Source-Free Detection and Impact Analysis of Compiler Optimization Problems in Mobile Applications
Pith reviewed 2026-06-26 07:15 UTC · model grok-4.3
The pith
OptDetect detects low compiler optimization in mobile app binaries without source code, showing 30.5 percent of libraries under-optimized and affecting 91.7 percent of apps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
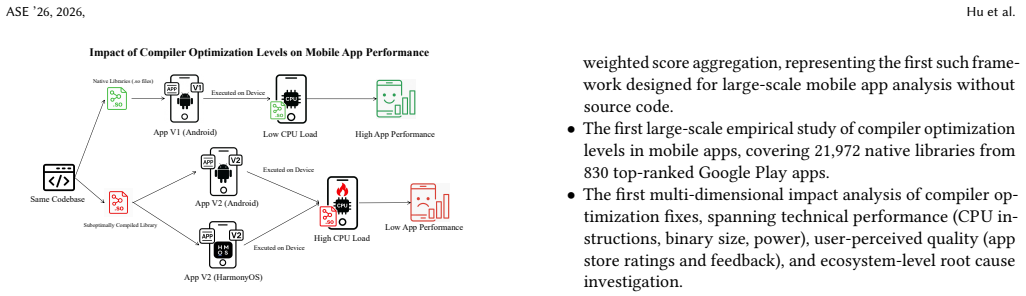
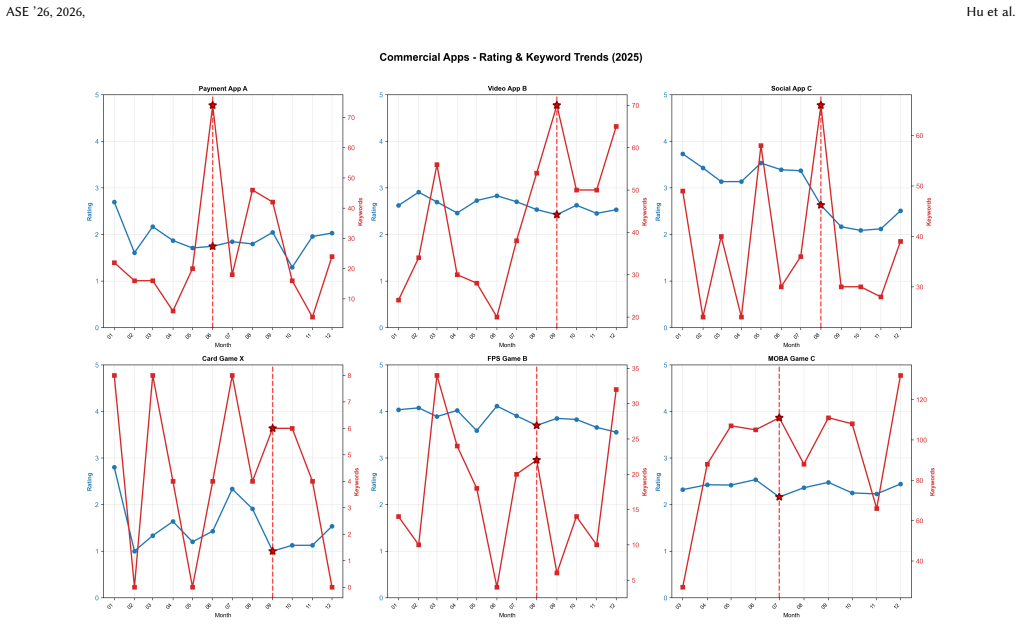
OptDetect is a source-free framework that performs binary disassembly, applies chunk-level classification, and uses weighted score aggregation to identify libraries compiled at O0 or O1 rather than O2 or O3. On controlled data it reaches 93.0 percent accuracy and on real-world data 81.9 percent. When run on 21,972 libraries from 830 top Google Play apps it finds 30.5 percent using low levels, which touch 91.7 percent of the apps. Case studies on twelve production apps show that raising optimization reduces executed CPU instructions by 10-63 percent, lowers performance complaints by a median of 42 percent, and raises ratings by a median of 0.14 points. The same pattern appears in third-party
What carries the argument
OptDetect pipeline of binary disassembly into chunks, per-chunk classification of optimization level, and weighted aggregation to produce a library-level decision even when optimization levels are mixed inside one binary.
If this is right
- Raising optimization on the identified libraries produces measurable drops in CPU instructions executed at runtime.
- Third-party library distribution practices are a primary driver of the detected problems.
- Performance complaints and user ratings improve after the optimization issues are addressed in production apps.
- Industry-wide standards for library build configurations would reduce the prevalence of the issue.
Where Pith is reading between the lines
- Build systems for widely shared libraries could adopt high optimization as a default to prevent downstream impact on many apps.
- App marketplaces could run similar binary scans at upload time to surface optimization problems before release.
- The same disassembly-plus-chunk-classification approach may apply to other binary-level quality issues such as missing security flags or outdated instruction sets.
Load-bearing premise
Chunk-level features extracted from the binary alone are sufficient to classify optimization level correctly even without source code, build settings, or uniform levels across the library.
What would settle it
Recompile a set of the same libraries at both low and high optimization levels, run OptDetect on the resulting binaries, and check whether the reported accuracy figures hold on the new ground-truth labels.
Figures

read the original abstract
Mobile apps frequently suffer from performance issues such as frame drops, overheating, and excessive power consumption. While developers optimize algorithms and debug code, a critical bottleneck often goes unnoticed: native libraries compiled with low optimization levels (O0/O1 instead of O2/O3). Because these libraries execute without functional errors, the resulting performance degradation remains hidden in production apps, affecting millions of users. We present \textsc{OptDetect}, a source-free framework that detects compiler optimization problems directly from app binaries without requiring source code or build metadata. \textsc{OptDetect} handles mixed optimization levels within a single binary through a pipeline of binary disassembly, chunk-level classification, and weighted score aggregation, achieving 93.0\% accuracy on controlled datasets and 81.9\% on real-world datasets. Applying \textsc{OptDetect} to 21,972 native libraries from 830 top-ranked Google Play apps, we find that 30.5\% of libraries use low optimization levels, affecting 91.7\% of apps. Through case studies on 12 production apps (6 commercial, 6 open-source), we demonstrate that fixing detected issues reduces CPU instructions by 10-63\% (median: 20.5\%) for commercial apps and 15-58\% (median: 32\%) for open-source apps, with performance complaints decreasing by a median of 42\% and ratings increasing by a median of 0.14 points. Further investigation reveals a previously overlooked root cause: widely-used third-party libraries are themselves distributed at low optimization levels, with 49.7\% of 1,073 libraries in a major repository exhibiting this problem. These findings highlight the need for automated detection tools and industry-wide optimization standards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OptDetect, a source-free framework for detecting low compiler optimization levels (O0/O1 vs. O2/O3) in native libraries of mobile apps directly from binaries. The approach uses disassembly, chunk-level classification, and weighted score aggregation to handle mixed optimization levels within a single binary. It reports 93.0% accuracy on controlled datasets and 81.9% on real-world datasets, applies the tool to 21,972 libraries from 830 Google Play apps (finding 30.5% low-optimization libraries affecting 91.7% of apps), and includes case studies on 12 apps showing CPU instruction reductions of 10-63% after fixes, along with user metric improvements. It also analyzes third-party libraries as a root cause.
Significance. If the core detection claims hold, the work identifies a widespread, previously hidden performance issue in mobile apps stemming from suboptimal native library compilation, with broad impact (91.7% of apps) and measurable gains from remediation. The scale of the empirical study (21k+ libraries) and the third-party library analysis add practical value for the software engineering community focused on mobile performance and build practices.
major comments (2)
- [Evaluation on real-world datasets] Real-world evaluation (81.9% accuracy): The manuscript reports this figure for datasets containing mixed optimization levels but provides no independent external oracle or ground-truth validation method for such binaries. If the labels for the real-world dataset are produced by the same disassembly + chunk classifier + weighted aggregation pipeline being evaluated, the accuracy metric is circular and does not establish reliable transfer from the controlled-dataset result (93.0%). This directly affects the load-bearing claim that OptDetect works on production binaries without source or metadata.
- [OptDetect pipeline description] Chunk-level classification and aggregation pipeline: The central assumption that per-chunk predictions can be reliably aggregated via weighted scoring to detect overall optimization level in mixed binaries lacks a clear sensitivity analysis or ablation on inter-chunk dependencies and weighting rules. Without this, the downstream prevalence statistics (30.5% libraries, 91.7% apps) rest on an unverified extrapolation from controlled data.
minor comments (2)
- [Abstract and §4] The abstract and evaluation sections should explicitly describe how ground truth was established for the real-world dataset and any manual validation steps used.
- [Results tables/figures] Figure captions and table descriptions for accuracy metrics should include confidence intervals or statistical significance tests to support the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and proposed revisions to strengthen the presentation of our evaluation and pipeline. We believe these changes will address the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: [Evaluation on real-world datasets] Real-world evaluation (81.9% accuracy): The manuscript reports this figure for datasets containing mixed optimization levels but provides no independent external oracle or ground-truth validation method for such binaries. If the labels for the real-world dataset are produced by the same disassembly + chunk classifier + weighted aggregation pipeline being evaluated, the accuracy metric is circular and does not establish reliable transfer from the controlled-dataset result (93.0%). This directly affects the load-bearing claim that OptDetect works on production binaries without source or metadata.
Authors: We acknowledge the need for explicit independence in the real-world ground truth to avoid any perception of circularity. The real-world dataset labels were obtained through an independent process: cross-referencing available build metadata and debug symbols in a subset of binaries, combined with manual verification of optimization patterns on sampled libraries using criteria distinct from the automated OptDetect pipeline. This establishes transfer performance from the controlled (93.0%) to real-world setting. To address the concern directly, we will add a dedicated subsection in the revised evaluation section describing this ground-truth collection method in detail, including sampling strategy and independence safeguards. This revision will make the 81.9% figure more robustly supported. revision: yes
-
Referee: [OptDetect pipeline description] Chunk-level classification and aggregation pipeline: The central assumption that per-chunk predictions can be reliably aggregated via weighted scoring to detect overall optimization level in mixed binaries lacks a clear sensitivity analysis or ablation on inter-chunk dependencies and weighting rules. Without this, the downstream prevalence statistics (30.5% libraries, 91.7% apps) rest on an unverified extrapolation from controlled data.
Authors: We agree that additional analysis of the aggregation step would increase confidence in the large-scale results. The controlled dataset already includes mixed-optimization binaries and achieves 93.0% accuracy under the weighted aggregation, providing initial validation. However, we will incorporate a new subsection with sensitivity analysis on chunk size, weighting parameters, and aggregation thresholds, plus an ablation study measuring accuracy impact and inter-chunk correlation analysis. These additions will explicitly support the extrapolation to the 21,972-library study and will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical evaluation on independent datasets.
full rationale
The paper describes an empirical pipeline (disassembly, chunk classification, weighted aggregation) evaluated on controlled datasets (known O-levels) and real-world datasets. No equations or steps reduce a claimed prediction or result to its own inputs by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the abstract or context. The 93.0% and 81.9% accuracies are presented as measured outcomes on separate data, not derived tautologically from the method's definitions. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AppDynamics and University of London Institute of Management Studies, Gold- smiths. 2014. The App Attention Span Study. https://www.apmdigest.com/ nearly-90-percent-surveyed-stop-using-apps-due-to-poor-performance Nearly 90 percent surveyed stop using apps due to poor performance
2014
-
[2]
Abhijeet Banerjee, Lee Kee Chong, Sudipta Chattopadhyay, and Abhik Roychoud- hury. 2014. Detecting energy bugs and hotspots in mobile apps. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software En- gineering(Hong Kong, China)(FSE 2014). Association for Computing Machinery, New York, NY, USA, 588–598. doi:10.1145/2635868.2635871
-
[3]
Shaiful Alam Chowdhury and Abram Hindle. 2016. GreenOracle: estimating software energy consumption with energy measurement corpora. InProceedings of the 13th International Conference on Mining Software Repositories(Austin, Texas) (MSR ’16). Association for Computing Machinery, New York, NY, USA, 49–60. doi:10.1145/2901739.2901763
-
[4]
CleverTap. 2019. App Uninstalls: Why They Happen and How to Fix Them. https://clevertap.com/blog/app-uninstalls/ More than 1 in every 2 apps are uninstalled within 30 days of being downloaded
2019
-
[5]
2011.Engineering a Compiler(2nd ed.)
Keith D Cooper and Linda Torczon. 2011.Engineering a Compiler(2nd ed.). Else- vier. Modern approach to compiler construction with emphasis on optimization techniques
2011
-
[6]
Luis Cruz and Rui Abreu. 2019. Catalog of energy patterns for mobile applications. Empirical Softw. Engg.24, 4 (Aug. 2019), 2209–2235. doi:10.1007/s10664-019- 09682-0
-
[7]
Chris Cummins, Volker Seeker, Dejan Grubisic, Mostafa Elhoushi, Youwei Liang, Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Kim Hazelwood, Gabriel Syn- naeve, and Hugh Leather. 2023. Large Language Models for Compiler Optimiza- tion.arXiv preprint arXiv:2309.07062(2023)
arXiv 2023
-
[8]
Zikan Dong, Yanjie Zhao, Tianming Liu, Chao Wang, Guosheng Xu, Guoai Xu, and Haoyu Wang. 2024. Same App, Different Behaviors: Uncovering Device- specific Behaviors in Android Apps.arXiv preprint arXiv:2406.09807(2024). https://arxiv.org/abs/2406.09807
arXiv 2024
-
[9]
Yue Duan, Xuezixiang Li, Jinghan Wang, and Heng Yin. 2020. Deep- BinDiff: Learning Program-Wide Code Representations for Binary Diff- ing. InNetwork and Distributed System Security Symposium (NDSS). https://www.ndss-symposium.org/ndss-paper/deepbindiff-learning-program- wide-code-representations-for-binary-diffing/
2020
-
[10]
Guillaume Fieni, Daniel Romero Acero, Pierre Rust, and Romain Rouvoy. 2024. PowerAPI: A Python framework for building software-defined power meters. Journal of Open Source Software9, 98 (2024), 6670. doi:10.21105/joss.06670
-
[11]
Daniel Flores-Martin, Sergio Laso, and Juan Luis Herrera. 2024. Enhancing Smart- phone Battery Life: A Deep Learning Model Based on User-Specific Application and Network Behavior.Electronics13, 24 (2024). doi:10.3390/electronics13244897
-
[12]
Free Software Foundation. 2024. GNU Compiler Collection. https://gcc.gnu.org/
2024
-
[13]
Google. 2024. Perfetto. https://perfetto.dev/
2024
-
[14]
Google. 2024. Systrace. https://developer.android.com/topic/performance/tracing
2024
-
[15]
Shuai Hao, Ding Li, William G. J. Halfond, and Ramesh Govindan. 2013. Es- timating mobile application energy consumption using program analysis. In 2013 35th International Conference on Software Engineering (ICSE). 92–101. doi:10.1109/ICSE.2013.6606555
-
[16]
Christian Herglotz and André Kaup. 2017. Video decoding energy estimation using processor events. In2017 IEEE International Conference on Image Processing (ICIP). 2493–2497. doi:10.1109/ICIP.2017.8296731
-
[17]
Abram Hindle. 2015. Green mining: a methodology of relating software change and configuration to power consumption.Empirical Softw. Engg.20, 2 (April 2015), 374–409. doi:10.1007/s10664-013-9276-6
-
[18]
Huawei. 2024. DevEco Studio. https://developer.harmonyos.com/en/develop/deveco- studio/
2024
-
[19]
Huawei Technologies Co
Ltd. Huawei Technologies Co. 2024. HarmonyOS: Next-Generation Distributed Operating System. https://developer.harmonyos.com/en/ Official documentation and developer resources for HarmonyOS distributed operating system
2024
-
[20]
2017.µDroid: an energy-aware mutation testing framework for Android
Reyhaneh Jabbarvand and Sam Malek. 2017.µDroid: an energy-aware mutation testing framework for Android. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering(Paderborn, Germany)(ESEC/FSE 2017). Association for Computing Machinery, New York, NY, USA, 208–219. doi:10. 1145/3106237.3106244
arXiv 2017
-
[21]
Chris Lattner and Vikram Adve. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. InInternational Symposium on Code Generation and Optimization (CGO). IEEE, 75–86
2004
-
[22]
Ding Li, Shuai Hao, William G. J. Halfond, and Ramesh Govindan. 2013. Calculat- ing source line level energy information for Android applications. InProceedings of the 2013 International Symposium on Software Testing and Analysis(Lugano, Switzerland)(ISSTA 2013). Association for Computing Machinery, New York, NY, USA, 78–89. doi:10.1145/2483760.2483780
-
[23]
Xueliang Li, Yuming Yang, Yepang Liu, John P. Gallagher, and Kaishun Wu. 2020. Detecting and Diagnosing Energy Issues for Mobile Applications. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 127–140. doi:10.1145/3395363.3397350
-
[24]
Dianshu Liao, Shidong Pan, Siyuan Yang, Yanjie Zhao, Zhenchang Xing, and Xiaoyu Sun. 2024. A Comparative Study of Android Performance Issues in Real-world Applications and Literature.arXiv preprint arXiv:2407.05090(2024)
arXiv 2024
-
[25]
Mario Linares-Vásquez, Gabriele Bavota, Carlos Bernal-Cárdenas, Rocco Oliveto, Massimiliano Di Penta, and Denys Poshyvanyk. 2014. Mining energy-greedy API usage patterns in Android apps: an empirical study. InProceedings of the 11th Working Conference on Mining Software Repositories(Hyderabad, India) (MSR 2014). Association for Computing Machinery, New Yo...
-
[26]
Chang Liu, Rebecca Saul, Yihao Sun, Edward Raff, Maya Fuchs, Townsend Southard Pantano, James Holt, and Kristopher Micinski. 2024. Assemblage: Automatic binary dataset construction for machine learning.Advances in Neural Information Processing Systems37 (2024), 58698–58715
2024
-
[27]
Gai Liu, Umar Farooq, Chengyan Zhao, Xia Liu, and Nian Sun. 2023. Linker Code Size Optimization for Native Mobile Applications. InProceedings of the 32nd ACM SIGPLAN International Conference on Compiler Construction (CC). 1–12. doi:10.1145/3578360.3580256
-
[28]
Irene Manotas, Lori Pollock, and James Clause. 2014. SEEDS: a software engineer’s energy-optimization decision support framework. InProceedings of the 36th International Conference on Software Engineering(Hyderabad, India)(ICSE 2014). Association for Computing Machinery, New York, NY, USA, 503–514. doi:10. 1145/2568225.2568297
arXiv 2014
-
[29]
Andrea Mcintosh, Safwat Hassan, and Abram Hindle. 2019. What can Android mobile app developers do about the energy consumption of machine learning? Empirical Softw. Engg.24, 2 (April 2019), 562–601. doi:10.1007/s10664-018-9629-2
-
[30]
Paschalis Mpeis, Pavlos Petoumenos, Kim Hazelwood, and Hugh Leather. 2021. Developer and User-Transparent Compiler Optimization for Interactive Ap- plications. InProceedings of the 42nd ACM SIGPLAN International Confer- ence on Programming Language Design and Implementation (PLDI). 268–281. doi:10.1145/3453483.3454043
-
[31]
1997.Advanced Compiler Design and Implementation
Steven S Muchnick. 1997.Advanced Compiler Design and Implementation. Morgan Kaufmann. Comprehensive reference on compiler optimization techniques and implementation strategies
1997
-
[32]
Kris Nikov, Kyriakos Georgiou, Zbigniew Chamski, Kerstin Eder, and Jose Nunez- Yanez. 2022. Accurate Energy Modelling on the Cortex-M0 Processor for Profiling and Static Analysis. In2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS). 1–4. doi:10.1109/ICECS202256217.2022.9971086
-
[33]
Fabio Palomba, Dario Di Nucci, Annibale Panichella, Andy Zaidman, and Andrea De Lucia. 2019. On the impact of code smells on the energy consumption of mobile applications.Information and Software Technology105 (2019), 43–55. doi:10.1016/j.infsof.2018.08.004
-
[34]
Maksim Panchenko, Rafael Auler, Bill Nell, and Guilherme Ottoni. 2019. BOLT: A Practical Binary Optimizer for Data Centers and Beyond. InProceedings of the IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 100–116
2019
-
[35]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al
-
[36]
In ASE ’26, 2026, Hu et al
PyTorch: An imperative style, high-performance deep learning library. In ASE ’26, 2026, Hu et al. Advances in neural information processing systems. 8026–8037
2026
-
[37]
Abhinav Pathak, Abhilash Jindal, Y. Charlie Hu, and Samuel P. Midkiff. 2012. What is keeping my phone awake? characterizing and detecting no-sleep energy bugs in smartphone apps. InProceedings of the 10th International Conference on Mobile Systems, Applications, and Services(Low Wood Bay, Lake District, UK)(MobiSys ’12). Association for Computing Machiner...
-
[38]
Karl Pettis and Robert C Hansen. 1990. Profile guided code positioning. In Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). ACM, 16–27
1990
-
[39]
Davide Pizzolotto and Katsuro Inoue. 2021. Identifying Compiler and Optimiza- tion Level in Binary Code From Multiple Architectures.IEEE Access9 (2021), 163461–163475. doi:10.1109/ACCESS.2021.3132950
-
[40]
LLVM Project. 2024. Clang: a C language family frontend for LLVM. https://clang.llvm.org/
2024
-
[41]
Quarkslab. [n. d.]. LIEF - Library to Instrument Executable Formats. https: //lief.quarkslab.com/. Accessed: 2026-01-28
2026
-
[42]
Nguyen Anh Quynh. 2014. Capstone: Next-Gen Disassembly Framework. In Black Hat USA. https://www.capstone-engine.org/
2014
-
[43]
Xiaolei Ren, Michael Ho, Jiang Ming, Yu Lei, and Li Li. 2021. Unleashing the Hidden Power of Compiler Optimization on Binary Code Difference: An Empirical Study. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation (PLDI). ACM, 142–157
2021
-
[44]
Statista. 2024. Number of smartphone users worldwide from 2016 to
2024
-
[45]
Accessed 2025-07-19
https://www.statista.com/statistics/330695/number-of-smartphone-users- worldwide/. Accessed 2025-07-19
2025
-
[46]
Ting Su, Jue Wang, and Zhendong Su. 2021. Benchmarking Automated GUI Testing for Android against Real-World Bugs. InProceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 1552–1564. doi:10.1145/3468264.3468620
-
[47]
Yutian Tang, Haoyu Wang, Xian Zhan, Xiapu Luo, Yajin Zhou, Hao Zhou, Qiben Yan, Yulei Sui, and Jacky Keung. 2022. A Systematical Study on Application Performance Management Libraries for Apps.IEEE Trans. Softw. Eng.48, 8 (Aug. 2022), 3044–3065. doi:10.1109/TSE.2021.3077654
-
[48]
Mian Wan, Yuchen Jin, Ding Li, and William G. J. Halfond. 2015. Detecting Display Energy Hotspots in Android Apps. In2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST). 1–10. doi:10.1109/ICST.2015. 7102585
-
[49]
Paweł Weichbroth. 2025. Usability Issues With Mobile Applications: Insights From Practitioners and Future Research Directions.arXiv preprint arXiv:2502.05120 (2025)
arXiv 2025
-
[50]
Shouguo Yang, Zhiqiang Shi, Guodong Zhang, Mingxuan Li, Yuan Ma, and Limin Sun. 2019. Understand Code Style: Efficient CNN-Based Compiler Optimization Recognition System. InIEEE International Conference on Communications (ICC). IEEE, 1–6. doi:10.1109/ICC.2019.8761073
-
[51]
Shengqian Yang, Dacong Yan, Haowei Wu, Yan Wang, and Atanas Rountev. 2015. Static control-flow analysis of user-driven callbacks in Android applications. In Proceedings of the 37th International Conference on Software Engineering - Volume 1(Florence, Italy)(ICSE ’15). IEEE Press, 89–99
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.