Hallucinations in Organization-backed AI advisors: Evidence about Skepticism, Verification, and Reliance in Goal-Directed Use
Pith reviewed 2026-06-26 07:13 UTC · model grok-4.3
The pith
Review of AI advisor studies finds that warnings about hallucinations have the weakest effects on user scrutiny while most research only tracks reliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across studies examining product search, medical decision-making, content generation, and chatbot-assisted tasks, several patterns emerge. Nearly all studies measure reliance, while variables such as user skepticism and verification of the information are more often targeted by an intervention than measured directly. The cues used to prompt scrutiny of the AI response are predominantly related to the AI output, such as source citations, and the most deployable of these AI output interventions for organizations (general and specific warnings about the risk of hallucinations) show the weakest and most mixed effects in the studies reviewed. Although the existing literature posits that users may
What carries the argument
The separation of skepticism of AI information, verification success, and reliance on the information as distinct constructs in goal-directed interactions with organization-backed AI advisors.
If this is right
- Measuring skepticism and verification separately from reliance can clarify what current evidence shows versus only implies.
- AI-output interventions such as general and specific warnings produce the weakest effects and may need to be replaced or strengthened.
- Content category has been hypothesized to affect scrutiny but remains untested and should be varied in future experiments.
Where Pith is reading between the lines
- Organizations could test interfaces that make verification steps easier rather than relying mainly on risk warnings.
- If verification success stays low even when users are skeptical, training on effective checking methods may be needed alongside interface changes.
- Domain differences such as medical versus consumer advice could be compared directly to test whether scrutiny rates vary by content type.
Load-bearing premise
That the reviewed studies form a representative sample of the literature and that skepticism, verification success, and reliance can be cleanly separated and measured without substantial overlap or measurement error.
What would settle it
A new study that directly measures skepticism and verification success in addition to reliance and finds they overlap so much that the three cannot be distinguished in practice.
Figures
read the original abstract
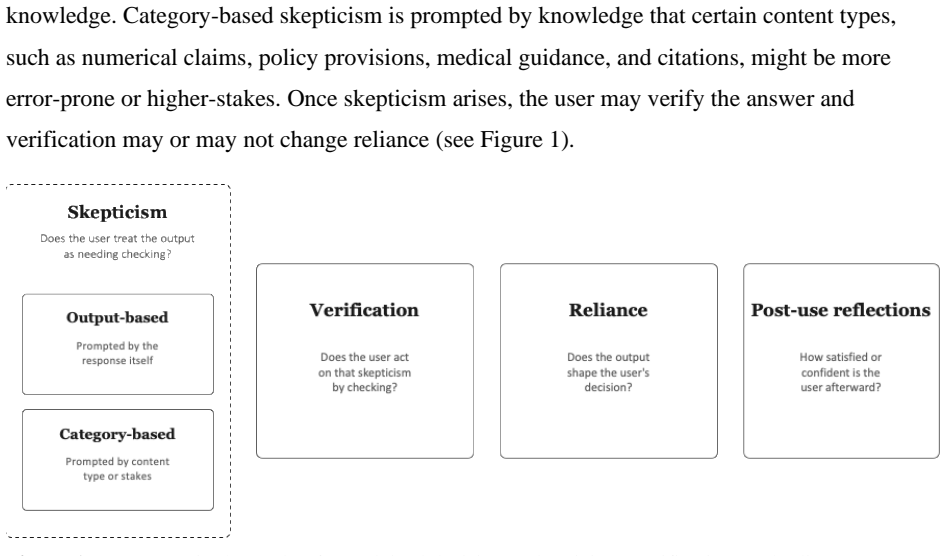
Generative AI systems are increasingly used by organizations to deliver information to consumers, patients, students, employees, and citizens. These systems can hallucinate, producing plausible but inaccurate responses. A central question for AI-advised decisions is therefore not only whether users rely on inaccurate information, but whether they recognize that a response may require verification. To answer this question, we review emerging empirical evidence relevant to hallucination detection in goal-directed interactions, with a focus on organization-backed AI advisors. We distinguish three constructs that existing studies often conflate: whether users are skeptical of information presented, whether they check it, whether checking succeeds, and whether the result of user verification affects reliance on the information. Across studies examining product search, medical decision-making, content generation, and chatbot-assisted tasks, several patterns emerge. Nearly all studies measure reliance, while variables such as user skepticism and verification of the information are more often targeted by an intervention than measured directly. The cues used to prompt scrutiny of the AI response are predominantly related to the AI output, such as source citations, and the most deployable of these AI output interventions for organizations (general and specific warnings about the risk of hallucinations) show the weakest and most mixed effects in the studies reviewed. Although the existing literature posits that users may be more likely to scrutinize responses related to particular areas of content, no studies varied the content category, leaving this question open for further research. In future research, measuring skepticism and verification separately from reliance may clarify what current evidence shows, what it only implies, and which questions require further exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews emerging empirical evidence on hallucination detection in goal-directed interactions with organization-backed AI advisors. It distinguishes three constructs often conflated in prior work—user skepticism of AI responses, verification of the information, and reliance on it—and synthesizes patterns across studies in product search, medical decision-making, content generation, and chatbot tasks. Key findings include that nearly all studies measure reliance while skepticism and verification are more often targeted by interventions than directly measured, that AI-output interventions (especially general/specific warnings) show the weakest and most mixed effects, and that no studies varied content category despite literature suggesting content affects scrutiny.
Significance. If the reviewed studies are representative and the proposed distinctions among constructs prove measurable without substantial overlap, the work would usefully highlight gaps in research on AI-advised decisions and suggest priorities for future studies on separate measurement of skepticism/verification and on content-category effects. The emphasis on organization-deployable interventions adds practical relevance.
major comments (2)
- [Abstract] Abstract: The central claim that 'no studies varied the content category' (and thus that the question remains open) is load-bearing for the synthesis and the call for further research, yet the manuscript provides no literature search strategy, databases, date range, inclusion/exclusion criteria, or total number of studies reviewed. Without these details the representativeness of the sample cannot be evaluated, directly weakening the reported patterns and the 'no studies' assertion.
- [Abstract] Abstract: The paper asserts that skepticism, verification success, and reliance 'can be cleanly separated and measured in goal-directed interactions without substantial overlap or measurement error,' but supplies no concrete examples or data from the source studies demonstrating separability, quantifying overlap, or addressing measurement error. This separability is foundational to the proposed distinction yet remains asserted rather than evidenced from the reviewed literature.
minor comments (1)
- The abstract is lengthy and could be condensed by shortening the domain list and pattern summary while retaining the core claims.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on methodological transparency and the need to evidence the proposed construct distinctions. We address each point below and will revise the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'no studies varied the content category' (and thus that the question remains open) is load-bearing for the synthesis and the call for further research, yet the manuscript provides no literature search strategy, databases, date range, inclusion/exclusion criteria, or total number of studies reviewed. Without these details the representativeness of the sample cannot be evaluated, directly weakening the reported patterns and the 'no studies' assertion.
Authors: The manuscript is framed as a narrative synthesis of emerging empirical evidence rather than a systematic review, which explains the absence of a formal PRISMA-style protocol in the current version. We agree that greater transparency would strengthen the work. In revision we will add a 'Study Identification and Selection' subsection (likely in a new Methods section) that specifies the databases consulted (Google Scholar, ACM Digital Library, PubMed, arXiv), search terms and combinations used, date range (primarily 2022 onward), inclusion criteria (empirical studies involving goal-directed tasks with organization-backed generative AI advisors that report on skepticism, verification, or reliance), and the approximate number of papers screened and retained. This addition will allow readers to assess the sample and the basis for observing that no included studies experimentally varied content category. revision: yes
-
Referee: [Abstract] Abstract: The paper asserts that skepticism, verification success, and reliance 'can be cleanly separated and measured in goal-directed interactions without substantial overlap or measurement error,' but supplies no concrete examples or data from the source studies demonstrating separability, quantifying overlap, or addressing measurement error. This separability is foundational to the proposed distinction yet remains asserted rather than evidenced from the reviewed literature.
Authors: The manuscript proposes distinguishing these constructs because prior studies often conflate them operationally, but it does not contain the precise phrasing or strong claim of 'clean separation without substantial overlap or measurement error' quoted by the referee. We will revise the relevant passages to make the language more precise and to supply concrete operational examples drawn from the reviewed studies (e.g., one study using self-report skepticism scales independent of behavioral verification logs, another measuring verification success via accuracy of external checks before measuring final reliance). Where direct evidence on low overlap or measurement error is limited in the source papers, we will acknowledge this limitation and frame the distinction as conceptually useful and experimentally feasible rather than already demonstrated to be free of overlap. revision: partial
Circularity Check
No circularity: literature review with no derivations or self-referential reductions
full rationale
This is a narrative literature review that summarizes external empirical studies on AI hallucination detection. It contains no equations, fitted parameters, predictions derived from inputs, ansatzes, or uniqueness theorems. The central claims (patterns across studies, weakest effects of output warnings, no studies varying content category) are presented as observations from reviewed literature rather than derivations that reduce to the paper's own inputs by construction. No self-citation load-bearing steps or renamings of known results appear. The absence of a formal search strategy is a methodological limitation but does not trigger any of the enumerated circularity patterns, as there is no derivation chain to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
hallucinated information
Introduction Organizations increasingly use generative AI systems as tools to assist customers, patients, students, employees, and citizens in completing ordinary tasks such as obtaining information about a reservation. Despite their utility, such systems can produce plausible but inaccurate responses. When incorrect information is provided by an AI tool,...
-
[2]
ChatGPT can make mistakes
Skepticism, verification, and reliance in goal-directed use Direct studies of how consumers are skeptical of, verify and rely upon hallucinations by organization-backed AI advisors in real settings remain rare. Much of the available evidence, summarized in Table 1, comes from adjacent goal-directed paradigms, including AI-assisted search, question answeri...
-
[3]
We now ask how organizations handle hallucination risks
Organizational and policy responses We have examined how users are skeptical of, verify, and rely upon AI advisors in adjacent settings. We now ask how organizations handle hallucination risks. Organizations often mitigate hallucination risks through at least two kinds of responses, a system-side response and a user- side response, and the two act at diff...
2024
-
[4]
Reliance, the outcome these studies most often record, can follow from skepticism, attempted verification, or successful verification, and these should not be conflated
Open psychological, methodological, and organizational questions Field studies of organization-backed AI advisors and how users respond to their hallucinations are rare, and the framework points to what such studies should measure. Reliance, the outcome these studies most often record, can follow from skepticism, attempted verification, or successful veri...
-
[5]
Moffatt v Air Canada, 2024 BCCRT 149
2024
-
[6]
Ji Z, Lee N, Frieske R, et al. Survey of hallucination in natural language generation. ACM Comput Surv 2023;55:Article 248. https://doi.org/10.1145/3571730
-
[7]
Trust in Automation: Designing for Appropriate Reliance,
Lee JD, See KA. Trust in automation: designing for appropriate reliance. Hum Factors 2004;46:50 -80. https://doi.org/10.1518/hfes.46.1.50_30392
-
[8]
Appropriate reliance on AI advice: conceptualization and the effect of explanations
Schemmer M, Kuehl N, Benz C, Bartos A, Satzger G. Appropriate reliance on AI advice: conceptualization and the effect of explanations. In: Proceedings of the 28th International Conference on Intelligent User Interfaces. ACM; 2023, p. 410-22. https://doi.org/10.1145/3581641.3584066
-
[9]
Explanations can reduce overreliance on AI systems during decision-making
Vasconcelos H, Jörke M, Grunde-McLaughlin M, Gerstenberg T, Bernstein MS, Krishna R. Explanations can reduce overreliance on AI systems during decision-making. Proc ACM Hum-Comput Interact 2023;7(CSCW1):Article 129. https://doi.org/10.1145/3579605
-
[10]
Clare DD, Levine TR. Documenting the truth-default: the low frequency of spontaneous unprompted veracity assessments in deception detection. Hum Commun Res 2019;45:286 -308. https://doi.org/10.1093/hcr/hqz001
-
[11]
InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25)
Spatharioti SE, Rothschild DM, Goldstein DG, Hofman JM. Effects of LLM -based search on decision making: speed, accuracy, and overreliance. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM; 2025. https://doi.org/10.1145/3706598.3714082. [8]* Bean AM, Payne RE, Parsons G, et al. Reliability of LLMs as medical assistants...
-
[12]
You always get an answer
Kaate I, Salminen J, Jung SG, Xuan TTT, Häyhänen E, Azem JY, Jansen BJ. “You always get an answer”: analyzing users’ interaction with AI-generated personas given unanswerable questions and risk of hallucination. In: Proceedings of the 30th International Conference on Intelligent User Interfaces. ACM
-
[13]
https://doi.org/10.1145/3708359.3712160
-
[14]
Hwang, Xiang Ren, and Maarten Sap
Zhou K, Hwang JD, Ren X, Sap M. Relying on the unreliable: the impact of l anguage models’ reluctance to express uncertainty. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics; 2024, p. 3623 -43. https://doi.org/10.18653/v1/2024.acl-long.198. [11]*...
-
[15]
Kim SSY, Liao QV, Vorvoreanu M, Ballard S, Wortman Vaughan J. “I’m not sure, but …”: examining the impact of large language models’ uncertainty expression on user reliance and trust. In: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. ACM; 2024, p. 822 -35. https://doi.org/10.1145/3630106.3658941
-
[16]
Polite AI mitigates user susceptibility to AI hallucinations
Pak R, Rovira E, McLaughlin AC. Polite AI mitigates user susceptibility to AI hallucinations. Ergonomics 2025;68:1735-45. https://doi.org/10.1080/00140139.2024.2434604. [14]** Bo JY, Wan S, Anderson A. To rely or not to rely? Evaluating interventions for appropriate reliance on large language models. In: Proceedings of the 2025 CHI Conference on Human Fac...
-
[17]
Buçinca Z, Malaya MB, Gajos KZ. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. Proc ACM Hum-Comput Interact 2021;5(CSCW1):Article 188. https://doi.org/10.1145/3449287
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[18]
Ashktorab Z, Desmond M, Pan Q, Johnson JM, Brachman M, Dugan C, et al. Emerging reliance behaviors i n human-AI content grounded data generation: the role of cognitive forcing functions and hallucinations. In: Proceedings of the 4th Annual Symposium on Human-Computer Interaction for Work. ACM; 2025. 10.1145/3729176.3729179. [17]* Liu C, Zhou Q, Shen X, Li...
-
[19]
New Tools, New Rules: A Practical Guide to Effective and Responsible Generative AI Use for Surveys and Experiments in Research
Blanchard SJ, Duani N, Garvey AM, Netzer O, Oh TT. New Tools, New Rules: A Practical Guide to Effective and Responsible Generative AI Use for Surveys and Experiments in Research. Journal of Marketing 2025 ; 89(6):119-39
2025
-
[20]
Effects of perceptual fluency on judgments of truth
Reber R, Schwarz N. Effects of perceptual fluency on judgments of truth. Consciousness and Cognition 1999;8:338–42. https://doi.org/10.1006/ccog.1999.0386
-
[21]
Knowledge does not protect against illusory truth
Fazio LK, Brashier NM, Payne BK, Marsh EJ. Knowledge does not protect against illusory truth. Journa l of Experimental Psychology: General 2015;144:993–1002. https://doi.org/10.1037/xge0000098
-
[22]
On the conversational persuasiveness of GPT-4.Nature Human Behaviour, pages 1–9, May 2025
Arora N, Chakraborty I, Nishimura Y. AI–human hybrids for marketing research: Leveraging large language models (LLMs) as collaborators. Journal of Marketing 2025; 89(2):43-70. [22]** Salvi F, Horta Ribeiro M, Gallotti R, West R. On the conversational persuasiveness of GPT -4. Nature Human Behaviour 2025;9:1645–53. https://doi.org/10.1038/s41562-025-02194-...
-
[23]
Kıyak YS, Coşkun Ö, Budakoğlu Iİ. “ChatGPT can make mistakes” warnings fail: a randomized controlled trial. Medical Education 2026;60:138–42. https://doi.org/10.1111/medu.70056. [24]* Spearing ER, Gile CI, Fogwill AL, Prike T, Swire-Thompson B, Lewandowsky S, Ecker UKH. Countering AI-generated misinformation with pre-emptive source discreditation and debu...
-
[24]
Improving human-AI collaboration with descriptions of AI behavior
Cabrera AA, Perer A, Hong JI. Improving human-AI collaboration with descriptions of AI behavior. Proceedings of the ACM on Human-Computer Interaction 2023;7(CSCW1):Article 136. https://doi.org/10.1145/3579612. [26]** Steyvers M, Tejeda H, Kumar A, et al. What large language models know and what people think they know. Nature Machine Intelligence 2025;7:22...
-
[25]
Knowing about knowing: an illusion of human competence can hinder appropriate reliance on AI systems
He G, Kuiper L, Gadiraju U. Knowing about knowing: an illusion of human competence can hinder appropriate reliance on AI systems. In: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM; 2023. https://doi.org/10.1145/3544548.3581025
-
[26]
A decision theoretic framework for measuring AI reliance
Guo Z, Wu Y, Hartline JD, Hullman J. A decision theoretic framework for measuring AI reliance. In: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. ACM; 2024. https://doi.org/10.1145/3630106.3658901
-
[27]
Three challenges for AI-assisted decision-making
Steyvers M, Kumar A. Three challenges for AI-assisted decision-making. Perspectives on Psychological Science 2024;19:722–34. https://doi.org/10.1177/17456916231181102. [30]** Farquhar S, Kossen J, Kuhn L, Gal Y. Detecting hallucinations in large language models using semantic entropy. Nature 2024;630:625–30. https://doi.org/10.1038/s41586-024-07421-0. Thi...
-
[28]
Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R
Dell’Acqua F, McFowland E III, Mollick ER, et al. Navigating the jagged technological frontier: field experimental evidence of the effects of artificial intelligence on knowledge worker productivity and quality. Organization Science 2026. (forthcoming) https://doi.org/10.1287/orsc.2025.21838. [32]* Kim TW, Usman U, Garvey A, Duhachek A. From algorithm ave...
-
[29]
OJ L, 2024/1689
Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). OJ L, 2024/1689
2024
-
[30]
1:22-cv-01461 (S.D.N.Y
Mata v Avianca, Inc., No. 1:22-cv-01461 (S.D.N.Y. June 22, 2023) (order imposing sanctions for AI-generated fabricated citations)
2023
-
[31]
Harvard Law School Forum on Corporate Governance, February 19, 2026
EY analysis of Fortune 100 10-K filings, cited in: How boards can lead in a world remade by AI. Harvard Law School Forum on Corporate Governance, February 19, 2026. https://corpgov.law.harvard.edu/2026/02/19/how- boards-can-lead-in-a-world-remade-by-ai/
2026
-
[32]
What are AI guardrails? November 2024
McKinsey & Company. What are AI guardrails? November 2024. https://www.mckinsey.com/featured - insights/mckinsey-explainers/what-are-ai-guardrails
2024
-
[33]
Zhang v Chen, 2024 BCSC 285 (lawyer ordered to pay costs and audit all files after submitting ChatGPT - fabricated citations in child custody dispute)
2024
-
[34]
[39]* Couvrette v Wisnovsky, 2025 WL 4109655 (D
Ko v Li, 2025 ONSC 2766 (Ontario judge ordered counsel to show cause for contempt after AI -generated false citations identified). [39]* Couvrette v Wisnovsky, 2025 WL 4109655 (D. Or. Dec. 12, 2025)
2025
-
[35]
P., Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N
Lee, H. P., Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In Proceedings of the 2025 CHI conference on human factors in computing systems 2025; 1-
2025
-
[36]
DOI 10.1145/3706598.3713778
-
[37]
AI hallucination cases database
Charlotin D. AI hallucination cases database. https://www.damiencharlotin.com/hallucinations/ (last updated May 14, 2026; 1,434 cases catalogued globally)
2026
-
[38]
FTC announces crackdown on deceptive AI claims and schemes (Operation AI Comply)
Federal Trade Commission. FTC announces crackdown on deceptive AI claims and schemes (Operation AI Comply). September 25, 2024. https://www.ftc.gov/news-events/news/press-releases/2024/09/ftc-announces- crackdown-deceptive-ai-claims-schemes
2024
-
[39]
2323042 (final order issued Jan
In re DoNotPay, Inc., FTC File No. 2323042 (final order issued Jan. 10, 2025) ($193,000 penalty for marketing AI chatbot as equivalent to human lawyer without substantiation)
2025
-
[40]
2423132 (settlement approved Dec
In re Evolv Technologies Holdings, Inc., FTC File No. 2423132 (settlement approved Dec. 2024) (AI security scanner marketed as weapons detection system failed to detect handguns; company removed negative findings from commissioned report)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.