow Matching (LAFM), a novel framework that replaces the monolithic Gaussian with an adaptive library of learned prior distributions. By grounding these distributions using a latent action model, LAFM maps current observations to discrete motion primitives, selecting a specialized base distribution that provides an informed, structurally aligned initialization for the denoising process. This dynamic adaptivity naturally accommodates heteroscedasticity in human demonstrations and makes transport trajectories shorter and less entangled. Empirically, LAFM substantially outperforms standard flow matching formulations, increasing task success rates by 23.4% in real-world robotic deployments and by 10.4% on the LIBERO-90 benchmark. Furthermore, we demonstrate that LAFM achieves state-of-the-art results, surpassing massively pre-trained vision-language-action models while utilizing significantly smaller architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Action Guided Flow Matching (LAFM) to address a claimed structural limitation in flow matching policies for robotic manipulation. Standard methods use a fixed isotropic Gaussian source distribution, which the authors argue forces entangled vector fields in heteroscedastic action spaces. LAFM replaces this with an adaptive library of learned priors selected via a latent action model that maps observations to discrete motion primitives. The paper reports empirical gains of 23.4% task success in real-world deployments and 10.4% on LIBERO-90, along with state-of-the-art results using smaller architectures than massively pre-trained vision-language-action models.
Significance. If the performance claims hold under rigorous controls, the work could meaningfully advance flow-matching approaches in robotics by providing a mechanism for structurally aligned initialization that accommodates action-space heterogeneity. The idea of grounding priors in latent motion primitives is a plausible direction for improving sample efficiency and reducing training entanglement, and the reported ability to outperform larger models with compact architectures would be a notable practical contribution if the comparisons are equitable.
major comments (2)
- [Abstract] Abstract: The central performance claims (23.4% real-world and 10.4% LIBERO-90 gains, plus SOTA over larger VLA models) are presented without any description of experimental protocol, baselines, number of trials, statistical tests, or ablation studies. This absence makes the empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion.
- [Abstract] Abstract: No technical details are supplied on the latent action model architecture, its training objective, how the library of priors is constructed or selected, or how the selection integrates into the flow-matching ODE. Without these elements it is impossible to assess whether the adaptive priors actually shorten trajectories or avoid new instabilities, undermining evaluation of the core methodological claim.
minor comments (1)
- [Abstract] Abstract: The phrase 'massively pre-trained vision-language-action models' and 'significantly smaller architectures' are used without naming the specific models, parameter counts, or training regimes, which weakens the interpretability of the size-performance comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. The two major points both concern the level of detail provided in the abstract. We address them point-by-point below, noting that abstracts are intentionally concise summaries while the full experimental and methodological details appear in the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (23.4% real-world and 10.4% LIBERO-90 gains, plus SOTA over larger VLA models) are presented without any description of experimental protocol, baselines, number of trials, statistical tests, or ablation studies. This absence makes the empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion.
Authors: We agree that the abstract itself contains no experimental protocol, baselines, trial counts, statistical tests, or ablations; this is standard for abstracts due to length limits. The full manuscript supplies these details in Section 4 (Experiments), including the real-world deployment protocol (number of trials per task, success criteria), LIBERO-90 evaluation setup, baseline implementations (standard flow matching and large VLA models), statistical reporting, and ablation studies on the latent action model. The performance numbers are therefore supported by the complete experimental record rather than the abstract alone. We do not believe a change to the abstract is required for the claims to be evaluable. revision: no
-
Referee: [Abstract] Abstract: No technical details are supplied on the latent action model architecture, its training objective, how the library of priors is constructed or selected, or how the selection integrates into the flow-matching ODE. Without these elements it is impossible to assess whether the adaptive priors actually shorten trajectories or avoid new instabilities, undermining evaluation of the core methodological claim.
Authors: The abstract likewise omits these architectural and integration specifics for brevity. Section 3 (Method) fully specifies the latent action model (architecture, training objective for learning discrete motion primitives), the construction and selection mechanism for the library of priors, and its integration into the flow-matching ODE (observation-conditioned selection of the base distribution). The text explains how this choice produces shorter, less entangled transport trajectories. The core methodological claim can therefore be assessed from the full manuscript; we see no need to expand the abstract. revision: no
Circularity Check
No circularity detected; empirical method with independent performance claims
full rationale
The provided abstract and context describe an empirical framework (LAFM) that replaces a fixed isotropic Gaussian source in flow matching with adaptive priors selected via a latent action model. No equations, derivation steps, or self-citations appear in the text. The central claims are performance improvements measured on benchmarks and real-world tasks, which do not reduce to fitted inputs by construction or rely on self-referential definitions. The motivation (heteroscedasticity mismatch) is stated as an assumption but is not used to derive results tautologically. This is a standard empirical contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the latent action model
axioms (1)
- domain assumption Robotic action spaces exhibit strongly fragmented and heteroscedastic structure that a single isotropic Gaussian cannot capture efficiently.
invented entities (1)
-
adaptive library of learned prior distributions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi et al. “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion”. In: Proceedings of Robotics: Science and Systems. Daegu, Republic of Korea, July 2023.DOI: 10.15607/RSS.2023.XIX.026(cit. on pp. 1, 6–8)
-
[2]
π0: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black et al. π0: A Vision-Language-Action Flow Model for General Robot Control
-
[3]
arXiv: 2410.24164 [cs.LG].URL: https://arxiv.org/abs/2410.24164 (cit. on pp. 1, 3, 6, 7, 9, 16, 17)
-
[4]
NVIDIA et al.GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. 2025. arXiv: 2503.14734 [cs.RO].URL: https://arxiv.org/abs/2503.14734 (cit. on pp. 1, 9)
Pith/arXiv arXiv 2025
-
[5]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. “Denoising Diffusion Probabilistic Models”. In: Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. V ol. 33. Curran Associates, Inc., 2020, pp. 6840–6851.URL: https://proceedings.neurips.cc/ paper_files/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf (cit. on p. 1)
2020
-
[6]
Deep Unsupervised Learning using Nonequilibrium Thermody- namics
Jascha Sohl-Dickstein et al. “Deep Unsupervised Learning using Nonequilibrium Thermody- namics”. In:Proceedings of the 32nd International Conference on Machine Learning. Ed. by Francis Bach and David Blei. V ol. 37. Proceedings of Machine Learning Research. Lille, France: PMLR, July 2015, pp. 2256–2265.URL: https://proceedings.mlr.press/v37/ sohl-dickstei...
2015
-
[7]
Flow Matching for Generative Modeling
Yaron Lipman et al. “Flow Matching for Generative Modeling”. In:The Eleventh International Conference on Learning Representations. 2023.URL: https://openreview.net/forum? id=PqvMRDCJT9t(cit. on pp. 1, 3)
2023
-
[8]
Qiang Liu.Rectified Flow: A Marginal Preserving Approach to Optimal Transport. 2022. arXiv: 2209.14577 [stat.ML] .URL: https://arxiv.org/abs/2209.14577 (cit. on pp. 1, 3)
Pith/arXiv arXiv 2022
-
[9]
Genie: Generative Interactive Environments
Jake Bruce et al. “Genie: Generative Interactive Environments”. In:Proceedings of the 41st International Conference on Machine Learning. Ed. by Ruslan Salakhutdinov et al. V ol. 235. Proceedings of Machine Learning Research. PMLR, 21–27 Jul 2024, pp. 4603–4623.URL: https://proceedings.mlr.press/v235/bruce24a.html(cit. on pp. 2, 9, 14)
2024
-
[10]
Latent Action Pretraining from Videos
Seonghyeon Ye et al. “Latent Action Pretraining from Videos”. In:The Thirteenth International Conference on Learning Representations. 2025.URL: https://openreview.net/forum? id=VYOe2eBQeh(cit. on pp. 2, 9)
2025
-
[11]
Attention is All you Need
Ashish Vaswani et al. “Attention is All you Need”. In:Advances in Neural Informa- tion Processing Systems. Ed. by I. Guyon et al. V ol. 30. Curran Associates, Inc., 2017. URL: https : / / proceedings . neurips . cc / paper _ files / paper / 2017 / file / 3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf(cit. on p. 4)
2017
-
[12]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. In:Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Ed. by Jill Burstein, Christy Doran, and Thamar Solorio. Minneapolis, Mi...
2019
-
[13]
William Peebles and Saining Xie. “ Scalable Diffusion Models with Transformers ”. In:2023 IEEE/CVF International Conference on Computer Vision (ICCV). Los Alamitos, CA, USA: IEEE Computer Society, Oct. 2023, pp. 4172–4182.DOI: 10.1109/ICCV51070.2023.00387. URL: https://doi.ieeecomputersociety.org/10.1109/ICCV51070.2023.00387 (cit. on p. 5)
-
[14]
Octo: An Open-Source Generalist Robot Policy
Dibya Ghosh et al. “Octo: An Open-Source Generalist Robot Policy”. In:Proceedings of Robotics: Science and Systems. Delft, Netherlands, July 2024.DOI: 10.15607/RSS.2024. XX.090(cit. on pp. 6, 7, 9)
-
[15]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim et al. “OpenVLA: An Open-Source Vision-Language-Action Model”. In:8th Annual Conference on Robot Learning. 2024.URL: https://openreview.net/forum?id= ZMnD6QZAE6(cit. on pp. 6, 7). 10
2024
-
[16]
Mustafa Shukor et al.SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. 2025. arXiv: 2506 . 01844 [cs.LG].URL: https : / / arxiv . org / abs / 2506 . 01844(cit. on pp. 6, 7)
2025
-
[17]
Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu et al. “Learning to Act Anywhere with Task-centric Latent Actions”. In:Proceed- ings of Robotics: Science and Systems. LosAngeles, CA, USA, June 2025.DOI: 10.15607/ RSS.2025.XXI.014(cit. on pp. 6, 7, 9, 14, 15)
2025
-
[18]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao et al. “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware”. In:Proceedings of Robotics: Science and Systems. Daegu, Republic of Korea, July 2023.DOI: 10.15607/RSS.2023.XIX.016(cit. on pp. 6, 7, 16)
-
[19]
Behavior Generation with Latent Actions
Seungjae Lee et al. “Behavior Generation with Latent Actions”. In:Proceedings of the 41st International Conference on Machine Learning. Ed. by Ruslan Salakhutdinov et al. V ol. 235. Proceedings of Machine Learning Research. PMLR, 21–27 Jul 2024, pp. 26991–27008.URL: https://proceedings.mlr.press/v235/lee24y.html(cit. on pp. 6, 7)
2024
-
[20]
QueST: Self-Supervised Skill Abstractions for Learning Continuous Control
Atharva Mete et al. “QueST: Self-Supervised Skill Abstractions for Learning Continuous Control”. In:Advances in Neural Information Processing Systems. Ed. by A. Globerson et al. V ol. 37. Curran Associates, Inc., 2024, pp. 4062–4089.DOI: 10 . 52202 / 079017 - 0133.URL: https://proceedings.neurips.cc/paper_files/paper/2024/file/ 076c3e48fa502c660902105965f...
2024
-
[21]
Philipp Wu et al. “GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators”. In:2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2024, pp. 12156–12163.DOI: 10.1109/IROS58592.2024.10801581 (cit. on p. 6)
-
[22]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
Andrew Wagenmaker et al. “Steering Your Diffusion Policy with Latent Space Reinforcement Learning”. In:9th Annual Conference on Robot Learning. 2025.URL: https://openreview. net/forum?id=jU7AbGq3se(cit. on p. 9)
2025
-
[23]
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Avi Singh et al. “Parrot: Data-Driven Behavioral Priors for Reinforcement Learning”. In: International Conference on Learning Representations. 2021.URL: https://openreview. net/forum?id=Ysuv-WOFeKR(cit. on p. 9)
2021
-
[24]
Imitating Latent Policies from Observation
Ashley Edwards et al. “Imitating Latent Policies from Observation”. In:Proceedings of the 36th International Conference on Machine Learning. Ed. by Kamalika Chaudhuri and Ruslan Salakhutdinov. V ol. 97. Proceedings of Machine Learning Research. PMLR, Sept. 2019, pp. 1755–1763.URL: https://proceedings.mlr.press/v97/edwards19a.html (cit. on p. 9)
2019
-
[25]
Learning to Act without Actions
Dominik Schmidt and Minqi Jiang. “Learning to Act without Actions”. In:International Conference on Learning Representations. Ed. by B. Kim et al. V ol. 2024. 2024, pp. 9379– 9395.URL: https : / / proceedings . iclr . cc / paper _ files / paper / 2024 / file / 27985d21f0b751b933d675930aa25022-Paper-Conference.pdf(cit. on p. 9)
2024
-
[26]
Moto: Latent Motion Token as the Bridging Language for Learning Robot Manipulation from Videos
Yi Chen et al. “Moto: Latent Motion Token as the Bridging Language for Learning Robot Manipulation from Videos”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Oct. 2025, pp. 19752–19763 (cit. on p. 9)
2025
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. “Decoupled Weight Decay Regularization”. In:International Conference on Learning Representations. 2019.URL: https://openreview.net/forum? id=Bkg6RiCqY7(cit. on pp. 14, 17)
2019
-
[28]
Mingxing Xu et al.Spatial-Temporal Transformer Networks for Traffic Flow Forecasting. 2021. arXiv: 2001.02908 [eess.SP] .URL: https://arxiv.org/abs/2001.02908 (cit. on p. 14)
arXiv 2021
-
[29]
NSVQ: Noise Substitution in Vector Quantiza- tion for Machine Learning
Mohammad Hassan Vali and Tom Bäckström. “NSVQ: Noise Substitution in Vector Quantiza- tion for Machine Learning”. In:IEEE Access10 (2022), pp. 13598–13610.DOI: 10.1109/ ACCESS.2022.3147670(cit. on p. 14)
arXiv 2022
-
[30]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan et al. “RT-1: Robotics Transformer for Real-World Control at Scale”. In: Proceedings of Robotics: Science and Systems. Daegu, Republic of Korea, July 2023.DOI: 10.15607/RSS.2023.XIX.025(cit. on pp. 14, 15)
-
[31]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky et al. “DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset”. In:Proceedings of Robotics: Science and Systems. Delft, Netherlands, July 2024.DOI: 10. 15607/RSS.2024.XX.120(cit. on p. 15). 11
2024
-
[32]
Abby O’Neill et al. “Open X-Embodiment: Robotic Learning Datasets and RT-X Models : Open X-Embodiment Collaboration”. In:2024 IEEE International Conference on Robotics and Automation (ICRA). 2024, pp. 6892–6903.DOI: 10.1109/ICRA57147.2024.10611477 (cit. on p. 15)
-
[33]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman et al. “Ego4d: Around the world in 3,000 hours of egocentric video”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, pp. 18995–19012 (cit. on p. 15)
2022
-
[34]
2024 (cit
Remi Cadene et al.LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch.https://github.com/huggingface/lerobot. 2024 (cit. on p. 16)
2024
-
[35]
Benjamin Warner et al. “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”. In:Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ed. by Wanxiang Che et al. Vienna, Austria: Association for Computational Linguis...
-
[36]
Deep Residual Learning for Image Recognition
Kaiming He et al. “Deep Residual Learning for Image Recognition”. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 2016 (cit. on p. 16)
2016
-
[37]
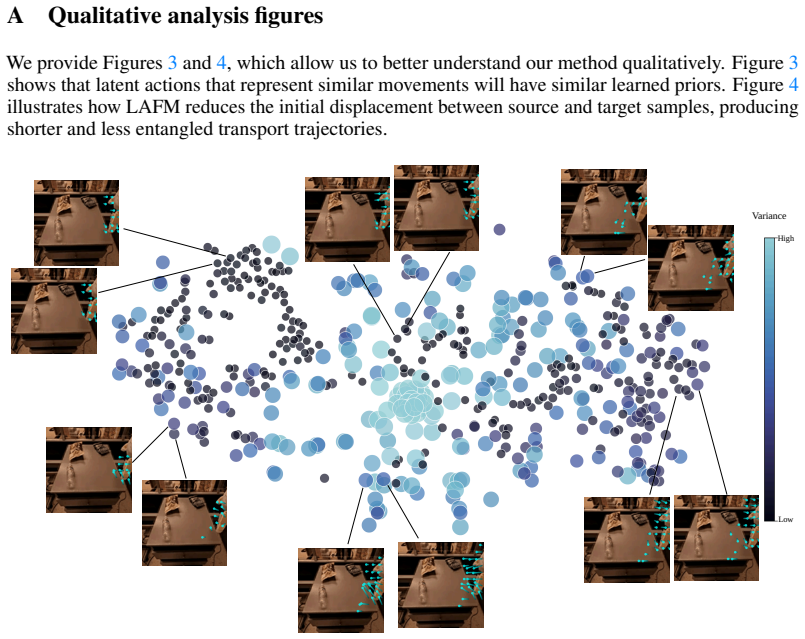
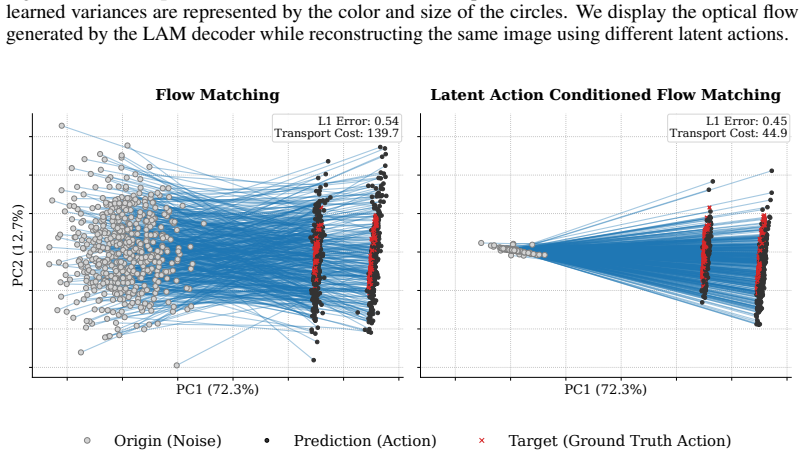
Jia Deng et al. “ImageNet: A large-scale hierarchical image database”. In:2009 IEEE Confer- ence on Computer Vision and Pattern Recognition. 2009, pp. 248–255.DOI: 10.1109/CVPR. 2009.5206848(cit. on p. 16). 12 A Qualitative analysis figures We provide Figures 3 and 4, which allow us to better understand our method qualitatively. Figure 3 shows that latent...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.