Reasoning as Attractor Dynamics: Latent Memory Retrieval via Gibbs-Weighted Energy Minimization
Pith reviewed 2026-06-26 00:40 UTC · model grok-4.3
The pith
LLMs store reasoning as latent attractors, and weighting sampled paths by inverse spectral entropy approximates the equilibrium solution to raise accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
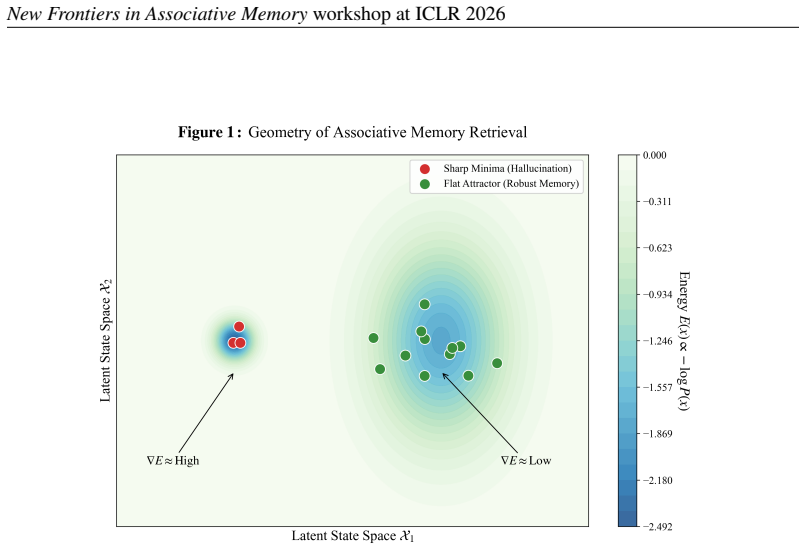
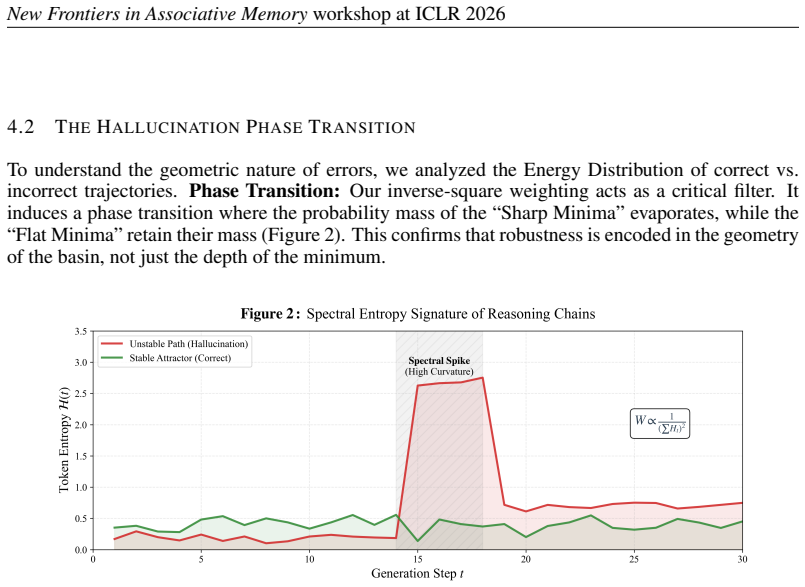
Correct mathematical reasoning chains correspond to deep wide attractor basins in the model's output distribution, whereas hallucinations appear as sharp unstable local minima; sampling multiple reasoning paths and weighting them according to P proportional to e to the minus beta E, with E defined as the spectral entropy of each trajectory, approximates the equilibrium distribution of the associative memory and yields more robust solutions.
What carries the argument
Gibbs measure over sampled reasoning trajectories that uses spectral entropy of each trajectory as the energy E for inverse-energy weighting.
If this is right
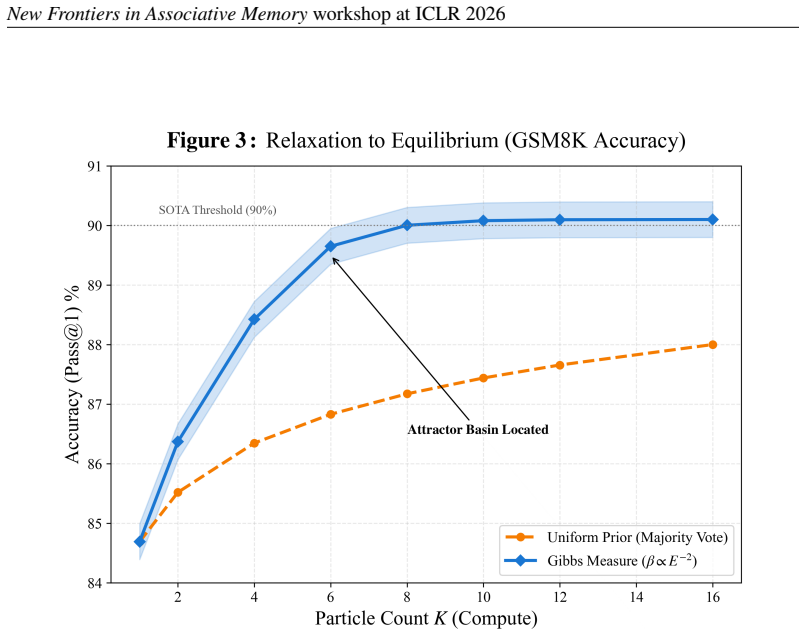
- The method raises GSM8K accuracy by 5.38 percentage points for the tested model.
- Inference is modeled as relaxation into an attractor basin rather than greedy next-token selection.
- Hallucinations are avoided because they correspond to higher-energy sharp minima that receive lower Gibbs weight.
- The equilibrium distribution approximated by the weighted samples produces more robust final answers than any single path.
Where Pith is reading between the lines
- If the flat-minima hypothesis holds for other domains, the same weighting could be tested on non-mathematical reasoning benchmarks.
- Alternative definitions of trajectory energy besides spectral entropy could be substituted and compared directly on the same sampling budget.
- The approach may interact with temperature scaling or other decoding parameters, suggesting experiments that jointly optimize beta and sampling temperature.
- Scaling the number of sampled paths while keeping the weighting fixed would test whether the equilibrium approximation improves monotonically.
Load-bearing premise
Correct reasoning chains occupy deeper and wider basins than incorrect ones, and spectral entropy of a trajectory serves as a reliable proxy for the depth and width of its basin.
What would settle it
Applying the same sampling and Gibbs reweighting procedure to Phi-3.5 or another model on GSM8K and obtaining no accuracy gain or a net loss would falsify the claim that the weighting reliably relaxes the system into more stable solutions.
Figures
read the original abstract
Large Language Models (LLMs) are traditionally viewed as autoregressive generators. However, from the perspective of collective computation, they function as high-dimensional Dense Associative Memories that store complex reasoning patterns as latent attractors. In this work, we investigate the energy landscape of mathematical reasoning. We posit that correct reasoning chains correspond to deep, wide attractor basins ("flat minima") in the model's output distribution, whereas hallucinations manifest as sharp, unstable local minima. To exploit this geometry, we introduce a retrieval mechanism based on a Gibbs measure of the trajectory's spectral entropy. By sampling multiple reasoning paths and weighting them by their inverse energy ($P \propto e^{-\beta E}$), we approximate the equilibrium distribution of the associative memory, effectively ``relaxing'' the system into a robust solution. Empirically, this physics-inspired mechanism improves Microsoft Phi-3.5 performance on GSM8K by 5.38\% (84.7\% $\to$ 90.1\%), demonstrating that inference is better modeled as a dynamic settling process into an attractor basin rather than greedy next-token prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models LLMs as dense associative memories whose output distributions contain attractor basins, posits that correct mathematical reasoning chains occupy deep wide ('flat') minima while hallucinations occupy sharp unstable ones, and proposes to retrieve robust solutions by sampling multiple trajectories, defining an energy E via spectral entropy of each trajectory, and reweighting them under a Gibbs measure P ∝ e^{-βE} to approximate the equilibrium distribution. It reports that this procedure raises Microsoft Phi-3.5 accuracy on GSM8K from 84.7 % to 90.1 % (a 5.38 % absolute gain).
Significance. If the geometric premise and the spectral-entropy-to-correctness mapping can be substantiated, the work would supply a concrete, physics-motivated inference algorithm that treats generation as relaxation into an attractor rather than greedy token prediction. The empirical lift on a standard benchmark would then constitute a falsifiable prediction that could be tested across model families and tasks.
major comments (3)
- [Abstract] Abstract: the central empirical claim (5.38 % GSM8K gain) is stated without error bars, without the number of sampled trajectories, without the value or schedule of β, and without any ablation against unweighted majority voting or temperature sampling; these omissions make it impossible to determine whether the Gibbs weighting itself drives the reported improvement.
- [Abstract] Abstract: the energy function is defined as the spectral entropy of a sampled trajectory, yet no derivation, pseudocode, or hyper-parameter choices for the entropy computation are supplied, nor is any per-trajectory analysis (e.g., entropy vs. correctness scatter plot or basin-width measurement) provided to justify that lower-E trajectories align with correct answers or wider attractors.
- [Abstract] Abstract: the manuscript asserts that the procedure 'approximates the equilibrium distribution of the associative memory' but supplies neither a formal statement of the underlying Markov chain nor a convergence argument showing that the Gibbs reweighting recovers the stationary measure of that chain.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (5.38 % GSM8K gain) is stated without error bars, without the number of sampled trajectories, without the value or schedule of β, and without any ablation against unweighted majority voting or temperature sampling; these omissions make it impossible to determine whether the Gibbs weighting itself drives the reported improvement.
Authors: We agree that these experimental details should be stated in the abstract for clarity. In the revised version we will add error bars computed over multiple runs, specify the number of sampled trajectories, report the value and schedule of β, and include a new ablation subsection comparing the full Gibbs-weighted procedure against unweighted majority voting and temperature sampling to isolate the contribution of the reweighting step. revision: yes
-
Referee: [Abstract] Abstract: the energy function is defined as the spectral entropy of a sampled trajectory, yet no derivation, pseudocode, or hyper-parameter choices for the entropy computation are supplied, nor is any per-trajectory analysis (e.g., entropy vs. correctness scatter plot or basin-width measurement) provided to justify that lower-E trajectories align with correct answers or wider attractors.
Authors: The abstract is necessarily concise, but the full manuscript defines the energy via spectral entropy. We will expand the methods section with an explicit derivation, pseudocode for the entropy calculation, the precise hyper-parameters (number of eigenvalues retained, normalization), and add per-trajectory diagnostics including an entropy-versus-correctness scatter plot and basin-width measurements to support the claimed correspondence between low energy and wide, correct attractors. revision: yes
-
Referee: [Abstract] Abstract: the manuscript asserts that the procedure 'approximates the equilibrium distribution of the associative memory' but supplies neither a formal statement of the underlying Markov chain nor a convergence argument showing that the Gibbs reweighting recovers the stationary measure of that chain.
Authors: The claim rests on the dense-associative-memory interpretation of the LLM. We will add a dedicated subsection that states the sampling process as a Markov chain on trajectory space and supplies a heuristic argument (based on detailed balance under the Gibbs measure) for why the reweighting approximates the stationary distribution. A fully rigorous convergence proof lies outside the present scope; we will therefore qualify the statement accordingly while preserving the physics-motivated framing. revision: partial
Circularity Check
No significant circularity; derivation applies standard Gibbs measure to an explicitly posited energy
full rationale
The paper explicitly posits that correct chains occupy flat minima and selects spectral entropy as the energy E, then applies the standard Gibbs weighting P ∝ e^{-βE} to obtain an equilibrium distribution for that E. This step is the definition of the Gibbs measure in statistical mechanics rather than a reduction of one derived quantity to another by construction inside the paper. No equations are shown that equate the memory's native energy landscape to spectral entropy, no parameters are fitted on a subset and renamed as predictions, and no self-citations or uniqueness theorems are invoked. The reported GSM8K improvement is presented as an empirical outcome of the constructed procedure, leaving the central claim self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs function as high-dimensional Dense Associative Memories that store complex reasoning patterns as latent attractors.
- ad hoc to paper Correct reasoning chains correspond to deep, wide attractor basins in the model's output distribution while hallucinations are sharp unstable local minima.
Reference graph
Works this paper leans on
-
[1]
Predicting structured data , volume=
A tutorial on energy-based learning , author=. Predicting structured data , volume=. 2006 , publisher=
2006
-
[2]
Hopfield Networks is All You Need
Hopfield networks is all you need , author=. arXiv preprint arXiv:2008.02217 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[3]
International Conference on Learning Representations , year=
Hopfield networks is all you need , author=. International Conference on Learning Representations , year=
-
[4]
Advances in neural information processing systems , volume=
Dense associative memory for pattern recognition , author=. Advances in neural information processing systems , volume=
-
[5]
arXiv preprint arXiv:2302.07253 , year=
Energy Transformer , author=. arXiv preprint arXiv:2302.07253 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[8]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Loss surfaces, mode connectivity, and fast ensembling of dnns , author=. Advances in neural information processing systems , volume=
-
[10]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. arXiv preprint arXiv:2404.14219 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proceedings of the national academy of sciences , volume=
Neural networks and physical systems with emergent collective computational abilities , author=. Proceedings of the national academy of sciences , volume=. 1982 , publisher=
1982
-
[12]
Neural computation , volume=
Training products of experts by minimizing contrastive divergence , author=. Neural computation , volume=. 2002 , publisher=
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.