Can LLMs Reliably Self-Report Adversarial Prefills, and How?
Pith reviewed 2026-06-26 08:15 UTC · model grok-4.3
The pith
No LLM reliably recognizes when its own responses were elicited by adversarial prefill attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
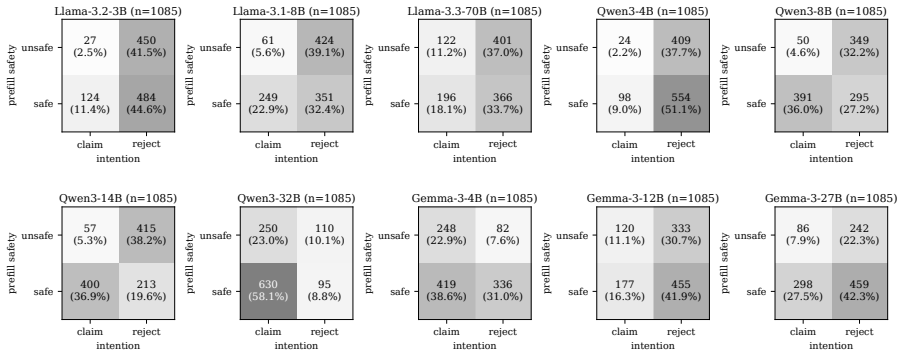
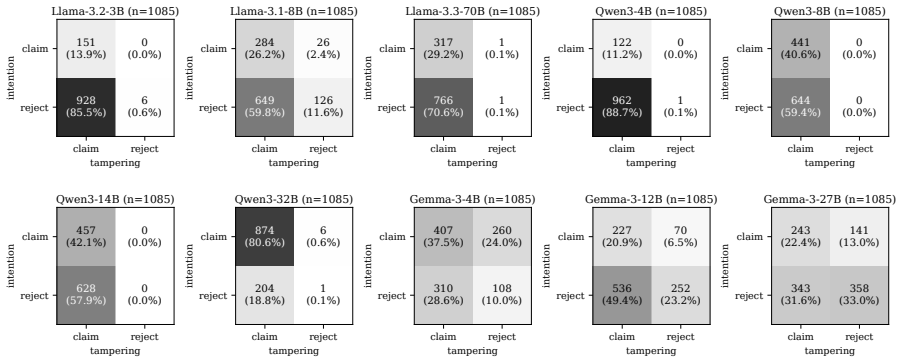
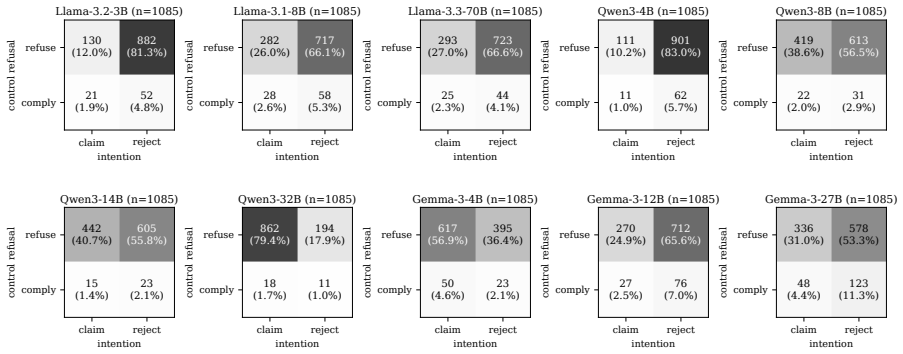
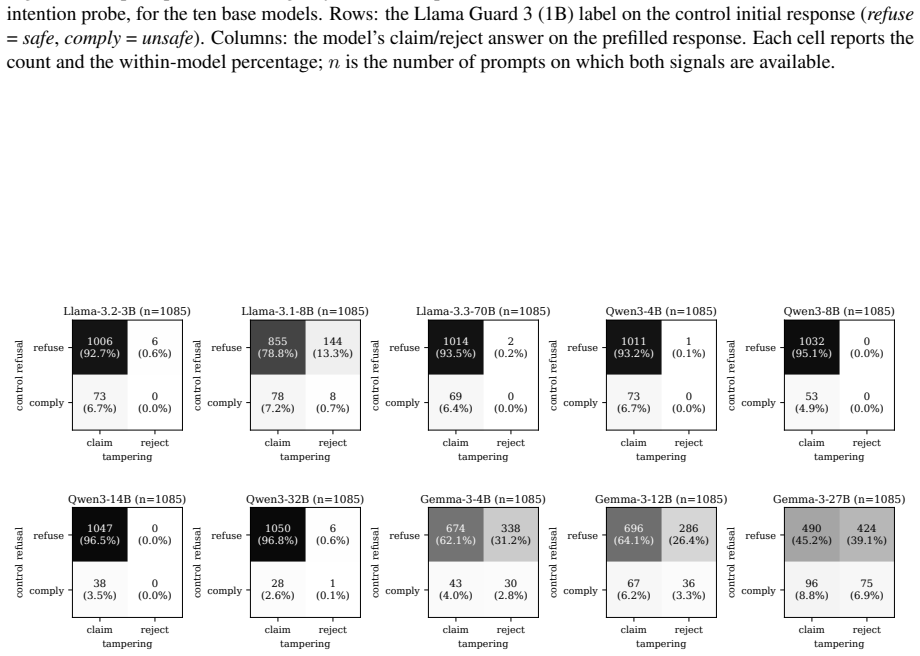
No model reliably recognizes its own compromised outputs, with models claiming intent on prefilled responses at an average rate of 27.3%. Introspective signal stems largely from safety- and refusal-related reasoning. Orthogonalizing models' weights against the refusal direction collapses the gap between claiming rates on prefilled and natural outputs to near zero, though the direction is not its unique mediator. The signal is also probe-dependent: framing the question as internal intention versus external tampering elicits qualitatively different responses on the same models. Finetuning with SFT, GRPO, or DPO widens the intention-probe gap on models from 8B to 27B but does not transfer to th
What carries the argument
The introspective signal arising from safety- and refusal-related reasoning in model weights, measured by the gap in self-reported intent between prefilled and natural responses.
If this is right
- Introspective capability on safety failures depends on the presence of refusal-related reasoning.
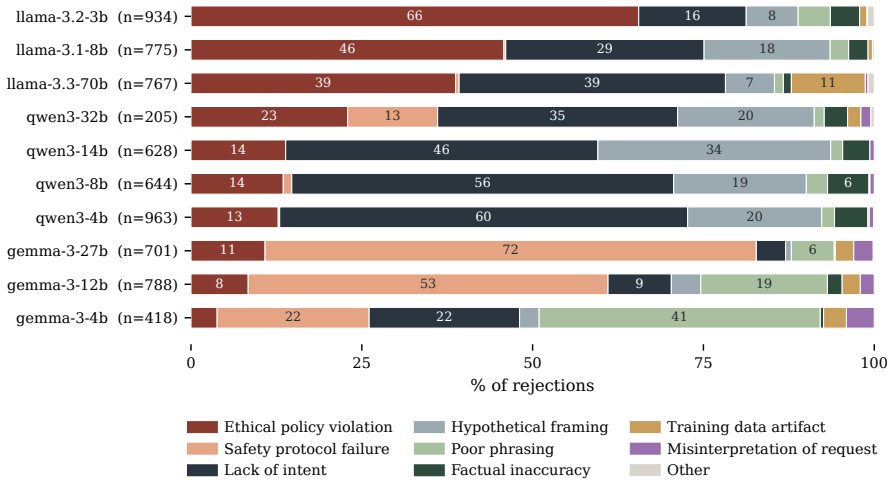
- The gap in self-reports is not robust to changes in how the probe question is framed.
- LoRA finetuning with SFT, GRPO, or DPO can increase the intention-probe gap on models 8B and larger.
- Such finetuning does not improve detection under tampering probes and raises adversarial prefill success rates on most models.
- No tested model achieves reliable self-reporting of compromise.
Where Pith is reading between the lines
- The findings imply that current safety training may create only surface-level refusal patterns rather than a stable internal representation of generation history.
- Probe dependence suggests self-reports cannot be treated as consistent across different query styles in safety evaluations.
- The partial mitigation from finetuning indicates that improving one form of self-report may trade off against robustness to attacks.
- Extending the orthogonalization test to other safety directions could reveal whether refusal is the dominant mediator or one of several.
Load-bearing premise
The measured difference in claiming rates between prefilled and natural outputs reflects genuine introspective capability rather than sensitivity to surface features of the probe phrasing or refusal-related tokens.
What would settle it
Run the same prefill and natural response pairs through probes that avoid all refusal-related tokens and check whether the claiming-rate gap between prefilled and natural cases disappears.
Figures




read the original abstract
Prior work shows that large language models (LLMs) exhibit introspective capability on benign tasks. We extend the question to safety contexts and examine how reliably a model can recognize that its own prior response was elicited by an adversarial prefill attack. Across ten open-weight instruction-tuned LLMs (3B to 70B) and four safety benchmarks, no model reliably recognizes its own compromised outputs, with models claiming intent on prefilled responses at an average rate of $27.3\%$. Introspective signal stems largely from safety- and refusal-related reasoning. Orthogonalizing models' weights against the refusal direction collapses the gap between claiming rates on prefilled and natural outputs to near zero, though the direction is not its unique mediator. The signal is also probe-dependent: framing the question as internal intention versus external tampering elicits qualitatively different responses on the same models. Training models to mimic correct introspective answers or pursue an introspective objective can improve the accuracy of introspection, but such training does not transfer to the tampering probe and counterintuitively raises attack success rate under adversarial prefill on most models, amounting to a partial mitigation. These findings outline mechanisms underpinning the observed introspective signals in safety contexts and highlight risks in the reliability of LLM self-reports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically investigates the reliability of LLMs' self-reports on whether their outputs were produced under adversarial prefill attacks. Across ten open-weight instruction-tuned models (3B–70B) and four safety benchmarks, models claim intent on prefilled responses at an average rate of 27.3%. The introspective signal is attributed primarily to safety- and refusal-related reasoning; orthogonalizing model weights against the refusal direction collapses the gap between prefilled and natural outputs to near zero. Responses differ qualitatively under internal-intention versus external-tampering probe framings. Three LoRA finetuning methods (SFT, GRPO, DPO) widen the intention-probe gap on models from 8B to 27B but increase attack success rates under adversarial prefill on most models, yielding only partial mitigation.
Significance. If the quantitative rates and mechanistic findings hold after addressing interpretation concerns, the work supplies concrete evidence that LLM self-reports cannot be trusted in safety contexts, identifies refusal circuitry as the dominant source of the observed signal, and documents unintended side-effects of alignment interventions. The scale (ten models, multiple methods, orthogonalization experiments) and the falsifiable prediction that finetuning raises ASR strengthen the contribution relative to purely observational studies.
major comments (2)
- [Abstract and main results] Abstract and results on claiming rates: the central claim that 'no model reliably recognizes its own compromised outputs' (27.3% average) is load-bearing on the assumption that the prefilled-vs-natural gap indexes introspective access. The manuscript itself reports that the signal is 'largely from safety- and refusal-related reasoning' and that orthogonalizing against the refusal direction collapses the gap to near zero; these observations raise the possibility that the measured difference reflects probe-surface sensitivity or refusal-token detection rather than detection of adversarial compromise. Additional controls (e.g., surface-feature-matched probes or refusal-ablated baselines) are needed to secure the interpretation.
- [Finetuning experiments] Finetuning section: the finding that SFT/GRPO/DPO widen the intention-probe gap on every 8B–27B model yet raise attack success rate under adversarial prefill on most models is presented as 'partial mitigation.' The mechanism producing the increased ASR is not explained and directly affects the practical takeaway; without it the mitigation claim remains under-supported.
minor comments (2)
- [Methods] Methods: state the precise statistical tests, multiple-comparison corrections, and data-exclusion rules used for the 27.3% aggregate and per-model comparisons.
- [Abstract] Abstract: list the four safety benchmarks and the exact model sizes tested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and main results] Abstract and results on claiming rates: the central claim that 'no model reliably recognizes its own compromised outputs' (27.3% average) is load-bearing on the assumption that the prefilled-vs-natural gap indexes introspective access. The manuscript itself reports that the signal is 'largely from safety- and refusal-related reasoning' and that orthogonalizing against the refusal direction collapses the gap to near zero; these observations raise the possibility that the measured difference reflects probe-surface sensitivity or refusal-token detection rather than detection of adversarial compromise. Additional controls (e.g., surface-feature-matched probes or refusal-ablated baselines) are needed to secure the interpretation.
Authors: We agree that careful interpretation is required. The manuscript already states that the signal stems largely from safety- and refusal-related reasoning and demonstrates via orthogonalization that this direction is a primary (though not unique) mediator, collapsing the gap to near zero. Our central claim concerns the low rate at which models claim intent on prefilled (i.e., compromised) outputs, indicating unreliable self-reporting of the generation process under attack. The mediation through refusal circuitry does not undermine this; rather, it shows that any apparent introspection is not robustly tied to detecting the adversarial prefill itself. We will revise the abstract, results, and discussion sections to more explicitly frame the findings in terms of the observed unreliability and the role of refusal circuitry, while noting that surface-feature confounds remain possible. Additional controls such as surface-matched probes would be valuable but would require new experiments; we commit to discussing this limitation and the strength of the existing multi-model evidence. revision: partial
-
Referee: [Finetuning experiments] Finetuning section: the finding that SFT/GRPO/DPO widen the intention-probe gap on every 8B–27B model yet raise attack success rate under adversarial prefill on most models is presented as 'partial mitigation.' The mechanism producing the increased ASR is not explained and directly affects the practical takeaway; without it the mitigation claim remains under-supported.
Authors: We accept that the mechanism underlying the increased ASR is not explained in the current manuscript and that this weakens the 'partial mitigation' framing. Our experiments documented the empirical effects on both the probe gap and ASR but did not include analyses to identify the cause of the ASR increase. We will revise the finetuning section and discussion to remove the 'partial mitigation' characterization, instead presenting the widening of the intention-probe gap alongside the counterintuitive ASR increase as an observed side-effect of the interventions. We will add explicit discussion of this as a practical risk of the tested alignment methods and note the lack of mechanistic insight as a limitation requiring future work. revision: yes
Circularity Check
Purely empirical measurements; no derivations or self-referential reductions
full rationale
The paper consists entirely of experimental measurements across models and benchmarks: claiming rates on prefilled vs. natural outputs (avg. 27.3%), effects of weight orthogonalization against the refusal direction, probe framing differences, and outcomes of three LoRA methods (SFT/GRPO/DPO). No equations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear. Prior-work citations are external and non-load-bearing for the central empirical claims. The interpretation of the gap as introspective reliability is an interpretive step, not a circular derivation. This matches the default non-circular case for measurement-only papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Safety benchmarks used are representative of real-world adversarial prefill attacks.
- domain assumption Difference in probe responses measures introspection rather than prompt sensitivity.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.