PatternGSL: A Structured Specification Language for Template-Free and Simulation-Ready 3D Garments
Pith reviewed 2026-07-01 06:49 UTC · model grok-4.3
The pith
PatternGSL encodes complete sewing patterns as a template-free specification language that lets a model predict simulation-ready 3D garments directly from one image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
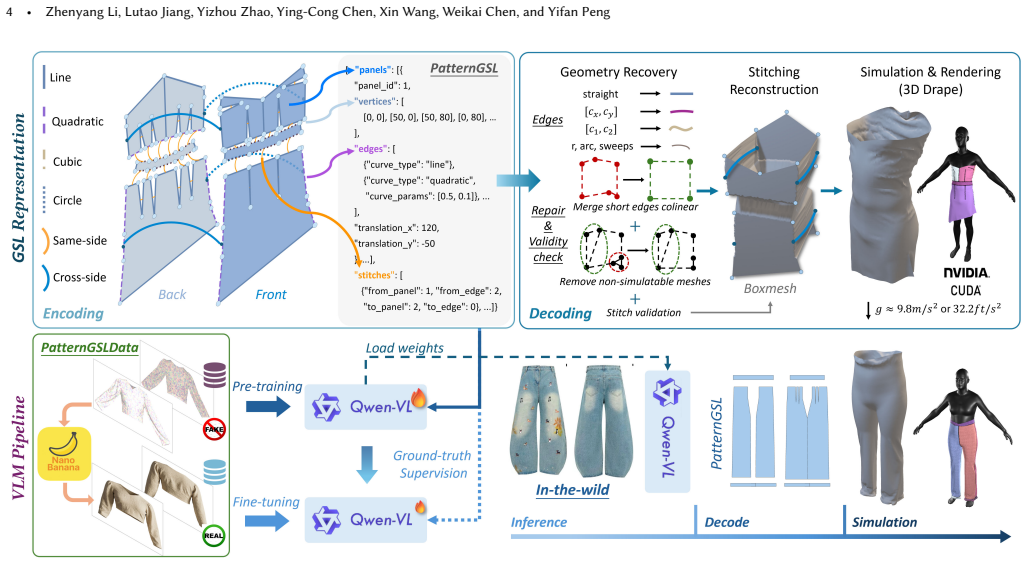
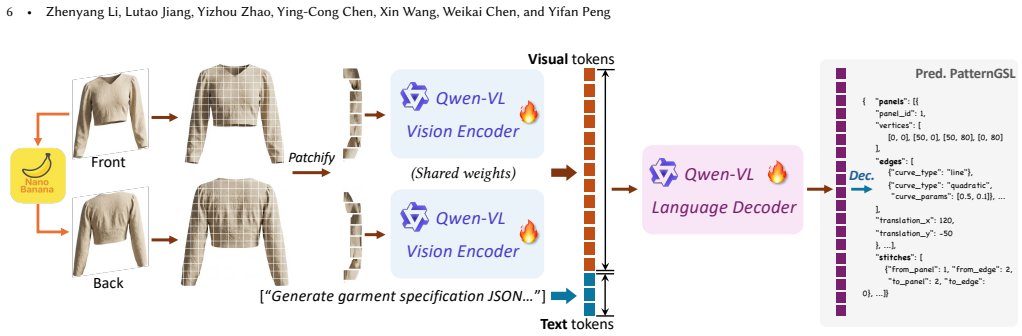
PatternGSL is a template-free and learnable specification language that encodes complete sewing patterns, including panel boundaries, parameterized seams, and explicit stitch topology, in a compact and standardized form. A vision-language framework predicts these specifications from a single image and decodes them into garments using lightweight deterministic validity handling without optimization-based refinement or manual cleanup. The same decoding pipeline supports reliable cloth simulation and pattern-level editing.
What carries the argument
The PatternGSL specification language, which records panel boundaries, parameterized seams, and explicit stitch topology as a compact, standardized encoding that supports direct prediction and deterministic decoding to simulation-ready garments.
If this is right
- Pattern accuracy improves over prior template-based or template-free baselines.
- Explicit sewing structure is recovered directly from images.
- Cloth simulation runs reliably on the decoded garments.
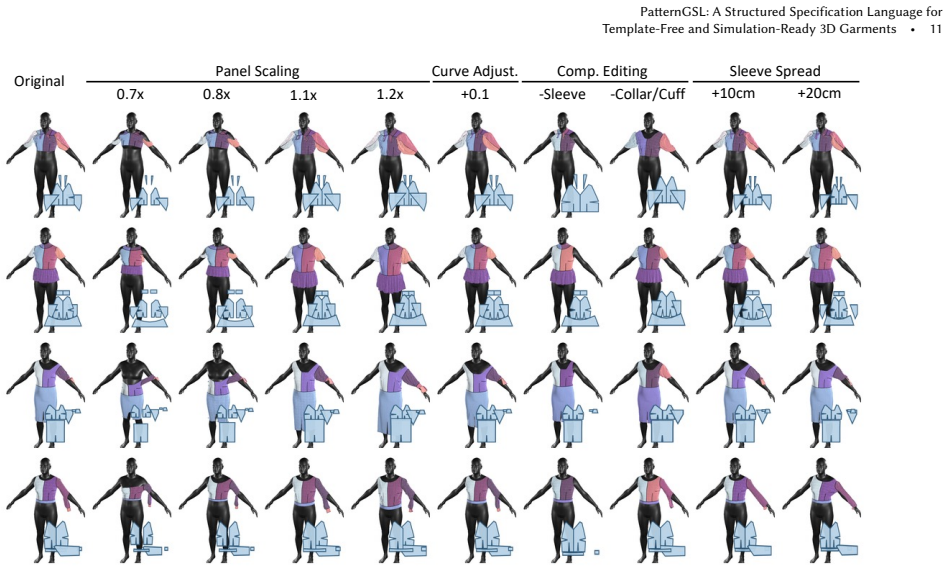
- Pattern-level edits are possible through the deterministic decoding pipeline.
Where Pith is reading between the lines
- The representation could support downstream tasks such as automated grading of patterns across sizes.
- Integration with existing 3D body scanners might allow end-to-end image-to-wearable pipelines.
- The dataset size suggests the language could serve as a training target for other generative models beyond the vision-language setup shown.
Load-bearing premise
A vision-language model can predict complete, valid PatternGSL specifications from a single image that decode into simulation-ready garments using only lightweight deterministic validity handling.
What would settle it
Running the model on a held-out image set and checking whether the output specifications produce garments that require optimization-based refinement or manual cleanup to become simulation-valid.
Figures






read the original abstract
Reconstructing realistic, physically plausible garments from a single image remains a fundamental challenge. Template-free methods capture surface geometry but lack explicit sewing structure for simulation; while programmatic systems are simulation-ready but constrained by predefined templates. This reveals a fundamental representation gap between geometric reconstruction and structured garment construction. We present PatternGSL, a structured garment representation in the form of a template-free and learnable specification language that encodes complete sewing patterns, including panel boundaries, parameterized seams, and explicit stitch topology, in a compact and standardized form. PatternGSL preserves the physical rigor of pattern-based models while removing template dependence, elevating sewing structure as a first-class target for generative modeling. We further propose a vision-language framework that predicts PatternGSL specifications directly from a single image and decodes them into garments using lightweight deterministic validity handling, without optimization-based refinement or manual cleanup. In addition, we introduce PatternGSLData, the first large-scale image-to-GSL paired dataset comprising 300K samples with complete sewing pattern annotations, enabling supervised VLM training for structured garment reconstruction. Experiments demonstrate improved pattern accuracy over prior baselines, explicit sewing-structure recovery, reliable cloth simulation, and pattern-level editing through the same deterministic decoding pipeline. Code and data-processing scripts will be released at https://lagrangeli.github.io/PatternGSL/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PatternGSL, a template-free and learnable specification language for complete sewing patterns encoding panel boundaries, parameterized seams, and explicit stitch topology in a compact form. It proposes a vision-language model framework that predicts PatternGSL specifications directly from a single image and decodes them into simulation-ready garments via lightweight deterministic validity handling without optimization-based refinement or manual cleanup. The work also presents the PatternGSLData dataset of 300K image-to-GSL pairs and reports experiments claiming improved pattern accuracy, explicit sewing-structure recovery, reliable cloth simulation, and pattern-level editing.
Significance. If the central claims hold, the work would address a key representation gap by elevating sewing structure to a first-class, template-free target for generative modeling while preserving simulation readiness. The large-scale paired dataset and deterministic decoding pipeline could enable more flexible single-image garment reconstruction and editing in computer vision and graphics applications.
major comments (2)
- [Abstract] Abstract: the statement that 'Experiments demonstrate improved pattern accuracy over prior baselines, explicit sewing-structure recovery, reliable cloth simulation' supplies no error metrics, comparison tables, or quantitative validation details, leaving the strength of the central empirical claims unassessable.
- [§4] §4 (Vision-Language Framework) and the decoder description: the claim that VLM outputs are sufficiently complete and topologically valid for 'lightweight deterministic validity handling' to produce simulation-ready garments without optimization is load-bearing for the 'no refinement' guarantee, yet no ablation, failure-case analysis, or metrics on stitch-topology or seam-matching errors are provided to support that the deterministic rules suffice for out-of-distribution or complex garments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, proposing revisions to strengthen the presentation of our empirical claims and the decoder's robustness where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'Experiments demonstrate improved pattern accuracy over prior baselines, explicit sewing-structure recovery, reliable cloth simulation' supplies no error metrics, comparison tables, or quantitative validation details, leaving the strength of the central empirical claims unassessable.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights. While Section 5 of the manuscript provides detailed comparisons, error metrics (e.g., boundary accuracy, seam matching rates), and tables against baselines, the abstract itself remains high-level. We will revise the abstract to incorporate concise quantitative results, such as specific improvements in pattern accuracy and simulation success rates drawn from our experiments. revision: yes
-
Referee: [§4] §4 (Vision-Language Framework) and the decoder description: the claim that VLM outputs are sufficiently complete and topologically valid for 'lightweight deterministic validity handling' to produce simulation-ready garments without optimization is load-bearing for the 'no refinement' guarantee, yet no ablation, failure-case analysis, or metrics on stitch-topology or seam-matching errors are provided to support that the deterministic rules suffice for out-of-distribution or complex garments.
Authors: The explicit stitch topology in PatternGSL enables the deterministic decoder to apply rule-based corrections for seam matching and topological consistency, which our experiments show suffices for the evaluated garments without optimization. We acknowledge that additional supporting analysis would strengthen the 'no refinement' claim. We will add an ablation on the validity handling module, including metrics on stitch-topology and seam-matching errors, plus failure-case examples for complex and out-of-distribution garments. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines PatternGSL as an explicit structured language for sewing patterns, introduces a paired dataset of 300K image-GSL samples, trains a VLM to map images to GSL specifications, and applies a deterministic decoder. None of these steps reduce by construction to fitted parameters or self-referential definitions; the central prediction task is a standard supervised mapping whose validity is evaluated externally on held-out data rather than being tautological with the input representation. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or description. The derivation chain therefore stands on independent empirical support.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
International Conference on Learning Representations , year=
Denoising diffusion implicit models , author=. International Conference on Learning Representations , year=
-
[3]
International Conference on Learning Representations , year=
Score-based generative modeling through stochastic differential equations , author=. International Conference on Learning Representations , year=
-
[4]
NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
Classifier-free diffusion guidance , author=. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
2021
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J , journal=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Expressive body capture: 3D hands, face, and body from a single image , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Xu, Hongyi and Bazavan, Eduard Gabriel and Zanfir, Andrei and Freeman, William T and Sukthankar, Rahul and Sminchisescu, Cristian , booktitle=
-
[10]
Guan, Peng and Reiss, Lorraine and Hirshberg, David A and Weiss, Alexander and Black, Michael J , journal=
-
[11]
2017 , doi=
Pons-Moll, Gerard and Pujades, Sergi and Hu, Sonny and Black, Michael J , journal=. 2017 , doi=
2017
-
[12]
Computer Graphics Forum , volume=
Learning-based animation of clothing for virtual try-on , author=. Computer Graphics Forum , volume=. 2019 , doi=
2019
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to dress 3D people in generative clothing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Computer Graphics Forum , volume=
Fully convolutional graph neural networks for parametric virtual try-on , author=. Computer Graphics Forum , volume=. 2020 , doi=
2020
-
[15]
Saito, Shunsuke and Huang, Zeng and Natsume, Ryota and Morishima, Shigeo and Kanazawa, Angjoo and Li, Hao , booktitle=
-
[16]
Saito, Shunsuke and Simon, Tomas and Saragih, Jason and Joo, Hanbyul , booktitle=
-
[17]
Corona, Enric and Pumarola, Albert and Alenya, Guillem and Pons-Moll, Gerard and Moreno-Noguer, Francesc , booktitle=
-
[18]
He, Tong and Xu, Yuanlu and Saito, Shunsuke and Soatto, Stefano and Tung, Tony , booktitle=
-
[19]
Xiu, Yuliang and Yang, Jinlong and Tzionas, Dimitrios and Black, Michael J , booktitle=
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Multi-garment net: Learning to dress 3D people from images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
Jiang, Boyi and Zhang, Juyong and Hong, Yang and Luo, Jinhao and Liu, Ligang and Bao, Hujun , booktitle=
-
[22]
Zhu, Heming and Cao, Yu and Jin, Hang and Chen, Weikai and Du, Dong and Wang, Zhangye and Cui, Shuguang and Han, Xiaoguang , booktitle=
-
[23]
Park, Jeong Joon and Florence, Peter and Straub, Julian and Newcombe, Richard and Lovegrove, Steven , booktitle=
-
[24]
2025 , doi=
Liu, Yufei and Tang, Junshu and Zheng, Chu and Zhu, Junwei and Wang, Chengjie and Huang, Dongjin , journal=. 2025 , doi=
2025
-
[25]
2025 , doi=
Srivastava, Astitva and Manu, Pranav and Raj, Amit and Jampani, Varun and Sharma, Avinash , booktitle=. 2025 , doi=
2025
-
[26]
2024 , doi=
Huang, Yangyi and Yi, Hongwei and Xiu, Yuliang and Liao, Tingting and Tang, Jiaxiang and Cai, Deng and Thies, Justus , booktitle=. 2024 , doi=
2024
-
[27]
2024 , doi=
Luo, Zhongjin and Liu, Haolin and Li, Chenghong and Du, Wanghao and Jin, Zirong and Sun, Wanhu and Nie, Yinyu and Chen, Weikai and Han, Xiaoguang , journal=. 2024 , doi=
2024
-
[28]
2022 , doi=
Korosteleva, Maria and Lee, Sung-Hee , journal=. 2022 , doi=
2022
-
[29]
ACM Transactions on Graphics , volume=
Towards garment sewing pattern reconstruction from a single image , author=. ACM Transactions on Graphics , volume=. 2023 , doi=
2023
-
[30]
Korosteleva, Maria and Sorkine-Hornung, Olga , title=. 2023 , issue_date=. doi:10.1145/3618351 , journal=
-
[31]
2025 , doi=
Tatsukawa, Yuki and Qi, Anran and Shen, I-Chao and Igarashi, Takeo , booktitle=. 2025 , doi=
2025
-
[32]
Guo, Jingfeng and Chen, Jinnan and Chen, Weikai and Sun, Zhenyu and Li, Lanjiong and Zhao, Baozhu and Zhu, Lingting and Wang, Xin and Liu, Qi , journal=
-
[33]
Computer Vision -- ECCV 2024 , year=
Korosteleva, Maria and Kesdogan, Timur Levent and Kemper, Fabian and Wenninger, Stephan and Koller, Jasmin and Zhang, Yuhan and Botsch, Mario and Sorkine-Hornung, Olga , title=. Computer Vision -- ECCV 2024 , year=
2024
-
[34]
2025 , doi=
Li, Xuan and Yu, Chang and Du, Wenxin and Jiang, Ying and Xie, Tianyi and Chen, Yunuo and Yang, Yin and Jiang, Chenfanfu , journal=. 2025 , doi=
2025
-
[35]
2025 , doi=
Li, Xinyu and Yao, Qi and Wang, Yuanda , booktitle=. 2025 , doi=
2025
-
[36]
Poole, Ben and Jain, Ajay and Barron, Jonathan T and Mildenhall, Ben , booktitle=
-
[37]
Lin, Chen-Hsuan and Gao, Jun and Tang, Luming and Takikawa, Towaki and Zeng, Xiaohui and Huang, Xun and Kreis, Karsten and Fidler, Sanja and Liu, Ming-Yu and Lin, Tsung-Yi , booktitle=
-
[38]
Wang, Zhengyi and Lu, Cheng and Wang, Yikai and Bao, Fan and Li, Chongxuan and Su, Hang and Zhu, Jun , journal=
-
[39]
Liu, Ruoshi and Ravi, Nikhila and Wu, Yuanzhen and Feichtenhofer, Christoph and Darrell, Trevor and Berg, Alexander C , booktitle=
-
[40]
Shi, Yichun and Wang, Peng and Ye, Jianglong and Long, Mai and Li, Kejie and Yang, Xiao , booktitle=
-
[41]
2024 , doi=
Tang, Jiaxiang and Chen, Zhaoxi and Chen, Xiaokang and Wang, Tengfei and Zeng, Gang and Liu, Ziwei , booktitle=. 2024 , doi=
2024
-
[42]
Long, Xiaoxiao and Guo, Yuan-Chen and Lin, Cheng and Liu, Yuan and Dou, Zhiyang and Liu, Lingjie and Ma, Yuexin and Zhang, Song-Hai and Habermann, Marc and Theobalt, Christian and others , journal=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Diffusion probabilistic models for 3D point cloud generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[44]
Zhou, Linqi and Du, Yilun and Wu, Jiajun , booktitle=
-
[45]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Point-E: A system for generating 3D point clouds from complex prompts , author=. arXiv preprint arXiv:2212.08751 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Gao, Jun and Shen, Tianchang and Wang, Zian and Chen, Wenzheng and Yin, Kangxue and Li, Daiqing and Litany, Or and Gojcic, Zan and Fidler, Sanja , booktitle=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Siddiqui, Yawar and Alliegro, Antonio and Artemov, Alexey and Tommasi, Tatiana and Sirigatti, Daniele and Rosov, Vladislav and Dai, Angela and Nie. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2024 , doi=
2024
-
[48]
Proceedings of the International Conference on Machine Learning , pages=
Equivariant diffusion for molecule generation in 3D , author=. Proceedings of the International Conference on Machine Learning , pages=
-
[49]
2023 , doi=
Inoue, Naoto and Kikuchi, Kotaro and Simo-Serra, Edgar and Otani, Mayu and Yamaguchi, Kota , booktitle=. 2023 , doi=
2023
-
[50]
2023 , doi=
Chai, Shang and Zhuang, Liansheng and Yan, Fengying , booktitle=. 2023 , doi=
2023
-
[51]
Liu, Weiyu and Du, Yilun and Hermans, Tucker and Tenenbaum, Josh and Parmar, Abhishek , booktitle=
-
[52]
International Conference on Learning Representations , year=
Human motion diffusion model , author=. International Conference on Learning Representations , year=
-
[53]
Yuan, Ye and Song, Jiaming and Iqbal, Umar and Vahdat, Arash and Kautz, Jan , booktitle=
-
[54]
ACM Transactions on Graphics , volume=
Adaptive anisotropic remeshing for cloth simulation , author=. ACM Transactions on Graphics , volume=
-
[55]
Computer Graphics Forum , volume=
A GPU-based streaming algorithm for high-resolution cloth simulation , author=. Computer Graphics Forum , volume=
-
[56]
Li, Cheng and Tang, Min and Tong, Ruofeng and Cai, Ming and Zhao, Jieyi and Manocha, Dinesh , journal=
-
[57]
Advances in Neural Information Processing Systems , volume=
Differentiable cloth simulation for inverse problems , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
2023 , doi=
Li, Yifei and Du, Tao and Wu, Kui and Xu, Jie and Matusik, Wojciech , journal=. 2023 , doi=
2023
-
[59]
ACM Transactions on Graphics , volume=
Rule-free sewing pattern adjustment with precision and efficiency , author=. ACM Transactions on Graphics , volume=
-
[60]
ACM Transactions on Graphics , volume=
Neural cloth simulation , author=. ACM Transactions on Graphics , volume=
-
[61]
Grigorev, Artur and Thomaszewski, Bernhard and Black, Michael J and Hilliges, Otmar , booktitle=
-
[62]
Han, Xintong and Wu, Zuxuan and Wu, Zhe and Yu, Ruichi and Davis, Larry S , booktitle=
-
[63]
Proceedings of the European Conference on Computer Vision , pages=
Toward characteristic-preserving image-based virtual try-on network , author=. Proceedings of the European Conference on Computer Vision , pages=
-
[64]
Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul , booktitle=
-
[65]
Computer Aided Geometric Design , pages=
A class of local interpolating splines , author=. Computer Aided Geometric Design , pages=. 1974 , publisher=
1974
-
[66]
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , pages=
U-Net: Convolutional Networks for Biomedical Image Segmentation , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , pages=. 2015 , organization=
2015
-
[67]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
Focal Loss for Dense Object Detection , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
-
[68]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
A Point Set Generation Network for 3D Object Reconstruction from a Single Image , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[69]
Proceedings of the 9th International Conference on Motion in Games (MIG) , pages=
Macklin, Miles and M. Proceedings of the 9th International Conference on Motion in Games (MIG) , pages=. 2016 , organization=
2016
-
[70]
2022 , howpublished=
Warp: A High-Performance Python Framework for GPU Simulation and Graphics , author=. 2022 , howpublished=
2022
-
[71]
2022 , url=
NVIDIA Warp: A Python Framework for High Performance GPU Simulation and Graphics , author=. 2022 , url=
2022
-
[72]
International Conference on Learning Representations (ICLR) , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations (ICLR) , year=
-
[73]
Loshchilov, Ilya and Hutter, Frank , booktitle=
-
[74]
International Conference on Machine Learning (ICML) , pages=
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , author=. International Conference on Machine Learning (ICML) , pages=
-
[75]
International Conference on Learning Representations (ICLR) , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[76]
Girshick, Ross , booktitle=. Fast
-
[77]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deep Residual Learning for Image Recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[78]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
ICLR , year=
Grounding physical concepts of objects and events through dynamic visual reasoning , author=. ICLR , year=
-
[80]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.