Agentic Collaborative Cognition for Zero-Shot 3D Understanding
Pith reviewed 2026-06-26 05:35 UTC · model grok-4.3
The pith
A Planning Agent and Perception Agent collaborate in a closed loop to build a holistic cognitive map for zero-shot 3D understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
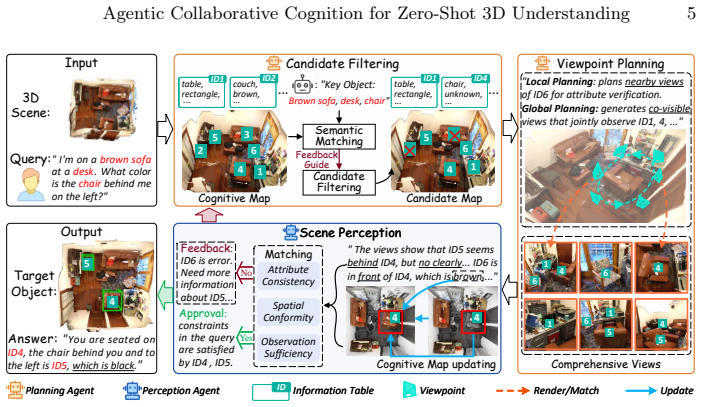
The paper claims that a closed-loop process in which a Planning Agent analyzes the current cognitive map to choose and supplement query-relevant viewpoints, while a Perception Agent assigns consistent instance identifiers across views, documents attributes, filters mismatches, and feeds back guidance, integrates fragmented observations into a single holistic cognitive map that supports accurate zero-shot 3D task completion.
What carries the argument
The closed-loop iterative collaboration between Planning Agent and Perception Agent that maintains a holistic cognitive map with cross-view consistent instance identifiers.
If this is right
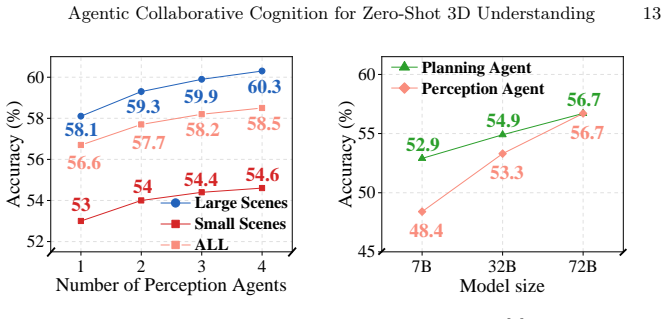
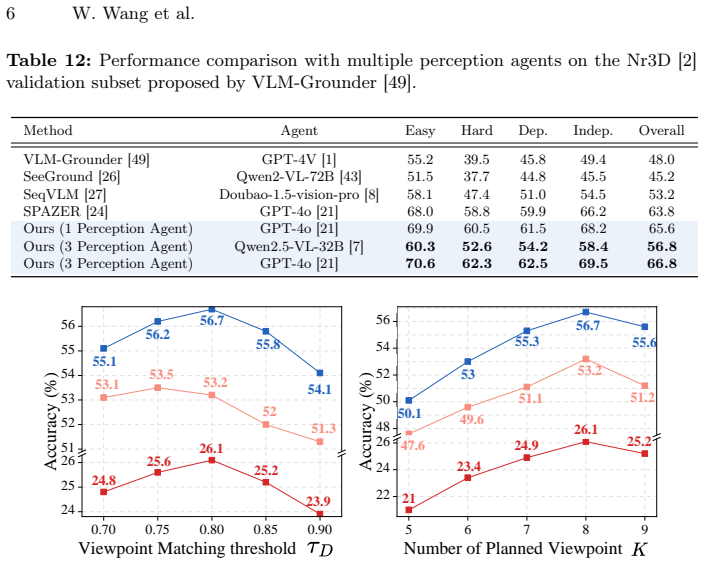
- The method reaches state-of-the-art results on six benchmarks, including an 11.1% gain in Acc@0.5 on ScanRefer.
- It produces a 14.6 BLEU-1 improvement on 3D-assisted dialog tasks.
- It yields a 2.1 EM improvement on SQA3D.
- The iterative process stops only when the Perception Agent judges that sufficient information has been collected.
Where Pith is reading between the lines
- If the identifier consistency mechanism holds for longer sequences, the same loop could support 3D reasoning over extended video streams or larger environments.
- The explicit cognitive map construction might transfer to other zero-shot vision-language settings that require cross-view object tracking.
- Adding a third agent focused on spatial relation extraction could be a direct extension without changing the core collaboration structure.
Load-bearing premise
The closed-loop collaboration between Planning and Perception Agents can consistently produce accurate cross-view instance identifiers and filter mismatched objects without accumulating errors that invalidate the final cognitive map.
What would settle it
Running the system on ScanRefer and finding that instance identifiers assigned by the Perception Agent become inconsistent across added viewpoints, causing repeated filtering failures and lower Acc@0.5 scores than reported, would falsify the central claim.
Figures



read the original abstract
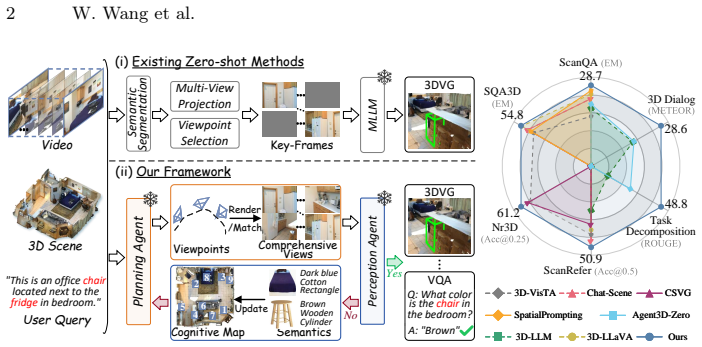
Recent advancements have explored agentic zero-shot 3D understanding by reformulating it as video keyframe understanding with Multimodal Large Language Models (MLLMs). However, existing methods face an intrinsic bottleneck due to the finite observation perspectives inherent in videos and the implicit perception of 3D scenes. In this paper, we propose a collaborative multi-agent framework that assigns a Planning Agent to handle high-level viewpoint planning and supplement novel perspectives, and a Perception Agent to explicitly summarize the 3D scene into a structured holistic cognitive map. Specifically, Planning Agent first analyzes this cognitive map to determine query-relevant viewpoints and supplements missing critical perspectives to ensure comprehensive observation. Subsequently, Perception Agent documents object-level attributes from these views by assigning consistent instance identifiers across viewpoints, thereby integrating fragmented observations into the holistic cognitive map. In parallel, it provides feedback to filter out mismatched candidate objects and guide subsequent viewpoint planning. Through this closed-loop iterative process, two agents collaboratively figure out candidates until Perception Agent determines that sufficient information has been captured to complete the task. Extensive experiments demonstrate that our method achieves state-of-the-art performance on 6 benchmarks, with improvements of 11.1\% Acc@0.5 on ScanRefer, 14.6 BLEU-1 on 3D-assisted dialog, and 2.1 EM on SQA3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a collaborative multi-agent framework for zero-shot 3D understanding with MLLMs. A Planning Agent analyzes a holistic cognitive map to plan and supplement query-relevant viewpoints, while a Perception Agent assigns consistent instance identifiers across views, integrates observations into the map, and provides feedback to filter mismatches in a closed-loop iterative process until the task is complete. The authors claim this yields SOTA results on 6 benchmarks, with gains of 11.1% Acc@0.5 on ScanRefer, 14.6 BLEU-1 on 3D-assisted dialog, and 2.1 EM on SQA3D.
Significance. If the closed-loop agent collaboration reliably produces consistent cross-view instance IDs and filters mismatches without error accumulation, the framework could meaningfully advance agentic approaches to 3D scene understanding by addressing limited video perspectives. The reported benchmark gains would then represent a substantive empirical contribution, though the absence of mechanistic validation leaves the attribution of those gains open.
major comments (2)
- [Abstract (iterative process paragraph)] Abstract (description of iterative process): the central claim that the Perception Agent 'assigns consistent instance identifiers across viewpoints' and 'provides feedback to filter out mismatched candidate objects' without error buildup is load-bearing for attributing SOTA performance to the framework, yet no matching criterion, similarity metric, or algorithm for ID consistency or mismatch detection is supplied. This directly engages the stress-test concern that moderate drift (e.g., from viewpoint variation or MLLM hallucination) would corrupt the cognitive map.
- [Method (agent collaboration)] Method section (agent collaboration description): no ablation, sensitivity analysis, or quantitative check on ID consistency or feedback efficacy is referenced, making it impossible to verify that the closed-loop process prevents the error accumulation that would invalidate downstream task performance. Without such evidence the experimental gains cannot be confidently linked to the proposed mechanism rather than implementation choices.
minor comments (2)
- [Abstract] The abstract is information-dense; expanding the description of the cognitive map construction with a high-level diagram or pseudocode would improve clarity without altering the technical content.
- [Experiments] The six benchmarks are listed only by name; adding a brief table or footnote with dataset characteristics and evaluation protocols would aid readers unfamiliar with the 3D understanding literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity around the agent collaboration mechanism. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (iterative process paragraph)] Abstract (description of iterative process): the central claim that the Perception Agent 'assigns consistent instance identifiers across viewpoints' and 'provides feedback to filter out mismatched candidate objects' without error buildup is load-bearing for attributing SOTA performance to the framework, yet no matching criterion, similarity metric, or algorithm for ID consistency or mismatch detection is supplied. This directly engages the stress-test concern that moderate drift (e.g., from viewpoint variation or MLLM hallucination) would corrupt the cognitive map.
Authors: We acknowledge that the abstract and current method description provide only a high-level overview of the Perception Agent's ID assignment and mismatch filtering without specifying the exact matching criterion, similarity metric, or algorithm. This omission limits the ability to evaluate error accumulation risks. We will expand the method section in the revision to include the precise algorithm, similarity metric (e.g., feature-based or embedding similarity), and mismatch detection procedure used. revision: yes
-
Referee: [Method (agent collaboration)] Method section (agent collaboration description): no ablation, sensitivity analysis, or quantitative check on ID consistency or feedback efficacy is referenced, making it impossible to verify that the closed-loop process prevents the error accumulation that would invalidate downstream task performance. Without such evidence the experimental gains cannot be confidently linked to the proposed mechanism rather than implementation choices.
Authors: We agree that the absence of ablations or quantitative checks on ID consistency and feedback efficacy makes it difficult to isolate the contribution of the closed-loop mechanism. We will add ablation studies and sensitivity analyses on these components (e.g., with/without feedback, varying consistency thresholds) to the experiments section in the revised manuscript to provide supporting evidence. revision: yes
Circularity Check
No circularity: empirical agent framework validated on external benchmarks
full rationale
The paper presents a multi-agent architecture (Planning + Perception Agents) for zero-shot 3D tasks and reports performance gains on six standard benchmarks (ScanRefer, 3D-assisted dialog, SQA3D, etc.). No equations, fitted parameters, or derived quantities appear in the provided text. Results are framed as experimental outcomes rather than predictions obtained by construction from the framework definition. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims. The derivation chain is therefore self-contained against external data and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can reliably perform high-level viewpoint planning and cross-view object attribute summarization when given structured feedback
invented entities (1)
-
holistic cognitive map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
In: European Conference on Computer Vision (ECCV)
Achlioptas, P., Abdelreheem, A., Xia, F., Elhoseiny, M., Guibas, L.: ReferIt3D: Neural listeners for fine-grained 3D object identification in real-world scenes. In: European Conference on Computer Vision (ECCV). pp. 422–440 (2020)
2020
-
[3]
Advances in neural information processing systems (NeurIPS) 35, 23716–23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems (NeurIPS) 35, 23716–23736 (2022)
2022
-
[4]
Computers11(2), 28 (2022)
Arena, F., Collotta, M., Pau, G., Termine, F.: An overview of augmented reality. Computers11(2), 28 (2022)
2022
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Azuma, D., Miyanishi, T., Kurita, S., Kawanabe, M.: Scanqa: 3d question answer- ing for spatial scene understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19129–19139 (2022)
2022
-
[6]
arXiv preprint arXiv:2308.129661(2), 3 (2023)
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.129661(2), 3 (2023)
Pith/arXiv arXiv 2023
-
[7]
arXiv preprint arXiv:2502.13923 (2025)
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[8]
ByteDance: VolcEngine (2025),https://console.volcengine.com/, accessed: 2025-02-18
2025
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chang, C.P., Wang, S., Pagani, A., Stricker, D.: MiKASA: Multi-key-anchor & scene-aware transformer for 3D visual grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14131–14140 (2024)
2024
-
[10]
In: European Conference on Computer Vision (ECCV)
Chen, D.Z., Chang, A.X., Nießner, M.: ScanRefer: 3D object localization in RGB- D scans using natural language. In: European Conference on Computer Vision (ECCV). pp. 202–221 (2020)
2020
-
[11]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Chen, Z., Gholami, A., Nießner, M., Chang, A.X.: Scan2cap: Context-aware dense captioning in rgb-d scans. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 3193–3203 (2021)
2021
-
[12]
Journal of Machine Learning Research (JMLR)25(70), 1–53 (2024)
Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al.: Scaling instruction-finetuned language models. Journal of Machine Learning Research (JMLR)25(70), 1–53 (2024)
2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scan- Net: Richly-annotated 3D reconstructions of indoor scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5828–5839 (2017)
2017
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Fan, Y., Ma, X., Su, R., Guo, J., Wu, R., Chen, X., Li, Q.: Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6342–6352 (2025)
2025
-
[15]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Fu, R., Liu, J., Chen, X., Nie, Y., Xiong, W.: Scene-llm: Extending language model for 3d visual reasoning. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2195–2206. IEEE (2025) Agentic Collaborative Cognition for Zero-Shot 3D Understanding 17
2025
-
[16]
In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., et al.: Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning. In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5021–5028. IEEE (2024)
2024
-
[17]
Advances in Neural Information Processing Systems (NeurIPS)36, 20482–20494 (2023)
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3d-llm: In- jecting the 3d world into large language models. Advances in Neural Information Processing Systems (NeurIPS)36, 20482–20494 (2023)
2023
-
[18]
Advances in Neural Information Processing Systems (NeurIPS)37, 113991–114017 (2024)
Huang, H., Chen, Y., Wang, Z., Huang, R., Xu, R., Wang, T., Liu, L., Cheng, X., Zhao, Y., Pang, J., et al.: Chat-scene: Bridging 3d scene and large language models with object identifiers. Advances in Neural Information Processing Systems (NeurIPS)37, 113991–114017 (2024)
2024
-
[19]
In: Proceedings of the International Conference on Machine Learning (ICML) (2024)
Huang, J., Yong, S., Ma, X., Linghu, X., Li, P., Wang, Y., Li, Q., Zhu, S.C., Jia, B., Huang, S.: An embodied generalist agent in 3D world. In: Proceedings of the International Conference on Machine Learning (ICML) (2024)
2024
-
[20]
arXiv preprint arXiv:2506.01946 (2025)
Huang, X., Wu, J., Xie, Q., Han, K.: MLLMs Need 3D-Aware Representation Supervision for Scene Understanding. arXiv preprint arXiv:2506.01946 (2025)
arXiv 2025
-
[21]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[22]
In: European Conference on Computer Vision (ECCV)
Jain, A., Gkanatsios, N., Mediratta, I., Fragkiadaki, K.: Bottom up top down detection transformers for language grounding in images and point clouds. In: European Conference on Computer Vision (ECCV). pp. 417–433. Springer (2022)
2022
-
[23]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Jin, Z., Hayat, M., Yang, Y., Guo, Y., Lei, Y.: Context-aware alignment and mu- tual masking for 3D-language pre-training. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 10984–10994 (2023)
2023
-
[24]
arXiv preprint arXiv:2506.21924 (2025)
Jin, Z., Tu, R.C., Liao, J., Sun, W., Luo, X., Liu, S., Tao, D.: SPAZER: Spatial- Semantic progressive reasoning agent for zero-shot 3d visual grounding. arXiv preprint arXiv:2506.21924 (2025)
arXiv 2025
-
[25]
In: Proceedings of the International Conference on Machine Learning (ICML)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 19730–19742. PMLR (2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Li, R., Li, S., Kong, L., Yang, X., Liang, J.: SeeGround: See and ground for Zero- Shot Open-Vocabulary 3D visual grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[27]
In: Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM)
Lin, J., Bian, S., Zhu, Y., Tan, W., Zhang, Y., Xie, Y., Qu, Y.: SeqVLM: Proposal- Guided Multi-View sequences reasoning via VLM for Zero-Shot 3D visual ground- ing. In: Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM). pp. 3094–3103 (2025)
2025
-
[28]
arXiv preprint arXiv:2412.09237 (2024)
Liu, Y., Liu, W., Gu, X., Rui, Y., He, X., Zhang, Y.: Lmagent: A large-scale mul- timodal agents society for multi-user simulation. arXiv preprint arXiv:2412.09237 (2024)
arXiv 2024
-
[29]
Advances in Neural Information Processing Systems (NeurIPS)36, 37193–37229 (2023)
Liu, Y., Kong, L., Cen, J., Chen, R., Zhang, W., Pan, L., Chen, K., Liu, Z.: Seg- ment any point cloud sequences by distilling vision foundation models. Advances in Neural Information Processing Systems (NeurIPS)36, 37193–37229 (2023)
2023
-
[30]
In: International Conference on Learning Representations (ICLR) (2023) 18 W
Ma, X., Yong, S., Zheng, Z., Li, Q., Liang, Y., Zhu, S.C., Huang, S.: SQA3D: Situated question answering in 3D scenes. In: International Conference on Learning Representations (ICLR) (2023) 18 W. Wang et al
2023
-
[31]
IEEE Robotics and Automation Letters9(10), 8921–8928 (2024)
Maggio, D., Chang, Y., Hughes, N., Trang, M., Griffith, D., Dougherty, C., Cristo- falo, E., Schmid, L., Carlone, L.: Clio: Real-time task-driven open-set 3d scene graphs. IEEE Robotics and Automation Letters9(10), 8921–8928 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR)
Man, Y., Gui, L.Y., Wang, Y.X.: Situational awareness matters in 3d vision lan- guage reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR). pp. 13678–13688 (2024)
2024
-
[33]
Annual Review of Control, Robotics, and Autonomous Systems8(2024)
Mascaro, R., Chli, M.: Scene representations for robotic spatial perception. Annual Review of Control, Robotics, and Autonomous Systems8(2024)
2024
-
[34]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[35]
arXiv preprint arXiv:2501.01428 (2025)
Qi, Z., Zhang, Z., Fang, Y., Wang, J., Zhao, H.: Gpt4scene: Understand 3d scenes from videos with vision-language models. arXiv preprint arXiv:2501.01428 (2025)
arXiv 2025
-
[36]
arXiv preprint arXiv:2109.08238 (2021)
Ramakrishnan, S.K., Gokaslan, A., Wijmans, E., Maksymets, O., Clegg, A., Turner, J., Undersander, E., Galuba, W., Westbury, A., Chang, A.X., et al.: Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for em- bodied ai. arXiv preprint arXiv:2109.08238 (2021)
Pith/arXiv arXiv 2021
-
[37]
arXiv preprint arXiv:2002.06289 (2020)
Rosinol, A., Gupta, A., Abate, M., Shi, J., Carlone, L.: 3d dynamic scene graphs: Actionable spatial perception with places, objects, and humans. arXiv preprint arXiv:2002.06289 (2020)
arXiv 2002
-
[38]
In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Schult, J., Engelmann, F., Hermans, A., Litany, O., Tang, S., Leibe, B.: Mask3D: Mask transformer for 3D semantic instance segmentation. In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 8216–8223. IEEE (2023)
2023
-
[39]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Shen, Z., Luo, H., Chen, K., Lv, F., Li, T.: Enhancing multi-robot semantic nav- igation through multimodal chain-of-thought score collaboration. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 14664–14672 (2025)
2025
-
[40]
arXiv preprint arXiv:2505.04911 (2025)
Taguchi, S., Deguchi, H., Hamazaki, T., Sakai, H.: SpatialPrompting: Keyframe- driven Zero-Shot spatial reasoning with Off-the-Shelf Multimodal Large Language Models. arXiv preprint arXiv:2505.04911 (2025)
arXiv 2025
-
[41]
arXiv preprint arXiv:2510.07709 (2025)
Vera, A., Sanchez, K., Hinojosa, C., Hamid, H.B., Kim, D., Ghanem, B.: Mul- timodal safety evaluation in generative agent social simulations. arXiv preprint arXiv:2510.07709 (2025)
arXiv 2025
-
[42]
arXiv preprint arXiv:2504.01901 (2025)
Wang, H., Zhao, Y., Wang, T., Fan, H., Zhang, X., Zhang, Z.: Ross3d: Reconstruc- tive visual instruction tuning with 3d-awareness. arXiv preprint arXiv:2504.01901 (2025)
arXiv 2025
-
[43]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, X., Huang, Q., Celikyilmaz, A., Gao, J., Shen, D., Wang, Y.F., Wang, W.Y., Zhang, L.: Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6629–6638 (2019)
2019
-
[45]
arXiv preprint arXiv:2505.23747 (2025)
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747 (2025)
Pith/arXiv arXiv 2025
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wu, S.C., Wald, J., Tateno, K., Navab, N., Tombari, F.: Scenegraphfusion: In- cremental 3d scene graph prediction from rgb-d sequences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7515–7525 (2021) Agentic Collaborative Cognition for Zero-Shot 3D Understanding 19
2021
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xia,F.,Zamir,A.R.,He,Z.,Sax,A.,Malik,J.,Savarese,S.:Gibsonenv:Real-world perception for embodied agents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9068–9079 (2018)
2018
-
[48]
arXiv preprint arXiv:2504.08307 (2025)
Xie, Q., Liang, Z., Zeng, L.: DSM: Building a diverse semantic map for 3D visual grounding. arXiv preprint arXiv:2504.08307 (2025)
arXiv 2025
-
[49]
In: Conference on Robot Learning (CoRL) (2024)
Xu, R., Huang, Z., Wang, T., Chen, Y., Pang, J., Lin, D.: VLM-Grounder: A VLM agent for zero-shot 3D visual grounding. In: Conference on Robot Learning (CoRL) (2024)
2024
-
[50]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Yang, J., Chen, X., Qian, S., Madaan, N., Iyengar, M., Fouhey, D.F., Chai, J.: LLM-Grounder: Open-vocabulary 3D visual grounding with large language model as an agent. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 7694–7701. IEEE (2024)
2024
-
[51]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). pp. 10632–10643 (2025)
2025
-
[52]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
Yang, Y., Hayat, M., Jin, Z., Zhu, H., Lei, Y.: Zero-shot point cloud segmentation by semantic-visual aware synthesis. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 11586–11596 (2023)
2023
-
[53]
arXiv preprint arXiv:2411.14594 (2024)
Yuan, Q., Li, K., Zhang, J.: Solving zero-shot 3d visual grounding as constraint satisfaction problems. arXiv preprint arXiv:2411.14594 (2024)
arXiv 2024
-
[54]
arXiv preprint arXiv:2403.13248 (2024)
Yuan, Z., Liu, Y., Cao, Y., Sun, W., Jia, H., Chen, R., Li, Z., Lin, B., Yuan, L., He, L., et al.: Mora: Enabling generalist video generation via a multi-agent framework. arXiv preprint arXiv:2403.13248 (2024)
arXiv 2024
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yuan, Z., Peng, Y., Ren, J., Liao, Y., Han, Y., Feng, C.M., Zhao, H., Li, G., Cui, S., Li, Z.: Empowering large language models with 3d situation awareness. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19435–19445 (2025)
2025
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yuan, Z., Ren, J., Feng, C.M., Zhao, H., Cui, S., Li, Z.: Visual programming for zero-shot open-vocabulary 3D visual grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20623– 20633 (2024)
2024
-
[57]
In: European Conference on Com- puter Vision (ECCV)
Zhang, S., Huang, D., Deng, J., Tang, S., Ouyang, W., He, T., Zhang, Y.: Agent3d- zero: An agent for zero-shot 3d understanding. In: European Conference on Com- puter Vision (ECCV). pp. 186–202. Springer (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, Y., Luo, H., Lei, Y.: Towards CLIP-driven language-free 3D visual ground- ing via 2D-3D relational enhancement and consistency. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13063–13072 (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhao, L., Cai, D., Sheng, L., Xu, D.: 3DVG-Transformer: Relation modeling for visual grounding on point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2928–2937 (2021)
2021
-
[60]
arXiv preprint arXiv:2306.12156 (2023)
Zhao, X., Ding, W., An, Y., Du, Y., Yu, T., Li, M., Tang, M., Wang, J.: Fast segment anything. arXiv preprint arXiv:2306.12156 (2023)
arXiv 2023
-
[61]
Zheng, D., Huang, S., Wang, L.: Video-3d llm: Learning position-aware video repre- sentationfor3dsceneunderstanding.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition (CVPR). pp. 8995–9006 (2025)
2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhi, H., Chen, P., Li, J., Ma, S., Sun, X., Xiang, T., Lei, Y., Tan, M., Gan, C.: Lscenellm: Enhancing large 3d scene understanding using adaptive visual pref- erences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3761–3771 (2025) 20 W. Wang et al
2025
-
[63]
arXiv preprint arXiv:2506.01300 (2025)
Zhou, Y., He, Y., Su, Y., Han, S., Jang, J., Bertasius, G., Bansal, M., Yao, H.: ReAgent-V: A Reward-Driven Multi-Agent framework for video understanding. arXiv preprint arXiv:2506.01300 (2025)
arXiv 2025
-
[64]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV)
Zhu, Z., Ma, X., Chen, Y., Deng, Z., Huang, S., Li, Q.: 3d-vista: Pre-trained trans- former for 3d vision and text alignment. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV). pp. 2911–2921 (2023)
2023
-
[65]
Category
Zhu, Z., Wang, X., Li, Y., Zhang, Z., Ma, X., Chen, Y., Jia, B., Liang, W., Yu, Q., Deng, Z., et al.: Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8120–8132 (2025) Agentic Collaborat...
2025
-
[66]
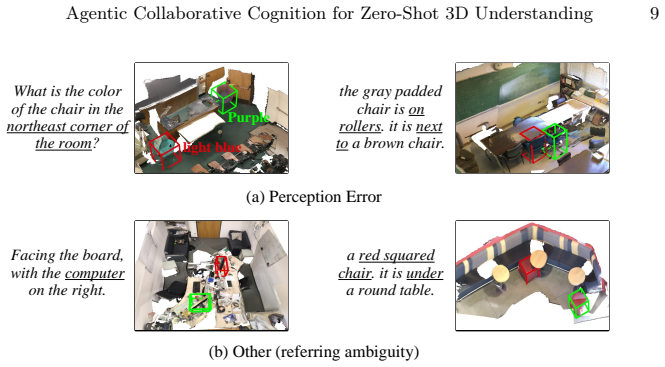
next to”), absolute relation (e.g., “northeast corner
Detection: The 3D detector fails to detect the tar- get object or predicts the incorrect category, causing subsequent processing to rely on an inaccurate set of candidate objects. 2) Planning: Errors caused by the model fails to understand 3D layout and plan infor- mative viewpoints relevant to the query. 3) Percep- tion: Error where the model fails to co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.