LemonHarness Technical Report
Pith reviewed 2026-06-26 00:04 UTC · model grok-4.3
The pith
LemonHarness unifies runtime boundaries, callable rules, and time awareness to stabilize long-horizon LLM agent execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
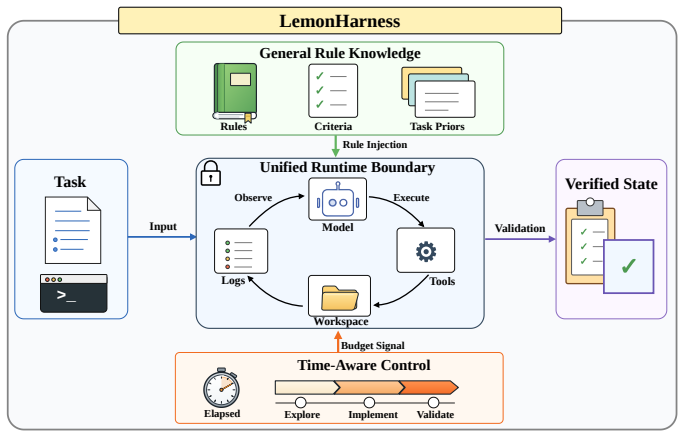
LemonHarness establishes an explicit execution boundary by constraining state-changing operations within a clearly defined workspace and bringing model invocation, tool execution, and rule knowledge within a single controlled boundary. State-changing operations, including file writes, dependency installation, and temporary artifact creation, are executed through structured tool interfaces, with execution feedback recorded as observations available to subsequent model decisions. The system also introduces a reusable rule knowledge base, which turns recurring execution rules and acceptance criteria into runtime knowledge. LemonHarness further adds a time-aware execution mechanism that exposes
What carries the argument
LemonHarness integrated execution framework that enforces a unified runtime boundary, exposes callable rule knowledge, and supplies time-budget signals to the model.
If this is right
- State changes become observable and reversible because every write or artifact creation returns structured feedback.
- Recurring rules no longer need to be re-prompted each round because they live in a callable knowledge base.
- Models can shift effort among exploration, coding, and validation as remaining time shrinks, reducing timeout failures.
- Long-horizon runs accumulate fewer untracked file modifications across multiple agent rounds.
Where Pith is reading between the lines
- The same boundary pattern could be applied to non-agent tool-use loops that also suffer from invisible side effects.
- Time-budget exposure might be generalized to token or memory limits in other agent scaffolds.
- Rule knowledge bases could be versioned and shared across teams to standardize acceptance criteria for similar tasks.
Load-bearing premise
Accuracy gains are produced by the LemonHarness mechanisms rather than by the choice of LLM backbone or other unstated experimental factors.
What would settle it
Run identical Terminal-Bench tasks on the same backbone model once inside LemonHarness and once without its boundary, rule base, or time signals, then compare accuracy and state-tracking error rates.
Figures
read the original abstract
As large language model (LLM) agents are applied to longer tasks, they increasingly modify workspace state across multiple rounds of iteration. However, agents typically observe only tool outputs and log fragments, while the actual state changes occur in the file system. Without explicit workspace boundaries, state-changing operations such as file writes and temporary artifact generation may scatter changes across paths. Over time, these weakly constrained changes accumulate, making states such as modified files difficult to track. This paper presents LemonHarness, an integrated execution framework for long-horizon agents. LemonHarness establishes an explicit execution boundary by constraining state-changing operations within a clearly defined workspace and bringing model invocation, tool execution, and rule knowledge within a single controlled boundary. State-changing operations, including file writes, dependency installation, and temporary artifact creation, are executed through structured tool interfaces, with execution feedback recorded as observations available to subsequent model decisions. The system also introduces a reusable rule knowledge base, which turns recurring execution rules and acceptance criteria into runtime knowledge. LemonHarness further adds a time-aware execution mechanism that exposes elapsed and remaining budget to the model, so it can rebalance exploration, implementation, and validation effort as time pressure shifts and avoid timeouts from long waits or excessive verification. On Terminal-Bench 2.0, LemonHarness_GPT-5.3-CodeX reached 84.49% accuracy over 445 trials; pairing the same framework with the stronger GPT-5.5 backbone raised the average accuracy to 86.52% across five jobs. The results suggest that a unified runtime boundary, callable rule knowledge, and time-aware execution can improve the stability of long-horizon agent execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LemonHarness, an execution framework for long-horizon LLM agents. It enforces an explicit workspace boundary for state-changing operations, supplies a callable reusable rule knowledge base, and exposes elapsed/remaining time to the model. On Terminal-Bench 2.0 the framework reports 84.49% accuracy (GPT-5.3-CodeX, 445 trials) and 86.52% accuracy (GPT-5.5).
Significance. If the performance gains can be causally attributed to the three mechanisms, the work would address a practical obstacle in agent reliability by reducing uncontrolled state drift and timeout failures. The absolute numbers are high, but without isolating experiments their contribution remains unverified.
major comments (1)
- [Abstract] Abstract: the central claim—that unified runtime boundary, callable rule knowledge, and time-aware execution improve long-horizon stability—rests solely on absolute accuracies for the integrated system. No control runs, ablations, or baseline results are reported for the identical LLM backbones under a standard agent loop without the workspace constraints, rule KB, or time exposure. Consequently the numbers cannot be attributed to the proposed mechanisms rather than model choice or other unstated factors.
Simulated Author's Rebuttal
Thank you for the review. We address the major comment on attribution of results below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim—that unified runtime boundary, callable rule knowledge, and time-aware execution improve long-horizon stability—rests solely on absolute accuracies for the integrated system. No control runs, ablations, or baseline results are reported for the identical LLM backbones under a standard agent loop without the workspace constraints, rule KB, or time exposure. Consequently the numbers cannot be attributed to the proposed mechanisms rather than model choice or other unstated factors.
Authors: We agree that the manuscript reports absolute accuracies only for the complete LemonHarness system and provides no ablation studies, control runs, or baselines with the same backbones under a standard agent loop. The abstract uses 'suggest' rather than claiming definitive causation. The contribution is the integrated framework and its benchmark results. We will revise the abstract to state explicitly that performance figures apply to the full system without isolated controls or attribution experiments. revision: partial
- Absence of ablation studies or control experiments isolating the contributions of workspace boundary, rule knowledge base, and time awareness.
Circularity Check
No derivation chain or equations; empirical benchmark report only
full rationale
The paper presents an engineering framework for LLM agents and reports absolute benchmark accuracies on Terminal-Bench 2.0. No equations, derivations, fitted parameters, or mathematical claims appear anywhere in the text. The central suggestion that the three mechanisms improve stability is supported solely by the reported numbers for the integrated system; there are no self-referential definitions, predictions derived from fitted inputs, or load-bearing self-citations that reduce any result to its own inputs by construction. The absence of any derivation chain makes circularity analysis inapplicable; the work is self-contained as an empirical technical report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(2025) SABER: Small actions, big errors– safeguarding mutating steps in LLM agents
Cuadron, A., Y u, P ., Liu, Y ., & Gupta, A. (2025) SABER: Small actions, big errors– safeguarding mutating steps in LLM agents. arXiv preprint arXiv:2512.07850
arXiv 2025
-
[2]
E., Lee, N., Kim, S., Moon, S., Furuta, H., Anumanchipalli, G., Keutzer, K., & Gholami, A
Erdogan, L. E., Lee, N., Kim, S., Moon, S., Furuta, H., Anumanchipalli, G., Keutzer, K., & Gholami, A. (2025) Plan-and-act: Improving planning of agents for long-horizon tasks. In F orty- second International Conference on Machine Learning (ICML)
2025
-
[3]
(2023) PAL: Program-aided language models
Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P ., Y ang, Y ., Callan, J., & Neubig, G. (2023) PAL: Program-aided language models. In International Conference on Machine Learning , pages 10764–10799. PMLR
2023
-
[4]
(2025) Enforcing tem- poral constraints for LLM agents
Kamath, A., Zhang, S., Xu, C., Ugare, S., Singh, G., & Misailovic, S. (2025) Enforcing tem- poral constraints for LLM agents. arXiv preprint arXiv:2512.23738
arXiv 2025
-
[5]
Lin, J., Liu, S., Pan, C., Lin, L., Dou, S., Huang, X., Y an, H., Han, Z., & Gui, T. (2026) Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses. arXiv preprint arXiv:2604.25850
Pith/arXiv arXiv 2026
-
[6]
(2025) UltraHorizon: Benchmarking agent capabilities in ultra long-horizon scenarios
Luo, H., Zhang, H., Zhang, X., Wang, H., Qin, Z., Lu, W., Ma, G., He, H., Xie, Y ., Zhou, Q., et al. (2025) UltraHorizon: Benchmarking agent capabilities in ultra long-horizon scenarios. arXiv preprint arXiv:2509.21766
arXiv 2025
-
[7]
Merrill, M. A., Shaw, A. G., Carlini, N., Li, B., Raj, H., Bercovich, I., Shi, L., Shin, J. Y ., Walshe, T., Buchanan, E. K., et al. (2026) Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint arXiv:2601.11868
Pith/arXiv arXiv 2026
-
[8]
Ning, X., Tieu, K., Fu, D., Wei, T., Li, Z., Bei, Y ., Zou, J., Ai, M., Liu, Z., Li, T.-W., et al. (2026) Code as agent harness. arXiv preprint arXiv:2605.18747
Pith/arXiv arXiv 2026
-
[9]
N., Parker-Holder, J., & Rocktäschel, T
Paglieri, D., Cupiał, B., Cook, J., Piterbarg, U., Tuyls, J., Grefenstette, E., Foerster, J. N., Parker-Holder, J., & Rocktäschel, T. (2025) Learning when to plan: Efficiently allocating test-time compute for LLM agents. arXiv preprint arXiv:2509.03581
arXiv 2025
-
[10]
(2023) Toolformer: Language models can teach themselves to use tools
Schick, T., Dwivedi-Y u, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023) Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems , 36:68539–68551
2023
-
[11]
(2026) EvoCode-Bench: Evaluating coding agents in multi-turn iterative interactions
Shen, H., Chen, X., Xu, W., Ma, Y ., Chen, L., & Li, K. (2026) EvoCode-Bench: Evaluating coding agents in multi-turn iterative interactions. arXiv preprint arXiv:2605.24110
Pith/arXiv arXiv 2026
-
[12]
(2023) Reflexion: Language agents with verbal reinforcement learning
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Y ao, S. (2023) Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems , 36:8634–8652
2023
-
[13]
(2025) OpenAI GPT-5 system card
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. (2025) OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267
Pith/arXiv arXiv 2025
-
[14]
(2026) EnvScaler: Scaling tool-interactive environments for llm agent via programmatic synthesis
Song, X., Chang, H., Dong, G., Zhu, Y ., Wen, J.-R., & Dou, Z. (2026) EnvScaler: Scaling tool-interactive environments for llm agent via programmatic synthesis. arXiv preprint arXiv:2601.05808
Pith/arXiv arXiv 2026
-
[15]
(2023) V oyager: An open-ended embodied agent with large language models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., & Anandkumar, A. (2023) V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291. 8
Pith/arXiv arXiv 2023
-
[16]
J., Bai, H., Sun, Y ., Wang, H., Zhang, S., Hu, W., Schroder, M., Mutlu, B., Song, D., & Nowak, R
Wang, X. J., Bai, H., Sun, Y ., Wang, H., Zhang, S., Hu, W., Schroder, M., Mutlu, B., Song, D., & Nowak, R. D. (2026) The long-horizon task mirage? Diagnosing where and why agentic systems break. arXiv preprint arXiv:2604.11978
Pith/arXiv arXiv 2026
-
[17]
E., Peng, B., Qin, S., Nath, S., Lin, Q., et al
Wang, Z., Wu, Q., Zhang, X., Zhang, C., Y ao, W., Faisal, F. E., Peng, B., Qin, S., Nath, S., Lin, Q., et al. (2026) WebXSkill: Skill learning for autonomous web agents. arXiv preprint arXiv:2604.13318
Pith/arXiv arXiv 2026
-
[18]
Xu, T., Wen, H., & Li, M. (2026) Adapting the interface, not the model: Runtime harness adaptation for deterministic LLM agents. arXiv preprint arXiv:2605.22166
Pith/arXiv arXiv 2026
-
[19]
(2026) SkillOpt: Executive strategy for self-evolving agent skills
Y ang, Y ., Gong, Z., Huang, W., Y ang, Q., Zhou, Z., Huang, Z., Li, Y ., Gao, X., Dai, Q., Liu, B., et al. (2026) SkillOpt: Executive strategy for self-evolving agent skills. arXiv preprint arXiv:2605.23904
Pith/arXiv arXiv 2026
-
[20]
(2022) ReAct: Syner- gizing reasoning and acting in language models
Y ao, S., Zhao, J., Y u, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y . (2022) ReAct: Syner- gizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[21]
(2024) ExpeL: LLM agents are experiential learners
Zhao, A., Huang, D., Xu, Q., Lin, M., Liu, Y .-J., & Huang, G. (2024) ExpeL: LLM agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence 38, pages 19632–19642. 9
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.