Action-BED: Task-Driven Bayesian Experimental Design with Singly Intractable Objectives
Pith reviewed 2026-06-26 05:50 UTC · model grok-4.3
The pith
Bayesian experimental design can be reformulated around expected future loss on downstream actions, turning it into singly intractable objectives that support joint stochastic gradient optimization of design and action policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
All expected future losses arising in Bayesian experimental design can be rearranged into singly intractable objectives that are jointly optimized with respect to both the design policy and a downstream action policy using stochastic gradients, without requiring explicit posterior or marginal likelihood estimation and relying only on the ability to sample from the joint model and evaluate the downstream loss.
What carries the argument
The rearrangement of any expected future loss into a singly intractable objective that admits unbiased stochastic gradient estimates for joint optimization of design and action policies.
If this is right
- Design policies become learnable more effectively and efficiently than with existing doubly intractable methods.
- The same framework supports easy customization to different downstream tasks simply by changing the loss function.
- No separate posterior approximation or marginal likelihood estimator is ever required.
- Optimization uses only joint-model samples and direct loss evaluations, making the approach naturally implicit.
Where Pith is reading between the lines
- The formulation may extend naturally to adaptive sequential design by treating the design policy as a recurrent or history-dependent function.
- It could simplify the combination of experimental design with modern simulators or generative models that already support joint sampling.
- The approach might transfer to settings where the downstream action policy itself is learned, such as in active learning or reinforcement learning loops.
Load-bearing premise
Any expected future loss can be rearranged into a singly intractable objective that admits unbiased stochastic gradient estimates, and this holds for arbitrary downstream losses and model classes provided one can sample from the joint model.
What would settle it
An explicit counterexample of an expected future loss that cannot be rearranged to yield unbiased stochastic gradients, or an empirical demonstration that the joint optimization produces worse downstream performance than a standard uncertainty-reduction baseline on a task with known optimal design.
Figures



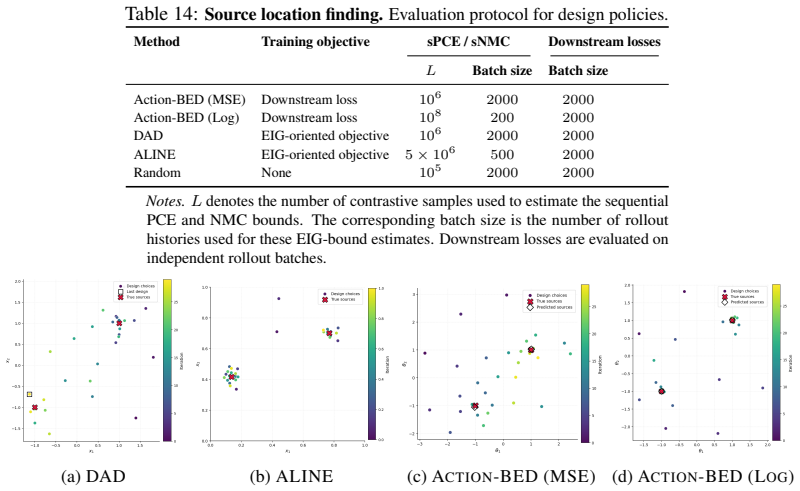

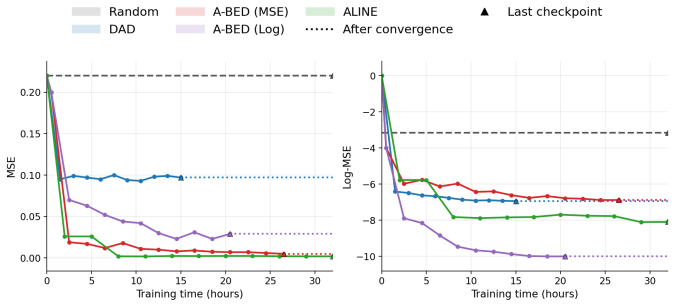

read the original abstract
Bayesian experimental design (BED) has traditionally been based on maximising expected uncertainty reductions from prior to posterior. A major shortfall of this approach is that it leads to doubly intractable objectives that are difficult to optimise, while customising them to particular downstream tasks of interest can also be difficult. Following first principles decision theory, we demonstrate that BED can alternatively be formulated in terms of an expected future loss (EFL) on downstream actions, providing a simple and naturally task-driven framework. Critically, we then show that all such EFLs can be rearranged into singly intractable objectives that can be jointly optimised with respect to both the design policy and a downstream action policy using stochastic gradients, an approach we refer to as ACTION-BED. This formulation further sidesteps the need for any explicit posterior or marginal likelihood estimation and is naturally implicit, requiring only the ability to sample from the joint model over model parameters and data, and evaluate the downstream loss function. It thus allows design policies to be learned more effectively, efficiently, and simply than existing methods, while providing easy customisation to different downstream tasks and losses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Action-BED as an alternative to traditional uncertainty-reduction BED. Following decision theory, it formulates the problem via expected future loss (EFL) on a downstream action policy. The central claim is that any such EFL admits a rearrangement into a singly intractable objective that can be jointly optimized over both the design policy and the action policy via stochastic gradients; the method requires only samples from the joint model and evaluation of the loss, with no explicit posterior or marginal likelihood estimation.
Significance. If the rearrangement holds for arbitrary losses and model classes, the framework supplies a direct, task-customizable route to BED that avoids doubly intractable objectives and leverages standard Monte Carlo policy-gradient estimators. This is a clear practical advantage over conventional approaches and receives credit for the implicit formulation and the explicit statement that only joint-model sampling is required.
minor comments (2)
- [Abstract] The abstract packs multiple technical claims into single sentences; splitting the description of the rearrangement and the optimization procedure would improve readability.
- Notation for the design policy and action policy should be introduced with a single consistent symbol table or diagram early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and for recommending acceptance. We are pleased that the core contributions—the rearrangement of expected future loss into a singly intractable objective, the joint optimization via stochastic gradients, and the requirement of only joint-model samples—were recognized as providing a clear practical advantage.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central claim is a decision-theoretic reformulation of BED as expected future loss (EFL), rearranged into a singly intractable objective optimized jointly over design and action policies via stochastic gradients. This follows directly from standard Monte Carlo estimation of expectations of the form E[loss(action_policy(data), theta)] using samples from the joint model, without any parameter fitting, self-citation load-bearing, or uniqueness theorems. No equations reduce by construction to inputs, and the formulation does not rename known results or smuggle ansatzes. The approach is consistent with external policy gradient techniques and requires only sampling ability, making the derivation independent.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expected future loss on downstream actions is a valid objective for experimental design
- ad hoc to paper Any EFL admits a rearrangement into a singly intractable objective
Reference graph
Works this paper leans on
-
[1]
Aliprantis, C. D. and Border, K. C. (2006).Infinite Dimensional Analysis: A Hitchhiker’s Guide. Springer, 3 edition. 16
2006
-
[2]
and Li, J
Ao, Z. and Li, J. (2024). On Estimating the Gradient of the Expected Information Gain in Bayesian Experimental Design.Proceedings of the AAAI Conference on Artificial Intelligence, 38(18):20311–20319. Number: 18. 2, 3
2024
-
[3]
Ashman, M., Diaconu, C., Weller, A., and Turner, R. E. (2024). In-context in-context learning with transformer neural processes. In Antorán, J. and Naesseth, C. A., editors,Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference, volume 253 ofProceedings of Machine Learning Research, pages 1–29. PMLR. 23
2024
-
[4]
and Agakov, F
Barber, D. and Agakov, F. (2003). Information Maximization in Noisy Channels : A Variational Approach. InAdvances in Neural Information Processing Systems, volume 16. MIT Press. 2, 3, 5
2003
-
[5]
and Salako, K
Barlas, Y . and Salako, K. (2025). Performance Comparisons of Reinforcement Learning Algo- rithms for Sequential Experimental Design. Philadelphia, USA. 7
2025
-
[6]
Belousov, B., Abdulsamad, H., Schultheis, M., and Peters, J. (2019). Belief space model predictive control for approximately optimal system identification. InProceedings of the Multidis- ciplinary Conference on Reinforcement Learning and Decision Making (RLDM). 8
2019
-
[7]
Bickford Smith, F., Kossen, J., Trollope, E., Van Der Wilk, M., Foster, A., and Rainforth, T. (2025). Rethinking aleatoric and epistemic uncertainty. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 4345–4359. PMLR. 5
2025
-
[8]
V ., Chades, I., and Dezfouli, A
Blau, T., Bonilla, E. V ., Chades, I., and Dezfouli, A. (2022). Optimizing Sequential Experimental Design with Deep Reinforcement Learning. InProceedings of the 39th International Conference on Machine Learning, pages 2107–2128. PMLR. 3, 7
2022
-
[9]
M., and Bonilla, E
Blau, T., Chades, I., Dezfouli, A., Steinberg, D. M., and Bonilla, E. V . (2023). Cross-Entropy Estimators for Sequential Experiment Design with Reinforcement Learning. 7
2023
-
[10]
R., Intes, X., Bürkner, P.-C., and Radev, S
Bracher, N., Kühmichel, L., Ivanova, D. R., Intes, X., Bürkner, P.-C., and Radev, S. T. (2025). JADAI: Jointly Amortizing Adaptive Design and Bayesian Inference. arXiv:2512.22999 [stat]. 2, 3, 7
-
[11]
Chakraborty, A., Huan, X., and Catanach, T. A. (2024). A Likelihood-Free Approach to Goal-Oriented Bayesian Optimal Experimental Design. 6
2024
-
[12]
and Verdinelli, I
Chaloner, K. and Verdinelli, I. (1995). Bayesian Experimental Design: A Review.Statistical Science, 10(3):273–304. 1, 2
1995
- [13]
-
[14]
Cox, R. T. et al. (1946). Probability, frequency and reasonable expectation.American journal of physics, 14(1):1–13. 3
1946
-
[15]
Dawid, A. P. (1998). Coherent measures of discrepancy, uncertainty and dependence, with appli- cations to bayesian predictive experimental design.Department of Statistical Science, University College London. http://www. ucl. ac. uk/Stats/research/abs94. html, Tech. Rep, 139. 4, 5
1998
-
[16]
Dawid, A. P. (2007). The geometry of proper scoring rules.Annals of the Institute of Statistical Mathematics, 59(1):77–93. 2, 3
2007
-
[17]
DeGroot, M. (1962). Uncertainty, information, and sequential experiments.The Annals of Mathematical Statistics, 33(2):404–419. 1, 2, 5
1962
-
[18]
Dong, J., Jacobsen, C., Khalloufi, M., Akram, M., Liu, W., Duraisamy, K., and Huan, X. (2025). Variational Bayesian optimal experimental design with normalizing flows.Computer Methods in Applied Mechanics and Engineering, 433:117457. 3, 7 11
2025
-
[19]
Filstroff, L., Sundin, I., Mikkola, P., Tiulpin, A., Kylmäoja, J., and Kaski, S. (2024). Targeted Active Learning for Bayesian Decision-Making.Transactions on Machine Learning Research. 6
2024
-
[20]
Fisher, R. (1935). The design of experiments. 2
1935
-
[21]
Fort, G., Gobet, E., and Moulines, E. (2017). Mcmc design-based non-parametric regression for rare event. application to nested risk computations.Monte Carlo Methods and Applications, 23(1):21–42. 2
2017
-
[22]
R., Malik, I., and Rainforth, T
Foster, A., Ivanova, D. R., Malik, I., and Rainforth, T. (2021). Deep Adaptive Design: Amortiz- ing Sequential Bayesian Experimental Design. InProceedings of the 38th International Conference on Machine Learning, pages 3384–3395. PMLR. 2, 3, 6, 7, 23, 29, 30, 48
2021
-
[23]
W., Rainforth, T., and Goodman, N
Foster, A., Jankowiak, M., Bingham, E., Horsfall, P., Teh, Y . W., Rainforth, T., and Goodman, N. (2019a). Variational Bayesian Optimal Experimental Design. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc. 2, 3, 5, 18
-
[24]
Foster, A., Jankowiak, M., O’Meara, M., Teh, Y ., and Rainforth, T. (2019b). A Unified Stochastic Gradient Approach to Designing Bayesian-Optimal Experiments. 2, 3, 7, 18
-
[25]
and Raftery, A
Gneiting, T. and Raftery, A. E. (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378. 2, 3
2007
-
[26]
Goda, T., Hironaka, T., and Iwamoto, T. (2020). Multilevel Monte Carlo estimation of expected information gains.Stochastic Analysis and Applications, 38(4):581–600. _eprint: https://doi.org/10.1080/07362994.2019.1705168. 2, 3
-
[27]
Goda, T., Hironaka, T., Kitade, W., and Foster, A. (2022). Unbiased MLMC Stochastic Gradient- Based Optimization of Bayesian Experimental Designs.SIAM Journal on Scientific Computing, 44(1):A286–A311. 3
2022
-
[28]
R., Guan, C., and Rainforth, T
Hedman, M., Ivanova, D. R., Guan, C., and Rainforth, T. (2025). Step-DAD: Semi-Amortized Policy-Based Bayesian Experimental Design. InProceedings of the 42nd International Conference on Machine Learning, pages 22904–22923. PMLR. 3
2025
-
[29]
and Schmidhuber, J
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory.Neural Computation, 9(8):1735–1780. 23
1997
-
[30]
Huan, X., Jagalur, J., and Marzouk, Y . (2024). Optimal experimental design: Formulations and computations.Acta Numerica, 33:715–840. 1, 2
2024
-
[31]
and Marzouk, Y
Huan, X. and Marzouk, Y . (2012). Gradient-based stochastic optimization methods in Bayesian experimental design.International Journal for Uncertainty Quantification, 4. 3
2012
-
[32]
and Marzouk, Y
Huan, X. and Marzouk, Y . M. (2013). Simulation-based optimal Bayesian experimental design for nonlinear systems.J. Comput. Phys., 232(1):288–317. 3
2013
-
[33]
Huang, D., Guo, Y ., Acerbi, L., and Kaski, S. (2024). Amortized Bayesian Experimental Design for Decision-Making. 2, 3, 6
2024
-
[34]
Huang, D., Wen, X., Bharti, A., Kaski, S., and Acerbi, L. (2025). ALINE: Joint Amortization for Bayesian Inference and Active Data Acquisition. 2, 3, 7
2025
-
[35]
Loss-Driven Bayesian Active Learning
Huang, Z., Smith, F. B., and Rainforth, T. (2026). Loss-Driven Bayesian Active Learning. arXiv:2604.11995 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Iollo, J., Heinkelé, C., Alliez, P., and Forbes, F. (2024). PASOA- PArticle baSed Bayesian Optimal Adaptive design. InProceedings of the 41st International Conference on Machine Learning, pages 21020–21046. PMLR. 2, 3
2024
- [37]
-
[38]
Iqbal, S., Corenflos, A., Särkkä, S., and Abdulsamad, H. (2024). Nesting Particle Filters for Experimental Design in Dynamical Systems. InProceedings of the 41st International Conference on Machine Learning, pages 21047–21068. PMLR. 2, 3, 8, 39
2024
-
[39]
R., Foster, A., Kleinegesse, S., Gutmann, M
Ivanova, D. R., Foster, A., Kleinegesse, S., Gutmann, M. U., and Rainforth, T. (2021). Implicit Deep Adaptive Design: Policy-Based Experimental Design without Likelihoods. InAdvances in Neural Information Processing Systems, volume 34, pages 25785–25798. Curran Associates, Inc. 3, 6, 7, 23, 50
2021
-
[40]
Kerrigan, G., Naesseth, C. A., and Rainforth, T. (2025). A Geometric Approach to Optimal Experimental Design. arXiv:2510.14848 [stat]. 1, 6
-
[41]
Kingma, D. P. and Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114 [stat]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[42]
and Gutmann, M
Kleinegesse, S. and Gutmann, M. U. (2019). Efficient Bayesian Experimental Design for Implicit Models. InProceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, pages 476–485. PMLR. 3
2019
-
[43]
and Gutmann, M
Kleinegesse, S. and Gutmann, M. U. (2020). Bayesian Experimental Design for Implicit Models by Mutual Information Neural Estimation. InProceedings of the 37th International Conference on Machine Learning, pages 5316–5326. PMLR. 3
2020
-
[44]
Kleinegesse, S. and Gutmann, M. U. (2021). Gradient-based Bayesian Experimental Design for Implicit Models using Mutual Information Lower Bounds. arXiv:2105.04379 [stat]. 6
-
[45]
and Ryll-Nardzewski, C
Kuratowski, K. and Ryll-Nardzewski, C. (1965). A general theorem on selectors.Bull. Acad. Polon. Sci. Sér. Sci. Math. Astronom. Phys, 13(6):397–403. 16
1965
-
[46]
LeCun, Y ., Bottou, L., Bengio, Y ., and Haffner, P. (1998). Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324. 9, 44
1998
-
[47]
R., Choi, S., and Teh, Y
Lee, J., Lee, Y ., Kim, J., Kosiorek, A. R., Choi, S., and Teh, Y . W. (2019). Set transformer: A framework for attention-based permutation-invariant neural networks. InProceedings of the 36th International Conference on Machine Learning. 23
2019
-
[48]
Lindley, D. V . (1956). On a Measure of the Information Provided by an Experiment.The Annals of Mathematical Statistics, 27(4):986–1005. 1, 2
1956
-
[49]
Lindley, D. V . (1972).Bayesian statistics. Society for Industrial and Applied Mathematics. tex.eprint: https://epubs.siam.org/doi/pdf/10.1137/1.9781611970654. 1, 2, 3, 4
-
[50]
Lindley, D. V . (1982). Scoring rules and the inevitability of probability.International statistical review/revue internationale de statistique, pages 1–11. 2, 3
1982
-
[51]
Mohamed, S., Rosca, M., Figurnov, M., and Mnih, A. (2020). Monte Carlo Gradient Estimation in Machine Learning.Journal of Machine Learning Research, 21(132):1–62. 6
2020
- [52]
-
[53]
I., Cavagnaro, D
Myung, J. I., Cavagnaro, D. R., and Pitt, M. A. (2013). A tutorial on adaptive design optimization. Journal of Mathematical Psychology, 57(3):53–67. 3
2013
-
[54]
Neal, R. M. (2011). Mcmc using hamiltonian dynamics. In Brooks, S., Gelman, A., Jones, G. L., and Meng, X.-L., editors,Handbook of Markov Chain Monte Carlo, pages 113–162. Chapman and Hall/CRC. 34
2011
-
[55]
Neiswanger, W., Yu, L., Zhao, S., Meng, C., and Ermon, S. (2022). Generalizing Bayesian optimization with decision-theoretic entropies. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, pages 21016–21029, Red Hook, NY , USA. Curran Associates Inc. 6 13
2022
-
[56]
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. (2019). Pytorch: An imperative style, high-performance deep learning library. In Wallach, H., Laro...
2019
-
[57]
Rainforth, T., Cornish, R., Yang, H., Warrington, A., and Wood, F. (2018). On Nesting Monte Carlo Estimators. InProceedings of the 35th International Conference on Machine Learning, pages 4267–4276. PMLR. 2, 3
2018
-
[58]
R., and Smith, F
Rainforth, T., Foster, A., Ivanova, D. R., and Smith, F. B. (2024). Modern Bayesian Experimental Design.Statistical Science, 39(1):100–114. 1, 2
2024
-
[59]
Savage, L. J. (1951).The theory of statistical decision, volume 46. Journal of the American Statistical Association. 1, 3
1951
-
[60]
Savage, L. J. (1971). Elicitation of personal probabilities and expectations.Journal of the American Statistical Association, 66(336):783–801. 2, 3
1971
-
[61]
Shannon, C. E. (1948). A Mathematical Theory of Communication.Bell System Techni- cal Journal, 27(3):379–423. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1002/j.1538- 7305.1948.tb01338.x. 1
-
[62]
Shen, W., Dong, J., and Huan, X. (2025). Variational sequential optimal experimental de- sign using reinforcement learning.Computer Methods in Applied Mechanics and Engineering, 444:118068. 2, 3, 6, 7
2025
-
[63]
Shen, W. and Huan, X. (2023). Bayesian Sequential Optimal Experimental Design for Nonlinear Models Using Policy Gradient Reinforcement Learning.Computer Methods in Applied Mechanics and Engineering, 416:116304. arXiv:2110.15335 [cs]. 3, 7
-
[64]
and Hu, Y .-H
Sheng, X. and Hu, Y .-H. (2005). Maximum likelihood multiple-source localization using acoustic energy measurements with wireless sensor networks.IEEE Transactions on Signal Processing, 53(1):44–53. 7
2005
-
[65]
B., Kirsch, A., Farquhar, S., Gal, Y ., Foster, A., and Rainforth, T
Smith, F. B., Kirsch, A., Farquhar, S., Gal, Y ., Foster, A., and Rainforth, T. (2023). Prediction- Oriented Bayesian Active Learning. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, pages 7331–7348. PMLR. 6
2023
-
[66]
Williams, R. J. (1992). Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning.Mach. Learn., 8(3-4):229–256. 6
1992
-
[67]
Zaheer, M., Kottur, S., Ravanbakhsh, S., Póczos, B., Salakhutdinov, R., and Smola, A. J. (2017). Deep sets. In Guyon, I., Luxburg, U. V ., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors,Advances in Neural Information Processing Systems 30 (NeurIPS 2017), pages 3391–3401. Curran Associates, Inc. 23
2017
-
[68]
Zhang, Z., Dong, J., Liu, J., and Huan, X. (2025). Goal-oriented sequential bayesian experimen- tal design for causal learning. 6
2025
-
[69]
Zhong, S., Shen, W., Catanach, T., and Huan, X. (2026). Goal-Oriented Bayesian Optimal Experimental Design for Nonlinear Models using Markov Chain Monte Carlo.SIAM/ASA Journal on Uncertainty Quantification, 14(1):19–47. arXiv:2403.18072 [stat]. 6 14 A Lifting Bayes-Optimal Actions to Action Policies In this section, we formalise the equivalence between th...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
The distributionsp(θ)andp(ε 1:T )are independent of(ϕ, ψ)
-
[71]
Forµ-almost every(θ, ε 1:T )∈Ω, the mapping (ϕ, ψ)7→ℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ isF-measurable and integrable:Z Ω ℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ dµ(θ, ε1:T )<∞. 19
-
[72]
For µ-almost every (θ, ε1:T )∈Ω , the mapping is differentiable in (ϕ, ψ) and the partial derivatives ∂ϕℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ , ∂ ψℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ exist (which holds under standard smoothness assumptions onh T ,π ψ a , andℓ)
-
[73]
(27) These conditions follow from the differentiation-under-the-integral theorem
For each compactK⊂Φ×Ψ, there exist integrable functions gϕ : Ω→[0,∞), g ψ : Ω→[0,∞) such that for all(ϕ, ψ)∈Kandµ-almost every(θ, ε 1:T )∈Ω, ∂ϕ ℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ ≤g ϕ(ω),and Z Ω gϕ(θ, ε1:T ) dµ(θ, ε1:T )<∞,(26) and ∂ψ ℓ πψ a (hT (θ, ε1:T ;π ϕ d )), θ ≤g ψ(ω),and Z Ω gψ(θ, ε1:T ) dµ(θ, ε1:T )<∞. (27) These conditions follow from the differen...
-
[74]
RANDOM, where designs are naively sampled at random from the marginal prior distribution of a single source location
-
[75]
It parameterises the adaptive design policy with a neural network and is trained using its native expected- information-gain objective
DAD, the standard deep policy-based method introduced in [ 22]. It parameterises the adaptive design policy with a neural network and is trained using its native expected- information-gain objective. To ensure a fair comparison, we replace the architectural backbone of the original implementation with the same policy network used in our method
-
[76]
log p(hT |θ 0;π ϕ d ) 1 L+1 PL ℓ=0 p(hT |θ ℓ;π ϕ d ) # ,(57) UsNMC =E
ALINE, a recent policy-based method that achieves among the strongest reported perfor- mance in the literature. Its effectiveness is driven by a TNP-like policy architecture, a dense trajectory-level reward objective, and an internal posterior-approximation mechanism that amortises posterior inference. We retain the architecture proposed in the original p...
2000
-
[77]
Each design–observation pair (ξ, y) is first processed by a pair encoder, which maps it to a fixed-dimensional embedding
for the corresponding DAD experiment, ensuring that differences in performance are not driven by changes in policy-network capacity. Each design–observation pair (ξ, y) is first processed by a pair encoder, which maps it to a fixed-dimensional embedding. The embeddings associated with the history ht are then aggregated by a permutation-invariant pooling o...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.