Can Aggregate Invariants Accelerate Continuous Subgraph Matching? Limits, Laws, and a Dynamic Spectral Index
Pith reviewed 2026-06-25 23:37 UTC · model grok-4.3
The pith
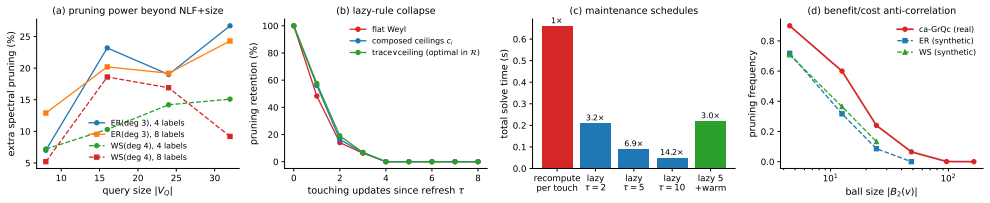
Spectral aggregate invariants accelerate candidate construction in continuous subgraph matching but leave enumeration intermediates unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lazily maintained spectral bounds are infeasible exactly where spectral pruning has value: the tightest safe rule over a formalized perturbation relaxation loses essentially all pruning power within four touching updates. Exact maintenance is affordable when selective: pruning utility and recomputation cost are anti-correlated across vertices, hubs provably never prune, and recomputing small-neighborhood spectra on touch sustains exact local spectra at microseconds per update, complete by construction. Integrated into a decoupled CSM benchmark, the tests remove up to 51% of candidates or safely skip up to 47% of update enumerations, yet enumeration intermediates remain unchanged beyond the g
What carries the argument
A reusable dynamic local-spectra index that recomputes exact Laplacian spectra only for touched low-degree vertices to enable selective pruning.
If this is right
- The tests accelerate construction and list scans that scale with candidate sets.
- Enumeration intermediates remain unchanged beyond the skipped first-level bindings.
- The index sustains exact local spectra at microseconds per update and is complete by construction.
- A radius-stratified workload confirms the method detects cases with large speedups such as 748 times faster.
Where Pith is reading between the lines
- If workloads shift so that deeper exploration dominates cost, the pruning benefit would shrink even if candidate reduction stays high.
- The cost-pruning anti-correlation observed for spectra may hold for other neighborhood-based aggregate invariants.
- The intermediate-invariance methodology could be used to assess filters in related dynamic graph problems such as continuous pattern mining.
Load-bearing premise
The dominant cost in continuous subgraph matching is first-level candidate construction rather than deeper adjacency-guided exploration, and the evaluated graphs contain enough low-degree vertices for selective exact maintenance to be effective.
What would settle it
A graph stream or workload in which deeper adjacency-guided exploration dominates runtime and candidate pruning produces no measurable reduction in total matching time would show the acceleration does not hold.
Figures


read the original abstract
Spectral filtering recently delivered substantial pruning for \emph{static} subgraph matching: Laplacian interlacing rejects candidates whose neighborhoods cannot host the query. We study whether such aggregate structural tests can accelerate \emph{continuous} subgraph matching (CSM) over dynamic graphs, and answer in three parts. First, lazily maintained spectral bounds are infeasible exactly where spectral pruning has value: we characterize the tightest safe rule over a formalized perturbation relaxation and show that even it loses essentially all pruning power within four touching updates. Second, exact maintenance is affordable when selective: pruning utility and recomputation cost are anti-correlated across vertices -- hubs provably never prune -- so recomputing small-neighborhood spectra on touch sustains exact local spectra at microseconds per update, complete by construction. Third, integrated into a decoupled CSM benchmark against an identical-minus-spectra control, the tests remove up to $51\%$ of candidates or safely skip up to $47\%$ of update enumerations, yet enumeration intermediates remain unchanged -- beyond the gates' skipped first-level bindings, typically zero -- across two engines, four real graphs, two stream types, and $77$ solved queries; a constructed radius-stratified workload confirms the instrument detects the exception when one exists ($-99.9\%$ intermediates, $748\times$ faster). Aggregate tests accelerate what scales with candidate sets -- construction, list scans -- never adjacency-guided exploration. We distill an intermediate-invariance methodology for evaluating CSM filters and release a reusable dynamic local-spectra index.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregate invariants such as spectral filtering via Laplacian interlacing can accelerate continuous subgraph matching (CSM) under selective exact maintenance of local spectra, despite lazy bounds losing all pruning power within four updates. It reports that the approach removes up to 51% of candidates or skips up to 47% of enumerations with enumeration intermediates unchanged beyond first-level bindings (typically zero) across two engines, four graphs, two streams, and 77 queries; a radius-stratified workload detects exceptions when present. It introduces an intermediate-invariance evaluation methodology and releases a reusable dynamic local-spectra index.
Significance. If the results hold, the work shows that aggregate structural tests can practically accelerate the candidate-set-dependent parts of CSM while clarifying limits of lazy maintenance and providing a reusable index plus an evaluation methodology for CSM filters. The release of the dynamic index and the explicit handling of the exception case via the stratified workload are concrete strengths.
major comments (2)
- [Abstract] Abstract, benchmark paragraph: the central empirical claims rest on concrete figures (51% candidate removal, 47% enumeration skips, typically zero deeper intermediates) across 77 queries with no error bars and no description of query selection or workload construction; this is load-bearing for the acceleration conclusion.
- [Perturbation relaxation] Perturbation relaxation section: the claim that even the tightest safe rule loses essentially all pruning power within four touching updates depends on the formalized perturbation relaxation, but no derivation or explicit characterization is provided in the abstract or summary, undermining verification of the infeasibility result.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments. We address each major point below and will make the indicated revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract, benchmark paragraph: the central empirical claims rest on concrete figures (51% candidate removal, 47% enumeration skips, typically zero deeper intermediates) across 77 queries with no error bars and no description of query selection or workload construction; this is load-bearing for the acceleration conclusion.
Authors: The abstract already states the workload spans two engines, four real graphs, two stream types, and 77 solved queries, with an explicitly constructed radius-stratified workload to detect exceptions. The reported figures are maxima ('up to') observed over this workload rather than means or averages, consistent with the paper's focus on existence of pruning power and its limits (rather than statistical performance); this is why error bars are omitted. We will revise the abstract to add one sentence describing query selection (standard benchmark queries solved by the engines, stratified by radius for coverage) and note the extremal reporting convention. revision: partial
-
Referee: [Perturbation relaxation] Perturbation relaxation section: the claim that even the tightest safe rule loses essentially all pruning power within four touching updates depends on the formalized perturbation relaxation, but no derivation or explicit characterization is provided in the abstract or summary, undermining verification of the infeasibility result.
Authors: The full derivation and characterization of the perturbation relaxation (updates touching at most k vertices) and the resulting four-update bound appear in the dedicated section. To improve standalone verifiability of the abstract, we will insert a short parenthetical: '(over a perturbation relaxation where touching updates affect at most k vertices, the tightest safe bound loses all power by k=4)'. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via analysis and benchmarks
full rationale
The paper's core claims rely on a formalized perturbation relaxation for spectral bounds, an anti-correlation argument for selective exact maintenance (with 'hubs provably never prune' presented as a derived property), and direct empirical measurements of candidate removal and enumeration skips across independent benchmarks. No quoted equations or steps reduce the reported pruning percentages, invariance results, or maintenance costs to fitted parameters, self-citations, or inputs by construction. The phrase 'complete by construction' describes the exactness of on-touch recomputation, a standard property independent of the target outcomes. The radius-stratified workload and multi-engine validation provide external falsifiability. This meets the criteria for a self-contained derivation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Laplacian interlacing theorems hold for the static case and can be relaxed under perturbation
invented entities (1)
-
Dynamic local-spectra index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ittai Abraham, David Durfee, Ioannis Koutis, Sebastian Krinninger, and Richard Peng. 2016. On Fully Dynamic Graph Sparsifiers. In57th IEEE Annual Symposium on Foundations of Computer Science, FOCS. 335–344. https://doi.org/10.1109/ FOCS.2016.44 9
2016
-
[2]
Junya Arai, Yasuhiro Fujiwara, and Makoto Onizuka. 2023. GuP: Fast Subgraph Matching by Guard-based Pruning.Proc. ACM Manag. Data1, 2 (2023). https: //doi.org/10.1145/3589312
-
[3]
Hua Bai. 2011. The Grone-Merris Conjecture.Trans. Amer. Math. Soc.363, 8 (2011), 4463–4474. https://doi.org/10.1090/S0002-9947-2011-05393-6
-
[4]
Bibek Bhattarai, Hang Liu, and H. Howie Huang. 2019. CECI: Compact Em- bedding Cluster Index for Scalable Subgraph Matching. InProceedings of the 2019 International Conference on Management of Data, SIGMOD. 1447–1462. https://doi.org/10.1145/3299869.3300086
-
[5]
Andries E. Brouwer and Willem H. Haemers. 2008. A lower bound for the Laplacian eigenvalues of a graph—proof of a conjecture by Guo.Linear Algebra Appl.429, 8-9 (2008), 2131–2135. https://doi.org/10.1016/j.laa.2008.06.008
-
[6]
Pin-Yu Chen, Baichuan Zhang, and Mohammad Al Hasan. 2018. Incremental eigenpair computation for graph Laplacian matrices: theory and applications. Soc. Netw. Anal. Min.8, 1 (2018), 4. https://doi.org/10.1007/s13278-017-0481-y
-
[7]
Xiangyang Gou, Lei Zou, Jeffrey Xu Yu, and Wenjie Zhang. 2026. An Extensive Experimental Study of Indexes in Continuous Subgraph Matching.Proc. ACM Manag. Data4, 1 (2026). https://doi.org/10.1145/3786623
-
[8]
Robert Grone and Russell Merris. 1994. The Laplacian Spectrum of a Graph II.SIAM J. Discrete Math.7, 2 (1994), 221–229. https://doi.org/10.1137/ S0895480191222653
1994
-
[9]
Myoungji Han, Hyunjoon Kim, Geonmo Gu, Kunsoo Park, and Wook-Shin Han. 2019. Efficient Subgraph Matching: Harmonizing Dynamic Programming, Adaptive Matching Order, and Failing Set Together. InProceedings of the 2019 International Conference on Management of Data, SIGMOD. 1429–1446. https: //doi.org/10.1145/3299869.3319880
-
[10]
Huahai He and Ambuj K. Singh. 2008. Graphs-at-a-time: Query Language and Access Methods for Graph Databases. InProceedings of the 2008 ACM SIGMOD International Conference on Management of Data. 405–418. https://doi.org/10. 1145/1376616.1376660
arXiv 2008
-
[11]
Horn and Charles R
Roger A. Horn and Charles R. Johnson. 2013.Matrix Analysis(2nd ed.). Cam- bridge University Press
2013
-
[12]
Chathura Kankanamge, Siddhartha Sahu, Amine Mhedhbi, Jeremy Chen, and Semih Salihoglu. 2017. Graphflow: An Active Graph Database. InProceedings of the 2017 ACM International Conference on Management of Data, SIGMOD. 1695–1698. https://doi.org/10.1145/3035918.3056445
-
[13]
Kyoungmin Kim, In Seo, Wook-Shin Han, Jeong-Hoon Lee, Sungpack Hong, Hassan Chafi, Hyungyu Shin, and Geonhwa Jeong. 2018. TurboFlux: A Fast Continuous Subgraph Matching System for Streaming Graph Data. InProceedings of the 2018 International Conference on Management of Data, SIGMOD. 411–426. https://doi.org/10.1145/3183713.3196917
-
[14]
Jinsoo Lee, Wook-Shin Han, Romans Kasperovics, and Jeong-Hoon Lee. 2012. An In-depth Comparison of Subgraph Isomorphism Algorithms in Graph Databases. Proc. VLDB Endow.6, 2 (2012), 133–144. https://doi.org/10.14778/2535568.2448946
-
[15]
Yukyoung Lee, Kyoungmin Kim, Wonseok Lee, and Wook-Shin Han. 2024. In- depth Analysis of Continuous Subgraph Matching in a Common Delta Query Compilation Framework.Proc. ACM Manag. Data2, 3 (2024). https://doi.org/10. 1145/3654950
2024
-
[16]
Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data
2014
-
[17]
Ziming Li, Youhuan Li, Xinhuan Chen, Lei Zou, Yang Li, Xiaofeng Yang, and Hongbo Jiang. 2024. NewSP: A New Search Process for Continuous Subgraph Matching over Dynamic Graphs. In40th IEEE International Conference on Data Engineering, ICDE. 3324–3337. https://doi.org/10.1109/ICDE60146.2024.00257
-
[18]
Amine Mhedhbi and Semih Salihoglu. 2019. Optimizing Subgraph Queries by Combining Binary and Worst-Case Optimal Joins.Proc. VLDB Endow.12, 11 (2019), 1692–1704. https://doi.org/10.14778/3342263.3342643
-
[19]
Seunghwan Min, Sung Gwan Park, Kunsoo Park, Dora Giammarresi, Giuseppe F. Italiano, and Wook-Shin Han. 2021. Symmetric Continuous Subgraph Matching with Bidirectional Dynamic Programming.Proc. VLDB Endow.14, 8 (2021), 1298–1310. https://doi.org/10.14778/3457390.3457395
-
[20]
Konstantinos Skitsas, Davide Mottin, and Panagiotis Karras. 2025. Pilos: Scalable Large-Subgraph Matching by Online Spectral Filtering. In41st IEEE International Conference on Data Engineering, ICDE. https://doi.org/10.1109/ICDE65448.2025. 00093
-
[21]
Shixuan Sun and Qiong Luo. 2020. In-Memory Subgraph Matching: An In-depth Study. InProceedings of the 2020 International Conference on Management of Data, SIGMOD. 1083–1098. https://doi.org/10.1145/3318464.3380581
-
[22]
Shixuan Sun, Xibo Sun, Bingsheng He, and Qiong Luo. 2022. RapidFlow: An Efficient Approach to Continuous Subgraph Matching.Proc. VLDB Endow.15, 11 (2022), 2415–2427. https://doi.org/10.14778/3551793.3551803
-
[23]
Xibo Sun, Shixuan Sun, Qiong Luo, and Bingsheng He. 2022. An In-Depth Study of Continuous Subgraph Matching.Proc. VLDB Endow.15, 7 (2022), 1403–1416. https://doi.org/10.14778/3523210.3523218
-
[24]
Zhao Sun, Hongzhi Wang, Haixun Wang, Bin Shao, and Jianzhong Li. 2012. Efficient Subgraph Matching on Billion Node Graphs.Proc. VLDB Endow.5, 9 (2012), 788–799. https://doi.org/10.14778/2311906.2311907
-
[25]
Xi Wang, Qianzhen Zhang, Deke Guo, and Xiang Zhao. 2023. A survey of continuous subgraph matching for dynamic graphs.Knowl. Inf. Syst.65, 3 (2023), 945–989. https://doi.org/10.1007/s10115-022-01753-x
-
[26]
Rongjian Yang, Zhijie Zhang, Weiguo Zheng, and Jeffrey Xu Yu. 2023. Fast Con- tinuous Subgraph Matching over Streaming Graphs via Backtracking Reduction. Proc. ACM Manag. Data1, 1 (2023), 15:1–15:26. https://doi.org/10.1145/3588695
-
[27]
Yutong Ye, Xiang Lian, Nan Zhang, and Mingsong Chen. 2025. Continuous Sub- graph Matching via Cost-Model-based Dynamic Vertex Dominance Embeddings. Proc. ACM Manag. Data3, 6 (2025). https://doi.org/10.1145/3769774
-
[28]
Zhijie Zhang, Yujie Lu, Weiguo Zheng, and Xuemin Lin. 2024. A Comprehensive Survey and Experimental Study of Subgraph Matching: Trends, Unbiasedness, and Interaction.Proc. ACM Manag. Data2, 1 (2024). https://doi.org/10.1145/ 3639315 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.