GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
Pith reviewed 2026-06-26 08:22 UTC · model grok-4.3
The pith
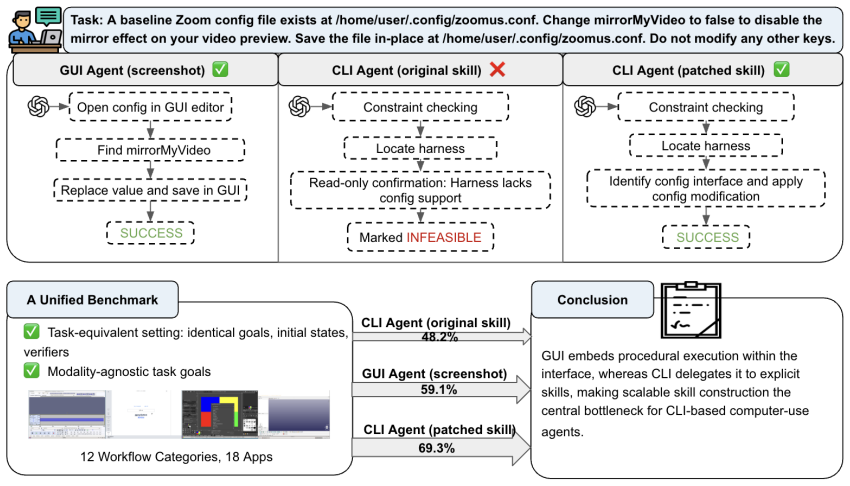
A matched benchmark of 440 tasks shows GUI agents at 59.1% success outperforming original-skill CLI at 48.2%, with verifier-guided CLI reaching 69.3%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a matched execution-layer benchmark of 440 desktop tasks across 18 applications and 12 workflow categories, where screen-only GUI agents and skill-mediated CLI agents receive identical goals, states, and final-state verifiers while being restricted to modality-native actions, the strongest GUI agent reaches a 59.1% full pass rate, outperforming the strongest original-skill CLI agent at 48.2%; however, verifier-guided skill augmentation raises CLI success to 69.3%, showing that much of the CLI deficit comes from incomplete skill coverage rather than model capability alone. These results suggest that GUI and CLI expose different execution bottlenecks: GUI agents are limited by reliable grou
What carries the argument
The matched execution-layer benchmark of 440 desktop tasks across 18 applications and 12 workflow categories that equalizes goals, states, verifiers, and restricts agents to modality-native actions.
If this is right
- GUI agents require advances specifically in reliable grounded interaction for long-horizon workflows.
- CLI agents improve substantially when their skill interfaces are expanded via verifier guidance.
- Performance differences between the two modalities can be isolated when tasks and verifiers are matched.
- Optimization efforts for computer-use agents should target modality-specific constraints rather than model scale alone.
Where Pith is reading between the lines
- Hybrid agents that can switch between GUI and CLI actions within the same workflow may reach higher success rates than either modality alone.
- The benchmark design could be reused to compare additional modalities such as voice or API-only interfaces on the same task set.
- Dynamic skill generation during execution might address CLI coverage limits more scalably than static skill libraries.
- Long-horizon grounding failures in GUI may be measurable by counting the step at which agents lose accurate screen localization.
Load-bearing premise
The benchmark of 440 tasks successfully eliminates confounding differences in tasks, initial states, verifiers, and permitted actions so that performance gaps can be attributed solely to interaction modality.
What would settle it
Re-running the 440-task evaluation with the same agents but allowing cross-modality actions or altered verifiers and observing that the performance ordering disappears or reverses would falsify the claim that the bottlenecks are caused by modality.
Figures





read the original abstract
Computer-use agents can execute software tasks through either graphical interfaces or programmatic command interfaces, but existing evaluations confound interaction modality with differences in tasks, initial states, verifiers, and permitted actions. We introduce a matched execution-layer benchmark of 440 desktop tasks across 18 applications and 12 workflow categories, where screen-only GUI agents and skill-mediated CLI agents receive identical goals, states, and final-state verifiers while being restricted to modality-native actions. In this controlled setting, the strongest GUI agent reaches a 59.1% full pass rate, outperforming the strongest original-skill CLI agent at 48.2%; however, verifier-guided skill augmentation raises CLI success to 69.3%, showing that much of the CLI deficit comes from incomplete skill coverage rather than model capability alone. These results suggest that GUI and CLI expose different execution bottlenecks: GUI agents are limited by reliable grounded interaction over long-horizon workflows, whereas CLI agents are limited by the coverage and scalability of their skill interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a matched execution-layer benchmark of 440 desktop tasks across 18 applications and 12 workflow categories. Screen-only GUI agents and skill-mediated CLI agents receive identical goals, states, and final-state verifiers but are restricted to modality-native actions. The strongest GUI agent achieves a 59.1% full pass rate, outperforming the strongest original-skill CLI agent at 48.2%; verifier-guided skill augmentation raises CLI success to 69.3%. The authors conclude that GUI agents are limited by reliable grounded interaction over long-horizon workflows, whereas CLI agents are limited by the coverage and scalability of their skill interfaces.
Significance. If the benchmark successfully isolates interaction modality, the work supplies concrete empirical evidence distinguishing execution bottlenecks between GUI and CLI computer-use agents. The scale of the matched benchmark (440 tasks) and the augmentation experiment (showing CLI improvement to 69.3%) are strengths that could guide future agent design toward better grounding mechanisms for GUI and expanded skill libraries for CLI.
major comments (2)
- [Abstract] Abstract: The central attribution of the performance gap (59.1% GUI vs. 48.2% original-skill CLI) to interaction modality rather than agent differences requires that the 'strongest' agents per modality are comparable in base model capability, training, and prompting. The abstract supplies no selection criteria or verification that underlying models are matched, which is load-bearing for the claim that the gap reflects modality-specific bottlenecks.
- [Benchmark description] Benchmark description (as summarized in abstract): The matched execution-layer benchmark is stated to control for tasks, initial states, verifiers, and permitted actions, yet the description does not address control over agent implementations themselves. Without such control, differences in model strength or prompting regimes could confound the modality comparison and undermine the conclusion that GUI and CLI expose distinct bottlenecks.
minor comments (1)
- The abstract references 'verifier-guided skill augmentation' and 'original-skill CLI' without defining these terms or the augmentation procedure; these should be expanded with concrete examples in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to clearly establish that performance differences arise from interaction modality rather than uncontrolled agent variations. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central attribution of the performance gap (59.1% GUI vs. 48.2% original-skill CLI) to interaction modality rather than agent differences requires that the 'strongest' agents per modality are comparable in base model capability, training, and prompting. The abstract supplies no selection criteria or verification that underlying models are matched, which is load-bearing for the claim that the gap reflects modality-specific bottlenecks.
Authors: We agree the abstract is concise and omits explicit selection criteria. The full manuscript (Section 4.1) specifies that both the GUI and CLI agents are instantiated from the same base model (GPT-4o) with modality-specific action interfaces and standardized prompting templates; the 'strongest' designation refers to the best publicly documented configuration for each modality under these constraints. To address the concern directly in the abstract, we will insert a short clause noting the use of matched base models and prompting regimes. revision: yes
-
Referee: [Benchmark description] Benchmark description (as summarized in abstract): The matched execution-layer benchmark is stated to control for tasks, initial states, verifiers, and permitted actions, yet the description does not address control over agent implementations themselves. Without such control, differences in model strength or prompting regimes could confound the modality comparison and undermine the conclusion that GUI and CLI expose distinct bottlenecks.
Authors: The benchmark description intentionally focuses on environmental controls (identical tasks, states, and verifiers) to isolate modality effects while allowing each modality to use its strongest available agent implementation; agent details and base-model matching are provided in the experimental setup to avoid confounding. We will expand the benchmark description paragraph to cross-reference the agent-matching criteria already present in Section 4, making the controls explicit without altering the core design. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparison
full rationale
The paper reports results from a matched execution-layer benchmark of 440 tasks with no equations, fitted parameters, derivations, or self-citation chains. The central claim (distinct bottlenecks for GUI vs. CLI) is an interpretation of measured pass rates (59.1% GUI, 48.2% original CLI, 69.3% augmented CLI) under controlled conditions. No step reduces a prediction or uniqueness claim to its own inputs by construction. This is a standard empirical study whose validity rests on benchmark design rather than any definitional or self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2108.07732 , year =
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
-
[2]
arXiv preprint arXiv:2107.03374 , year =
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
-
[3]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
and Del Verme, Manuel and Marty, Tom and Boisvert, L
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Boisvert, L. arXiv preprint arXiv:2403.07718 , year =
-
[5]
2023 , url =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu , journal =. 2023 , url =
2023
-
[6]
2024 , url =
Zheng, Boyuan and Gou, Boyu and Kil, Jihyung and Sun, Huan and Su, Yu , journal =. 2024 , url =
2024
-
[7]
2024 , url =
Rawles, Christopher and Clinckemaillie, Sarah and Chang, Yifan and Waltz, Jonathan and Lau, Gabrielle and Fair, Marybeth and Li, Alice and Bishop, William and Li, Wei and Campbell-Ajala, Folawiyo and Toyama, Daniel and Berry, Robert and Tyamagundlu, Divya and Lillicrap, Timothy and Riva, Oriana , journal =. 2024 , url =
2024
-
[8]
2024 , url=
Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu , booktitle=. 2024 , url=
2024
-
[9]
Xu and Shuyan Zhou and Graham Neubig , year=
Yueqi Song and Frank F. Xu and Shuyan Zhou and Graham Neubig , year=. Beyond Browsing:
-
[10]
2023 , url =
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , booktitle =. 2023 , url =
2023
-
[11]
2024 , url =
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , journal =. 2024 , url =
2024
-
[12]
arXiv preprint arXiv:2604.00073 , year =
Terminal Agents Suffice for Enterprise Automation , author =. arXiv preprint arXiv:2604.00073 , year =
-
[13]
2025 , url=
GUI Agents: A Survey , author=. 2025 , url=
2025
-
[14]
arXiv preprint arXiv:2601.11868 , year =
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author =. arXiv preprint arXiv:2601.11868 , year =
-
[15]
2026 , eprint=
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author=. 2026 , eprint=
2026
-
[16]
2026 , url =
Han, Tingxu and Zhang, Yi and Song, Wei and Fang, Chunrong and Chen, Zhenyu and Sun, Youcheng and Hu, Lijie , journal =. 2026 , url =
2026
-
[17]
and Yao, Ziyu , journal =
Aghzal, Mohamed and Stein, Gregory J. and Yao, Ziyu , journal =. Why Do. 2026 , url =
2026
-
[18]
2023 , url =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , journal =...
2023
-
[19]
2026 , howpublished =
Introducing. 2026 , howpublished =
2026
-
[20]
2026 , howpublished =
2026
-
[21]
2026 , eprint=
EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience , author=. 2026 , eprint=
2026
-
[22]
2026 , eprint=
OpenComputer: Verifiable Software Worlds for Computer-Use Agents , author=. 2026 , eprint=
2026
-
[23]
2025 , eprint=
UI-TARS: Pioneering Automated GUI Interaction with Native Agents , author=. 2025 , eprint=
2025
-
[24]
2026 , eprint=
ANCHOR: Branch-Point Data Generation for GUI Agents , author=. 2026 , eprint=
2026
-
[25]
2026 , eprint=
Android Coach: Improve Online Agentic Training Efficiency with Single State Multiple Actions , author=. 2026 , eprint=
2026
-
[26]
2025 , eprint=
OpenCUA: Open Foundations for Computer-Use Agents , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[28]
Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change
Chen, Ben. Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[29]
Deep Reinforcement Learning of LLM s using RLHF
Levandovsky, Enoch. Deep Reinforcement Learning of LLM s using RLHF. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[30]
Conversational Collaborative Robots
Kranti, Chalamalasetti. Conversational Collaborative Robots. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[31]
Dialogue System using Large Language Model-based Dynamic Slot Generation
Hashimoto, Ekai. Dialogue System using Large Language Model-based Dynamic Slot Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[32]
Towards Adaptive Human-Agent Collaboration in Real-Time Environments
Nakae, Kaito. Towards Adaptive Human-Agent Collaboration in Real-Time Environments. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[33]
Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation
Jiang, Jingjing. Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[34]
Controlling Dialogue Systems with Graph-Based Structures
Hilgendorf, Laetitia Mina. Controlling Dialogue Systems with Graph-Based Structures. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[35]
Multimodal Agentic Dialogue Systems for Situated Human-Robot Interaction
Sucal, Virgile. Multimodal Agentic Dialogue Systems for Situated Human-Robot Interaction. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[36]
Knowledge Graphs and Representational Models for Dialogue Systems
Walker, Nicholas Thomas. Knowledge Graphs and Representational Models for Dialogue Systems. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[37]
Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.0
-
[38]
Efeoglu, Sefika and Paschke, Adrian. Fine-Tuning Large Language Models for Relation Extraction within a Retrieval-Augmented Generation Framework. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.1
-
[39]
Benchmarking Table Extraction: Multimodal LLM s vs Traditional OCR
Nunes, Guilherme and Rolla, Vitor and Pereira, Duarte and Alves, Vasco and Carreiro, Andre and Baptista, M \'a rcia. Benchmarking Table Extraction: Multimodal LLM s vs Traditional OCR. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.2
-
[40]
Injecting Structured Knowledge into LLM s via Graph Neural Networks
Li, Zichao and Ke, Zong and Zhao, Puning. Injecting Structured Knowledge into LLM s via Graph Neural Networks. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.3
-
[41]
Regular-pattern-sensitive CRF s for Distant Label Interactions
Papay, Sean and Klinger, Roman and Pad \'o , Sebastian. Regular-pattern-sensitive CRF s for Distant Label Interactions. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.4
-
[42]
Swarup, Anushka and Bhandarkar, Avanti and Wilson, Ronald and Pan, Tianyu and Woodard, Damon. From Syntax to Semantics: Evaluating the Impact of Linguistic Structures on LLM -Based Information Extraction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.5
-
[43]
Detecting Referring Expressions in Visually Grounded Dialogue with Autoregressive Language Models
Willemsen, Bram and Skantze, Gabriel. Detecting Referring Expressions in Visually Grounded Dialogue with Autoregressive Language Models. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.6
-
[44]
Exploring Multilingual Probing in Large Language Models: A Cross-Language Analysis
Li, Daoyang and Zhao, Haiyan and Zeng, Qingcheng and Du, Mengnan. Exploring Multilingual Probing in Large Language Models: A Cross-Language Analysis. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.7
-
[45]
Self-Contrastive Loop of Thought Method for Text-to- SQL Based on Large Language Model
Kang, Fengrui and Tan, Mingxi and Huang, Xianying and Yang, Shiju. Self-Contrastive Loop of Thought Method for Text-to- SQL Based on Large Language Model. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.8
-
[46]
Isaeva, Ulyana and Astafurov, Danil and Martynov, Nikita. Combining Automated and Manual Data for Effective Downstream Fine-Tuning of Transformers for Low-Resource Language Applications. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.9
-
[47]
Bartkowiak, Patryk and Grali \'n ski, Filip. Seamlessly Integrating Tree-Based Positional Embeddings into Transformer Models for Source Code Representation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.10
-
[48]
Enhancing AMR Parsing with Group Relative Policy Optimization
Barta, Botond and Hamerlik, Endre and Nyist, Mil \'a n and Ito, Masato and Acs, Judit. Enhancing AMR Parsing with Group Relative Policy Optimization. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.11
-
[49]
Structure Modeling Approach for UD Parsing of Historical M odern J apanese
Ozaki, Hiroaki and Omura, Mai and Komiya, Kanako and Asahara, Masayuki and Ogiso, Toshinobu. Structure Modeling Approach for UD Parsing of Historical M odern J apanese. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.12
-
[50]
BARTABSA ++: Revisiting BARTABSA with Decoder LLM s
Pfister, Jan and V. BARTABSA ++: Revisiting BARTABSA with Decoder LLM s. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.13
-
[51]
Typed- RAG : Type-Aware Decomposition of Non-Factoid Questions for Retrieval-Augmented Generation
Lee, DongGeon and Park, Ahjeong and Lee, Hyeri and Nam, Hyeonseo and Maeng, Yunho. Typed- RAG : Type-Aware Decomposition of Non-Factoid Questions for Retrieval-Augmented Generation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.14
-
[52]
Hellwig, Nils Constantin and Fehle, Jakob and Kruschwitz, Udo and Wolff, Christian. Do we still need Human Annotators? Prompting Large Language Models for Aspect Sentiment Quad Prediction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.15
-
[53]
Can LLM s Interpret and Leverage Structured Linguistic Representations? A Case Study with AMR s
Raut, Ankush and Zhu, Xiaofeng and Pacheco, Maria Leonor. Can LLM s Interpret and Leverage Structured Linguistic Representations? A Case Study with AMR s. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.16
work page internal anchor Pith review doi:10.18653/v1/2025.xllm-1.16 2025
-
[54]
LLM Dependency Parsing with In-Context Rules
Ginn, Michael and Palmer, Alexis. LLM Dependency Parsing with In-Context Rules. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.17
-
[55]
Han, Xu and Wang, Bo and Sun, Yueheng and Zhao, Dongming and Qu, Zongfeng and He, Ruifang and Hou, Yuexian and Hu, Qinghua. Cognitive Mirroring for D oc RE : A Self-Supervised Iterative Reflection Framework with Triplet-Centric Explicit and Implicit Feedback. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025)...
-
[56]
Cross-Document Event-Keyed Summarization
Walden, William and Kuchmiichuk, Pavlo and Martin, Alexander and Jin, Chihsheng and Cao, Angela and Sun, Claire and Allen, Curisia and White, Aaron. Cross-Document Event-Keyed Summarization. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.19
-
[57]
Transfer of Structural Knowledge from Synthetic Languages
Budnikov, Mikhail and Yamshchikov, Ivan. Transfer of Structural Knowledge from Synthetic Languages. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.20
-
[58]
Language Models are Universal Embedders
Zhang, Xin and Li, Zehan and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Zhang, Min. Language Models are Universal Embedders. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.21
-
[59]
Duan, Shuoqiu and Chen, Xiaoliang and Miao, Duoqian and Gu, Xu and Li, Xianyong and Du, Yajun. D ia DP @ XLLM 25: Advancing C hinese Dialogue Parsing via Unified Pretrained Language Models and Biaffine Dependency Scoring. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.22
-
[60]
Yuan, Jiahao and Sun, Xingzhe and Yu, Xing and Wang, Jingwen and Du, Dehui and Cui, Zhiqing and Di, Zixiang. LLMSR @ XLLM 25: Less is More: Enhancing Structured Multi-Agent Reasoning via Quality-Guided Distillation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.23
-
[61]
S peech EE @ XLLM 25: End-to-End Structured Event Extraction from Speech
Chaudhuri, Soham and Biswas, Diganta and Saha, Dipanjan and Das, Dipankar and Bandyopadhyay, Sivaji. S peech EE @ XLLM 25: End-to-End Structured Event Extraction from Speech. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.24
-
[62]
Pham Hoang Le, Nguyen and Dinh Thien, An and T. Luu, Son and Van Nguyen, Kiet. D oc IE @ XLLM 25: Z ero S emble - Robust and Efficient Zero-Shot Document Information Extraction with Heterogeneous Large Language Model Ensembles. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.25
-
[63]
Popovic, Nicholas and Kangen, Ashish and Schopf, Tim and F. D oc IE @ XLLM 25: In-Context Learning for Information Extraction using Fully Synthetic Demonstrations. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.26
-
[64]
Tai, Le and Van, Thin. LLMSR @ XLLM 25: Integrating Reasoning Prompt Strategies with Structural Prompt Formats for Enhanced Logical Inference. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.27
-
[65]
Qiu, Chengfeng and Zhou, Lifeng and Wei, Kaifeng and Li, Yuke. D oc IE @ XLLM 25: UIEP rompter: A Unified Training-Free Framework for universal document-level information extraction via Structured Prompt. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.28
-
[66]
Chen, Danchun. LLMSR @ XLLM 25: SWRV : Empowering Self-Verification of Small Language Models through Step-wise Reasoning and Verification. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.29
-
[67]
LLMSR @ XLLM 25: An Empirical Study of LLM for Structural Reasoning
Li, Xinye and Wan, Mingqi and Sui, Dianbo. LLMSR @ XLLM 25: An Empirical Study of LLM for Structural Reasoning. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.30
-
[68]
LLMSR @ XLLM 25: A Language Model-Based Pipeline for Structured Reasoning Data Construction
Xing, Hongrui and Liu, Xinzhang and Jiang, Zhuo and Yang, Zhihao and Yao, Yitong and Wang, Zihan and Deng, Wenmin and Wang, Chao and Song, Shuangyong and Yang, Wang and He, Zhongjiang and Li, Yongxiang. LLMSR @ XLLM 25: A Language Model-Based Pipeline for Structured Reasoning Data Construction. Proceedings of the 1st Joint Workshop on Large Language Model...
-
[69]
S peech EE @ XLLM 25: Retrieval-Enhanced Few-Shot Prompting for Speech Event Extraction
Gedeon, M \'a t \'e. S peech EE @ XLLM 25: Retrieval-Enhanced Few-Shot Prompting for Speech Event Extraction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.32
-
[70]
Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[71]
An introduction to computational identification and classification of Upam \= a alaṇk \= a ra
Jadhav, Bhakti and Dutta, Himanshu and Kanitkar, Shruti and Kulkarni, Malhar and Bhattacharyya, Pushpak. An introduction to computational identification and classification of Upam \= a alaṇk \= a ra. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[72]
Aesthetics of S anskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on \'S ikṣ \= a ṣṭaka
Sandhan, Jivnesh and Barbadikar, Amruta and Maity, Malay and Satuluri, Pavankumar and Sandhan, Tushar and Gupta, Ravi M and Goyal, Pawan and Behera, Laxmidhar. Aesthetics of S anskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on \'S ikṣ \= a ṣṭaka. Computational Sanskrit and Digital Humanities - World Sanskrit Confere...
2025
-
[73]
Itaretara Dvandva: A challenge for Dependency Tree semantics
Kulkarni, Amba and Neelamana, Vasudha. Itaretara Dvandva: A challenge for Dependency Tree semantics. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[74]
A Case Study of Handwritten Text Recognition from Pre-Colonial era S anskrit Manuscripts
Chincholikar, Kartik and Dwivedi, Shagun and Gopalan, Kaushik and Awasthi, Tarinee. A Case Study of Handwritten Text Recognition from Pre-Colonial era S anskrit Manuscripts. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[75]
Towards Accent-Aware V edic S anskrit Optical Character Recognition Based on Transformer Models
Tsukagoshi, Yuzuki and Kuroiwa, Ryo and Ohmukai, Ikki. Towards Accent-Aware V edic S anskrit Optical Character Recognition Based on Transformer Models. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[76]
Vedavani: A Benchmark Corpus for ASR on V edic S anskrit Poetry
Kumar, Sujeet and Ray, Pretam and Beerukuri, Abhinay and Kamoji, Shrey and Jagadeeshan, Manoj Balaji and Goyal, Pawan. Vedavani: A Benchmark Corpus for ASR on V edic S anskrit Poetry. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[77]
Compound Type Identification in S anskrit
Krishnan, Sriram and Satuluri, Pavankumar and Barbadikar, Amruta and Prasanna Venkatesh, T S and Kulkarni, Amba. Compound Type Identification in S anskrit. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[78]
IKML : A Markup Language for Collaborative Semantic Annotation of I ndic Texts
Lakkundi, Chaitanya S and Rajaraman, Gopalakrishnan and Susarla, Sai Rama Krishna. IKML : A Markup Language for Collaborative Semantic Annotation of I ndic Texts. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[79]
Challenges in Processing V edic S anskrit: Towards creating a normalized dataset for the Ṛgveda-saṃhit \= a
Krishnan, Sriram and Gayathri, Sepuri and Kulkarni, Amba. Challenges in Processing V edic S anskrit: Towards creating a normalized dataset for the Ṛgveda-saṃhit \= a. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[80]
P \= a ṇḍitya: Visualizing S anskrit Intellectual Networks
Neill, Tyler. P \= a ṇḍitya: Visualizing S anskrit Intellectual Networks. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.