Random coloured digraphs defined by a Markov logic network
Pith reviewed 2026-06-26 21:55 UTC · model grok-4.3
The pith
Scaling weights by 1/n in an MLN with all Boolean combinations of P(x) and R(x,y) as soft constraints produces a 0-1 law for first-order logic whose limit is independent of the weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
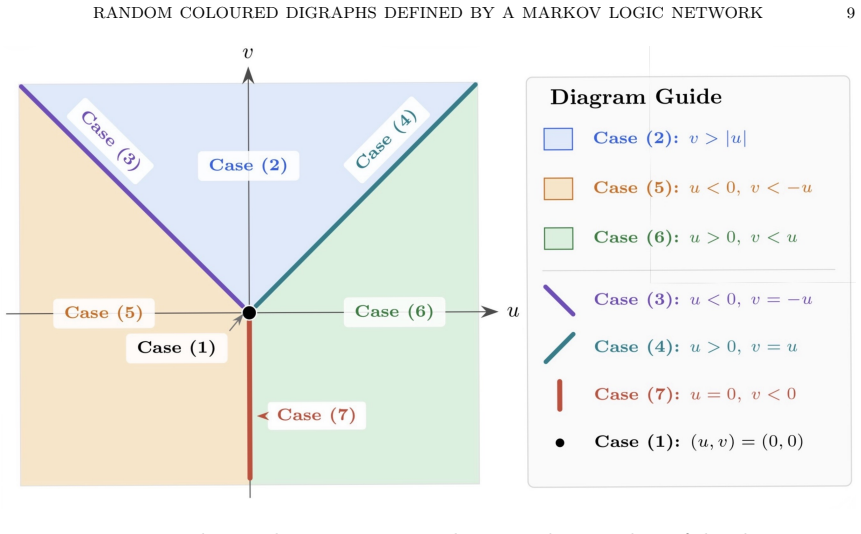
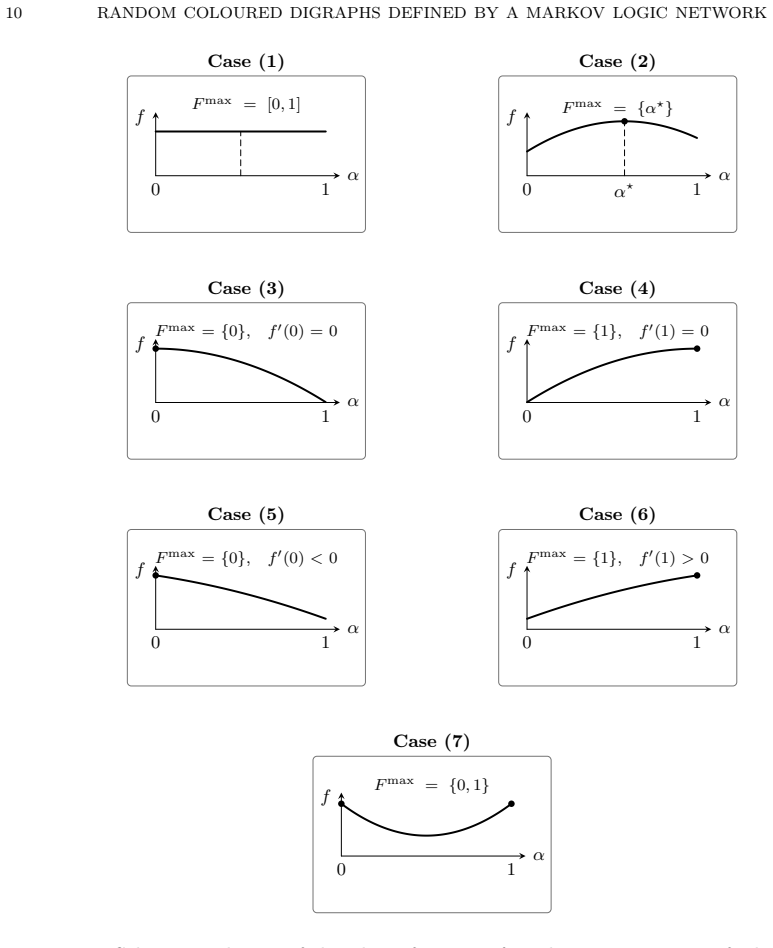
For an MLN that includes every Boolean combination of P(x) and R(x,y) as a soft constraint, scaling all weights by 1/n makes the probability of any first-order sentence tend to 0 or 1 as n tends to infinity, and this limit probability is the same for every choice of nonnegative weights. With unscaled weights the model exhibits one of seven qualitatively different asymptotic regimes whose character depends on the weights; in some regimes a 0-1 law holds, in others only a convergence law holds, and changes in the weights can produce abrupt transitions between regimes.
What carries the argument
The exhaustive collection of soft constraints, one for each Boolean combination of the atoms P(x) and R(x,y), together with the uniform 1/n scaling applied to their weights.
If this is right
- The limiting probability of every first-order sentence is determined only by the logical form of the sentence, not by the numerical values of the weights.
- Unscaled weights produce up to seven distinct asymptotic regimes whose boundaries are crossed by continuous variation of the weights.
- In some unscaled regimes a convergence law still holds even though the limit is not 0 or 1.
- Inference tasks on large domains become insensitive to exact weight values once scaling by 1/n is applied.
Where Pith is reading between the lines
- The scaled model is asymptotically equivalent to a uniform distribution over a certain class of colored digraphs whose edge and vertex colors are governed by the same Boolean combinations.
- The seven unscaled regimes may correspond to different dominance orders among the weighted formulas, each producing its own limiting random structure.
- The same exhaustive-constraint construction could be tested on signatures with more than one binary relation to see whether the 0-1 law survives.
Load-bearing premise
The MLN includes every Boolean combination of P(x) and R(x,y) as a soft constraint with its own nonnegative weight.
What would settle it
A first-order sentence whose probability, under weights scaled by 1/n, tends to a number strictly between 0 and 1 for some positive weight vector, or tends to different limits for two different positive weight vectors.
Figures
read the original abstract
A Markov Logic Network (MLN) is a probabilistic relational model used in Statistical Relational Artificial Intelligence for defining a probability distribution on the set of possible worlds with domain $D$ for an arbitrary finite domain $D$. An MLN consists of soft constraints with associated weights which are nonnegative real numbers. In this study we consider a language speaking about a property $P(x)$ and a relation $R(x, y)$. We consider an MLN for which every Boolean combination of $P(x)$ and $R(x, y)$ is a soft constraint (with associated weight). Let $n$ denote the size (cardinality) of the domain. We show that, for every choice of weights, if the weights are scaled by $1/n$ then, for every first-order sentence $\varphi$, the probability that $\varphi$ holds tends to either 0 or 1 as $n \to \infty$; that is, a 0-1 law for first-order logic holds. Morover, the limit probability does {\em not} depend on the weights. If we instead use the standard semantics of MLNs, in the case of which the weights are {\em not} scaled, then the limit behaviour is more complicated and {\em depends} on the weights. With unscaled weights we get 7 qualitatively different cases which depend on the weights. In some cases we have a 0-1 law for first-order logic, in some cases not, but we may still have a convergence law. The influence of the weights on the asymptotic probability of a first-order sentence may be in the form of a sudden ``phase transition'' from one of the 7 cases to another. The presence of a convergence law has positive implications for inference on large domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies Markov Logic Networks over a language with unary predicate P(x) and binary relation R(x,y) in which every Boolean combination of these symbols appears as a soft constraint with an associated nonnegative real weight. The central results are: (i) when all weights are scaled by 1/n, every first-order sentence has limiting probability 0 or 1 as n o∞ and the limit is independent of the particular choice of weights; (ii) when weights are left unscaled, the asymptotic regime falls into one of seven qualitatively distinct cases determined by the weights, some of which obey a 0-1 law, others a convergence law but not 0-1, with possible phase transitions between cases as weights vary. The modeling premise (exhaustive constraint set) is stated explicitly and the scaled versus unscaled regimes are contrasted throughout.
Significance. If the theorems hold, the work supplies a new, explicitly constructed family of random relational structures whose limiting FO theory is weight-independent under 1/n scaling, thereby extending classical 0-1 laws (e.g., for the Erdős–Rényi graph) to a soft-constraint probabilistic setting. The exhaustive-constraint hypothesis is shown to be load-bearing for the independence result. The seven-case taxonomy for the unscaled regime, together with the observation that convergence laws remain useful for large-domain inference even when 0-1 fails, constitutes a concrete contribution to the interface between statistical relational AI and finite-model theory. The paper ships a clean separation of regimes and an explicit modeling premise; both are strengths.
minor comments (2)
- [Introduction] The abstract states the seven cases only at a high level; a brief enumerated summary of the seven regimes (with the relevant weight conditions) already in the introduction would improve readability for readers outside statistical relational AI.
- [§2] Notation for the MLN distribution (e.g., the precise normalization constant and the product over all groundings) is introduced only after the statement of the main theorems; moving the formal definition of the probability measure to §2 would make the subsequent limit statements easier to parse.
Simulated Author's Rebuttal
We thank the referee for their careful reading and positive recommendation to accept the manuscript. The provided summary accurately captures both the scaled-weight 0-1 law (weight-independent) and the seven-regime taxonomy for unscaled weights.
Circularity Check
No circularity: direct proof of weight-independent 0-1 law from exhaustive MLN definition
full rationale
The paper defines an MLN that includes every Boolean combination of P(x) and R(x,y) as a soft constraint, then derives the 0-1 law for FO sentences under 1/n weight scaling as a mathematical consequence of that model. The limit is shown to be independent of specific weights by explicit asymptotic analysis of the probability measure; no parameter is fitted to data and then reused as a prediction, no self-citation chain is load-bearing, and the unscaled case is treated separately with explicit case distinctions. The derivation is self-contained against the model axioms and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math First-order sentences have well-defined truth values in finite structures of size n
Reference graph
Works this paper leans on
-
[1]
Sam Adam-Day, Theodor-Mihai Iliant, İsmail İlkan Ceylan, Zero-One Laws of Graph Neural Networks, inAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023, 70733–70756,https: //doi.org/10.52202/075280-3099
-
[2]
Sam Adam-Day, Michael Benedikt, İsmail İlkan Ceylan, Ben Finkelshtein, Almost Surely Asymptot- ically Constant Graph Neural Networks, inAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024, 124843–124886,https://doi.org/10.52202/079017-3965
-
[3]
Sam Adam-Day, Michael Benedikt, Alberto Larrauri, Convergence Laws for Extensions of First-Order Logic with Averaging, inProceedings of the 40th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS 2025), IEEE (2025), 818–830,https://doi.org/10.1109/LICS65433.2025.00067
-
[4]
Guy Van den Broeck, Kristian Kersting, Sriraam Natarajan, David Poole (editors),An Introduction to Lifted Probabilistic Inference, MIT Press (2021),https://doi.org/10.7551/mitpress/10548.001. 0001
-
[5]
Research Track, ECML PKDD 2024, Part VII, Lecture Notes in Computer Science, vol
Florian Chen, Felix Weitkämper, Sagar Malhotra, Understanding Domain-Size Generalization in Markov Logic Networks, inMachine Learning and Knowledge Discovery in Databases. Research Track, ECML PKDD 2024, Part VII, Lecture Notes in Computer Science, vol. 14947, Springer (2024), 297– 314,https://doi.org/10.1007/978-3-031-70368-3_18. RANDOM COLOURED DIGRAPHS...
-
[6]
Fabio G. Cozman, Denis D. Mauá, The finite model theory of Bayesian network specifications: De- scriptive complexity and zero/one laws,International Journal of Approximate Reasoning, vol. 110 (2019), 107–126,https://doi.org/10.1016/j.ijar.2019.04.003
-
[7]
Luc De Raedt, Kristian Kersting, Sriraam Natarajan, David Poole,Statistical Relational Artificial Intelligence: Logic, Probability, and Computation, Morgan & Claypool Publishers (2016),https: //doi.org/10.2200/S00692ED1V01Y201601AIM032
-
[8]
Pedro Domingos, Daniel Lowd, Unifying logical and statistical AI with Markov logic,Communications of the ACM, vol. 62, no. 7 (2019), 74–83,https://doi.org/10.1145/3241978
-
[9]
Heinz-Dieter Ebbinghaus, Jörg Flum,Finite Model Theory, second revised and enlarged edition, Springer, 1999,https://doi.org/10.1007/3-540-28788-4
-
[10]
Ronald Fagin, Probabilities on finite models,The Journal of Symbolic Logic, vol. 41, no. 1 (1976), 50–58,https://doi.org/10.1017/S0022481200051756
-
[11]
Lise Getoor, Ben Taskar (editors),Introduction to Statistical Relational Learning, MIT Press (2007), https://doi.org/10.7551/mitpress/7432.001.0001
-
[12]
Manfred Jaeger, Convergence results for relational Bayesian networks, inProceedings of the Thirteenth Annual IEEE Symposium on Logic in Computer Science (LICS 1998), IEEE Computer Society (1998), 44–55,https://doi.org/10.1109/LICS.1998.705642
-
[13]
Manfred Jaeger, Oliver Schulte, A Complete Characterization of Projectivity for Statistical Relational Models, inProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Christian Bessière (editor), International Joint Conferences on Artificial Intelligence Or- ganization (2020), 4283–4290,https://doi.org/10.24...
-
[14]
215, IOS Press (2010), 937–942, https://doi.org/10.3233/978-1-60750-606-5-937
Dominik Jain, Andreas Barthels, Michael Beetz, Adaptive Markov logic networks: Learning statistical relational models with dynamic parameters, inECAI 2010: 19th European Conference on Artificial Intelligence, Frontiers in Artificial Intelligence and Applications, vol. 215, IOS Press (2010), 937–942, https://doi.org/10.3233/978-1-60750-606-5-937
-
[15]
99 (2015), 1–45,https://doi.org/10.1007/s10994-014-5443-2
Angelika Kimmig, Lilyana Mihalkova, Lise Getoor, Lifted graphical models: A survey,Machine Learn- ing, vol. 99 (2015), 1–45,https://doi.org/10.1007/s10994-014-5443-2
-
[16]
Daphne Koller, Nir Friedman,Probabilistic Graphical Models: Principles and Techniques, MIT Press (2009),https://dl.acm.org/doi/book/10.5555/1795555
-
[17]
Displaying trees across two phylogenetic networks
Vera Koponen, Conditional probability logic, lifted Bayesian networks, and almost sure quantifier elimination,Theoretical Computer Science, vol. 848 (2020), 1–27,https://doi.org/10.1016/j.tcs. 2020.08.006
-
[18]
Vera Koponen, Random expansions of finite structures with bounded degree,Annals of Pure and Applied Logic, vol. 177, no. 3 (2026), 103665,https://doi.org/10.1016/j.apal.2025.103665
-
[19]
Vera Koponen, Domain size asymptotics for Markov logic networks, arXiv:2509.04192v2 [cs.AI], 2026, https://doi.org/10.48550/arXiv.2509.04192
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.04192 2026
-
[20]
1040 (2025), 115201,https://doi.org/10.1016/j.tcs.2025.115201
Vera Koponen, Yasmin Tousinejad, Random expansions of trees with bounded height,Theoretical Computer Science, vol. 1040 (2025), 115201,https://doi.org/10.1016/j.tcs.2025.115201
-
[21]
293 (2023), 105061,https://doi
VeraKoponen, FelixWeitkämper, Asymptoticeliminationofpartiallycontinuousaggregationfunctions in directed graphical models,Information and Computation, vol. 293 (2023), 105061,https://doi. org/10.1016/j.ic.2023.105061
-
[22]
Vera Koponen, Felix Weitkämper, On the relative asymptotic expressivity of inference frameworks, Logical Methods in Computer Science, vol. 20, no. 4 (2024), 13:1–13:52,https://doi.org/10.46298/ lmcs-20(4:13)2024
2024
-
[23]
13717, Springer (2023), 223–238,https://doi.org/10.1007/978-3-031-26419-1_14
Sagar Malhotra, Luciano Serafini, On Projectivity in Markov Logic Networks, inMachine Learning and Knowledge Discovery in Databases, ECML PKDD 2022, Part V, Lecture Notes in Computer Science, vol. 13717, Springer (2023), 223–238,https://doi.org/10.1007/978-3-031-26419-1_14
-
[24]
89, PMLR (2019), 3216–3224,https://proceedings.mlr.press/v89/mittal19a.html
Happy Mittal, Ayush Bhardwaj, Vibhav Gogate, Parag Singla, Domain-size aware Markov logic net- works, in Kamalika Chaudhuri, Masashi Sugiyama (editors),Proceedings of the Twenty-Second In- ternational Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Re- search, vol. 89, PMLR (2019), 3216–3224,https://proceedings.mlr.pr...
2019
-
[25]
8720, Springer (2014), 292–305,https://doi.org/10.1007/978-3-319-11508-5_ 25
David Poole, David Buchman, Seyed Mehran Kazemi, Kristian Kersting, Sriraam Natarajan, Popula- tionsizeextrapolationinrelationalprobabilisticmodelling, inUmbertoStraccia, AndreaCalì(editors), Scalable Uncertainty Management: 8th International Conference (SUM 2014), Lecture Notes in Com- puter Science, vol. 8720, Springer (2014), 292–305,https://doi.org/10...
-
[26]
62 (2006), 107–136,https://doi.org/10.1007/s10994-006-5833-1
Matthew Richardson, Pedro Domingos, Markov logic networks,Machine Learning, vol. 62 (2006), 107–136,https://doi.org/10.1007/s10994-006-5833-1
-
[27]
Herbert Robbins, A remark on Stirling’s formula,The American Mathematical Monthly, vol. 62, no. 1 (1955), 26–29,https://doi.org/10.2307/2308012. 46 RANDOM COLOURED DIGRAPHS DEFINED BY A MARKOV LOGIC NETWORK
-
[28]
James P. Sethna,Statistical Mechanics: Entropy, Order Parameters, and Complexity, second edition, Oxford University Press (2021),https://doi.org/10.1093/oso/9780198865247.001.0001
-
[29]
Felix Q. Weitkämper, An asymptotic analysis of probabilistic logic programming, with implications for expressing projective families of distributions,Theory and Practice of Logic Programming, vol. 21, no. 6 (2021), 802–817,https://doi.org/10.1017/S1471068421000314
-
[30]
80 (2024), 1407–1436,https: //doi.org/10.1613/JAIR.1.15679
Felix Weitkämper, Probabilities of the Third Type: Statistical Relational Learning and Reasoning with Relative Frequencies,Journal of Artificial Intelligence Research, vol. 80 (2024), 1407–1436,https: //doi.org/10.1613/JAIR.1.15679
-
[31]
symmetric
Felix Q. Weitkämper, Scaling the weight parameters in Markov logic networks and relational lo- gistic regression models,Machine Learning, vol. 114 (2025), article 85,https://doi.org/10.1007/ s10994-024-06635-7. AppendixA.Proof of Lemma 6.5 Recall the formulation of Lemma 6.5: (a) IfF max ={0}andf ′(0) = 0then, for allε∈(0, 1 2), lim n→∞ Pn A ∈W n : 1−ε 2|...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.