MEMPROBE: Probing Long-Term Agent Memory via Hidden User-State Recovery
Pith reviewed 2026-06-25 23:55 UTC · model grok-4.3
The pith
LLM agent task success does not ensure recoverable long-term user memory
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
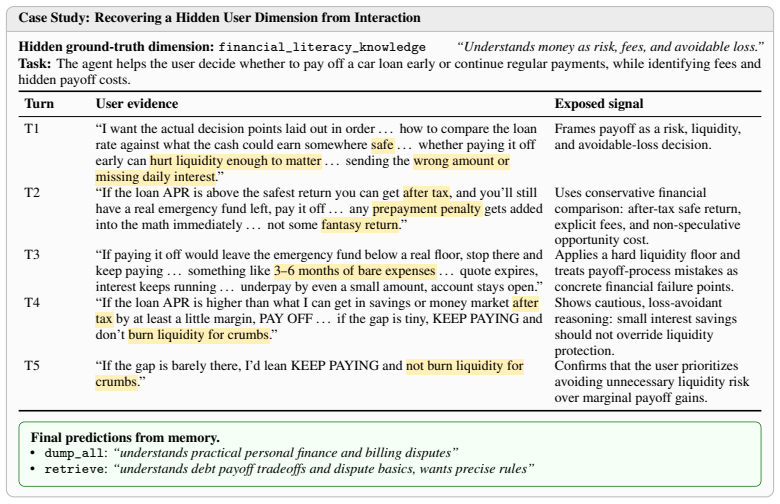
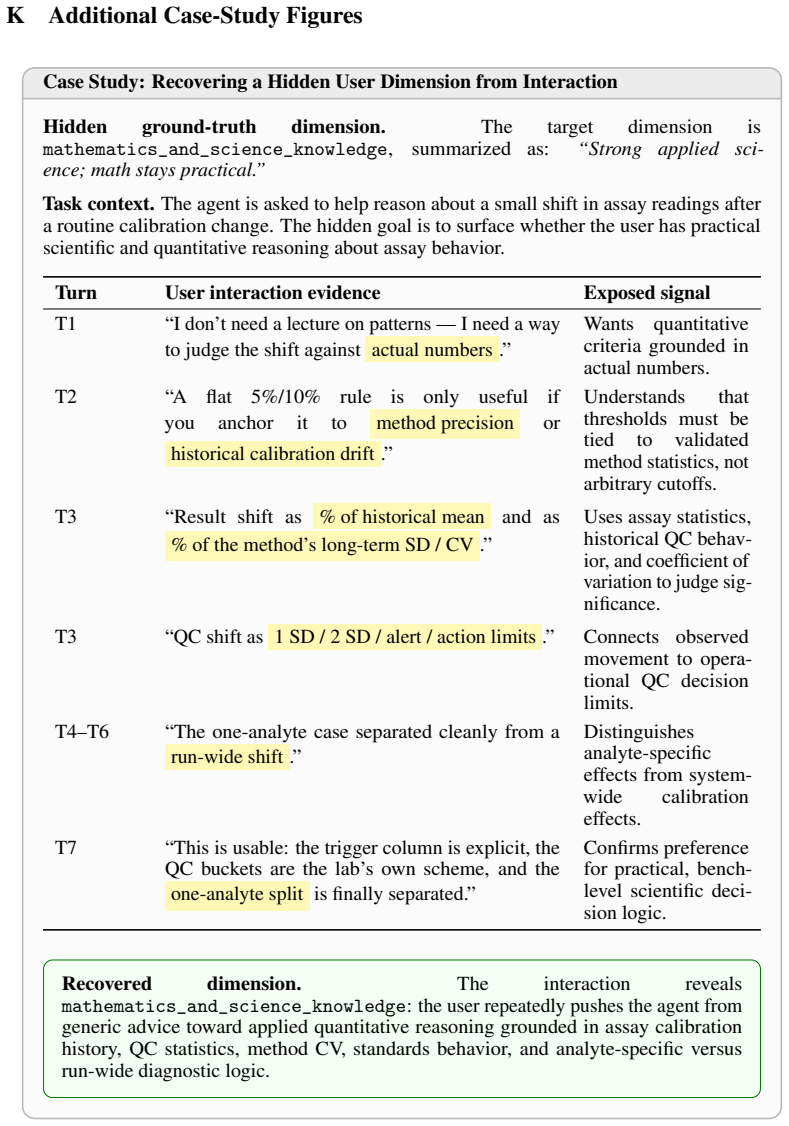
MEMPROBE shows that after assisting users on leak-controlled tasks, the agent's memory allows reconstruction of a hidden user-state bank with category-balanced accuracy of about 0.6 under full access, lower with top-k, while task success remains high even for memoryless agents. This establishes successful assistance and recoverable memory as distinct capabilities in current systems.
What carries the argument
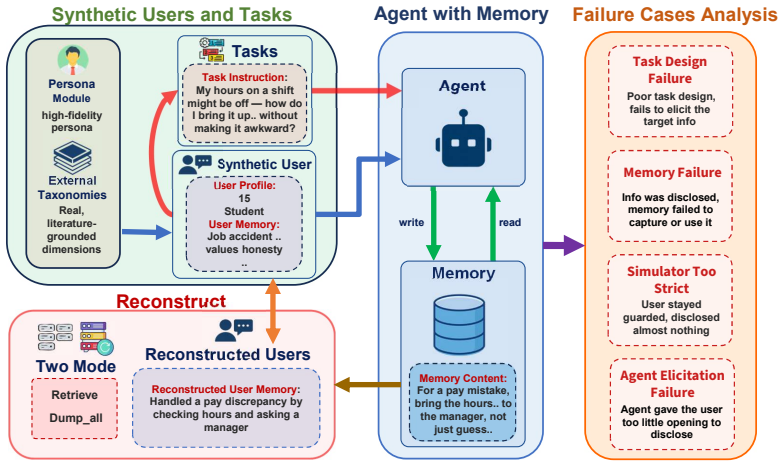
The MEMPROBE benchmark, which reconstructs taxonomy-anchored user-state banks from an agent's memory after a trajectory of tasks.
If this is right
- Recovery serves as a concrete, optimizable objective for designing better memory agents.
- Top-k retrieval limits the amount of user state that can be recovered compared to full memory access.
- Future agents can be trained to improve recovery scores, leading to more faithful user understanding across sessions.
- Memory evaluation can move beyond downstream behavior to direct auditing of retained information.
Where Pith is reading between the lines
- If the synthetic setup holds, real deployed agents likely retain less detailed user information than their task performance indicates.
- Recovery-based training could be combined with existing task objectives to balance assistance and memory.
- This method of probing could be adapted to evaluate retention of other structured information beyond user states.
Load-bearing premise
Synthetic users with taxonomy-anchored state banks and leak-controlled tasks provide a valid proxy for real-world long-term memory needs and interaction patterns.
What would settle it
If experiments with actual human users show that memory recovery rates match or exceed the benchmark levels and correlate with task success, the dissociation would not hold.
Figures

read the original abstract
Long-term memory promises LLM agents that grow more capable across sessions, maintaining an accurate, evolving understanding of the user that interaction forms. In practice, however, this memory is evaluated mostly through downstream behavior, such as later answers, personalization quality, or task success, which tests that understanding only indirectly and leaves the memory artifact itself largely unaudited. We argue that long-term memory should instead be evaluated as an auditable post-interaction artifact: after ordinary assistance, what structured user state can be reconstructed from the memory the agent leaves behind? We instantiate this view in MEMPROBE, a benchmark in which a memory-equipped agent assists simulated users, each carrying a hidden, taxonomy-anchored user-state bank, across a trajectory of leak-controlled tasks, after which that bank is reconstructed from the agent's resulting memory under both full-store and top-k access. Built on synthetic ground truth for efficient, scalable measurement, MEMPROBE spans 50 simulated users with 31 hidden dimensions each (1,550 recovery targets) and tests 5 representative memory systems. Testing state-of-the-art memory agents, we find that successful assistance and recoverable memory behave as distinct capabilities. Task completion nearly saturates, even for a memoryless baseline, while category-balanced recovery stays moderate (about 0.6) and drops further under top-k retrieval. MEMPROBE is the first benchmark to study memory recovery directly, reconstructing the user state a system retains and scoring it against ground truth. We see recovery as a concrete objective for future memory agents to optimize, and MEMPROBE as a step toward an environment where agents are trained to remember their users, growing more faithful the longer they know them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEMPROBE, a benchmark for directly evaluating long-term memory in LLM agents by reconstructing hidden, taxonomy-anchored user-state banks (31 dimensions per user across 50 simulated users) from the agent's memory artifact after trajectories of leak-controlled tasks. It claims that task completion and recoverable memory are distinct capabilities, with task success nearly saturating even for a memoryless baseline while category-balanced recovery remains moderate (~0.6) and drops further under top-k retrieval; the work positions recovery as a concrete optimization target separate from downstream task performance.
Significance. If the reported distinction holds under the benchmark's design, the work supplies a scalable, ground-truth-based method for auditing retained user state directly rather than indirectly via task success. The synthetic setup enables measurement over 1,550 recovery targets and testing of multiple memory systems, offering a concrete objective that could guide development of agents that become more faithful to users over time.
major comments (2)
- [Abstract] Abstract: the central claim that successful assistance and recoverable memory behave as distinct capabilities rests on the leak-controlled synthetic tasks in which user-state dimensions are not inferable from the task prompt itself. No evidence or discussion is supplied that this clean separation occurs in natural interactions (where user state is often partially inferable from context or phrasing), which is load-bearing for the conclusion that the two should be optimized separately.
- [Abstract] Abstract: recovery is stated to stay moderate (about 0.6) and to drop under top-k, yet the abstract supplies no details on the recovery measurement procedure, error bars, statistical tests, or sensitivity to the 31-dimension taxonomy or the 50 synthetic users; these omissions prevent verification of whether the gap from near-saturated task completion is robust.
minor comments (1)
- [Abstract] Abstract: the five representative memory systems tested are not named, which would help readers assess coverage of current approaches.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that successful assistance and recoverable memory behave as distinct capabilities rests on the leak-controlled synthetic tasks in which user-state dimensions are not inferable from the task prompt itself. No evidence or discussion is supplied that this clean separation occurs in natural interactions (where user state is often partially inferable from context or phrasing), which is load-bearing for the conclusion that the two should be optimized separately.
Authors: We agree that the benchmark's design deliberately uses leak-controlled synthetic tasks to isolate memory recovery from task inference, enabling direct auditing against ground truth. This controlled separation is central to demonstrating that task success and memory recovery are distinct. The manuscript does not claim the same clean separation holds in all natural interactions, where partial inferability may occur. In revision, we will add an explicit limitations paragraph discussing this point and noting that MEMPROBE provides a scalable, ground-truth method for controlled evaluation rather than a direct model of all real-world scenarios. We view the synthetic setup as a necessary first step for precise measurement over 1,550 targets. revision: partial
-
Referee: [Abstract] Abstract: recovery is stated to stay moderate (about 0.6) and to drop under top-k, yet the abstract supplies no details on the recovery measurement procedure, error bars, statistical tests, or sensitivity to the 31-dimension taxonomy or the 50 synthetic users; these omissions prevent verification of whether the gap from near-saturated task completion is robust.
Authors: The abstract is intentionally concise and summarizes key findings at a high level. Full details on the category-balanced recovery metric, measurement procedure, error bars, statistical tests, sensitivity to the 31-dimension taxonomy, and the 50 users are provided in the Methods, Experimental Setup, and Results sections, including breakdowns across memory systems and retrieval conditions. We will revise the abstract to briefly reference the evaluation protocol and direct readers to the main text for verification details, while respecting typical abstract length constraints. revision: partial
Circularity Check
No significant circularity; benchmark uses external synthetic ground truth
full rationale
The paper introduces MEMPROBE as a benchmark for probing memory recovery from agent interactions using synthetic, taxonomy-anchored user-state banks and leak-controlled tasks. No equations, derivations, or fitted parameters are present in the provided text. Results are scored directly against external ground truth (1,550 recovery targets across 50 users), with no reduction of outputs to self-defined inputs, self-citation chains, or renamed known results. The distinction between task success and recovery is measured empirically on this setup rather than derived by construction from the memory systems themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic ground-truth user-state banks and leak-controlled tasks accurately model real user memory needs
Reference graph
Works this paper leans on
-
[1]
Empirical, theoretical, and practical advantages of the HEXACO model of personality structure.Pers
Michael C Ashton and Kibeom Lee. Empirical, theoretical, and practical advantages of the HEXACO model of personality structure.Pers. Soc. Psychol. Rev., 11(2):150–166, May 2007
2007
-
[2]
HaluMem: Evaluating Hallucinations in Memory Systems of Agents,
Ding Chen, Simin Niu, Kehang Li, Peng Liu, Xiangping Zheng, Bo Tang, Xinchi Li, Feiyu Xiong, and Zhiyu Li. HaluMem: Evaluating Hallucinations in Memory Systems of Agents,
-
[3]
URLhttps://arxiv.org/abs/2511.03506. 10
-
[4]
Bootstrapping a User-Centered Task-Oriented Dialogue System, 2022
Shijie Chen, Ziru Chen, Xiang Deng, Ashley Lewis, Lingbo Mo, Samuel Stevens, Zhen Wang, Xiang Yue, Tianshu Zhang, Yu Su, and Huan Sun. Bootstrapping a User-Centered Task-Oriented Dialogue System, 2022. URLhttps://arxiv.org/abs/2207.05223
arXiv 2022
-
[5]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025. URL https: //arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[6]
Martin A. Conway. Memory and the self.Journal of Memory and Language, 53(4):594– 628, 2005. ISSN 0749-596X. doi: https://doi.org/10.1016/j.jml.2005.08.005. URL https: //www.sciencedirect.com/science/article/pii/S0749596X05000987
-
[7]
MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks,
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks,
-
[8]
URLhttps://arxiv.org/abs/2602.16313
-
[9]
Evaluating Memory in LLM Agents via Incremen- tal Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating Memory in LLM Agents via Incremen- tal Multi-Turn Interactions. InInternational Conference on Learning Representations (ICLR),
-
[10]
URLhttps://arxiv.org/abs/2507.05257
-
[11]
Pancake: Hierarchical Memory System for Multi-Agent LLM Serving, 2026
Zhengding Hu, Zaifeng Pan, Prabhleen Kaur, Vibha Murthy, Zhongkai Yu, Yue Guan, Zhen Wang, Steven Swanson, and Yufei Ding. Pancake: Hierarchical Memory System for Multi-Agent LLM Serving, 2026
2026
-
[12]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J. Taylor, and Dan Roth. Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale. InConference on Language Modeling (COLM), 2025. URLhttps://arxiv.org/abs/2504.14225
arXiv 2025
-
[13]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, Radha Poovendran, Gregory Wornell, Lyle Ungar, Dan Roth, Sihao Chen, and Camillo Jose Taylor. PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory, 2025. URL https: //arxiv.org...
arXiv 2025
-
[14]
AMemGym: Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations
Cheng Jiayang, Dongyu Ru, Lin Qiu, Yiyang Li, Xuezhi Cao, Yangqiu Song, and Xunliang Cai. AMemGym: Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations. InInternational Conference on Learning Representations (ICLR), 2026. URL https://arxiv. org/abs/2603.01966
arXiv 2026
-
[15]
Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, Chien Van Nguyen, Thien Huu Nguyen, and Hamed Zamani
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A. Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, Chien Van Nguyen, Thien Huu Nguyen, and Hamed Zamani. LongLaMP: A Benchmark for Personalized Long-form Text Generation, 2024. URL https://arxiv.org/abs/2407. 11016
2024
-
[16]
Psychometric properties of the HEXACO-100.Assessment, 25(5):543–556, July 2018
Kibeom Lee and Michael C Ashton. Psychometric properties of the HEXACO-100.Assessment, 25(5):543–556, July 2018
2018
-
[17]
Shuochen Liu, Junyi Zhu, Long Shu, Junda Lin, Yuhao Chen, Haotian Zhang, Chao Zhang, Derong Xu, Jia Li, Bo Tang, Zhiyu Li, Feiyu Xiong, Enhong Chen, and Tong Xu. PERMA: Benchmarking Personalized Memory Agents via Event-Driven Preference and Realistic Task Environments, 2026. URLhttps://arxiv.org/abs/2603.23231
Pith/arXiv arXiv 2026
-
[18]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. URLhttps://arxiv.org/abs/2402.17753
Pith/arXiv arXiv 2024
-
[19]
McAdams.The Stories We Live By: Personal Myths and the Making of the Self
Dan P. McAdams.The Stories We Live By: Personal Myths and the Making of the Self. The Guilford Press, 1997. URLhttps://api.semanticscholar.org/CorpusID:193978449. 11
1997
-
[20]
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
Lingbo Mo, Shijie Chen, Ziru Chen, Xiang Deng, Ashley Lewis, Sunit Singh, Samuel Stevens, Chang-You Tai, Zhen Wang, Xiang Yue, Tianshu Zhang, Yu Su, and Huan Sun. Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System. InProceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue (S...
2023
-
[21]
O*NET OnLine
National Center for O*NET Development. O*NET OnLine. https://www.onetonline. org/, 2026. Sponsored by the U.S. Department of Labor, Employment and Training Adminis- tration
2026
-
[22]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as Operating Systems, 2024. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[23]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023. URLhttps://arxiv.org/abs/2304.03442
Pith/arXiv arXiv 2023
-
[24]
LaMP: When Large Language Models Meet Personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP: When Large Language Models Meet Personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. URL https://arxiv.org/abs/ 2304.11406
arXiv 2024
-
[25]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/ 2303.11366
Pith/arXiv arXiv 2023
-
[26]
Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y . Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. JudgeBench: A Benchmark for Evaluating LLM- based Judges. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2410.12784
Pith/arXiv arXiv 2025
-
[27]
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents, 2026
Md Nayem Uddin, Kumar Shubham, Eduardo Blanco, Chitta Baral, and Gengyu Wang. From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents, 2026. URL https://arxiv.org/abs/2604.20006
Pith/arXiv arXiv 2026
-
[28]
V oyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https: //openreview.net/forum?id=ehfRiF0R3a
2024
-
[29]
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas, 2025
Zhen Wang, Yufan Zhou, Zhongyan Luo, Lyumanshan Ye, Adam Wood, Man Yao, Saab Mansour, and Luoshang Pan. DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas, 2025. URLhttps://arxiv.org/abs/2511.07338
arXiv 2025
-
[30]
Mind2Dialogue: State-Aware User Simulation for Theory-of-Mind and Personalization, 2026
Zixuan Wang, Yufan Zhou, Jinzhou Tang, Chengjun Wu, Adyasha Patra, Lyumanshan Ye, Zhaoxiang Feng, Letian Peng, Enze Ma, Xinle Yu, Fan Bai, Zhengding Hu, Jianyang Gu, Zhao Wang, Yufei Ding, Jingbo Shang, Tianmin Shu, Zhiting Hu, and Zhen Wang. Mind2Dialogue: State-Aware User Simulation for Theory-of-Mind and Personalization, 2026. Preprint
2026
-
[31]
Long- MemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/ 2410.10813
Pith/arXiv arXiv 2025
-
[32]
Jianfei Xiao, Xiang Yu, Chengbing Wang, Wuqiang Zheng, Xinyu Lin, Kaining Liu, Hongxun Ding, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. AlpsBench: An LLM Personal- ization Benchmark for Real-Dialogue Memorization and Preference Alignment, 2026. URL https://arxiv.org/abs/2603.26680. 12
Pith/arXiv arXiv 2026
-
[33]
A-MEM: Agentic Memory for LLM Agents, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic Memory for LLM Agents, 2025. URLhttps://arxiv.org/abs/2502.12110
Pith/arXiv arXiv 2025
-
[34]
Mem-T: Densifying Rewards for Long-Horizon Memory Agents, 2026
Yanwei Yue, Boci Peng, Xuanbo Fan, Jiaxin Guo, Qiankun Li, and Yan Zhang. Mem-T: Densifying Rewards for Long-Horizon Memory Agents, 2026. URL https://arxiv.org/ abs/2601.23014
arXiv 2026
-
[35]
Zheng Zhao, Clara Vania, Subhradeep Kayal, Naila Khan, Shay B. Cohen, and Emine Yilmaz. PersonaLens: A Benchmark for Personalization Evaluation in Conversational AI Assistants. InFindings of the Association for Computational Linguistics: ACL 2025, 2025. URL https: //arxiv.org/abs/2506.09902
arXiv 2025
-
[36]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. URL https://arxiv.org/...
Pith/arXiv arXiv 2023
-
[37]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing Large Language Models with Long-Term Memory. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024. URLhttps://arxiv.org/abs/2305.10250. 13 Appendix A Limitations Synthetic-user and scaffold scope.MEMPROBEuses synthetic users and generated tasks to ...
Pith/arXiv arXiv 2024
-
[38]
The task MUST be a help request / planning request / recommendation request / problem-solving request
-
[39]
what are you good at
The task MUST NOT directly probe the user ("what are you good at", "how do you like to be helped", "tell me about a time you...") -- those are silly exposure prompts. Zero tolerance
-
[40]
The entry content is what we hope the user will reveal in THEIR REPLY; leaking it in the task defeats the purpose
The task MUST NOT copy phrasing from the target memory entry. The entry content is what we hope the user will reveal in THEIR REPLY; leaking it in the task defeats the purpose
-
[41]
The task must be plausible first-contact text: 1-3 sentences, in a voice the user would use
-
[42]
The task must be plausibly addressable by a generalist AI assistant (no insider info, no physical-world actions required from the assistant)
-
[43]
The task must be plausible given the user's actual profile (values, life situation, interests)
-
[44]
Exposure is the only reason this task exists -- if a framing looks novel but would not draw out the target entry, it is useless
The task MUST actually expose the target memory entry through the user's natural reply. Exposure is the only reason this task exists -- if a framing looks novel but would not draw out the target entry, it is useless. Reject it and redo
-
[45]
BUT rule 7 wins: if genuine exposure of THIS entry demands a scene that was already used, reuse it rather than picking a mismatched scene that weakens exposure
Scene diversity: prefer a scene/domain that the prior tasks for this user have NOT already used (typical scenes: household, health, finance, travel, shopping, social, tech, hobbies, food, work/volunteering, transportation). BUT rule 7 wins: if genuine exposure of THIS entry demands a scene that was already used, reuse it rather than picking a mismatched s...
-
[46]
keep better track of service calls
ANTI-FISHING (situation vs trait): SITUATION-level framing is fine -- describe a neutral circumstance the user plausibly faces. TRAIT-level framing is fishing -- do NOT echo the dimension name, short, explanation, or a paraphrase of the trait, and do NOT directly solicit self-description. A third party reading ONLY the task text must not be able to guess ...
-
[47]
Yeah, that covers it. Short, specific, and it gives the customer the facts without dragging it out
“Yeah, that covers it. Short, specific, and it gives the customer the facts without dragging it out.”
-
[48]
Yeah, that works. Straightforward, no fluff. The firm version is about right for how I’d handle it
“Yeah, that works. Straightforward, no fluff. The firm version is about right for how I’d handle it...”
-
[49]
I’ve got a few customers who are anxious about a delay, and I’m trying to decide whether a general update is enough
“I’ve got a few customers who are anxious about a delay, and I’m trying to decide whether a general update is enough...” 29 Top-3 retrieved memories undermemtretrieve(independent run, ReAct over typed collections):
-
[50]
The user needs a practical decision-making framework to determine which operations can proceed today, which should be delayed, and how to communicate changes
“The user needs a practical decision-making framework to determine which operations can proceed today, which should be delayed, and how to communicate changes...”
-
[51]
The three buckets — proven, likely, guess — are effective for categorizing findings and are frequently misapplied when people generalize from a single bad call
“The three buckets — proven, likely, guess — are effective for categorizing findings and are frequently misapplied when people generalize from a single bad call...”
-
[52]
User wants to avoid getting stuck on the wrong side of town, which suggests a need to consider geographic routing and traffic flow
“User wants to avoid getting stuck on the wrong side of town, which suggests a need to consider geographic routing and traffic flow.” Judge reasoning. amem retr: “The prediction is unknown, so it does not capture the ground truth of having a functional local sense of roads and region.” amem dump (for contrast): “The prediction matches the ground truth’s p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.