Toward Low-Latency Vision-Language Models with Doubly-Correct Predictions in Egocentric Visual Understanding
Pith reviewed 2026-06-25 23:45 UTC · model grok-4.3
The pith
A rationale-informed pruning method for vision-language models improves both prediction accuracy and the count of doubly-correct outputs on egocentric video tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
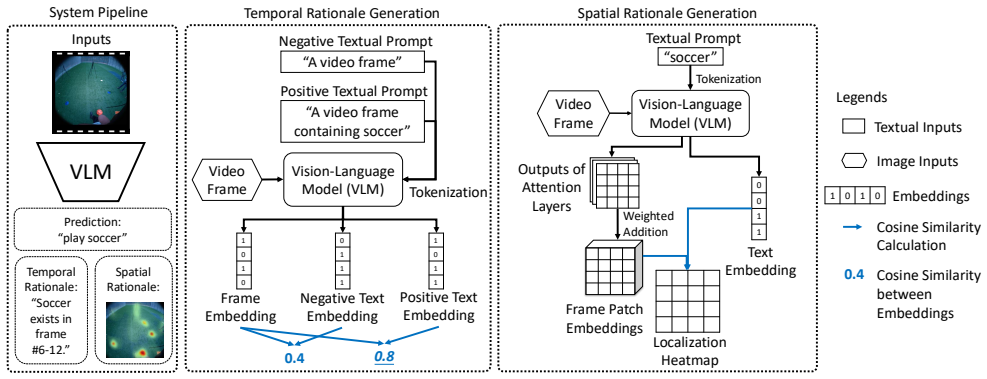
Existing pruning methods frequently preserve correct evidence localization yet reduce prediction accuracy, whereas a rationale-informed pruning strategy aligns evidence with decisions to achieve superior accuracy and more doubly-correct predictions on egocentric video benchmarks.
What carries the argument
The rationale-informed pruning strategy, which uses the model's decision rationale to guide weight removal so that evidence localization and output accuracy stay aligned.
If this is right
- Low-latency VLMs become feasible for on-board processing in interactive robotics without sacrificing evidential grounding.
- Safety in human-robot collaboration improves because predictions remain tied to observable visual evidence.
- Pruning research gains an explicit target metric that combines accuracy with evidence correctness.
- Auditability of model decisions increases when pruning respects the internal rationale used to reach each output.
Where Pith is reading between the lines
- The same rationale-guided pruning could be tested on other multimodal models where decision grounding matters for trust.
- If the alignment benefit holds, it suggests that efficiency techniques in embodied AI should be evaluated on joint accuracy-grounding metrics rather than accuracy alone.
- Future work might check whether the method reduces downstream errors in tasks that depend on both correct classification and correct localization, such as object handover.
Load-bearing premise
That using the model's rationale to select which weights to prune will consistently raise both accuracy and evidence alignment without creating new mismatches.
What would settle it
A controlled test on a new egocentric video dataset in which the proposed pruning method produces fewer doubly-correct predictions than at least one standard pruning baseline.
Figures

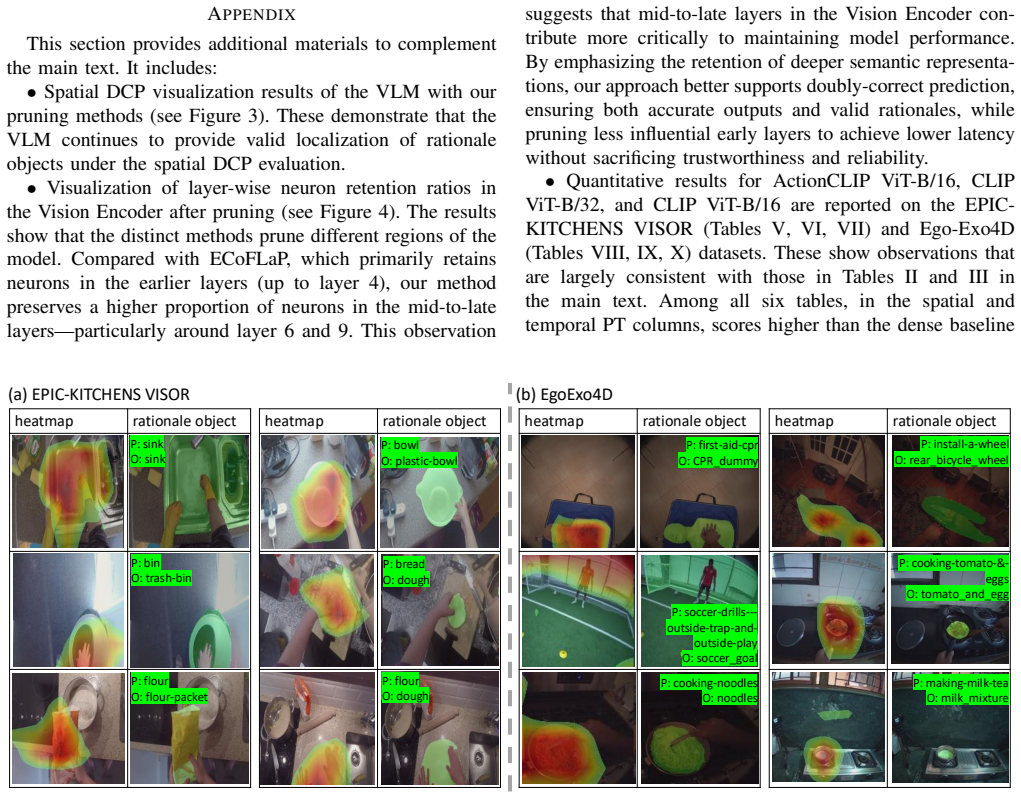
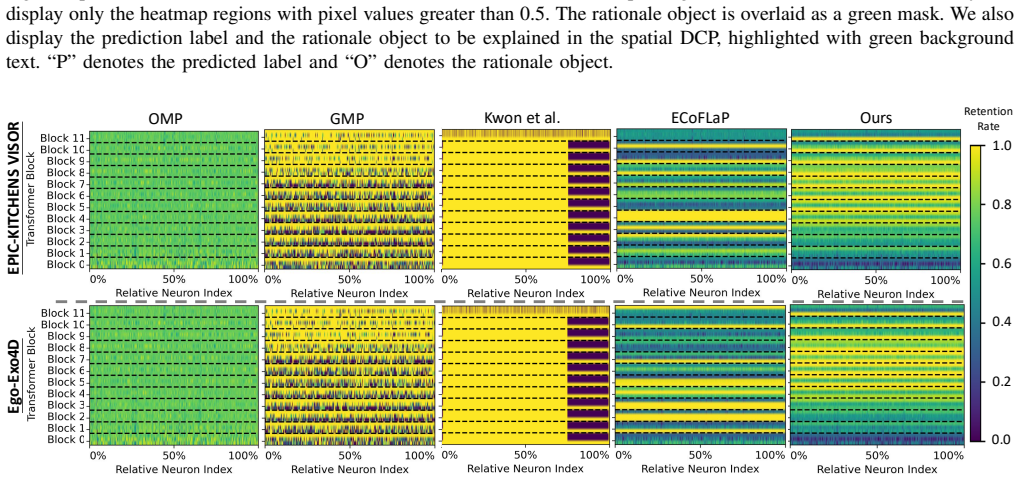
read the original abstract
The rapid rise of Vision-Language Models (VLMs) in egocentric visual understanding has made low-latency inference in human-robot collaborative (HRC) tasks increasingly critical. Weight pruning techniques developed for VLMs to shrink model size and computation can be readily applied to satisfy the efficiency demands of on-board processing and real-time interactive robotics. Moreover, safe human-robot interaction demands pruning strategies that preserve doubly-correct predictions; outputs must be both accurate and evidentially grounded to mitigate risks and ensure user trust. In this paper, we present a new study of VLM pruning through the lens of doubly-correct prediction. Our experiments surprisingly show that existing pruning methods often preserve the right evidence localization but undermine correct prediction. To address this, we propose a rationale-informed pruning strategy that better aligns evidence with decisions. Benchmark results on egocentric video datasets demonstrate that our method not only achieves the highest prediction accuracy but also outperforms existing approaches in attaining doubly-correct predictions. We aim to stimulate research on efficient and reliable VLMs, ensuring accuracy-driven advances align with the transparency, auditability, and safety required for responsible human-robot interaction and embodied intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines weight pruning for Vision-Language Models (VLMs) to enable low-latency inference in egocentric visual understanding for human-robot collaboration. It observes that standard pruning often preserves evidence localization while harming prediction accuracy, and proposes a rationale-informed pruning strategy to better align evidence with decisions. The central claim is that this method achieves the highest prediction accuracy and outperforms baselines on doubly-correct predictions (accurate and evidentially grounded outputs) when evaluated on egocentric video datasets.
Significance. If the empirical claims hold, the work could meaningfully advance pruning techniques for VLMs by prioritizing both efficiency and the alignment of evidence with predictions, which is relevant for safety-critical applications in embodied robotics and human-robot interaction.
major comments (1)
- [Abstract] Abstract: the central claim of benchmark superiority in prediction accuracy and doubly-correct predictions on egocentric video datasets is asserted without any description of methods, baselines, datasets, evaluation metrics, or quantitative results, rendering the claim impossible to evaluate or verify.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting the need for clarity in the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of benchmark superiority in prediction accuracy and doubly-correct predictions on egocentric video datasets is asserted without any description of methods, baselines, datasets, evaluation metrics, or quantitative results, rendering the claim impossible to evaluate or verify.
Authors: We acknowledge that the abstract, as written, provides only a high-level summary of the central claim without enumerating specific methods, baselines, datasets, metrics, or numerical results. This is standard for abstracts to remain concise and accessible. The full manuscript supplies all required details for evaluation: the rationale-informed pruning strategy is defined in Section 2, the egocentric video benchmarks and evaluation protocol (including doubly-correct prediction metrics) are specified in Section 3, and quantitative comparisons against prior pruning methods appear in Section 4 with tables reporting accuracy and doubly-correct rates. The claim is therefore verifiable from the complete paper rather than the abstract alone. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical study of VLM pruning for egocentric video datasets, with claims resting on benchmark comparisons of prediction accuracy and doubly-correct predictions. No equations, derivations, or self-referential constructions appear in the abstract or description; the proposed rationale-informed pruning strategy is motivated by observed empirical patterns in existing methods rather than by definition or self-citation chains. The central results are externally falsifiable via standard benchmarks and do not reduce to fitted inputs renamed as predictions or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[2]
Actionclip: A new paradigm for video action recognition,
M. Wang, J. Xing, and Y . Liu, “Actionclip: A new paradigm for video action recognition,”arXiv preprint arXiv:2109.08472, 2021
arXiv 2021
-
[3]
Internvideo: General video foundation models via generative and discriminative learning,
Y . Wang, K. Li, Y . Li, Y . He, B. Huang, Z. Zhao, H. Zhang, J. Xu, Y . Liu, Z. Wanget al., “Internvideo: General video foundation models via generative and discriminative learning,”arXiv preprint arXiv:2212.03191, 2022
Pith/arXiv arXiv 2022
-
[4]
Ego- exo4d: Understanding skilled human activity from first-and third- person perspectives,
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Booteet al., “Ego- exo4d: Understanding skilled human activity from first-and third- person perspectives,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 383–19 400
2024
-
[5]
Scaling egocentric vision: The epic-kitchens dataset,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Priceet al., “Scaling egocentric vision: The epic-kitchens dataset,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 720–736
2018
-
[6]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 995–19 012
2022
-
[7]
Egovla: Learning vision- language-action models from egocentric human videos,
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiuet al., “Egovla: Learning vision- language-action models from egocentric human videos,”arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[8]
UPop: Unified and progressive pruning for compressing vision-language transformers,
D. Shi, C. Tao, Y . Jin, Z. Yang, C. Yuan, and J. Wang, “UPop: Unified and progressive pruning for compressing vision-language transformers,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR...
2023
-
[9]
Multiflow: Shifting towards task-agnostic vision-language pruning,
M. Farina, M. Mancini, E. Cunegatti, G. Liu, G. Iacca, and E. Ricci, “Multiflow: Shifting towards task-agnostic vision-language pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 185–16 195
2024
-
[10]
Isomorphic pruning for vision models,
G. Fang, X. Ma, M. B. Mi, and X. Wang, “Isomorphic pruning for vision models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 232–250
2024
-
[11]
A fast post-training pruning framework for transform- ers,
W. Kwon, S. Kim, M. W. Mahoney, J. Hassoun, K. Keutzer, and A. Gholami, “A fast post-training pruning framework for transform- ers,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 101–24 116, 2022
2022
-
[12]
Ecoflap: Efficient coarse-to- fine layer-wise pruning for vision-language models,
Y .-L. Sung, J. Yoon, and M. Bansal, “Ecoflap: Efficient coarse-to- fine layer-wise pruning for vision-language models,” inThe Twelfth International Conference on Learning Representations
-
[13]
Doubly right object recognition: A why prompt for visual rationales,
C. Mao, R. Teotia, A. Sundar, S. Menon, J. Yang, X. Wang, and C. V ondrick, “Doubly right object recognition: A why prompt for visual rationales,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2722–2732
2023
-
[14]
Beyond accuracy: ensuring correct predictions with correct rationales,
T. Li, M. Ma, and X. Peng, “Beyond accuracy: ensuring correct predictions with correct rationales,”Advances in Neural Information Processing Systems, vol. 37, pp. 43 164–43 188, 2024
2024
-
[15]
Beyond accuracy: On the effects of fine-tuning towards vision-language model’s prediction rationality,
Q. Wang, T. Li, K. X. Nguyen, and X. Peng, “Beyond accuracy: On the effects of fine-tuning towards vision-language model’s prediction rationality,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 20, pp. 21 225–21 233, Apr. 2025. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/35421
2025
-
[16]
” why is there a tumor?
M. Ma, T. Li, Y . Peng, L. Lin, V . Beylergil, B. Zhao, O. Akin, and X. Peng, “” why is there a tumor?”: Tell me the reason, show me the evidence,” inForty-second International Conference on Machine Learning
-
[17]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone,
S. Pramanick, Y . Song, S. Nag, K. Q. Lin, H. Shah, M. Z. Shou, R. Chellappa, and P. Zhang, “Egovlpv2: Egocentric video-language pre-training with fusion in the backbone,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5285–5297
2023
-
[18]
Epic-kitchens visor benchmark: Video segmentations and object relations,
A. Darkhalil, D. Shan, B. Zhu, J. Ma, A. Kar, R. Higgins, S. Fidler, D. Fouhey, and D. Damen, “Epic-kitchens visor benchmark: Video segmentations and object relations,”Advances in Neural Information Processing Systems, vol. 35, pp. 13 745–13 758, 2022
2022
-
[19]
What made you do this? understanding black-box decisions with sufficient input subsets,
B. Carter, J. Mueller, S. Jain, and D. Gifford, “What made you do this? understanding black-box decisions with sufficient input subsets,” inThe 22nd International Conference on Artificial Intelligence and Statistics. PMLR, 2019, pp. 567–576
2019
-
[20]
Learning spatiotemporal attention for egocentric action recognition,
M. Lu, D. Liao, and Z.-N. Li, “Learning spatiotemporal attention for egocentric action recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0
2019
-
[21]
An action is worth multiple words: Handling ambiguity in action recognition,
K. Kim, D. Moltisanti, O. M. Aodha, and L. Sevilla-Lara, “An action is worth multiple words: Handling ambiguity in action recognition,” inBMVC, 2022, p. 356. [Online]. Available: https://bmvc2022.mpi-inf.mpg.de/356/
2022
-
[22]
Are nouns learned before verbs? infants provide insight into a long-standing debate,
S. Waxman, X. Fu, S. Arunachalam, E. Leddon, K. Geraghty, and H.-j. Song, “Are nouns learned before verbs? infants provide insight into a long-standing debate,”Child development perspectives, vol. 7, no. 3, pp. 155–159, 2013
2013
-
[23]
Contextualized spatio-temporal contrastive learning with self-supervision,
L. Yuan, R. Qian, Y . Cui, B. Gong, F. Schroff, M.-H. Yang, H. Adam, and T. Liu, “Contextualized spatio-temporal contrastive learning with self-supervision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 977–13 986
2022
-
[24]
Videogrounding-dino: Towards open-vocabulary spatio-temporal video grounding,
S. T. Wasim, M. Naseer, S. Khan, M.-H. Yang, and F. S. Khan, “Videogrounding-dino: Towards open-vocabulary spatio-temporal video grounding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 909–18 918
2024
-
[25]
Clevr-xai: A benchmark dataset for the ground truth evaluation of neural network explanations,
L. Arras, A. Osman, and W. Samek, “Clevr-xai: A benchmark dataset for the ground truth evaluation of neural network explanations,”Inf. Fusion, vol. 81, no. C, p. 14–40, may 2022. [Online]. Available: https://doi.org/10.1016/j.inffus.2021.11.008
-
[26]
Precise benchmarking of explainable ai attribution methods,
R. Brandt, D. Raatjens, and G. Gaydadjiev, “Precise benchmarking of explainable ai attribution methods,”arXiv preprint arXiv:2308.03161, 2023
arXiv 2023
-
[27]
Anticipating next active objects for egocentric videos,
S. K. Thakur, C. Beyan, P. Morerio, V . Murino, and A. Del Bue, “Anticipating next active objects for egocentric videos,”IEEE Access, vol. 12, pp. 61 767–61 779, 2024
2024
-
[28]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
Pith/arXiv arXiv 2015
-
[29]
Structured pruning of deep con- volutional neural networks,
S. Anwar, K. Hwang, and W. Sung, “Structured pruning of deep con- volutional neural networks,”ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 13, no. 3, pp. 1–18, 2017
2017
-
[30]
Video- llava: Learning united visual representation by alignment before pro- jection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video- llava: Learning united visual representation by alignment before pro- jection,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 5971–5984
2024
-
[31]
Videollama 3: Frontier multimodal foundation models for image and video understanding,
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y . Yuan, G. Chen, S. Leng, Y . Jiang, H. Zhang, X. Liet al., “Videollama 3: Frontier multimodal foundation models for image and video understanding,”arXiv preprint arXiv:2501.13106, 2025
Pith/arXiv arXiv 2025
-
[32]
Navila: Legged robot vision-language-action model for navigation,
A.-C. Cheng, Y . Ji, Z. Yang, X. Zou, J. Kautz, E. Biyik, H. Yin, S. Liu, and X. Wang, “Navila: Legged robot vision-language-action model for navigation,” inRSS, 2025
2025
-
[33]
Streamvln: Streaming vision-and-language navigation via slowfast context modeling,
M. Wei, C. Wan, X. Yu, T. Wang, Y . Yang, X. Mao, C. Zhu, W. Cai, H. Wang, Y . Chenet al., “Streamvln: Streaming vision-and-language navigation via slowfast context modeling,” inIEEE International Conference on Robotics and Automation, 2026
2026
-
[34]
Interpreting clip’s image representation via text-based decomposition,
Y . Gandelsman, A. A. Efros, and J. Steinhardt, “Interpreting clip’s image representation via text-based decomposition,” inThe Twelfth International Conference on Learning Representations
-
[35]
Interpreting the second-order effects of neurons in clip,
——, “Interpreting the second-order effects of neurons in clip,” inThe Thirteenth International Conference on Learning Representations
-
[36]
A simple and effective prun- ing approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective prun- ing approach for large language models,” inThe Twelfth International Conference on Learning Representations
-
[37]
Sparsegpt: Massive language models can be accurately pruned in one-shot,
E. Frantar and D. Alistarh, “Sparsegpt: Massive language models can be accurately pruned in one-shot,” inInternational conference on machine learning. PMLR, 2023, pp. 10 323–10 337
2023
-
[38]
Transformer feed- forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed- forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 5484–5495
2021
-
[39]
Second order derivatives for network pruning: Optimal brain surgeon,
B. Hassibi and D. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,” inAdvances in Neural Information Processing Systems, S. Hanson, J. Cowan, and C. Giles, Eds., vol. 5. Morgan-Kaufmann, 1992. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 1992/file/303ed4c69846ab36c2904d3ba8573050-Paper.pdf APPENDIX Thi...
arXiv 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.