Identifying structural design principles shaping the computational abilities of recurrent neural networks
Pith reviewed 2026-06-26 05:41 UTC · model grok-4.3
The pith
Local 2- and 3-cycles in recurrent neural networks strongly enhance their ability to compute Boolean functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
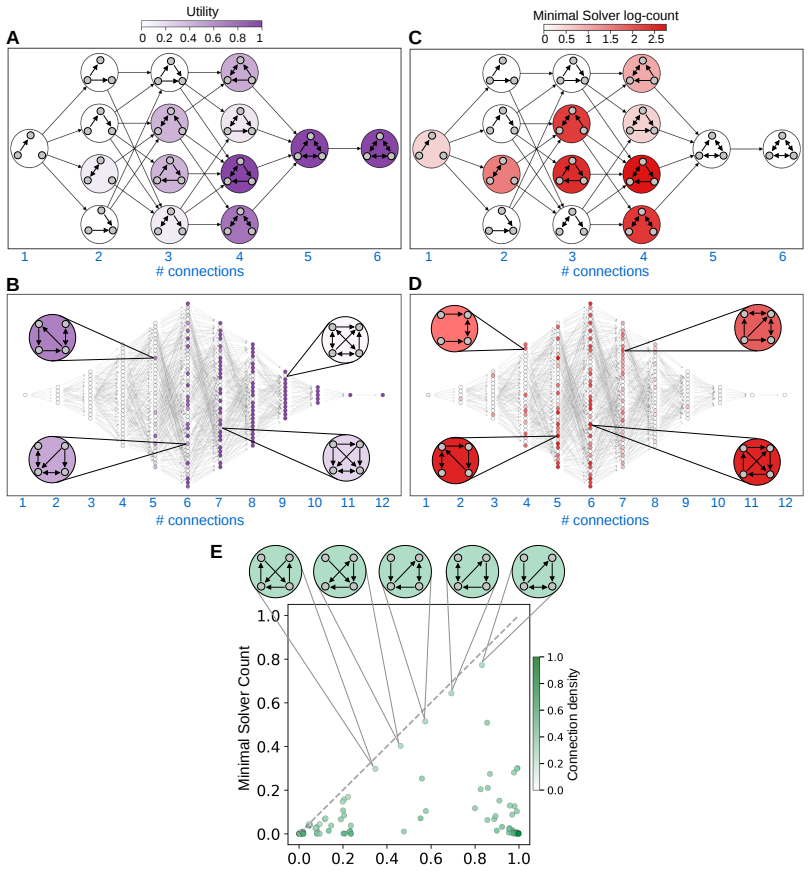
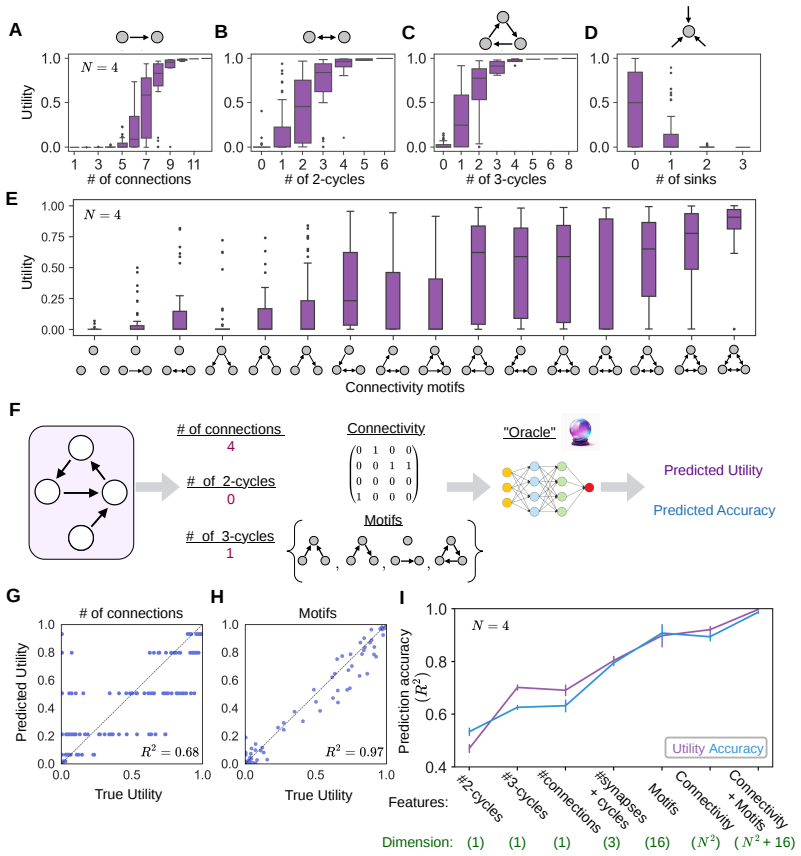
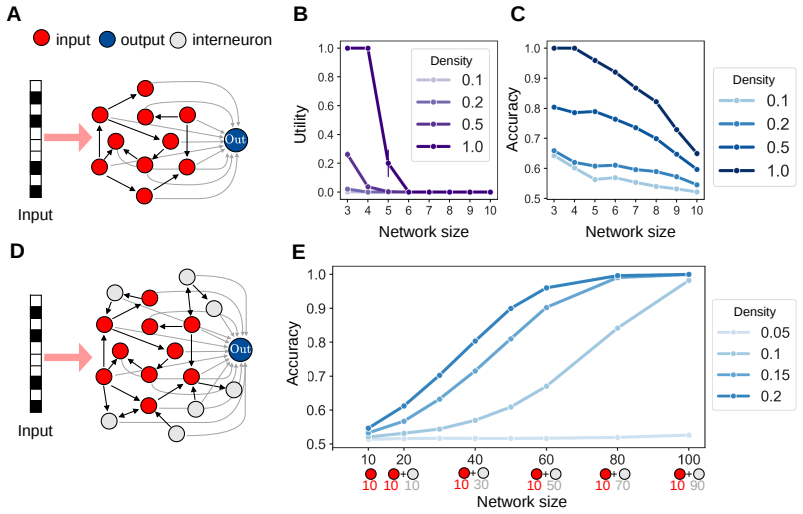
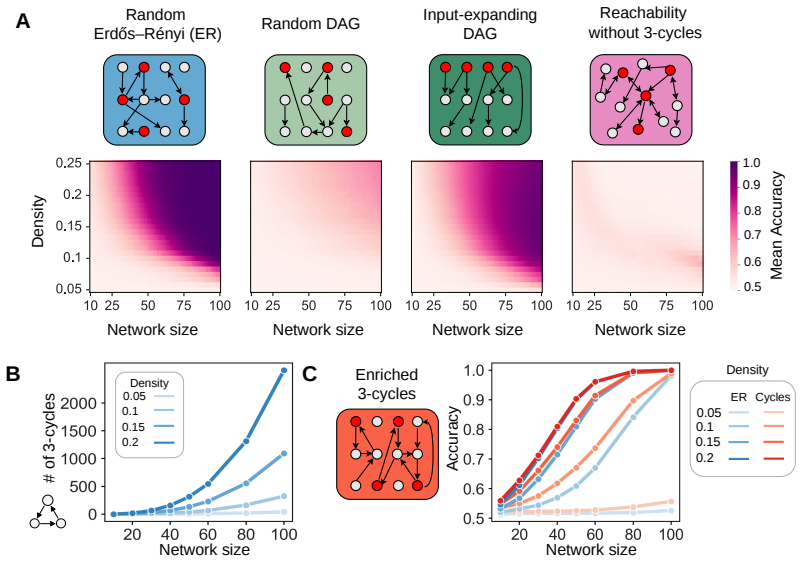
Exhaustive mapping of small recurrent networks onto Boolean functions shows that local 2-cycles and 3-cycles confer markedly higher computational capacity, that networks containing these cycles are often the minimal architectures sufficient for given functions, and that a compact set of connectivity statistics predicts performance across the function set; the same structural motifs increase capacity when introduced into larger networks.
What carries the argument
Local 2-cycles and 3-cycles in the directed connectivity graph of the recurrent network.
If this is right
- Networks containing local 2- and 3-cycles are often the minimal architectures that can solve particular Boolean functions.
- A small set of structural statistics accurately predicts how well any network will perform across the tested functions.
- Typical large networks fail to approximate randomly chosen functions.
- Adding a small number of sparsely connected interneurons dramatically raises computational capacity in large networks.
- Adding short cycles raises large-network capacity above that of acyclic or reachability-matched controls.
Where Pith is reading between the lines
- Cycle motifs may serve as a general design rule for efficient computation in other network types, not only RNNs.
- Biological circuits that perform demanding computations could be checked for enrichment of short directed cycles.
- Machine-learning network design could test whether deliberately inserting a few short cycles yields higher expressivity at smaller size.
Load-bearing premise
The use of Boolean functions together with the chosen training procedure accurately reflects the general computational abilities of the networks.
What would settle it
Finding that networks with local 2- and 3-cycles show no performance advantage over cycle-free networks when both are trained and tested on a different class of target computations or with altered training rules.
Figures
read the original abstract
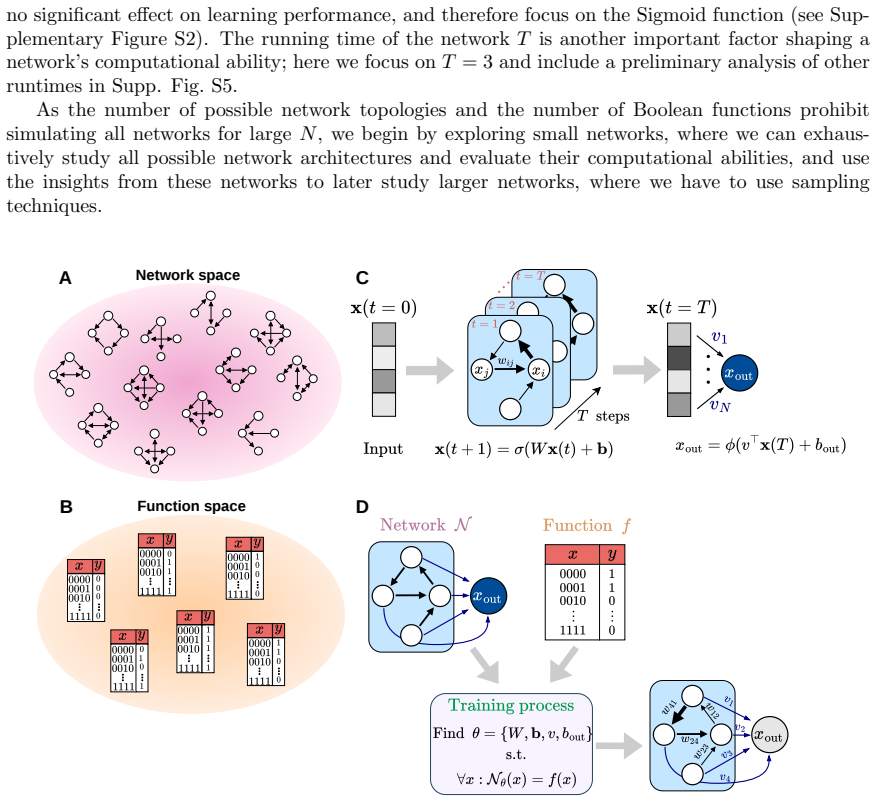
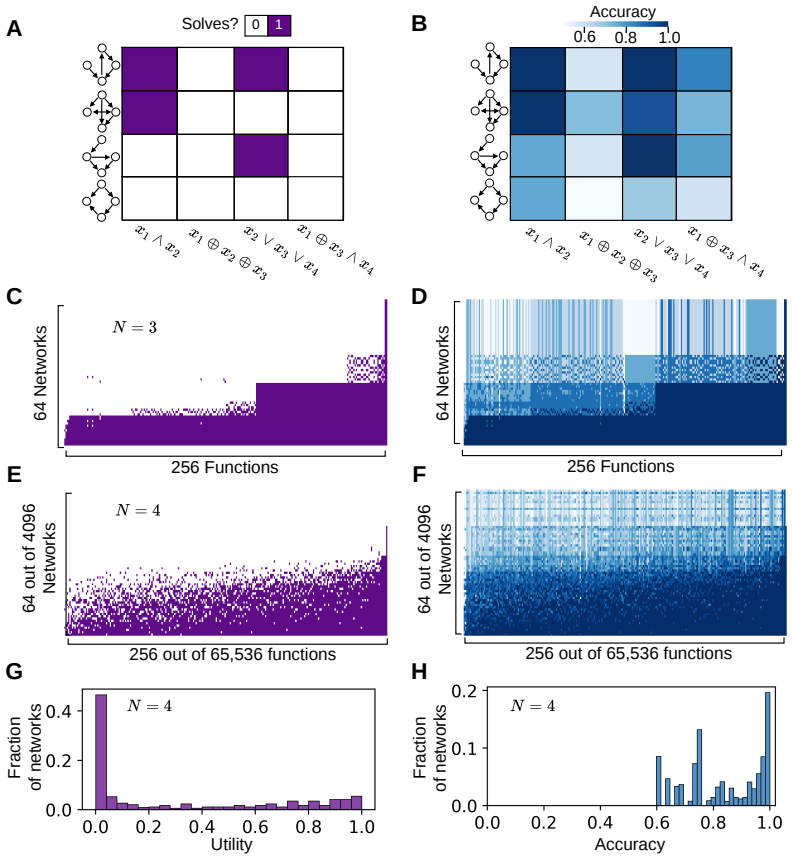
Understanding how the architecture of neural networks shapes the computations they carry is a central challenge in neuroscience and machine learning. While specific circuit architectures have been linked to particular network computations and theoretical bounds on expressivity of broad classes of networks have been found, we are still missing general principles connecting the structure of finite networks to their computational capabilities. Here, we characterize the computational abilities of recurrent neural networks as a function of their connectivity by training a large collection of different networks to compute a large set of Boolean functions. For small networks, we constructed the complete ``catalogs'' of network-function performance, which revealed that computational capacity varies widely across architectures and that most networks show poor performance, and most functions are hard to compute. However, we show that having local 2- and 3-cycles in a network strongly enhances its computational ability, and networks with such cycles are often the minimal architectures that can solve particular functions. We further show that a small set of structural statistics accurately predict networks' performance. Extending our analysis to large networks showed that typical networks fail even to approximate a randomly selected function. Surprisingly, adding a small number of sparsely connected biologically-inspired interneurons to the network dramatically increases computational capacity. As in small networks, adding short cycles improved networks' capacity, outperforming acyclic or reachability-matched controls. Thus, our results identify local cycles as design principles linking neural connectivity to computational power, and offer a general framework to explore structure-function relations in computing networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains large collections of recurrent neural networks on Boolean functions to map connectivity structure to computational performance. Complete catalogs for small networks show most architectures perform poorly while those containing local 2- and 3-cycles excel and often constitute minimal solutions for particular functions. A small set of structural statistics is shown to predict performance. In larger networks, typical architectures fail to approximate random functions, but adding a few sparsely connected interneurons dramatically increases capacity, with short cycles again outperforming acyclic and reachability-matched controls.
Significance. If the Boolean-function proxy is shown to generalize, the identification of local cycles as a structural design principle would provide a concrete link between finite-network connectivity and computational power, with direct relevance to both theoretical neuroscience and architecture search in machine learning. The exhaustive small-network catalogs and the use of matched controls constitute clear methodological strengths.
major comments (2)
- [Abstract] Abstract: the central claim that local 2- and 3-cycles 'strongly enhance computational ability' treats exact Boolean training success as a faithful proxy for general computational capacity. The manuscript provides no tests under input noise, continuous-valued inputs, or output robustness requirements; if cycle-containing networks merely stabilize fixed points more readily on these specific discrete tasks, the reported structural principle would be task-specific rather than general.
- [Abstract] Abstract and methods description: no information is given on training convergence criteria, the precise selection or sampling of the Boolean function set, or the statistical tests used to establish performance differences between cycle-containing and control architectures. These omissions make it impossible to evaluate whether the reported advantages are robust or could arise from optimization dynamics alone.
minor comments (1)
- [Abstract] The abstract states that 'a small set of structural statistics accurately predict networks' performance' but does not specify which statistics or the cross-validation procedure; adding this detail would improve clarity without altering the main claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and reproducibility of our results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that local 2- and 3-cycles 'strongly enhance computational ability' treats exact Boolean training success as a faithful proxy for general computational capacity. The manuscript provides no tests under input noise, continuous-valued inputs, or output robustness requirements; if cycle-containing networks merely stabilize fixed points more readily on these specific discrete tasks, the reported structural principle would be task-specific rather than general.
Authors: We agree this is a substantive limitation: our results are confined to exact Boolean function computation on noise-free discrete inputs, and we have no data on robustness to noise, continuous values, or output perturbations. The Boolean task was chosen to enable exhaustive catalogs and precise structure-function mapping, but we do not claim it is a universal proxy. We will revise the abstract and add a dedicated limitations paragraph in the discussion to qualify the claims as applying specifically to Boolean function computation and to note that generalization to other regimes is an open question for future work. No new experiments will be performed. revision: partial
-
Referee: [Abstract] Abstract and methods description: no information is given on training convergence criteria, the precise selection or sampling of the Boolean function set, or the statistical tests used to establish performance differences between cycle-containing and control architectures. These omissions make it impossible to evaluate whether the reported advantages are robust or could arise from optimization dynamics alone.
Authors: We acknowledge these details were omitted from the initial submission. The revised manuscript will expand the Methods section to specify: (i) convergence criteria (loss threshold of 0.01 and maximum epochs), (ii) Boolean function sampling (complete enumeration for n ≤ 4 inputs; uniform random sampling of 1000 functions for larger networks), and (iii) statistical comparisons (two-sided Wilcoxon rank-sum tests with exact p-values and effect sizes reported for cycle vs. control groups). These additions will allow direct assessment of robustness. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical training and controls
full rationale
The paper's central results derive from exhaustive training of many RNN architectures on Boolean functions, construction of performance catalogs, and explicit comparisons against acyclic and reachability-matched controls. These steps are independent computations on held-out or matched architectures rather than reductions of outputs to fitted inputs or self-citations. The structural-statistics predictor is a secondary post-hoc observation and does not load-bear the cycle-enhancement claim. No self-definitional, uniqueness-imported, or ansatz-smuggled steps appear in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- network sizes, training hyperparameters, and Boolean function set
axioms (1)
- domain assumption Boolean functions serve as a representative testbed for network computational abilities
Reference graph
Works this paper leans on
-
[1]
Emergence of scaling in random networks,
Albert-L´ aszl´ o Barab´ asi and R´ eka Albert. “Emergence of Scaling in Random Networks”.Science 286.5439 (1999), pp. 509–512.doi:10.1126/science.286.5439.509
-
[2]
6794, 378–382, doi:10.1038/35019019
R´ eka Albert, Hawoong Jeong, and Albert-L´ aszl´ o Barab´ asi. “Error and attack tolerance of complex networks”.Nature406.6794 (2000), pp. 378–382.doi:10.1038/35019019
-
[3]
Spatial growth of real-world networks
Marcus Kaiser and Claus C. Hilgetag. “Spatial growth of real-world networks”.Physical Review E69.3 (2004), p. 036103.doi:10.1103/PhysRevE.69.036103
-
[4]
Marcus Kaiser, Claus C. Hilgetag, and Arjen Van Ooyen. “A Simple Rule for Axon Outgrowth and Synaptic Competition Generates Realistic Connection Lengths and Filling Fractions”. Cerebral Cortex19.12 (2009), pp. 3001–3010.doi:10.1093/cercor/bhp071
-
[5]
Network Motifs: Simple Building Blocks of Complex Networks
Ron Milo et al. “Network Motifs: Simple Building Blocks of Complex Networks”.Science 298.5594 (2002), pp. 824–827.doi:10.1126/science.298.5594.824
-
[6]
Structure and function of the feed-forward loop network motif
Shmoolik Mangan and Uri Alon. “Structure and function of the feed-forward loop network motif”.Proceedings of the National Academy of Sciences100.21 (2003), pp. 11980–11985.doi: 10.1073/pnas.2133841100
-
[7]
Microstructure of a spatial map in the entorhinal cortex
Torkel Hafting et al. “Microstructure of a spatial map in the entorhinal cortex”.Nature 436.7052 (2005), pp. 801–806.doi:10.1038/nature03721
-
[8]
Context- dependent computation by recurrent dynamics in prefrontal cortex
Valerio Mante, David Sussillo, Krishna V. Shenoy, and William T. Newsome. “Context- dependent computation by recurrent dynamics in prefrontal cortex”.Nature503.7474 (2013), pp. 78–84.doi:10.1038/nature12742
-
[9]
31 The Mathematics of AI Winters Noguer i Alonso and Pacheco Aznar Moshe Leshno, Vladimir Ya
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. “Deep learning”.Nature521.7553 (2015), pp. 436–444.doi:10.1038/nature14539
-
[10]
John Jumper et al. “Highly accurate protein structure prediction with AlphaFold”.Nature 596.7873 (2021), pp. 583–589.doi:10.1038/s41586-021-03819-2
-
[11]
ImageNet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. “ImageNet classification with deep convolutional neural networks”.Commun. ACM60.6 (2017), pp. 84–90.doi:10 . 1145 / 3065386
2017
-
[12]
Generative adversarial nets
Ian J. Goodfellow et al. “Generative adversarial nets”. NIPS’14 (2014), pp. 2672–2680
2014
-
[13]
David Silver et al. “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play”.Science362.6419 (2018), pp. 1140–1144.doi:10.1126/science. aar6404
-
[14]
Volodymyr Mnih et al. “Human-level control through deep reinforcement learning”.Nature 518.7540 (2015), pp. 529–533.doi:10.1038/nature14236
-
[15]
Sterling, Philipp Schlegel, et al
Sven Dorkenwald et al. “Neuronal wiring diagram of an adult brain”.Nature634.8032 (2024), pp. 124–138.doi:10.1038/s41586-024-07558-y
-
[16]
Whole-animal connectomes of both Caenorhabditis elegans sexes
Steven J. Cook et al. “Whole-animal connectomes of both Caenorhabditis elegans sexes”. Nature571.7763 (2019), pp. 63–71.doi:10.1038/s41586-019-1352-7
-
[17]
The structure of the nervous system of the nematodeCaenorhabditis elegans
John Graham White, Eileen Southgate, J. N. Thomson, and Sydney Brenner. “The structure of the nervous system of the nematodeCaenorhabditis elegans”.Philosophical Transactions of the Royal Society of London. B, Biological Sciences314.1165 (1986), pp. 1–340.doi:10. 1098/rstb.1986.0056. 28
arXiv 1986
-
[18]
Nature Neuroscience29(4), 945–956 (Apr 2026)
Manuel Beiran and Ashok Litwin-Kumar. “Prediction of neural activity in connectome-constrained recurrent networks”.Nature Neuroscience28.12 (2025), pp. 2561–2574.doi:10.1038/s41593- 025-02080-4
-
[19]
Constraining computational models using elec- tron microscopy wiring diagrams
Ashok Litwin-Kumar and Srinivas C Turaga. “Constraining computational models using elec- tron microscopy wiring diagrams”.Current Opinion in Neurobiology58 (2019), pp. 94–100. doi:10.1016/j.conb.2019.07.007
-
[20]
Ring attractor dynamics in theDrosophilacentral brain
Sung Soo Kim, Herv´ e Rouault, Shaul Druckmann, and Vivek Jayaraman. “Ring attractor dynamics in theDrosophilacentral brain”.Science356.6340 (2017), pp. 849–853.doi:10. 1126/science.aal4835
2017
-
[22]
Wiring specificity in the direction-selectivity circuit of the retina
Kevin L. Briggman, Moritz Helmstaedter, and Winfried Denk. “Wiring specificity in the direction-selectivity circuit of the retina”.Nature471.7337 (2011), pp. 183–188.doi:10 . 1038/nature09818
2011
-
[23]
Whitening of odor representations by the wiring diagram of the olfactory bulb
Adrian A. Wanner and Rainer W. Friedrich. “Whitening of odor representations by the wiring diagram of the olfactory bulb”.Nature Neuroscience23.3 (2020), pp. 433–442.doi:10.1038/ s41593-019-0576-z
2020
-
[24]
A National Experiment Reveals Where a Growth Mindset Improves Achievement
Janne K. Lappalainen et al. “Connectome-constrained networks predict neural activity across the fly visual system”.Nature634.8036 (2024), pp. 1132–1140.doi:10.1038/s41586- 024- 07939-3
-
[25]
Generative models for network neuroscience: prospects and promise
Richard F. Betzel and Danielle S. Bassett. “Generative models for network neuroscience: prospects and promise”.Journal of The Royal Society Interface14.136 (2017), p. 20170623. doi:10.1098/rsif.2017.0623
-
[26]
Learning the Architectural Features That Predict Func- tional Similarity of Neural Networks
Adam Haber and Elad Schneidman. “Learning the Architectural Features That Predict Func- tional Similarity of Neural Networks”.Phys. Rev. X12 (2 2022), p. 021051.doi:10.1103/ PhysRevX.12.021051
2022
-
[27]
The structure and function of neural connectomes are shaped by a small number of design principles
Adam Haber, Adrian A. Wanner, Rainer W. Friedrich, and Elad Schneidman. “The structure and function of neural connectomes are shaped by a small number of design principles”.bioRxiv (2023).doi:10.1101/2023.03.15.532611
-
[28]
Building the connectome of a small brain with a simple stochastic developmental generative model
Oren Richter and Elad Schneidman. “Building the connectome of a small brain with a simple stochastic developmental generative model”.Proceedings of the National Academy of Sciences 122.47 (2025), e2504913122.doi:10.1073/pnas.2504913122
-
[29]
Multilayer feedforward networks are universal approximators
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. “Multilayer feedforward networks are universal approximators”.Neural Networks2.5 (1989), pp. 359–366.doi:https://doi.org/ 10.1016/0893-6080(89)90020-8
-
[30]
Almost optimal lower bounds for small depth circuits
Johan Hastad. “Almost optimal lower bounds for small depth circuits”.Proceedings of the Eighteenth Annual ACM Symposium on Theory of Computing. STOC ’86. Berkeley, California, USA: Association for Computing Machinery, 1986, pp. 6–20.isbn: 0897911938.doi:10.1145/ 12130.12132
arXiv 1986
-
[31]
MIT Press, Cambridge, MA, United States, 1994
Ian Parberry.Circuit complexity and neural networks. MIT Press, Cambridge, MA, United States, 1994
1994
-
[32]
The Power of Depth for Feedforward Neural Networks
Ronen Eldan and Ohad Shamir. “The Power of Depth for Feedforward Neural Networks”. Proceedings of Machine Learning Research 49 (2016), pp. 907–940. 29
2016
-
[33]
Shallow vs. deep sum-product networks
Olivier Delalleau and Yoshua Bengio. “Shallow vs. deep sum-product networks”. NIPS’11 (2011), pp. 666–674
2011
-
[34]
Leslie Valiant. “A theory of the learnable”.Commun. ACM27.11 (1984), pp. 1134–1142.doi: 10.1145/1968.1972
-
[35]
Architectures of neuronal circuits
Liqun Luo. “Architectures of neuronal circuits”.Science373.6559 (2021).doi:10 . 1126 / science.abg7285
2021
-
[36]
Recurrent neuronal circuits in the neocortex
Rodney Douglas and Kevan Martin. “Recurrent neuronal circuits in the neocortex”.Cell Cur- rent Biology17 (13 2007).doi:10.1016/j.cub.2007.04.024
-
[37]
Wolfgang Maass, Thomas Natschl¨ ager, and Henry Markram. “Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations”.Neural Computation14.11 (2002), pp. 2531–2560.doi:10.1162/089976602760407955
-
[38]
Generating Coherent Patterns of Activity from Chaotic Neural Networks
David Sussillo and L.F. Abbott. “Generating Coherent Patterns of Activity from Chaotic Neural Networks”.Neuron63.4 (2009), pp. 544–557.doi:10.1016/j.neuron.2009.07.018
-
[39]
David Sussillo and Omri Barak. “Opening the Black Box: Low-Dimensional Dynamics in High- Dimensional Recurrent Neural Networks”.Neural Computation25.3 (2013), pp. 626–649.doi: 10.1162/NECO_a_00409
-
[40]
Graph rules for recurrent neural network dynamics
Carina Curto and Katherine Morrison. “Graph rules for recurrent neural network dynamics”. Notices of the American Mathematical Society70.4 (2023).doi:https://doi.org/10.1090/ noti2661
2023
-
[41]
2025.doi:10.48550/ARXIV.2510.05098
Carina Curto.On graphical domination for threshold-linear networks with recurrent excitation and global inhibition. 2025.doi:10.48550/ARXIV.2510.05098
-
[42]
R´ eka Albert and Albert-L´ aszl´ o Barab´ asi. “Statistical mechanics of complex networks”.Reviews of Modern Physics74.1 (2002), pp. 47–97.doi:10.1103/RevModPhys.74.47
-
[43]
The Structure and Function of Complex Networks
Mark Newman. “The Structure and Function of Complex Networks”.SIAM Review45.2 (2003), pp. 167–256.doi:10.1137/S003614450342480
-
[44]
Cengage Learning, 2013
Michael Sipser.Introduction to the Theory of Computation, Third Edition. Cengage Learning, 2013
2013
-
[45]
Cambridge University Press, 2014
Ryan O’Donnell.Analysis of Boolean Functions. Cambridge University Press, 2014
2014
-
[46]
Ameya D. Jagtap and George Em Karniadakis.How important are activation functions in regression and classification? A survey, performance comparison, and future directions. 2022. arXiv:2209.02681 [cs.LG]
arXiv 2022
-
[47]
Backpropagation through time: what it does and how to do it
Paul Werbos. “Backpropagation through time: what it does and how to do it”.Proceedings of the IEEE78.10 (1990), pp. 1550–1560.doi:10.1109/5.58337
-
[48]
Michael A. A. Cox and Trevor F. Cox. “Multidimensional Scaling”.Handbook of Data Visu- alization. Berlin, Heidelberg: Springer Berlin Heidelberg, 2008, pp. 315–347.isbn: 978-3-540- 33037-0.doi:10.1007/978-3-540-33037-0_14
-
[49]
The synthesis of two-terminal switching circuits
Claude. E. Shannon. “The synthesis of two-terminal switching circuits”.The Bell System Technical Journal28.1 (1949), pp. 59–98.doi:10.1002/j.1538-7305.1949.tb03624.x
-
[50]
Cryptographic limitations on learning Boolean formulae and finite automata
Michael Kearns and Leslie Valiant. “Cryptographic limitations on learning Boolean formulae and finite automata”.Journal of the ACM41.1 (1994), pp. 67–95.doi:10.1145/174644. 174647
-
[51]
Bernhard Sch¨ olkopf, Ralf Herbrich, and Alex J
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. “Learning representations by back-propagating errors”.Nature323.6088 (1986), pp. 533–536.doi:10.1038/323533a0. 30
-
[52]
Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner. “Gradient-based learning applied to document recognition”.Proceedings of the IEEE86.11 (1998), pp. 2278–2324.doi:10.1109/5.726791
-
[53]
Attention is all you need
Ashish Vaswani et al. “Attention is all you need”. NIPS’17 (2017), pp. 6000–6010
2017
-
[54]
Similar network activity from disparate circuit parameters
Astrid Printz, Dirk Bucher, and Eve Marder. “Similar network activity from disparate circuit parameters.”Nature Neuroscience7 (2004), pp. 1345–1352.doi:https://doi.org/10.1038/ nn1352
2004
-
[55]
2024.doi:10.48550/ARXIV.2406.19108
Blaise Ag¨ uera y Arcas et al.Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction. 2024.doi:10.48550/ARXIV.2406.19108
-
[56]
Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication
Herbert Jaeger and Harald Haas. “Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication”.Science304.5667 (2004), pp. 78–80.doi:10 . 1126/science.1091277
2004
-
[57]
Adam Paszke et al.PyTorch: An Imperative Style, High-Performance Deep Learning Library
-
[58]
arXiv:1912.01703 [cs.LG]
Pith/arXiv arXiv 1912
-
[59]
Kingma and Jimmy Ba.Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba.Adam: A Method for Stochastic Optimization. 2017. arXiv: 1412.6980 [cs.LG]
Pith/arXiv arXiv 2017
-
[60]
Review of tools and algorithms for network motif discovery in biological networks
Sabyasachi Patra and Anjali Mohapatra. “Review of tools and algorithms for network motif discovery in biological networks”.IET Systems Biology14.4 (2020), pp. 171–189.doi:https: //doi.org/10.1049/iet-syb.2020.0004
-
[61]
On the evolution of random graphs
P´ al Erd˝ os and Alfr´ ed R´ enyi. “On the evolution of random graphs”.Publications of the Math- ematical Institute of the Hungarian Academy of Sciences5 (1960), pp. 17–61. 31
1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.