S1-Omni-Image: A Unified Model for Scientific Image Understanding, Generation, and Editing
Pith reviewed 2026-06-26 00:18 UTC · model grok-4.3
The pith
A single model handles scientific image understanding, generation, and editing by first producing a reasoning trace whose hidden states then condition the output images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
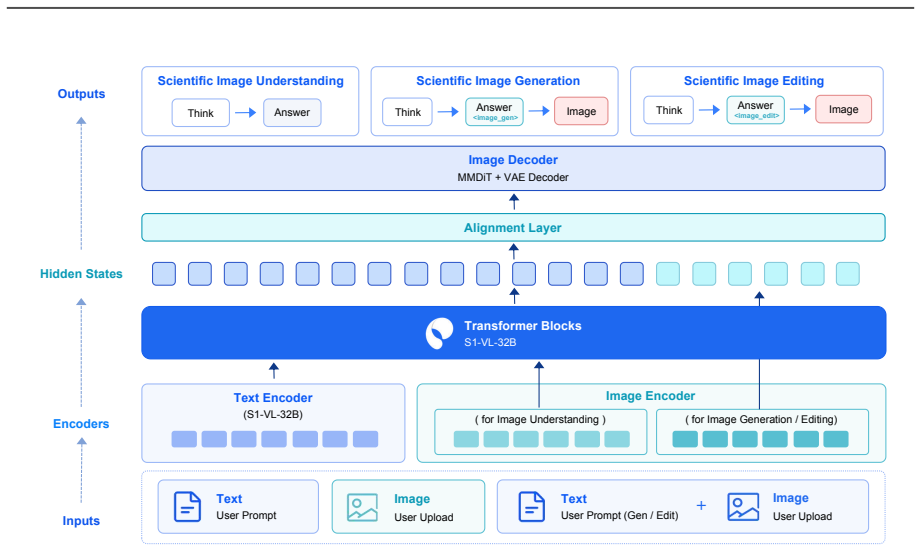
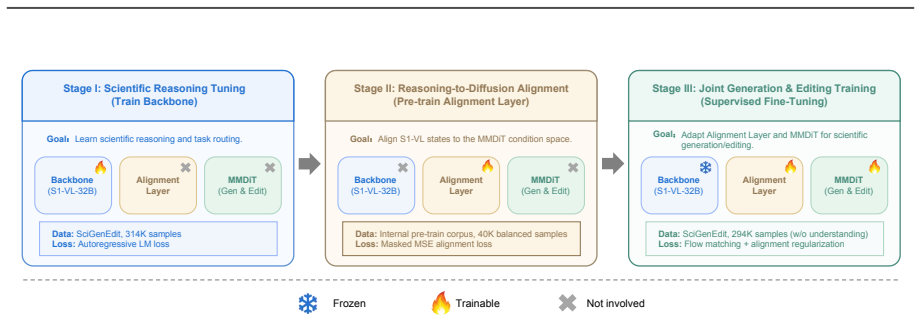
S1-Omni-Image couples the understanding capability of S1-VL-32B with an image generation module under a unified think-before-generate paradigm. Given a user instruction, the model first produces a task-oriented reasoning trace, a textual answer, and a task special token; their hidden states are then injected into the generation module to condition image generation or editing.
What carries the argument
The think-before-generate paradigm, in which hidden states from the reasoning trace and task special token are injected into the generation module to condition outputs on scientific semantics and domain knowledge.
If this is right
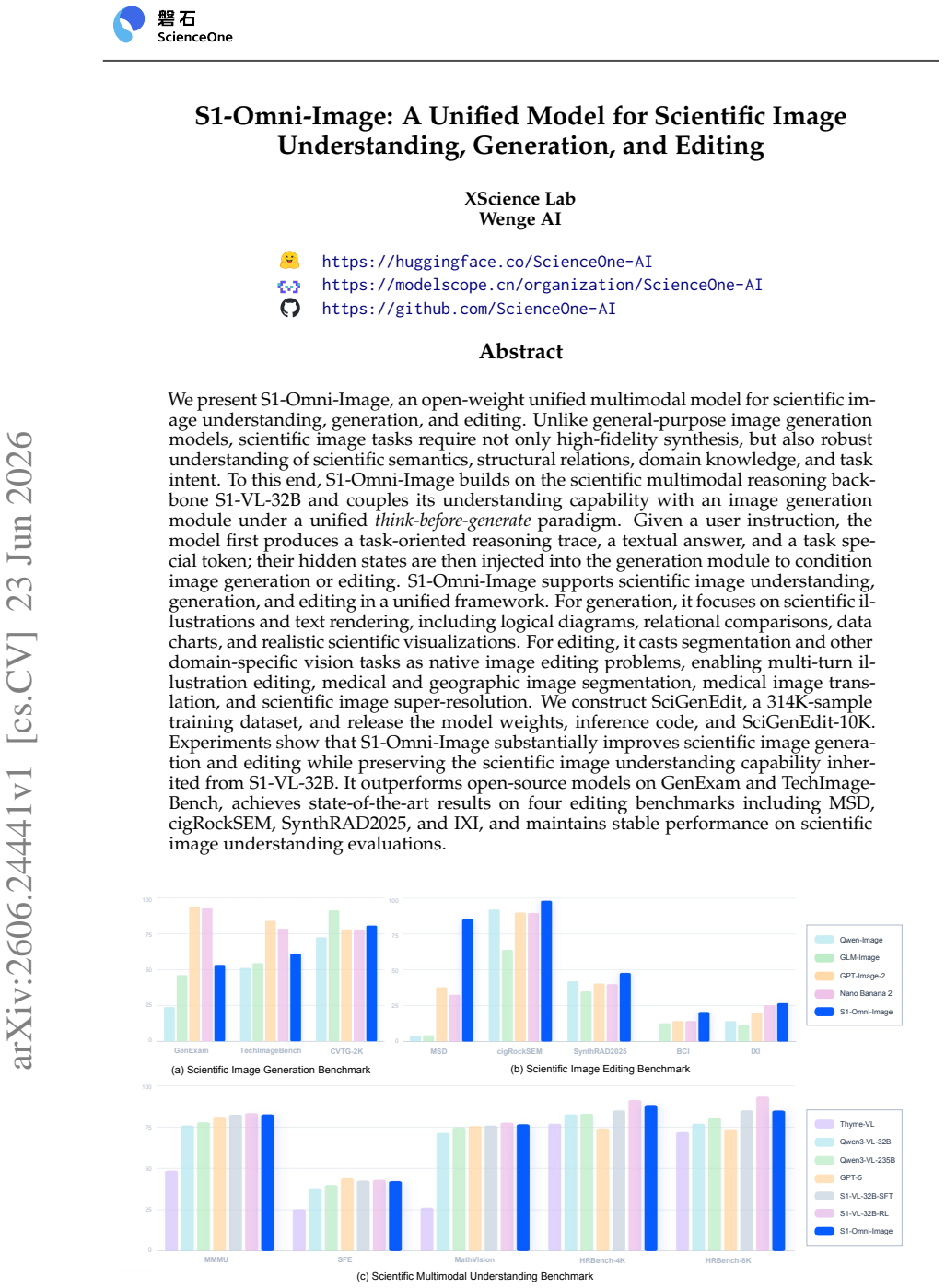
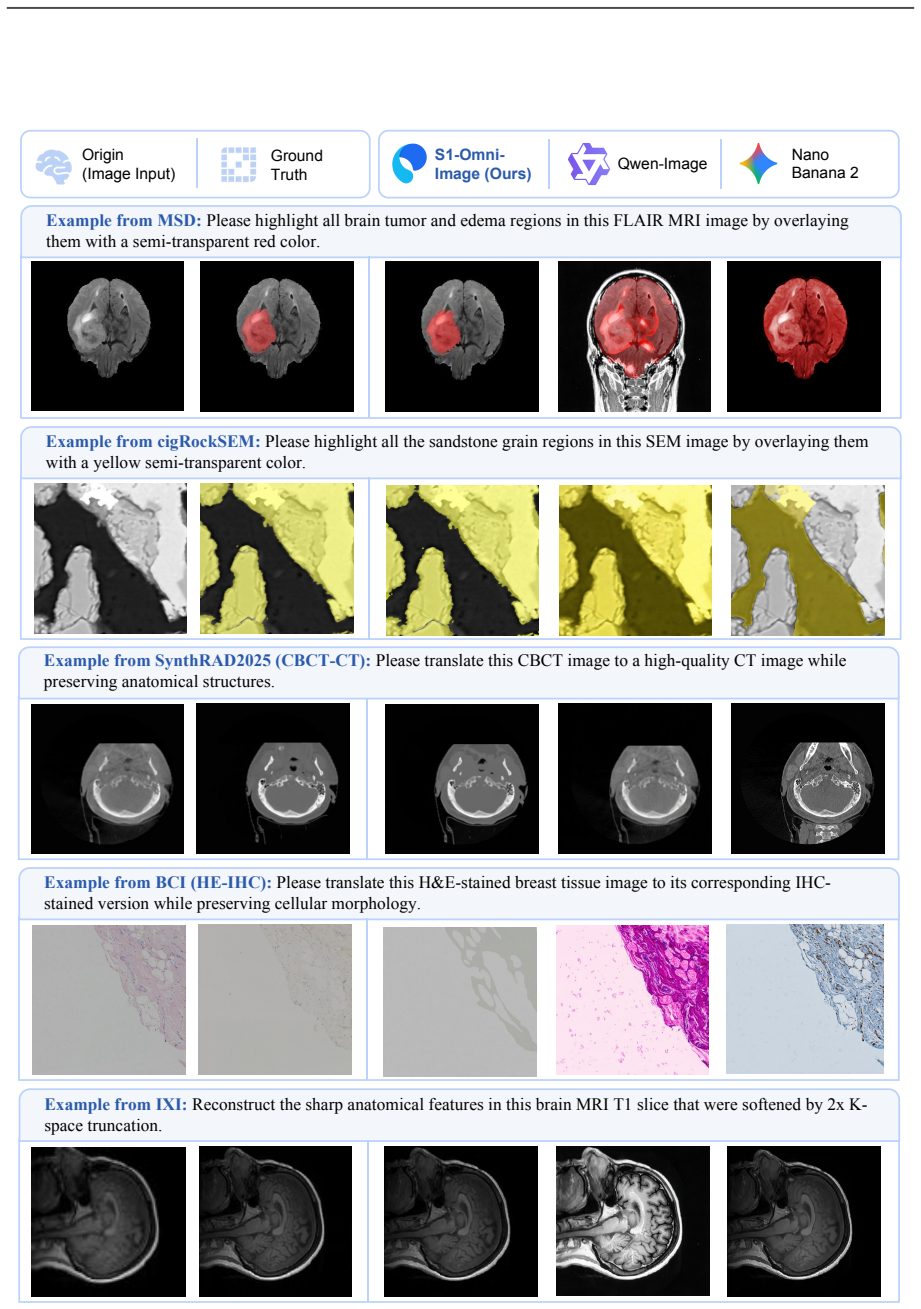
- The model outperforms open-source models on GenExam and TechImage-Bench for scientific image generation.
- It achieves state-of-the-art results on four editing benchmarks: MSD, cigRockSEM, SynthRAD2025, and IXI.
- It preserves stable performance on scientific image understanding evaluations inherited from the base model.
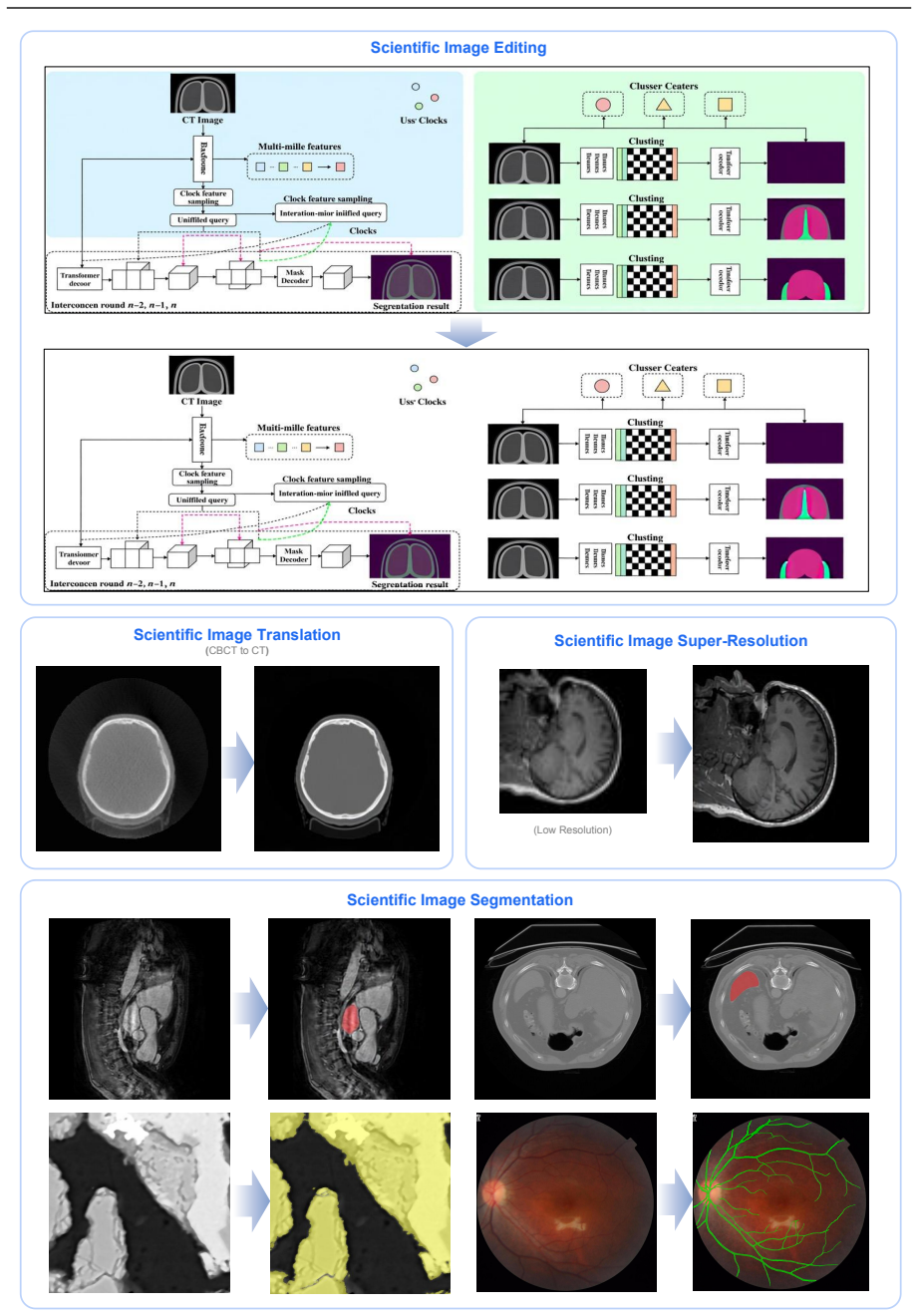
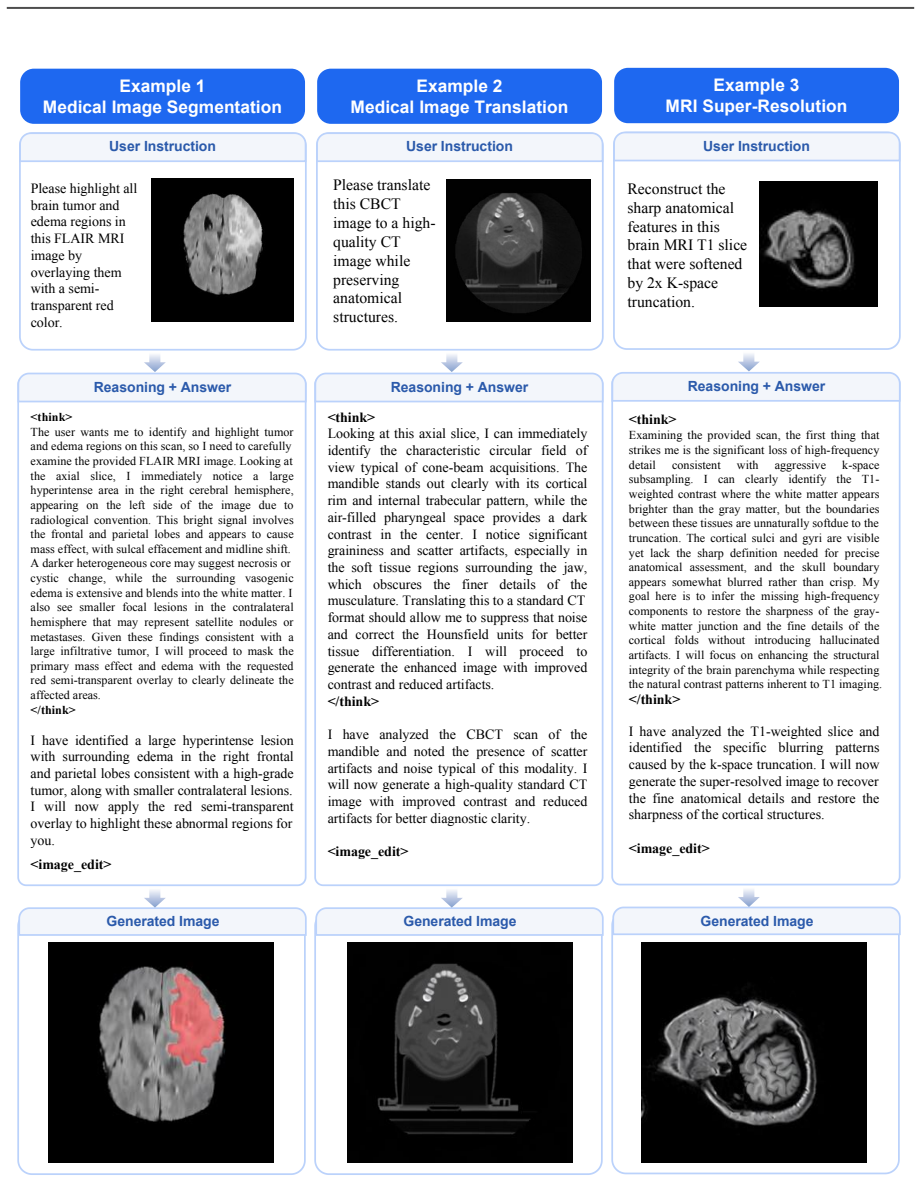
- Scientific tasks such as segmentation, medical image translation, and super-resolution can be cast as native image editing problems within the same framework.
- The approach supports multi-turn illustration editing and text rendering in logical diagrams and data charts.
Where Pith is reading between the lines
- The same injection mechanism might allow the model to accept external knowledge sources as additional conditioning tokens without retraining the generation weights.
- Extending the paradigm to video or 3D scientific data would test whether the reasoning-to-generation bridge generalizes beyond static images.
- If the hidden-state conditioning proves robust, separate task-specific models for understanding versus synthesis could become unnecessary in scientific pipelines.
- The released SciGenEdit dataset could serve as a starting point for testing whether other reasoning backbones produce usable conditioning states for image tasks.
Load-bearing premise
Hidden states from the reasoning trace can be injected into the generation module to reliably condition image outputs on scientific semantics, structural relations, and domain knowledge without further task-specific adaptation or loss of fidelity.
What would settle it
An ablation that removes the hidden-state injection from the generation module and measures the resulting drop on the MSD, cigRockSEM, SynthRAD2025, and IXI editing benchmarks would show whether the conditioning step is required for the reported gains.
Figures







read the original abstract
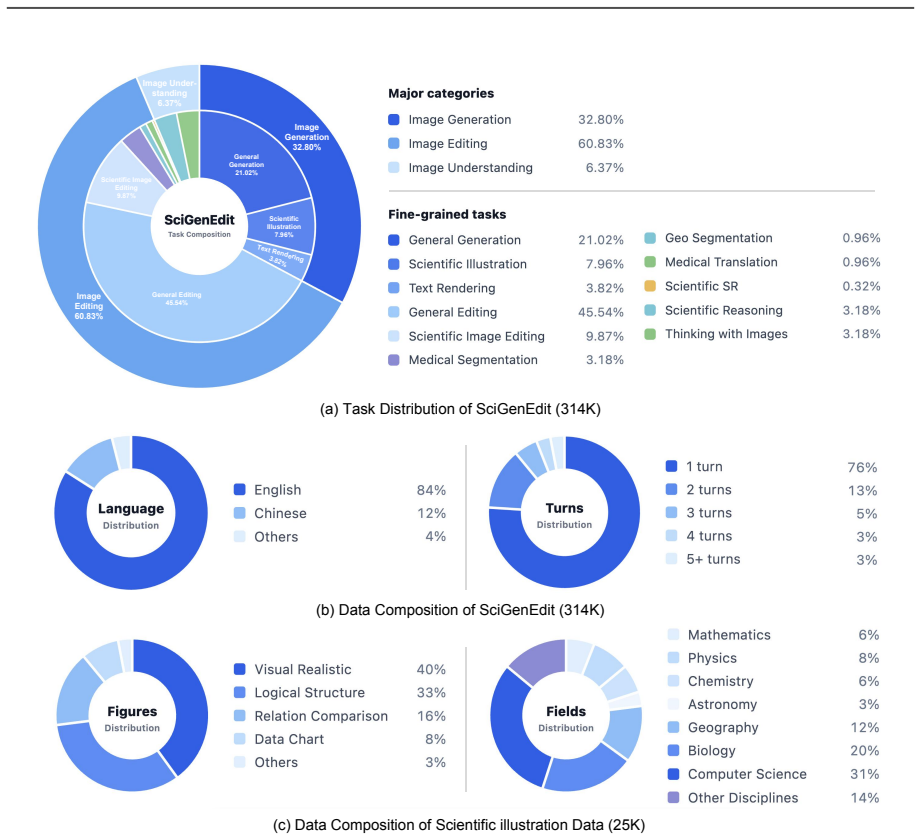
We present S1-Omni-Image, an open-weight unified multimodal model for scientific image understanding, generation, and editing. Unlike general-purpose image generation models, scientific image tasks require not only high-fidelity synthesis, but also robust understanding of scientific semantics, structural relations, domain knowledge, and task intent. To this end, S1-Omni-Image builds on the scientific multimodal reasoning backbone S1-VL-32B and couples its understanding capability with an image generation module under a unified think-before-generate paradigm. Given a user instruction, the model first produces a task-oriented reasoning trace, a textual answer, and a task special token; their hidden states are then injected into the generation module to condition image generation or editing. S1-Omni-Image supports scientific image understanding, generation, and editing in a unified framework. For generation, it focuses on scientific illustrations and text rendering, including logical diagrams, relational comparisons, data charts, and realistic scientific visualizations. For editing, it casts segmentation and other domain-specific vision tasks as native image editing problems, enabling multi-turn illustration editing, medical and geographic image segmentation, medical image translation, and scientific image super-resolution. We construct SciGenEdit, a 314K-sample training dataset, and release the model weights, inference code, and SciGenEdit-10K. Experiments show that S1-Omni-Image substantially improves scientific image generation and editing while preserving the scientific image understanding capability inherited from S1-VL-32B. It outperforms open-source models on GenExam and TechImage-Bench, achieves state-of-the-art results on four editing benchmarks including MSD, cigRockSEM, SynthRAD2025, and IXI, and maintains stable performance on scientific image understanding evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents S1-Omni-Image, an open-weight unified multimodal model extending the S1-VL-32B scientific reasoning backbone for image understanding, generation, and editing. It employs a think-before-generate paradigm in which a task-oriented reasoning trace, textual answer, and task special token are first produced; their hidden states are then injected into a generation module to condition outputs on scientific semantics, structural relations, and domain knowledge. The model is trained on the newly introduced SciGenEdit dataset (314K samples) and evaluated on generation benchmarks (GenExam, TechImage-Bench) and editing benchmarks (MSD, cigRockSEM, SynthRAD2025, IXI), with claims of substantial improvements over open-source models, SOTA editing performance, and preserved understanding capability.
Significance. If the results hold, the work provides a concrete step toward unified scientific multimodal models that integrate reasoning with controllable generation and editing, which could benefit domains requiring high-fidelity, semantically accurate imagery. The explicit release of model weights, inference code, and the SciGenEdit-10K subset is a clear strength for reproducibility and downstream use.
major comments (2)
- [Experiments] Experiments section: The reported gains on GenExam, TechImage-Bench, and the four editing benchmarks are end-to-end results only; no ablations are described that test the contribution of the injected hidden states from the reasoning trace and task special token (e.g., zeroing the states, replacing with random vectors, or comparing against direct text conditioning). This mechanism is load-bearing for the central claim that the think-before-generate paradigm transfers S1-VL-32B understanding without further adaptation or fidelity loss.
- [Method] Method section (architecture description): The precise mechanism for injecting the hidden states into the generation module, including any additional parameters, alignment losses, or training stages required for the coupling, is not detailed enough to assess whether the conditioning reliably preserves scientific semantics or introduces artifacts.
minor comments (1)
- [Abstract] Abstract: The SOTA and 'substantially improves' claims would be strengthened by explicit mention of the primary competing methods and quantitative margins even at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported gains on GenExam, TechImage-Bench, and the four editing benchmarks are end-to-end results only; no ablations are described that test the contribution of the injected hidden states from the reasoning trace and task special token (e.g., zeroing the states, replacing with random vectors, or comparing against direct text conditioning). This mechanism is load-bearing for the central claim that the think-before-generate paradigm transfers S1-VL-32B understanding without further adaptation or fidelity loss.
Authors: We agree that the manuscript would be strengthened by explicit ablations isolating the role of the injected hidden states. The current end-to-end results and comparisons to open-source baselines demonstrate overall gains, but do not directly quantify the contribution of the reasoning trace and task token states. In the revised manuscript we will add ablation studies in the Experiments section, including variants that zero the states, replace them with random vectors, and compare against direct text conditioning, to directly test the load-bearing claim. revision: yes
-
Referee: [Method] Method section (architecture description): The precise mechanism for injecting the hidden states into the generation module, including any additional parameters, alignment losses, or training stages required for the coupling, is not detailed enough to assess whether the conditioning reliably preserves scientific semantics or introduces artifacts.
Authors: We acknowledge that the current method description is insufficiently detailed on the injection process. In the revised manuscript we will expand the architecture subsection to specify the exact injection mechanism (e.g., cross-attention layers or concatenation), any newly introduced parameters, the alignment losses employed, and the staged training procedure used to couple the reasoning backbone with the generation module. This will enable readers to evaluate semantic preservation and potential artifacts. revision: yes
Circularity Check
No significant circularity in model construction or empirical claims
full rationale
The paper describes an architectural extension of the S1-VL-32B backbone by injecting hidden states from a reasoning trace and task token into a new generation module under a think-before-generate paradigm, then reports end-to-end benchmark results on GenExam, TechImage-Bench, MSD, cigRockSEM, SynthRAD2025, and IXI plus stable understanding performance. No equations, fitted parameters, or first-principles derivations are presented that reduce by construction to the inputs; the central claims rest on the new SciGenEdit dataset and external benchmark comparisons rather than self-referential definitions or load-bearing self-citations. The inheritance of understanding capability from the cited base model is a standard transfer step and does not create a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-vl: A frontier large vision-language model with versatile abilities
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966,
-
[2]
Intern-s1: A scientific multimodal foundation model
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model. arXiv preprint arXiv:2508.15763, 2025a. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Q...
-
[3]
28 Valentin Boussot, Cédric Hémon, Jean-Claude Nunes, and Jean-Louis Dillenseger
Accessed 2026-06-05. 28 Valentin Boussot, Cédric Hémon, Jean-Claude Nunes, and Jean-Louis Dillenseger. Why registra- tion quality matters: Enhancing sct synthesis with impact-based registration. arXiv preprint arXiv:2510.21358,
arXiv 2026
-
[4]
Gmai-mmbench: A comprehensive multimodal evaluation bench- mark towards general medical ai
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, et al. Gmai-mmbench: A comprehensive multimodal evaluation bench- mark towards general medical ai. Advances in Neural Information Processing Systems , 37:94327–94427, 2024a. Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, ...
-
[5]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pp. 24185–24198, 2024b. Gheorghe Comanici, Eric B...
-
[6]
Diffedit: Diffusion-based semantic image editing with mask guidance
Guillaume Couairon, Jakob V erbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv preprint arXiv:2210.11427,
-
[7]
Emerging properties in unified multimodal pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683,
-
[8]
Textcrafter: Accurately rendering multiple texts in complex visual scenes
Nikai Du, Zhennan Chen, Zhizhou Chen, Shan Gao, Xi Chen, Zhengkai Jiang, Jian Yang, and Ying Tai. Textcrafter: Accurately rendering multiple texts in complex visual scenes. arXiv preprint arXiv:2503.23461,
-
[9]
Seed-x: Multimodal models with unified multi-granularity comprehension and generation
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Ding Xiaohan, and Ying Shan. Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396,
-
[10]
Dai, Anja Hauth, Katie Millican, et al
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805,
-
[11]
arXiv:2509.14232. Luyi Han, Tao Tan, Yunzhi Huang, Haoran Dou, Tianyu Zhang, Yuan Gao, Xin Wang, Chunyao Lu, Xinglong Liang, Yue Sun, et al. All-in-one medical image-to-image translation. Cell Reports Methods, 5 (8):101138,
-
[12]
Prompt-to- prompt image editing with cross attention control
Amir Hertz, Ron Mokady , Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626,
-
[13]
Lance: Unified multimodal modeling by multi-task synergy
Lance Team. Lance: Unified multimodal modeling by multi-task synergy . arXiv preprint arXiv:2605.18678,
-
[14]
S1-vl: Scientific multimodal reasoning model with thinking-with-images
Qingxiao Li, Lifeng Xu, Qingli Wang, Yudong Bai, Mingwei Ou, Shu Hu, and Nan Xu. S1-vl: Scientific multimodal reasoning model with thinking-with-images. arXiv preprint arXiv:2604.21409,
-
[15]
Step1x-edit: A practical framework for general image editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761, 2025b. Zhiheng Liu, Weiming Ren, Haozhe Liu, Zijian Zhou, Shoufa Chen, Haonan Qiu, Xiaoke Huang, Zhao- chong An, Fanny Yang, Aditya Pate...
-
[16]
Techimage-bench: Rubric- based evaluation for professional image generation
Minheng Ni, Zhengyuan Yang, Yaowen Zhang, Linjie Li, Chung-Ching Lin, Kevin Lin, Zhendong Wang, Xiaofei Wang, Shujie Liu, Lei Zhang, Wangmeng Zuo, and Lijuan Wang. Techimage-bench: Rubric- based evaluation for professional image generation. arXiv preprint arXiv:2512.12220,
-
[17]
Rodríguez, David Vázquez, Issam H
Juan A. Rodríguez, David Vázquez, Issam H. Laradji, Marco Pedersoli, and Pau Rodríguez. Figgen: Text to scientific figure generation. arXiv preprint arXiv:2306.00800,
-
[18]
Aaditya Singh, Adam Fry , Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky , Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267,
-
[19]
Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers
30 Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers. arXiv preprint arXiv:2506.23918,
-
[20]
Generative multimodal models are in-context learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal models are in-context learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 14398–14409, 2024a. Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, ...
2024
-
[21]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, et al. Qwen-image technical report. arXiv preprint arXiv:2508.02324, 2025a. Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal under- standing and generation. In Proceedings ...
-
[22]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. In International Conference on Learning Representations , vol- ume 2025, pp. 28240–28264,
2025
-
[23]
Imgedit: A unified image editing dataset and benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark. arXiv preprint arXiv:2505.20275,
-
[24]
A benchmark dataset and baseline methods for rock mi- crostructure interpretation in sem images
Yao Zhang, Xinming Wu, and Jiachun You. A benchmark dataset and baseline methods for rock mi- crostructure interpretation in sem images. Scientific Data, 12(1):1671, 2025a. 31 Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images. arXiv preprint arXiv:2508.116...
-
[25]
Autofigure: Generating and refining publication-ready scientific illustrations
Minjun Zhu, Zhen Lin, Yixuan Weng, Panzhong Lu, Qiujie Xie, Yifan Wei, Sifan Liu, Qiyao Sun, and Yue Zhang. Autofigure: Generating and refining publication-ready scientific illustrations. arXiv preprint arXiv:2602.03828,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.