What Do Flow-Based Inverse Solvers Approximate? A Posterior-Transport View
Pith reviewed 2026-06-30 09:49 UTC · model grok-4.3
The pith
For deterministic flow priors, Bayesian conditioning is realized entirely by reweighting the source distribution, so that pushing it through the unmodified velocity field yields exact posterior samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
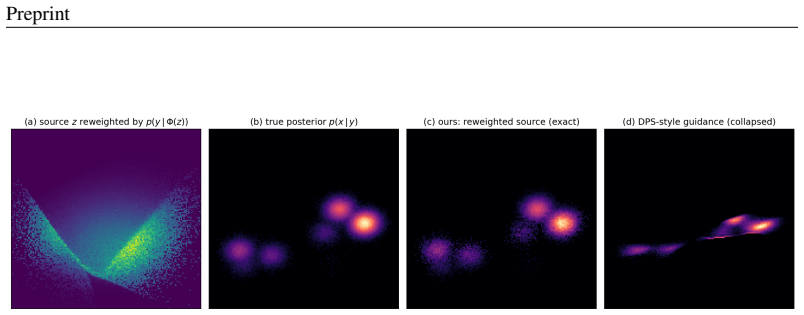
For a deterministic flow prior, Bayesian conditioning is realized entirely by a reweighting of the source distribution, not by a drift correction; pushing the reweighted source through the unmodified velocity field yields exact posterior samples. Trajectory-guidance solvers can be read as the minimum-kinetic-energy correction field needed to morph the unconditional source into the posterior, and FlowDPS, FLOWER and PnP-Flow correspond to distinct zeroth-order, Gaussian and proximal approximations of this single object, with the resulting posterior bias bounded in Wasserstein distance.
What carries the argument
Reweighting of the source distribution under the deterministic probability-flow ODE, which performs exact posterior transport without any modification to the velocity field.
If this is right
- Trajectory-guidance solvers correspond to distinct zeroth-order, Gaussian or proximal approximations of the minimal-kinetic-energy correction field.
- These approximations produce bounded but strictly positive Wasserstein bias relative to the true posterior.
- Source reweighting followed by the unmodified ODE recovers the posterior to Monte-Carlo accuracy.
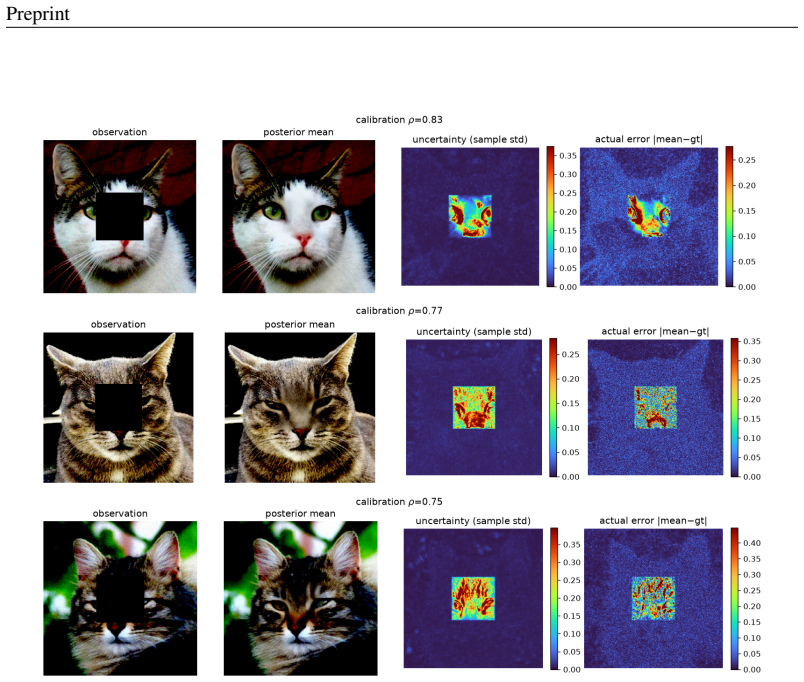
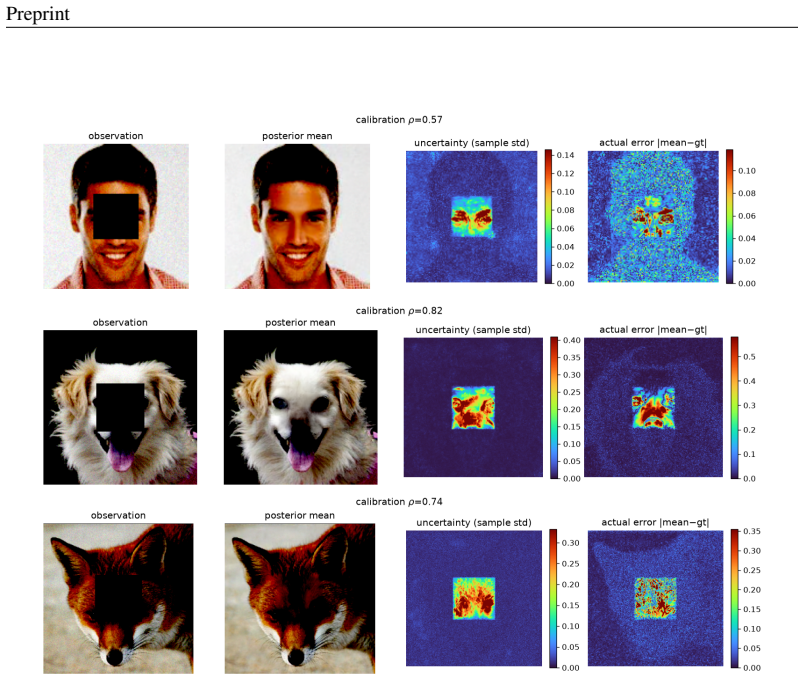
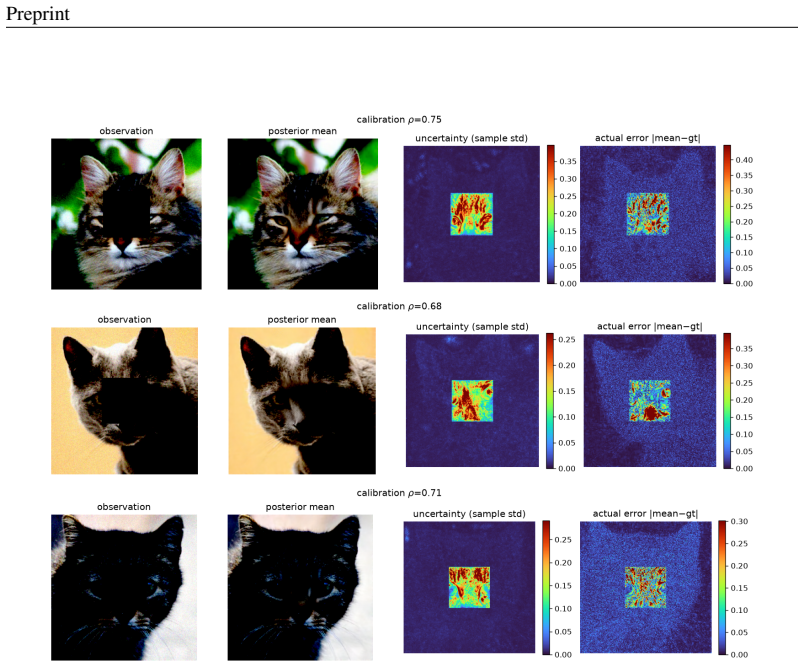
- The proposed velocity-correction solver yields diverse posterior samples whose uncertainty correlates with reconstruction error across in-domain and out-of-distribution priors.
Where Pith is reading between the lines
- The same reweighting perspective may apply to other deterministic transport models beyond flow matching.
- When the source weights can be evaluated exactly, reweighting should be preferred over any per-step guidance term to preserve posterior multimodality.
- Source-space optimization methods can be compared directly to the reweighting baseline to quantify how much diversity they lose.
- The analysis suggests testing whether the observed mode collapse persists when the guidance strength is annealed rather than held constant.
Load-bearing premise
The prior is given by a deterministic probability-flow ODE.
What would settle it
A controlled 2D experiment with closed-form posterior in which source reweighting matches the true posterior to Monte-Carlo floor error while trajectory guidance produces 200-800 times larger error on every metric.
Figures

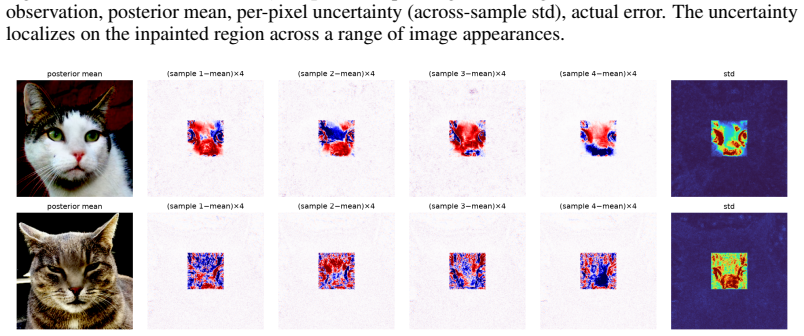
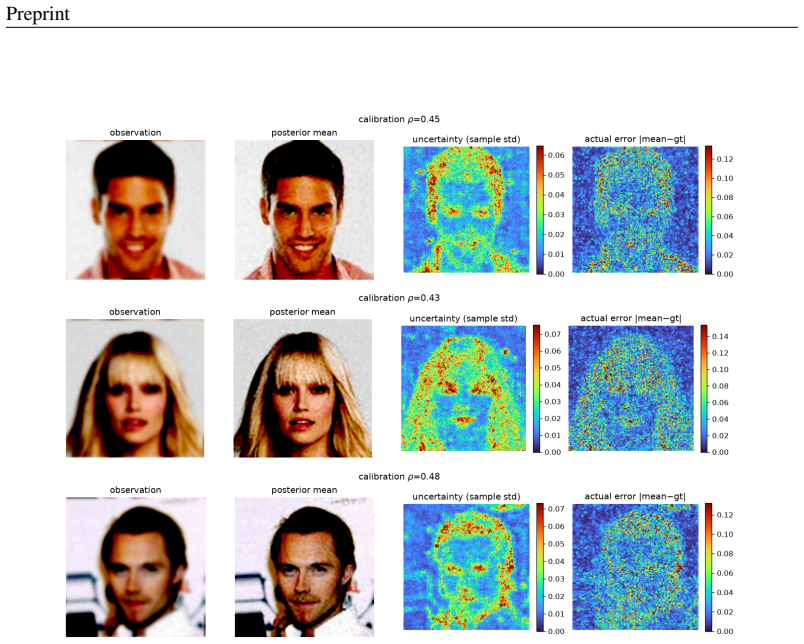
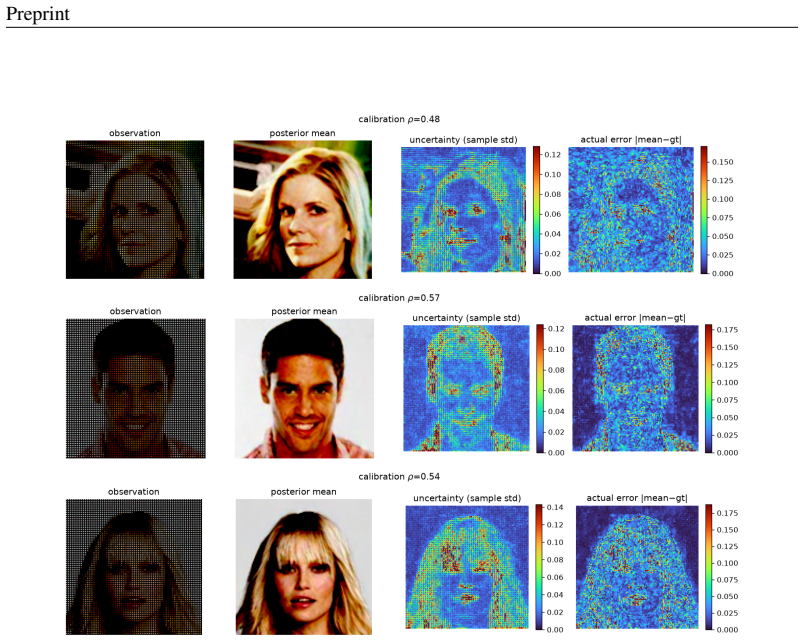
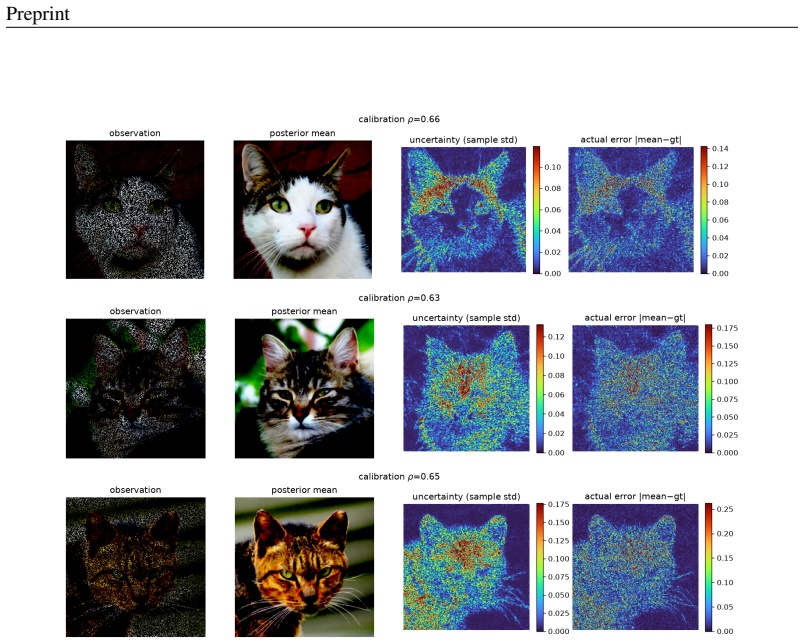
read the original abstract
A growing family of training-free solvers -- FlowDPS, FLOWER, PnP-Flow and their diffusion ancestors (DPS, DAPS) -- repurpose a pretrained flow-matching prior to solve imaging inverse problems by adding a measurement-guidance term to the deterministic probability-flow ODE. Despite strong empirical results, what these per-step corrections actually approximate -- and how far the resulting samples are from the true posterior $p(x\mid y)$ -- has not been characterized. We give a posterior-transport account of flow-based inverse problem solving. Our starting point is a simple but consequential fact: for a \emph{deterministic} flow prior, Bayesian conditioning is realized entirely by a \emph{reweighting of the source distribution}, not by a drift correction; pushing the reweighted source through the \emph{unmodified} velocity field yields exact posterior samples. From this we show that trajectory-guidance solvers can be read as the minimum-kinetic-energy \emph{correction} field needed to morph the unconditional source into the posterior, and that FlowDPS / FLOWER / PnP-Flow correspond to distinct zeroth-order / Gaussian / proximal approximations of this single object; we bound the resulting posterior bias in Wasserstein distance. A controlled $2$D study with a closed-form posterior confirms the theory decisively: source reweighting matches the true posterior to the Monte-Carlo floor on every metric, whereas trajectory guidance incurs $200$--$800\times$ larger error and collapses posterior modes, \emph{regardless of guidance strength}. Guided by the analysis we propose a cheap, principled velocity-correction solver that is competitive across two in-domain priors (AFHQ, CelebA) and two out-of-distribution settings while, unlike point-estimate source-space optimizers, producing diverse posterior samples with uncertainty that correlates with reconstruction error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Bayesian conditioning for a deterministic probability-flow ODE prior is realized exactly by reweighting the source measure by the likelihood factor and transporting the result with the unmodified velocity field; existing trajectory-guidance solvers (FlowDPS, FLOWER, PnP-Flow) are interpreted as distinct zeroth-order/Gaussian/proximal approximations to the minimum-kinetic-energy correction field that would map the unconditional source to the posterior; Wasserstein bounds on the induced bias are stated; a controlled 2D experiment with closed-form posterior confirms that source reweighting matches the true posterior to Monte-Carlo precision while guidance incurs 200–800× larger error and collapses modes; a new velocity-correction solver is proposed and shown competitive on AFHQ/CelebA in- and out-of-distribution tasks while producing diverse samples whose uncertainty correlates with reconstruction error.
Significance. If the central transport argument and bounds hold, the work supplies a clean posterior-transport account that explains why reweighting is exact and why guidance methods are biased approximations. The reproducible 2D closed-form experiment that matches theory to Monte-Carlo floor on every metric, together with the practical demonstration that the proposed solver yields diverse posterior samples, constitutes a concrete strength. The analysis could usefully inform the design of training-free flow-based inverse solvers.
minor comments (3)
- [Analysis of guidance methods] § on the minimum-kinetic-energy correction field: the precise definition of the kinetic-energy functional and the optimality condition that yields the correction field should be written explicitly (including any regularity assumptions on the velocity field) so that the subsequent approximation hierarchy is immediately verifiable.
- [Bias bounds] The Wasserstein bias bound is invoked to quantify the gap between guidance and the true posterior; the dependence of the bound on the guidance strength parameter and on the Lipschitz constant of the velocity field should be stated explicitly.
- [2D experiment] Figure captions for the 2D study should list the exact Monte-Carlo sample size, the precise metrics (Wasserstein, mode-collapse indicators, etc.), and the guidance-strength values tested so that the reported 200–800× error factor can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, accurate summary of our contributions, and recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The central argument begins from the standard deterministic probability-flow ODE and applies change-of-variables to show that posterior sampling reduces to source reweighting followed by the unmodified flow. This is a direct mathematical consequence of bijective transport maps under Lipschitz conditions, not a fit or self-referential definition. No load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work appear in the derivation chain. The 2D closed-form experiment and Wasserstein bounds provide independent verification outside any internal fitting. Minor self-citations, if present, are not required for the core posterior-transport claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The prior is given by a deterministic probability-flow ODE.
Reference graph
Works this paper leans on
-
[1]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic inter- polants.arXiv preprint arXiv:2209.15571,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Monte carlo guided denoising diffusion models for bayesian linear inverse problems
Gabriel Cardoso, Sylvain Le Corff, Eric Moulines, et al. Monte carlo guided denoising diffusion models for bayesian linear inverse problems. InInternational Conference on Learning Represen- tations, volume 2024, pp. 44001–44037,
2024
-
[3]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022a. Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Proces...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Pnp-flow: Plug-and-play image restoration with flow matching
S´egol`ene Martin, Anne Gagneux, Paul Hagemann, and Gabriele Steidl. Pnp-flow: Plug-and-play image restoration with flow matching. InInternational Conference on Learning Representations, volume 2025, pp. 45466–45492,
2025
-
[5]
Variational diffusion posterior sampling with midpoint guidance
Badr Moufad, Lisa Bedin, Alain Oliviero Durmus, Eric Moulines, Jimmy Olsson, et al. Variational diffusion posterior sampling with midpoint guidance. InInternational Conference on Learning Representations, volume 2025, pp. 95170–95214,
2025
-
[6]
Onsager-Machlup Posterior Transport for Deep Gaussian Processes
Jian Xu, Delu Zeng, John Paisley, and Qibin Zhao. Onsager-machlup posterior transport for deep gaussian processes.arXiv preprint arXiv:2605.23434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
x1=Φt→1(x).(12) The canonical correction.To reachp(· |y)when starting from theunconditionalp 0 (rather than py 0 ), one integrates ˙x=v t +u t with marginalsq u t ,q 0 =p 0, and requiresq u 1 =p(· |y). Among all admissibleu, the minimum-kinetic-energy field equation 4 exists and is a gradient fieldu ⋆ t =∇ϕ t, where(q ⋆ t , ϕt)solve the Benamou–Brenier op...
2000
-
[8]
15 Preprint A.5 PROOF OFPROPOSITION4 The source posterior is the Gibbs measurep y,ϵ 0 ∝e −Iy/ϵ withI y in equation 6 continuous and, by coercivity ofI 0, with compact sublevel sets (a good rate function). By Varadhan’s lemma / the Laplace principle (Dembo & Zeitouni, 2009; Dupuis & Ellis, 2011),{p y,ϵ 0 }satisfies an LDP with rateI y, so for any closedFan...
2009
-
[9]
Proposition 6(Exponential ESS decay).Under the above scaling with a tempered prior of the same order,E p0 wm ≍e − 1 ϵ inf z[I 0(z)+m ℓy(Φ(z)) ] by Laplace’s method, so ϵlog ESS N − − − → ϵ→0 − 2m 1 −m 2 −m 0 =:−∆≤0,(16) wherem j = inf z[I0(z) +j ℓ y(Φ(z))]forj∈ {0,1,2}. Whenever the likelihood is informative (ℓy ◦Φnon-constant on the prior’s typical set),...
2048
-
[10]
For Proposition 8, the deterministic descent map sends each initialization to one basin minimizer, so the pushforward of any initial law is supported on the basin minimizers; a greedy ascent that does not track inter-basin mass places (asymptotically) all mass on the dominant basin, andTVbetween a point mass atx ⋆ k⋆ and the mixtureP k wkδx⋆ k equals1−w k...
1988
-
[11]
Only source-side reweighting reproduces the posterior; the entire trajectory/guidance family is biased
C ADDITIONAL QUALITATIVE RESULTS Figure 4:Full mechanism comparison on the controlled2D prior(densities; companion to Ta- ble 1).(a)closed-form true posterior;(b)source reweighting (ours)—matches (a);(c)DPS-style guidance collapses onto a measurement-consistent ridge;(d)DAPS partially recovers the mode structure but mis-weights it;(e)MGPS, like guidance, ...
2015
-
[12]
inference amortization
and of latent-variable Bayesian inference more broadly; encoder/decoder posterior inference, flow-based VI, and “inference amortization” all exploit it.Bor- rowed:the identity itself.New:itsdynamicalconsequence for a flow-matching prior (Proposi- tions 1–2). The reweightingr t(x) =p(y|Φ t→1(x))/p(y)is a first integral of the prior flow ( D Dt rt = 0), so ...
2023
-
[13]
likelihood gradient
It is complementary to MCMC/SMC: it can warm-start them, and they can debias it. Conditional and dynamic optimal transport.When one insists on starting from the uncondi- tionalp 0, the minimum-energy way to reachp(· |y)is the canonical correctoru ⋆ of equation 4, a conditionaldynamic-OT problem relative to the reference driftv t, characterized by the Bena...
2000
-
[14]
The identification ofu ⋆ with the Freidlin–Wentzell minimum-action correction fromp 0 top(· |y) ties the transport, bridge, and large-deviation pictures together
draws on standard large-deviation theory (Dembo & Zeitouni, 2009; Dupuis & Ellis, 2011; Kifer, 1988).Borrowed:Varadhan’s lemma, the contraction principle, and Laplace’s method.New: their application to the flow source posterior to (a) quantify the IS effective-sample-size collapse via the rateI y, and (b) explain guidance mode collapse as a failure to pre...
2009
-
[15]
and the Onsager–Machlup action-minimization view of generative transition-path sampling (Raja et al., 2025), where the target is characterized as the minimizer of an Onsager–Machlup functional along transport paths; our flow-source actionIy is the inverse-problem analogue of that construction, specialized to a deterministic probability-flow prior. Diffusi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.