One Generator, Any Process: LLM-Conditioning for the LHC
Pith reviewed 2026-06-26 07:52 UTC · model grok-4.3
The pith
Pre-trained LLMs supply conditioning embeddings that let one autoregressive network generate events for any LHC process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conditioning an autoregressive transformer with embeddings from pre-trained LLMs for continuous parameters, process labels, and Feynman diagrams makes the generative network converge faster, match target distributions more closely, and produce valid events for processes absent from its training data.
What carries the argument
Descriptive embeddings from pre-trained LLMs that encode physics details and are fed as conditioning signals to the autoregressive transformer generator.
If this is right
- Training time drops because shared high-level patterns are supplied by the embeddings rather than learned from scratch.
- Event samples achieve higher fidelity to reference distributions across multiple processes.
- A trained model can be applied directly to new processes without retraining or architecture changes.
- The same conditioning pipeline works for parameter scans, label switches, and diagram inputs.
Where Pith is reading between the lines
- The method could reduce the need to maintain separate generator instances for each analysis channel at the LHC.
- If the embeddings capture process structure, the same scheme might transfer to other simulation domains that use diagram or label inputs.
Load-bearing premise
Embeddings produced by general-purpose pre-trained LLMs already contain enough transferable physics structure to improve convergence and allow generalization without any domain-specific retraining of the language model.
What would settle it
Train identical generators with and without LLM embeddings on the same set of processes, then evaluate both on a process completely withheld from training; if the LLM-conditioned version shows no gain in sample quality or training speed, the central claim is false.
Figures
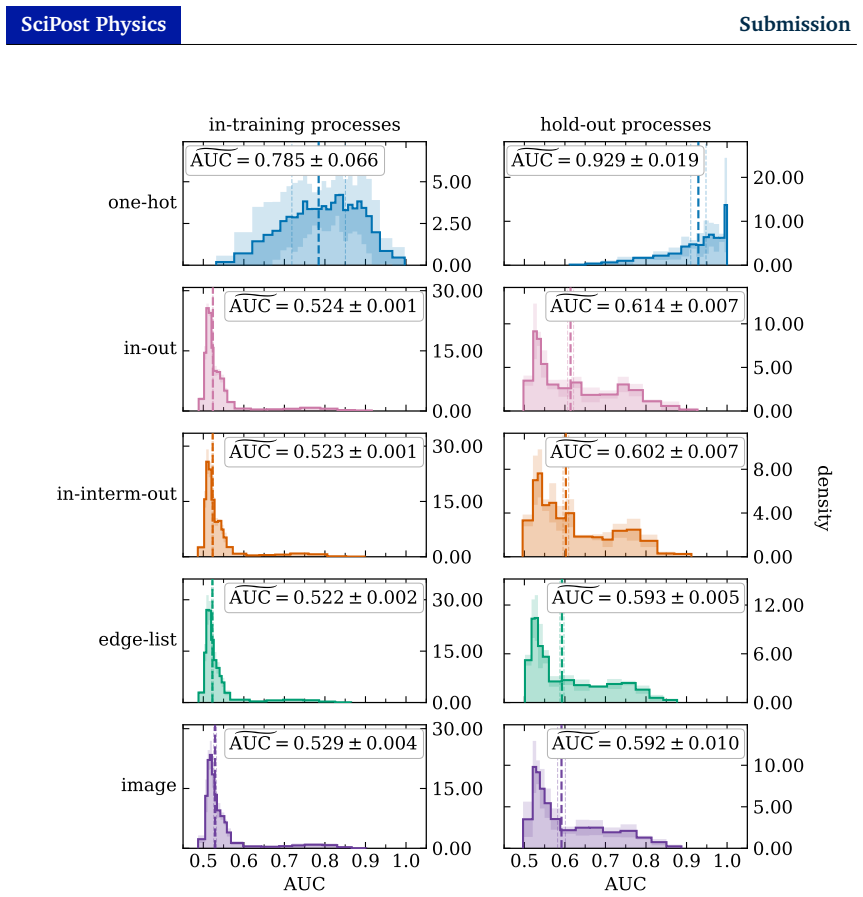
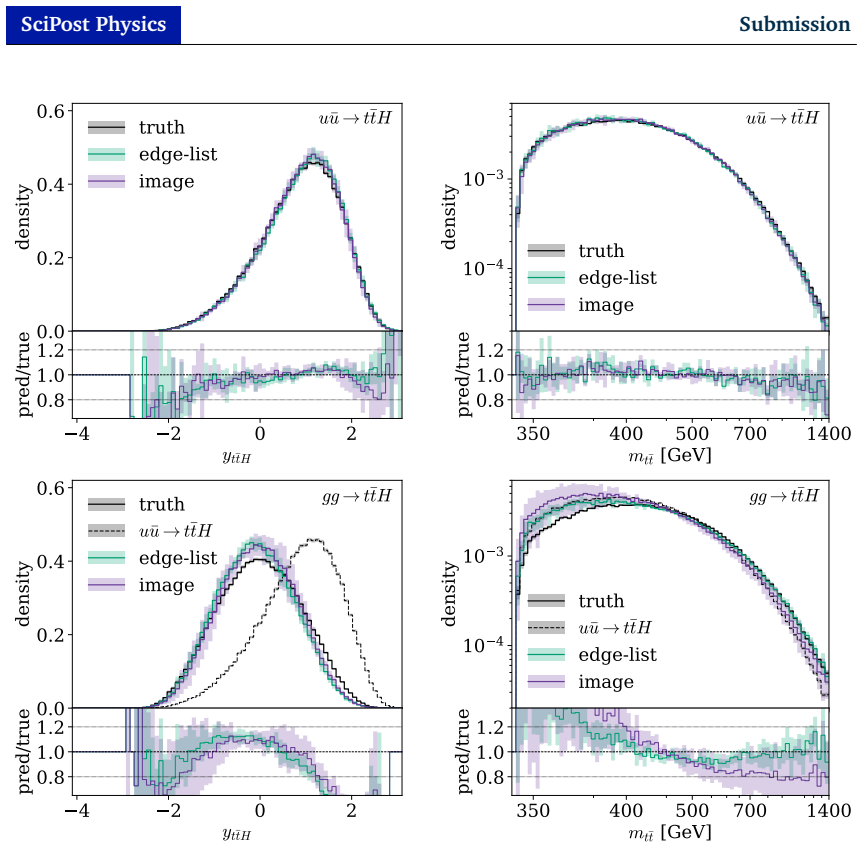
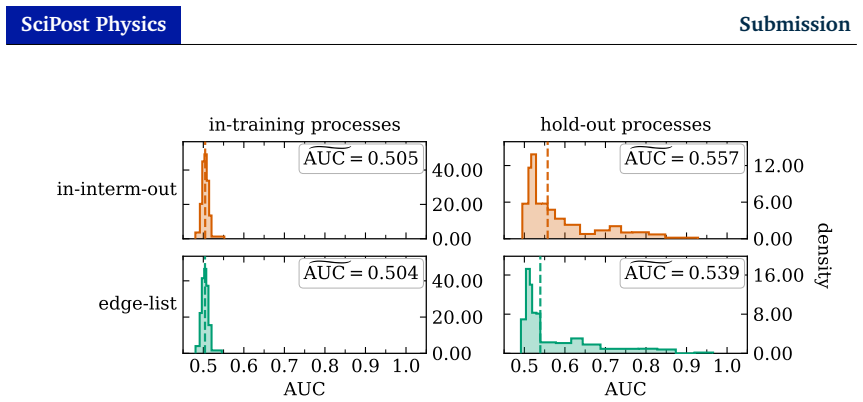
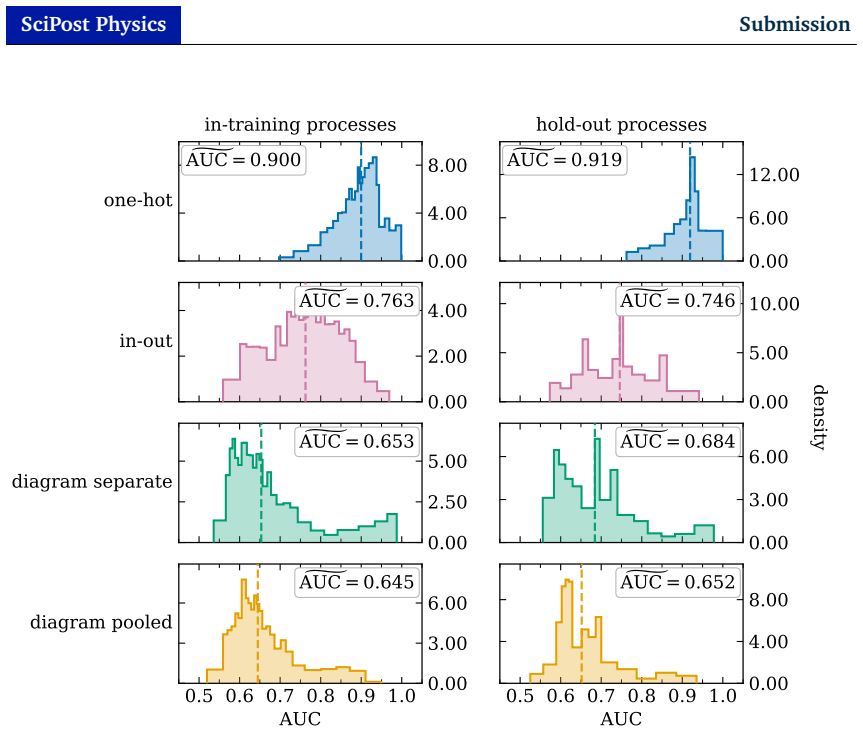
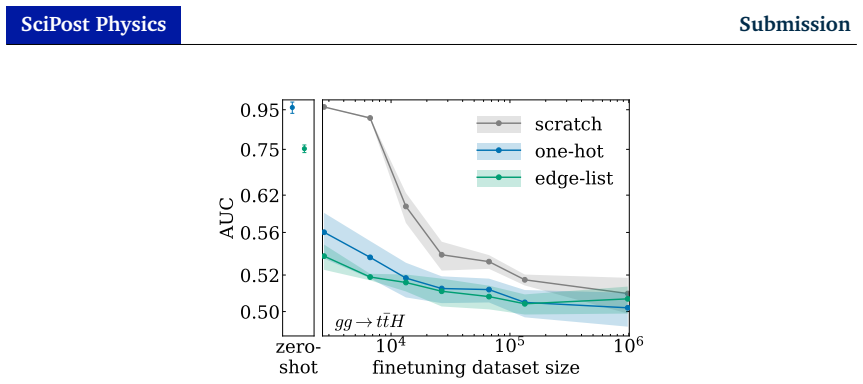
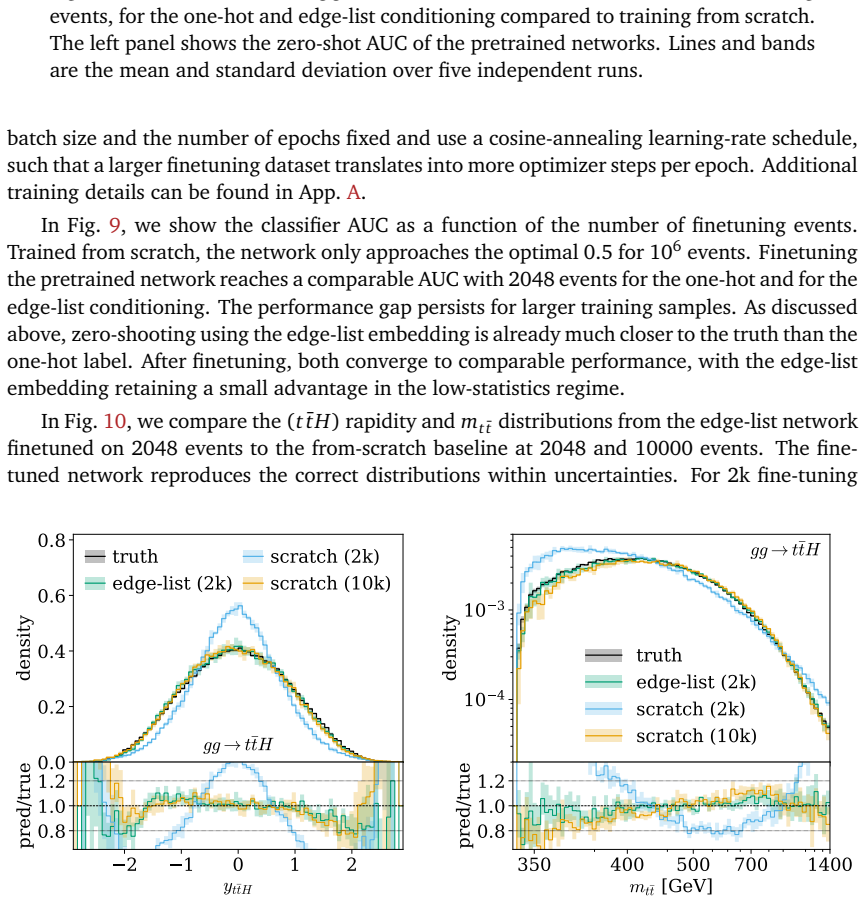
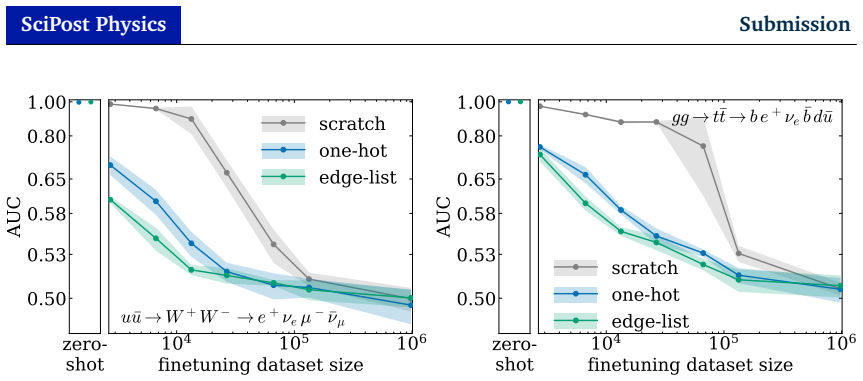
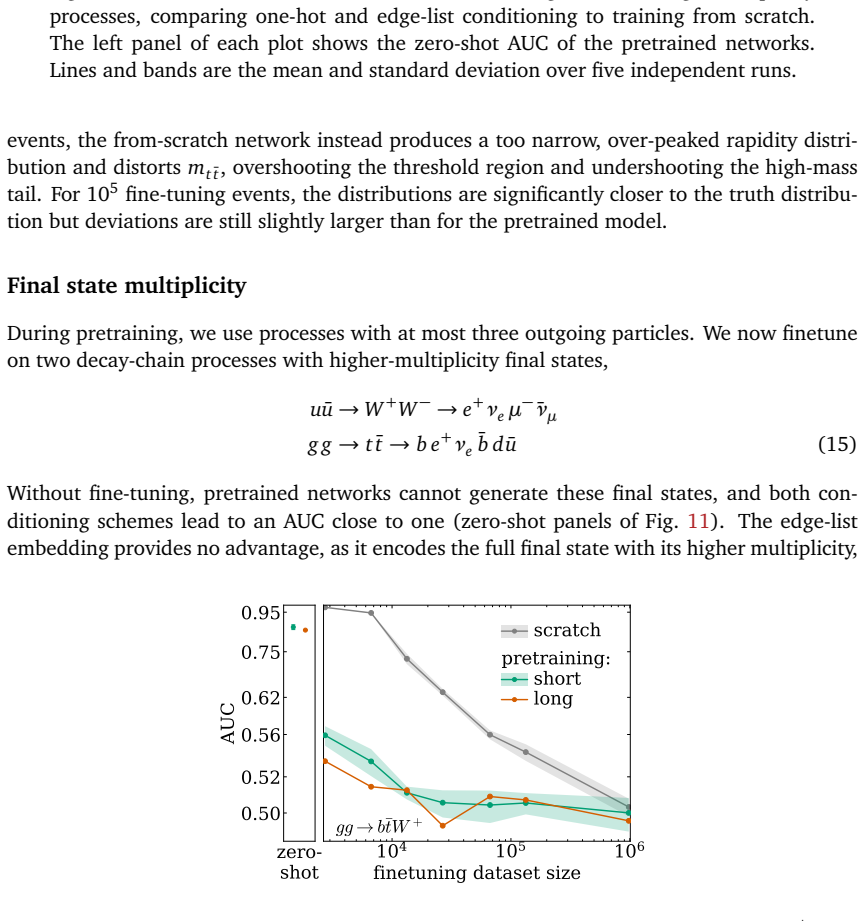


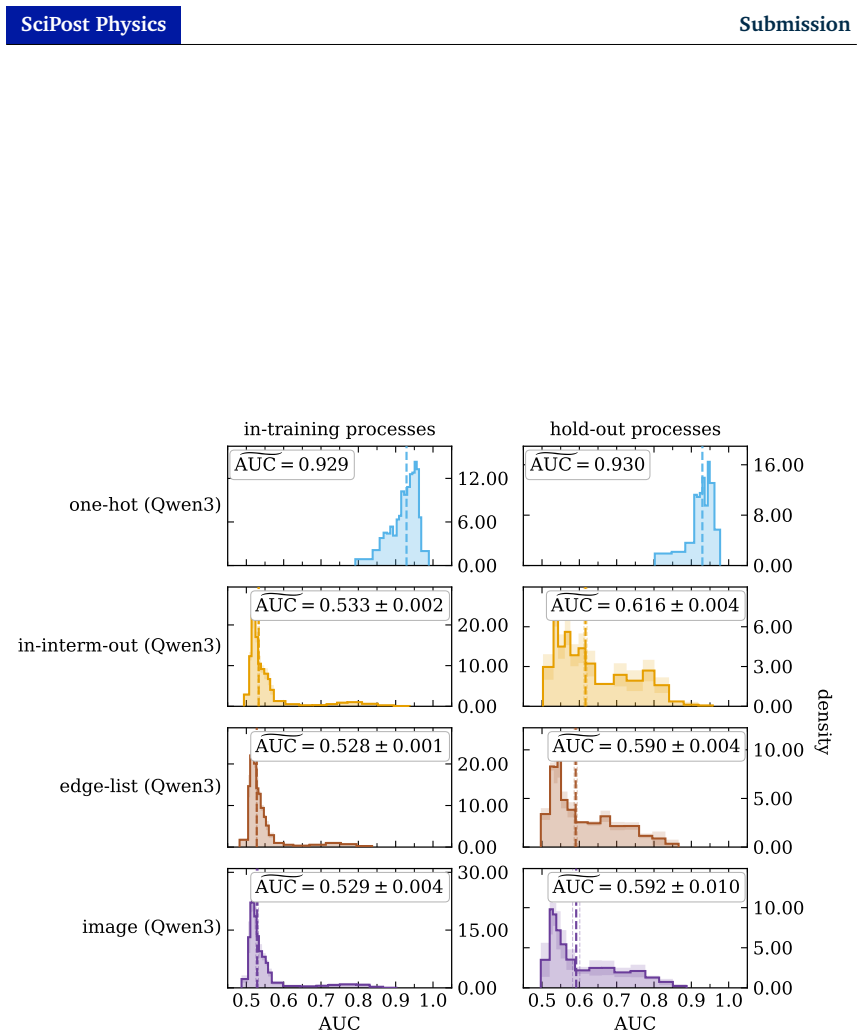

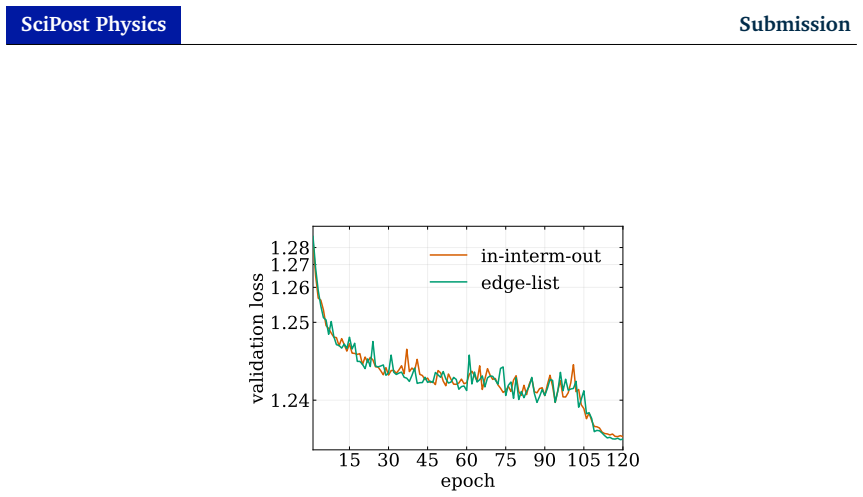
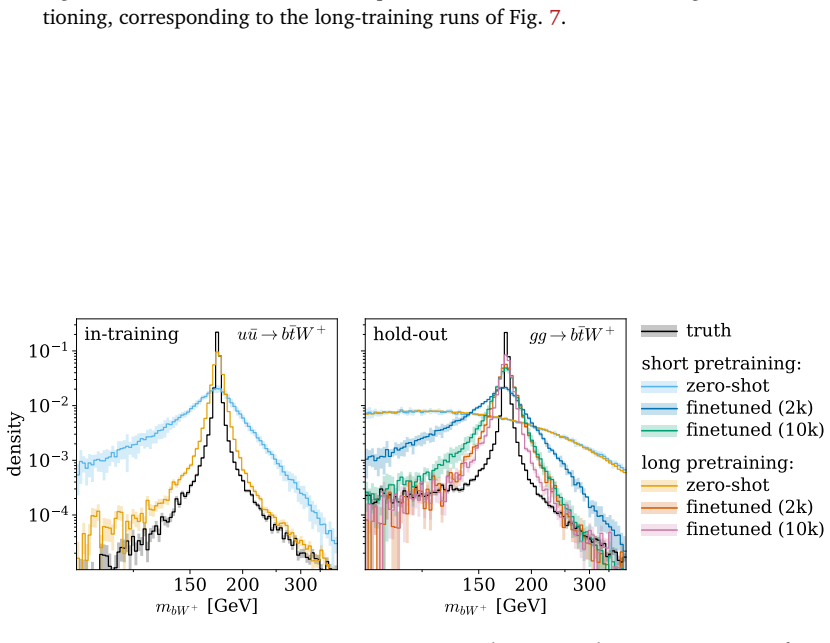
read the original abstract
Neural network training for LHC event generation should, ideally, benefit from common high-level patterns in different processes. We propose novel conditioning schemes for continuous parameters, process labels, and Feynman diagrams. We employ pre-trained LLMs as multi-modal foundation models to provide descriptive embeddings for an autoregressive transformer. With such high-level physics-inductive bias the generative networks converge faster, provide better result, and generalize to unseen processes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using pre-trained LLMs as multi-modal foundation models to generate descriptive embeddings that condition an autoregressive transformer on continuous parameters, process labels, and Feynman diagrams for LHC event generation. The central claim is that this high-level physics-inductive bias enables faster convergence, better results, and generalization to unseen processes.
Significance. If the claims are validated with quantitative evidence, the work could be significant for LHC phenomenology by enabling a single generative model to handle arbitrary processes, potentially streamlining Monte Carlo simulations and reducing the need for process-specific training. Leveraging unmodified general-purpose LLMs for physics conditioning would represent an innovative transfer-learning direction if the inductive bias proves transferable.
major comments (1)
- [Abstract] Abstract: The claims that 'the generative networks converge faster, provide better result, and generalize to unseen processes' with 'high-level physics-inductive bias' from LLM embeddings are presented without any quantitative metrics, ablation studies, training details, or performance comparisons. This absence is load-bearing, as it prevents assessment of whether improvements arise from the claimed physics bias or from the conditioning architecture itself.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims that 'the generative networks converge faster, provide better result, and generalize to unseen processes' with 'high-level physics-inductive bias' from LLM embeddings are presented without any quantitative metrics, ablation studies, training details, or performance comparisons. This absence is load-bearing, as it prevents assessment of whether improvements arise from the claimed physics bias or from the conditioning architecture itself.
Authors: We agree that the abstract states the central claims at a high level without quantitative support. The body of the manuscript contains the relevant metrics, ablation studies, training details, and comparisons. To address the concern directly, we will revise the abstract to incorporate key quantitative results (e.g., convergence speed, quality metrics, and generalization performance on held-out processes) so that the claims are anchored by evidence already present in the paper. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper proposes conditioning an autoregressive transformer with embeddings from unmodified pre-trained LLMs for LHC event generation. No equations, fitted parameters, or self-referential definitions appear in the abstract or described claims. The asserted gains in convergence, sample quality, and zero-shot generalization are presented as empirical outcomes of experiments rather than quantities defined by construction from the inputs. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing steps. The derivation chain is therefore self-contained against external validation and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Point cloud transformers applied to collider physics
Mikuni, Vinicius and Canelli, Florencia. Point cloud transformers applied to collider physics. Mach. Learn. Sci. Tech. 2021. doi:10.1088/2632-2153/ac07f6. arXiv:2102.05073
-
[2]
Reconstructing particles in jets using set transformer and hypergraph prediction networks
Di Bello, Francesco Armando and others. Reconstructing particles in jets using set transformer and hypergraph prediction networks. Eur. Phys. J. C. 2023. doi:10.1140/epjc/s10052-023-11677-7. arXiv:2212.01328
-
[3]
Learning the language of QCD jets with transformers
Finke, Thorben and Kr. Learning the language of QCD jets with transformers. JHEP. 2023. doi:10.1007/JHEP06(2023)184. arXiv:2303.07364
-
[4]
Komiske, Patrick T. and Metodiev, Eric M. and Thaler, Jesse. Energy Flow Networks: Deep Sets for Particle Jets. JHEP. 2019. doi:10.1007/JHEP01(2019)121. arXiv:1810.05165
-
[5]
ParticleNet: Jet Tagging via Particle Clouds
Qu, Huilin and Gouskos, Loukas. ParticleNet: Jet Tagging via Particle Clouds. Phys. Rev. D. 2020. doi:10.1103/PhysRevD.101.056019. arXiv:1902.08570
-
[6]
Bosman, Sarah E I and Davies, Frederick B and Becker, George D and Keating, Laura C and Davies, Rebecca L and Zhu, Yongda and Eilers, Anna-Christina and D’Odorico, Valentina and Bian, Fuyan and Bischetti, Manuela and Cristiani, Stefano V and Fan, Xiaohui and Farina, Emanuele P and Haehnelt, Martin G and Hennawi, Joseph F and Kulkarni, Girish and Mesinger,...
-
[7]
Spina, Benedetta and Bosman, Sarah E. I. and Davies, Frederick B. and Gaikwad, Prakash and Zhu, Yongda , year=. Damping wings in the Lyman- forest: A model-independent measurement of the neutral fraction at 5.4 < z < 6.1 , volume=. doi:10.1051/0004-6361/202450798 , journal=
-
[8]
Bhardwaj, Akanksha and Englert, Christoph and Naskar, Wrishik and Ngairangbam, Vishal S. and Spannowsky, Michael. Equivariant, safe and sensitive graph networks for new physics. JHEP. 2024. doi:10.1007/JHEP07(2024)245. arXiv:2402.12449
-
[9]
Neutsch, Steffen and Heneka, Caroline and Br\"uggen, Marcus , title = ". Mon. Not. Roy. Astron. Soc. 2022. doi:10.1093/mnras/stac218. arXiv:2201.07587
-
[10]
The frontier of simulation-based inference , volume =
Cranmer, Kyle and Brehmer, Johann and Louppe, Gilles. The frontier of simulation-based inference. Proc. Nat. Acad. Sci. 2020. doi:10.1073/pnas.1912789117. arXiv:1911.01429
-
[11]
Machine Learning and Cosmology
Dvorkin, Cora and others. Machine Learning and Cosmology. Snowmass 2021. 2022. arXiv:2203.08056
arXiv 2021
-
[12]
Enhancing Gravitational-Wave Science with Machine Learning
Cuoco, Elena and others. Enhancing Gravitational-Wave Science with Machine Learning. Mach. Learn. Sci. Tech. 2021. doi:10.1088/2632-2153/abb93a. arXiv:2005.03745
-
[13]
RAS Techniques and Instruments , volume =
Slijepcevic, Inigo V and Scaife, Anna M M and Walmsley, Mike and Bowles, Micah and Wong, O Ivy and Shabala, Stanislav S and White, Sarah V , title =. RAS Techniques and Instruments , volume =. 2023 , month =. doi:10.1093/rasti/rzad055 , url =
-
[14]
Monthly Notices of the Royal Astronomical Society , volume =
Parker, Liam and Lanusse, Francois and Golkar, Siavash and Sarra, Leopoldo and Cranmer, Miles and Bietti, Alberto and Eickenberg, Michael and Krawezik, Geraud and McCabe, Michael and Morel, Rudy and Ohana, Ruben and Pettee, Mariel and Régaldo-Saint Blancard, Bruno and Cho, Kyunghyun and Ho, Shirley and The Polymathic AI Collaboration , title =. Monthly No...
-
[15]
and Mishra-Sharma, Siddharth and Villar, V
Zhang, Gemma and Helfer, Thomas and Gagliano, Alexander T. and Mishra-Sharma, Siddharth and Villar, V. Ashley. Maven: a multimodal foundation model for supernova science. Mach. Learn. Sci. Tech. 2024. doi:10.1088/2632-2153/ad990d. arXiv:2408.16829
-
[16]
and Roussi, Marwah and Miller, David W
Bogatskiy, Alexander and Anderson, Brandon and Offermann, Jan T. and Roussi, Marwah and Miller, David W. and Kondor, Risi. Lorentz Group Equivariant Neural Network for Particle Physics. 2020. arXiv:2006.04780
arXiv 2020
-
[17]
uller, David I. and Schuh, Daniel , title =
Favoni, Matteo and Ipp, Andreas and M\"uller, David I. and Schuh, Daniel , title = ". Phys. Rev. Lett. 2022. doi:10.1103/PhysRevLett.128.032003. arXiv:2012.12901
-
[18]
uller, David I. and Schuh, Daniel , title =
Bulusu, Srinath and Favoni, Matteo and Ipp, Andreas and M\"uller, David I. and Schuh, Daniel , title = ". EPJ Web Conf. 2022. doi:10.1051/epjconf/202225809001. arXiv:2112.12493
-
[19]
An efficient Lorentz equivariant graph neural network for jet tagging
Gong, Shiqi and Meng, Qi and Zhang, Jue and Qu, Huilin and Li, Congqiao and Qian, Sitian and Du, Weitao and Ma, Zhi-Ming and Liu, Tie-Yan. An efficient Lorentz equivariant graph neural network for jet tagging. JHEP. 2022. doi:10.1007/JHEP07(2022)030. arXiv:2201.08187
-
[20]
Favoni, Matteo and Ipp, Andreas and M\"uller, David I. , title = ". EPJ Web Conf. 2022. doi:10.1051/epjconf/202227409001. arXiv:2212.00832
-
[21]
Symmetry Group Equivariant Architectures for Physics
Bogatskiy, Alexander and others. Symmetry Group Equivariant Architectures for Physics. Snowmass 2021. 2022. arXiv:2203.06153
arXiv 2021
-
[22]
Bogatskiy, Alexander and Hoffman, Timothy and Miller, David W. and Offermann, Jan T. PELICAN: Permutation Equivariant and Lorentz Invariant or Covariant Aggregator Network for Particle Physics. 2022. arXiv:2211.00454
arXiv 2022
-
[23]
Equivariant Graph Neural Networks for Charged Particle Tracking
Murnane, Daniel and Thais, Savannah and Thete, Ameya. Equivariant Graph Neural Networks for Charged Particle Tracking. 21th International Workshop on Advanced Computing and Analysis Techniques in Physics Research : AI meets Reality. 2023. arXiv:2304.05293
arXiv 2023
-
[24]
Learning broken symmetries with approximate invariance
Nabat, Seth and Ghosh, Aishik and Witkowski, Edmund and Kasieczka, Gregor and Whiteson, Daniel. Learning broken symmetries with approximate invariance. Phys. Rev. D. 2025. doi:10.1103/PhysRevD.111.072002. arXiv:2412.18773
-
[25]
Bogatskiy, Alexander and Hoffman, Timothy and Miller, David W. and Offermann, Jan T. and Liu, Xiaoyang. Explainable equivariant neural networks for particle physics: PELICAN. JHEP. 2024. doi:10.1007/JHEP03(2024)113. arXiv:2307.16506
-
[26]
Ma\^ tre, Daniel and Ngairangbam, Vishal S. and Spannowsky, Michael. Optimal equivariant architectures from the symmetries of matrix-element likelihoods. Mach. Learn. Sci. Tech. 2025. doi:10.1088/2632-2153/adbab1. arXiv:2410.18553
-
[27]
and Hallin, Anna and Kasieczka, Gregor and Kr
Amram, Oz and Anzalone, Luca and Birk, Joschka and Faroughy, Darius A. and Hallin, Anna and Kasieczka, Gregor and Kr. Aspen Open Jets: unlocking LHC data for foundation models in particle physics. Mach. Learn. Sci. Tech. 2025. doi:10.1088/2632-2153/ade58f. arXiv:2412.10504
-
[28]
2023 , eprint=
LIMA: Less Is More for Alignment , author=. 2023 , eprint=
2023
-
[29]
RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback , author=
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback , author=. 2024 , eprint=
2024
-
[30]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[31]
2024 , eprint=
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs , author=. 2024 , eprint=
2024
-
[32]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
-
[33]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[34]
2024 , eprint=
Investigating the Synergistic Effects of Dropout and Residual Connections on Language Model Training , author=. 2024 , eprint=
2024
-
[35]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[36]
2022 , eprint=
Emergent Abilities of Large Language Models , author=. 2022 , eprint=
2022
-
[37]
Permutationless many-jet event reconstruction with symmetry preserving attention networks
Fenton, Michael James and Shmakov, Alexander and Ho, Ta-Wei and Hsu, Shih-Chieh and Whiteson, Daniel and Baldi, Pierre. Permutationless many-jet event reconstruction with symmetry preserving attention networks. Phys. Rev. D. 2022. doi:10.1103/PhysRevD.105.112008. arXiv:2010.09206
-
[38]
ABCNet: An attention-based method for particle tagging
Mikuni, Vinicius and Canelli, Florencia. ABCNet: An attention-based method for particle tagging. Eur. Phys. J. Plus. 2020. doi:10.1140/epjp/s13360-020-00497-3. arXiv:2001.05311
-
[39]
Particle Transformer for Jet Tagging
Qu, Huilin and Li, Congqiao and Qian, Sitian. Particle Transformer for Jet Tagging. 2022. arXiv:2202.03772
arXiv 2022
-
[40]
Automated Approach to Accurate, Precise, and Fast Detector Simulation and Reconstruction
Dreyer, Etienne and Gross, Eilam and Kobylianskii, Dmitrii and Mikuni, Vinicius and Nachman, Benjamin and Soybelman, Nathalie. Automated Approach to Accurate, Precise, and Fast Detector Simulation and Reconstruction. Phys. Rev. Lett. 2024. doi:10.1103/PhysRevLett.133.211902. arXiv:2406.01620
-
[41]
Generating variable length full events from partons
Qu\'etant, Guillaume and Raine, John Andrew and Leigh, Matthew and Sengupta, Debajyoti and Golling, Tobias. Generating variable length full events from partons. Phys. Rev. D. 2024. doi:10.1103/PhysRevD.110.076023. arXiv:2406.13074
-
[42]
Generating particle physics Lagrangians with transformers
Koay, Yong Sheng and Enberg, Rikard and Moretti, Stefano and Camargo-Molina, Eliel. Generating particle physics Lagrangians with transformers. 2025. arXiv:2501.09729
arXiv 2025
-
[43]
Dersy, Aur\'elien and Schwartz, Matthew D. and Zhang, Xiaoyuan. Simplifying Polylogarithms with Machine Learning. Int. J. Data Sci. Math. Sci. 2024. doi:10.1142/S2810939223500028. arXiv:2206.04115
-
[44]
Learning the simplicity of scattering amplitudes
Cheung, Clifford and Dersy, Aur\'elien and Schwartz, Matthew D. Learning the simplicity of scattering amplitudes. SciPost Phys. 2025. doi:10.21468/SciPostPhys.18.2.040. arXiv:2408.04720
-
[45]
OmniJet- _ C : Learning point cloud calorimeter simulations using generative transformers
Birk, Joschka and Gaede, Frank and Hallin, Anna and Kasieczka, Gregor and Mozzanica, Martina and Rose, Henning. OmniJet- _ C : Learning point cloud calorimeter simulations using generative transformers. 2025. arXiv:2501.05534
arXiv 2025
-
[46]
HEP-JEPA: A foundation model for collider physics using joint embedding predictive architecture
Bardhan, Jai and Agrawal, Radhikesh and Tilak, Abhiram and Neeraj, Cyrin and Mitra, Subhadip. HEP-JEPA: A foundation model for collider physics using joint embedding predictive architecture. 2025. arXiv:2502.03933
arXiv 2025
-
[47]
Wildridge, Andrew J. and Rodgers, Jack P. and Colbert, Ethan M. and yao, Yao and Jung, Andreas W. and Liu, Miaoyuan. Bumblebee: Foundation Model for Particle Physics Discovery. 38th conference on Neural Information Processing Systems. 2024. arXiv:2412.07867
arXiv 2024
-
[48]
Solving key challenges in collider physics with foundation models
Mikuni, Vinicius and Nachman, Benjamin. Solving key challenges in collider physics with foundation models. Phys. Rev. D. 2025. doi:10.1103/PhysRevD.111.L051504. arXiv:2404.16091
-
[49]
Resimulation-based self-supervised learning for pretraining physics foundation models
Harris, Philip and Krupa, Jeffrey and Kagan, Michael and Maier, Benedikt and Woodward, Nathaniel. Resimulation-based self-supervised learning for pretraining physics foundation models. Phys. Rev. D. 2025. doi:10.1103/PhysRevD.111.032010. arXiv:2403.07066
-
[50]
OmniJet- : the first cross-task foundation model for particle physics
Birk, Joschka and Hallin, Anna and Kasieczka, Gregor. OmniJet- : the first cross-task foundation model for particle physics. Mach. Learn. Sci. Tech. 2024. doi:10.1088/2632-2153/ad66ad. arXiv:2403.05618
-
[51]
Physics event classification using Large Language Models
Fanelli, Cristiano and Giroux, James and Moran, Patrick and Nayak, Hemalata and Suresh, Karthik and Walter, Eric. Physics event classification using Large Language Models. JINST. 2024. doi:10.1088/1748-0221/19/07/C07011. arXiv:2404.05752
-
[52]
Masked particle modeling on sets: towards self-supervised high energy physics foundation models
Golling, Tobias and Heinrich, Lukas and Kagan, Michael and Klein, Samuel and Leigh, Matthew and Osadchy, Margarita and Raine, John Andrew. Masked particle modeling on sets: towards self-supervised high energy physics foundation models. Mach. Learn. Sci. Tech. 2024. doi:10.1088/2632-2153/ad64a8. arXiv:2401.13537
-
[53]
Is Tokenization Needed for Masked Particle Modelling?
Leigh, Matthew and Klein, Samuel and Charton, Fran c ois and Golling, Tobias and Heinrich, Lukas and Kagan, Michael and Ochoa, In\^es and Osadchy, Margarita. Is Tokenization Needed for Masked Particle Modelling?. Mach. Learn. Sci. Tech. 2025. doi:10.1088/2632-2153/addb98. arXiv:2409.12589
-
[54]
Finetuning foundation models for joint analysis optimization in High Energy Physics
Vigl, Matthias and Hartman, Nicole and Heinrich, Lukas. Finetuning foundation models for joint analysis optimization in High Energy Physics. Mach. Learn. Sci. Tech. 2024. doi:10.1088/2632-2153/ad55a3. arXiv:2401.13536
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Assran, Mahmoud and Duval, Quentin and Misra, Ishan and Bojanowski, Piotr and Vincent, Pascal and Rabbat, Michael and LeCun, Yann and Ballas, Nicolas , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[56]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[57]
2024 , eprint=
Can Large Language Models Learn the Physics of Metamaterials? An Empirical Study with ChatGPT , author=. 2024 , eprint=
2024
-
[58]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[59]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[60]
2023 , eprint=
Large Language Models are Zero-Shot Reasoners , author=. 2023 , eprint=
2023
-
[61]
The Impact of AI in Physics Education: A Comprehensive Review from GCSE to University Levels The Impact of AI in Physics Education , doi =
Yeadon, Will and Hardy, Tom , year =. The Impact of AI in Physics Education: A Comprehensive Review from GCSE to University Levels The Impact of AI in Physics Education , doi =
-
[62]
2023 , eprint=
Physics simulation capabilities of LLMs , author=. 2023 , eprint=
2023
-
[63]
2024 , eprint=
Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics , author=. 2024 , eprint=
2024
-
[64]
doi:10.48550/arXiv.2309.04533 , archivePrefix =
Unveiling Dark Matter free-streaming at the smallest scales with high redshift Lyman-alpha forest. doi:10.48550/arXiv.2309.04533 , archivePrefix =. 2309.04533 , primaryClass =
-
[65]
New constraints on warm dark matter from the Lyman- forest power spectrum. , keywords =. doi:10.1103/PhysRevD.108.023502 , archivePrefix =. 2209.14220 , primaryClass =
-
[66]
High Mass X-ray Binaries and the Cosmic 21-cm Signal: Impact of Host Galaxy Absorption
High-mass X-ray binaries and the cosmic 21-cm signal: impact of host galaxy absorption. , keywords =. doi:10.1093/mnras/stx943 , archivePrefix =. 1702.00409 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/mnras/stx943
-
[67]
Cosmology with One Galaxy?. , keywords =. doi:10.3847/1538-4357/ac5d3f , archivePrefix =. 2201.02202 , primaryClass =
-
[68]
Radio Galaxy Zoo: Compact and extended radio source classification with deep learning
Radio Galaxy Zoo: compact and extended radio source classification with deep learning. , keywords =. doi:10.1093/mnras/sty163 , archivePrefix =. 1801.04861 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/mnras/sty163
-
[69]
ML4Astro International Conference , pages=
Deep Learning 21 cm Lightcones in 3D , author=. ML4Astro International Conference , pages=. 2022 , organization=. doi:10.48550/arXiv.2311.17553 , archivePrefix =. 2311.17553 , primaryClass =
-
[70]
Quantifying uncertainty in deep learning approaches to radio galaxy classification. , keywords =. doi:10.1093/mnras/stac223 , archivePrefix =. 2201.01203 , primaryClass =
-
[71]
Galaxy Spectra neural Network (GaSNet). II. Using Deep Learning for Spectral Classification and Redshift Predictions. doi:10.48550/arXiv.2311.04146 , archivePrefix =. 2311.04146 , primaryClass =
-
[72]
doi:10.48550/arXiv.2310.02684 , archivePrefix =
The LoReLi database: 21 cm signal inference with 3D radiative hydrodynamics simulations. doi:10.48550/arXiv.2310.02684 , archivePrefix =. 2310.02684 , primaryClass =
-
[73]
Reports on Progress in Physics , keywords =
Machine learning for observational cosmology. Reports on Progress in Physics , keywords =. doi:10.1088/1361-6633/acd2ea , archivePrefix =. 2303.15794 , primaryClass =
-
[74]
doi:10.48550/arXiv.2203.08056 , archivePrefix =
Machine Learning and Cosmology. doi:10.48550/arXiv.2203.08056 , archivePrefix =. 2203.08056 , primaryClass =
-
[75]
Simulating the 21 cm signal from reionization including non-linear ionizations and inhomogeneous recombinations. , keywords =. doi:10.1093/mnras/stv3001 , archivePrefix =. 1510.04280 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/mnras/stv3001
-
[76]
Astraeus I: the interplay between galaxy formation and reionization. , keywords =. doi:10.1093/mnras/stab602 , archivePrefix =. 2004.08401 , primaryClass =
-
[77]
doi:10.48550/arXiv.2310.17602 , archivePrefix =
Simulation-based Inference of Reionization Parameters from 3D Tomographic 21 cm Light-cone Images -- II: Application of Solid Harmonic Wavelet Scattering Transform. doi:10.48550/arXiv.2310.17602 , archivePrefix =. 2310.17602 , primaryClass =
-
[78]
The DAWES review 10: The impact of deep learning for the analysis of galaxy surveys
Huertas-Company, Marc and Lanusse, Fran c ois. The DAWES review 10: The impact of deep learning for the analysis of galaxy surveys. Publ. Astron. Soc. Austral. 2023. doi:10.1017/pasa.2022.55. arXiv:2210.01813
-
[79]
2020 , eprint=
BayesFlow: Learning complex stochastic models with invertible neural networks , author=. 2020 , eprint=
2020
-
[80]
2023 , eprint=
BayesFlow: Amortized Bayesian Workflows With Neural Networks , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.