Tensor-Based Batch Fuzzing with Adaptive Perturbation Scaling for Deep Neural Networks
Pith reviewed 2026-06-25 22:30 UTC · model grok-4.3
The pith
A batch fuzzing framework embeds constraints as fixed layers and derives perturbation sizes from feasible ranges to process many DNN specifications at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
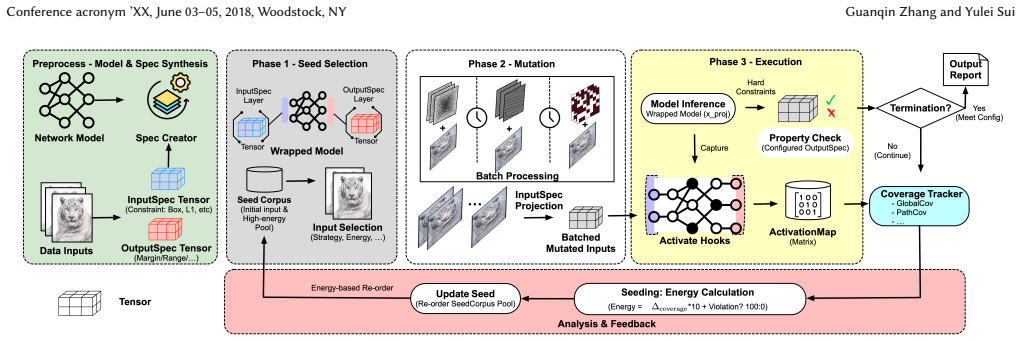
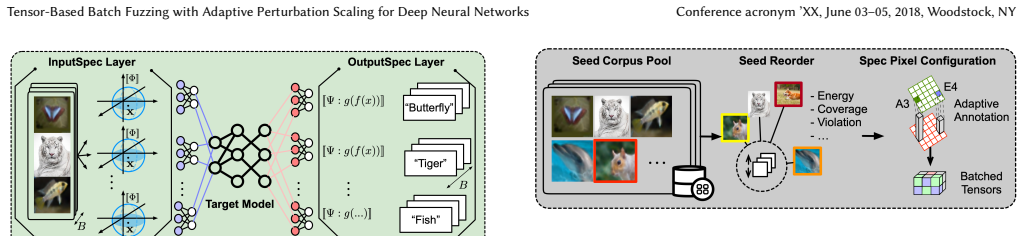
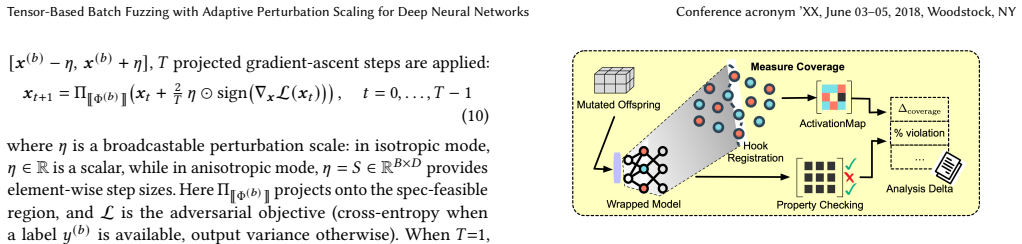
By turning each specification into a set of fixed layers that enforce bounds and check properties, the framework produces a wrapped model that accepts and processes an entire batch of B specifications in one iteration. Step sizes for input mutations are obtained by multiplying the gap between each specification's lower and upper bounds by a shared scale factor; the same factor can be used globally or converted to per-dimension values. The resulting perturbations remain consistent with the constraint geometry, enabling more effective exploration of input spaces whose features differ in magnitude.
What carries the argument
Wrapped model formed by inserting input-bound and output-property layers as non-trainable components, together with bound-gap scaling that supplies isotropic or anisotropic mutation step sizes.
If this is right
- A single model execution evaluates B specifications instead of B separate executions.
- Perturbations remain inside each specification's feasible region by construction.
- Up to 40 times more inputs can be tested in a fixed time budget.
- Up to 4 times more output-property violations are reported under the same time limit.
- Heterogeneous feature scales across specifications are handled without manual tuning of a global epsilon.
Where Pith is reading between the lines
- The same wrapping technique could be reused to batch other black-box analyses that currently run one test case at a time.
- Combining the bound-gap scaling with gradient information might further concentrate mutations on decision boundaries.
- The method's gains are likely largest when specifications differ substantially in their bound widths.
- Extending the layer-wrapping idea to recurrent or transformer models would test whether the batch advantage persists beyond feed-forward networks.
Load-bearing premise
Inserting the constraint and check layers as non-trainable components leaves the original network's input-output mapping unchanged and adds no overhead or bias that would make batch results incomparable to sequential runs.
What would settle it
A controlled experiment that runs both the sequential baseline and the batched version on the same hardware, same specifications, and same time budget and records no increase in inputs processed or violations discovered would falsify the throughput and effectiveness claims.
Figures


read the original abstract
Deep neural networks are increasingly deployed in safety-critical domains such as autonomous driving and medical diagnosis, yet their opaque, high-dimensional parameter spaces make it difficult to systematically assess model reliability on unseen inputs. Existing coverage-guided sequential fuzzing frameworks for DNNs inherit a one-input-per-iteration design from traditional software fuzzing and apply uniform perturbation budgets across all input dimensions, limiting both testing throughput (i.e., inputs processed per unit time) and the precision of input-space exploration. We present a new specification-aware batch fuzzing framework with adaptive perturbation scaling that addresses both limitations. Rather than relying on a fixed global perturbation radius epsilon, our approach derives mutation step sizes from specification-defined feasible ranges (the gap between lower and upper bounds) using a shared scale factor. This scaling can be applied either as a global scalar (isotropic) or as per-dimension step sizes (anisotropic), keeping perturbations consistent with the underlying constraint structure. As a result, the fuzzer can explore input spaces with heterogeneous feature scales more effectively across all specifications in the batch. We embed input constraints and output property checks directly into the network as non-trainable layers, yielding a wrapped model that processes B specification instances in a single batched iteration, substantially improving fuzzing efficiency and counterexample exploration. We evaluate our framework extensively on three benchmarks, covering six networks and over 400 specifications across TrafficSigns, Cifar100, and TinyImageNet. Our tensor-based fuzzing achieves up to 40X higher throughput and 4X more violations than the sequential baseline under the same time budget, demonstrating significantly improved effectiveness in specification-guided fuzzing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a tensor-based batch fuzzing framework for DNNs that derives adaptive perturbation scales from specification bounds (isotropic or anisotropic) and embeds input constraints plus output property checks as non-trainable layers to produce a wrapped model capable of processing B specifications in one batched forward pass. On three image-classification benchmarks (TrafficSigns, Cifar100, TinyImageNet) covering six networks and >400 specifications, it reports up to 40× higher throughput and 4× more violations than a sequential baseline under identical wall-clock budgets.
Significance. If the reported speedups and violation counts are shown to be attributable solely to the batching and scaling mechanisms rather than implementation artifacts, the work would meaningfully improve the scalability of specification-guided testing for safety-critical DNNs. The integration of constraints directly into the computation graph is a pragmatic engineering choice that could generalize beyond the evaluated domains.
major comments (2)
- [Evaluation] Evaluation section: the 40× throughput and 4× violation claims rest on direct wall-clock comparison to a sequential baseline, yet the manuscript supplies no experimental protocol (hardware, software stack, number of independent runs, timing instrumentation, or statistical tests). Without these, it is impossible to rule out confounds that would invalidate attribution of the gains to tensor batching.
- [Model Wrapping] Wrapped-model construction (likely §3): the central assumption that embedding constraints and property checks as non-trainable layers produces a model whose forward passes are semantically identical to the original network and incur no measurable extra latency is load-bearing for the throughput comparison. No equivalence verification (e.g., output matching on held-out inputs), floating-point consistency check, or per-component timing breakdown is reported.
minor comments (1)
- [Abstract] The abstract states quantitative gains without any accompanying protocol summary, baseline description, or caveat about potential overhead; this should be expanded for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and model-wrapping assumptions. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the 40× throughput and 4× violation claims rest on direct wall-clock comparison to a sequential baseline, yet the manuscript supplies no experimental protocol (hardware, software stack, number of independent runs, timing instrumentation, or statistical tests). Without these, it is impossible to rule out confounds that would invalidate attribution of the gains to tensor batching.
Authors: We agree that the absence of a detailed experimental protocol limits the ability to fully attribute the reported gains. In the revised manuscript we will add a dedicated 'Experimental Setup' subsection that specifies the hardware platform (GPU model, CPU, memory), software stack (framework version, CUDA/cuDNN), number of independent runs with random seeds, timing method (wall-clock via CUDA events with warm-up), and statistical analysis (mean, standard deviation, and significance tests). These additions will allow readers to assess whether the 40× throughput and 4× violation improvements are attributable to the batching and scaling mechanisms. revision: yes
-
Referee: [Model Wrapping] Wrapped-model construction (likely §3): the central assumption that embedding constraints and property checks as non-trainable layers produces a model whose forward passes are semantically identical to the original network and incur no measurable extra latency is load-bearing for the throughput comparison. No equivalence verification (e.g., output matching on held-out inputs), floating-point consistency check, or per-component timing breakdown is reported.
Authors: We acknowledge that explicit verification of semantic equivalence and latency overhead is necessary to support the throughput claims. In the revision we will include (i) output-equivalence checks on held-out inputs showing maximum absolute difference below a small threshold (e.g., 1e-6), (ii) floating-point consistency results across wrapped and original models, and (iii) a per-component timing breakdown isolating the overhead of the added constraint and property layers. These results will be presented in the Evaluation section to confirm that the observed speedups derive from batching rather than implementation differences. revision: yes
Circularity Check
No significant circularity; empirical results are direct measurements
full rationale
The paper's central claims consist of measured throughput and violation counts on benchmarks (TrafficSigns, Cifar100, TinyImageNet). No equations, fitted parameters, or derivations are shown that reduce the reported 40X/4X gains to quantities defined by the inputs themselves. The embedding of constraints as non-trainable layers is presented as an implementation technique whose overhead is assumed negligible for comparison purposes; this is an empirical assumption rather than a self-definitional or fitted-input reduction. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way for the performance results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- shared scale factor
axioms (1)
- standard math Batched tensor operations on wrapped models produce identical per-instance results to sequential execution
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al
-
[2]
InOSDI 16
{TensorFlow}: a system for {Large-Scale} machine learning. InOSDI 16. 265–283
-
[3]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. 2016. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565 (2016)
Pith/arXiv arXiv 2016
-
[4]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological)57, 1 (1995), 289–300
1995
-
[5]
Marcel Böhme, Van-Thuan Pham, and Abhik Roychoudhury. 2016. Coverage- based greybox fuzzing as markov chain. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. 1032–1043
2016
-
[6]
Mariusz Bojarski. 2016. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316(2016). doi:10.48550/arXiv.1604.07316
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1604.07316 2016
-
[7]
Fateh Boudardara, Abderraouf Boussif, Pierre-Jean Meyer, and Mohamed Ghazel
-
[8]
A Review of Abstraction Methods Toward Verifying Neural Networks. ACM Trans. Embed. Comput. Syst.23, 4 (2024), 58:1–58:19. doi:10.1145/3617508
-
[9]
Christopher Brix, Stanley Bak, Taylor T. Johnson, and Haoze Wu. 2024. The Fifth International Verification of Neural Networks Competition (VNN-COMP 2024): Summary and Results.CoRRabs/2412.19985 (2024). arXiv:2412.19985 doi:10.48550/arXiv.2412.19985
-
[10]
Christopher Brix, Mark Niklas Müller, Stanley Bak, Taylor T. Johnson, and Changliu Liu. 2023. First three years of the international verification of neural networks competition (VNN-COMP).Int. J. Softw. Tools Technol. Transf.25, 3 (2023), 329–339. doi:10.1007/s10009-023-00703-4
-
[11]
Nicholas Carlini and David A. Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. In2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017. Ieee, IEEE Computer Society, 39–57. doi:10. 1109/SP.2017.49
2017
-
[12]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. InOSDI 18. 578–594
2018
-
[13]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. routledge
2013
-
[14]
David Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit A. Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark W. Barrett, Ding Zhao, Tan Zhi- Xuan, Jeannette M. Wing, and Joshua B. Tenenbaum. 2024. Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI ...
-
[15]
Yang Feng, Qingkai Shi, Xinyu Gao, Jun Wan, Chunrong Fang, and Zhenyu Chen. 2020. Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks. InProceedings of the 29th ACM SIGSOFT international symposium on software testing and analysis. 177–188
2020
-
[16]
Chuqin Geng, Nham Le, Xiaojie Xu, Zhaoyue Wang, Arie Gurfinkel, and Xujie Si. 2023. Towards Reliable Neural Specifications. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceed- ings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato...
2023
-
[17]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In3rd Int. Conf. on Learning Representations (ICLR’15). Int. Conf. on Learning Representations, ICLR, San Diego, CA, United States, 11 pages. doi:10.48550/arXiv.1412.6572
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6572 2015
-
[18]
Google Brain Research. 2023. TensorFuzz: Coverage Guided Fuzzing for Neural Networks. https://github.com/brain-research/tensorfuzz. GitHub repository (archived), accessed: 2026-03-25
2023
-
[19]
Jianmin Guo, Yu Jiang, Yue Zhao, Quan Chen, and Jiaguang Sun. 2018. DLFuzz: differential fuzzing testing of deep learning systems. InProceedings of the 2018 ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2018, Lake Buena Vista, FL, USA, November 04-09, 2018, Gary T. ...
-
[20]
Fabrice Harel-Canada, Lingxiao Wang, Muhammad Ali Gulzar, Quanquan Gu, and Miryung Kim. 2020. Is neuron coverage a meaningful measure for testing deep neural networks?. InFSE’ 20. 851–862
2020
-
[21]
Guy Katz, Derek A Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Aleksandar Zeljić, et al
-
[22]
The marabou framework for verification and analysis of deep neural networks. InCA V’ 19. doi:10.1007/978-3-030-25540-4_26
-
[23]
Jinhan Kim, Robert Feldt, and Shin Yoo. 2019. Guiding deep learning system testing using surprise adequacy. InProceedings of the 41st International Con- ference on Software Engineering, ICSE 2019, Montreal, QC, Canada, May 25-31, 2019, Joanne M. Atlee, Tevfik Bultan, and Jon Whittle (Eds.). IEEE, IEEE / ACM, 1039–1049. doi:10.1109/ICSE.2019.00108
-
[24]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[25]
Yann Le and Xuan Yang. 2015. Tiny imagenet visual recognition challenge.CS 231N7, 7 (2015), 3
2015
-
[26]
Changliu Liu, Tomer Arnon, Christopher Lazarus, Christopher A. Strong, Clark W. Barrett, and Mykel J. Kochenderfer. 2021. Algorithms for Verifying Deep Neural Networks.Found. Trends Optim.4, 3-4 (2021), 244–404. doi:10.1561/2400000035
-
[27]
Lei Ma, Felix Juefei-Xu, Fuyuan Zhang, Jiyuan Sun, Minhui Xue, Bo Li, Chunyang Chen, Ting Su, Li Li, Yang Liu, et al. 2018. Deepgauge: Multi-granularity testing criteria for deep learning systems. InASE 18. 120–131. doi:10.1145/3238147. 3238202
-
[28]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. In6th Int. Conf. on Learning Representations (ICLR’18). Vancouver, Canada, 27 pages. doi:10.48550/arXiv.1706.06083
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.06083 2018
-
[29]
Valentin JM Manès, HyungSeok Han, Choongwoo Han, Sang Kil Cha, Manuel Egele, Edward J Schwartz, and Maverick Woo. 2019. The art, science, and engi- neering of fuzzing: A survey.IEEE Transactions on Software Engineering47, 11 (2019), 2312–2331
2019
-
[30]
Henry B Mann and Donald R Whitney. 1947. On a test of whether one of two random variables is stochastically larger than the other.The annals of mathematical statistics(1947), 50–60
1947
-
[31]
Barton P Miller, Lars Fredriksen, and Bryan So. 1990. An empirical study of the reliability of UNIX utilities.Commun. ACM33, 12 (1990), 32–44
1990
-
[32]
Pasareanu, Pavithra Prabhakar, Sanjit A
Sayan Mitra, Corina S. Pasareanu, Pavithra Prabhakar, Sanjit A. Seshia, Ravi Mangal, Yangge Li, Christopher Watson, Divya Gopinath, and Huafeng Yu. 2024. Formal Verification Techniques for Vision-Based Autonomous Systems - A Survey. InPrinciples of Verification: Cycling the Probabilistic Landscape - Essays Dedicated to Joost-Pieter Katoen on the Occasion ...
-
[33]
Andersen, and Ian J
Augustus Odena, Catherine Olsson, David G. Andersen, and Ian J. Goodfellow
-
[34]
InICML 19, Vol
TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing. InICML 19, Vol. 97. 4901–4911. http://proceedings.mlr.press/v97/odena19a.html
-
[35]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[36]
Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana. 2017. DeepXplore: Auto- mated Whitebox Testing of Deep Learning Systems. InProceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, October 28-31, 2017. ACM, 1–18. doi:10.1145/3132747.3132785
-
[37]
Amit Sabne. 2020. Xla: Compiling machine learning for peak performance. (2020)
2020
-
[38]
Gagandeep Singh, Timon Gehr, Markus Püschel, and Martin T. Vechev. 2019. An abstract domain for certifying neural networks.Proc. ACM Program. Lang.3, POPL (2019), 41:1–41:30. doi:10.1145/3290354
-
[39]
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. 2012. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural networks32 (2012), 323–332
2012
-
[40]
Youcheng Sun, Xiaowei Huang, Daniel Kroening, James Sharp, Matthew Hill, and Rob Ashmore. 2019. Structural test coverage criteria for deep neural networks. TECS18, 5s (2019), 1–23
2019
-
[41]
Youcheng Sun, Min Wu, Wenjie Ruan, Xiaowei Huang, Marta Kwiatkowska, and Daniel Kroening. 2018. Concolic testing for deep neural networks. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. 109–119
2018
-
[42]
Yuchi Tian, Kexin Pei, Suman Jana, and Baishakhi Ray. 2018. DeepTest: automated testing of deep-neural-network-driven autonomous cars. InProceedings of the 40th International Conference on Software Engineering, ICSE 2018, Gothenburg, Sweden, May 27 - June 03, 2018. ACM, 303–314. doi:10.1145/3180155.3180220
-
[43]
Naftali Tishby and Noga Zaslavsky. 2015. Deep learning and the information bottleneck principle. In2015 ieee information theory workshop (itw). Ieee, 1–5
2015
-
[44]
Xiaofei Xie, Lei Ma, Felix Juefei-Xu, Minhui Xue, Hongxu Chen, Yang Liu, Jianjun Zhao, Bo Li, Jianxiong Yin, and Simon See. 2019. Deephunter: a coverage-guided fuzz testing framework for deep neural networks. InISSTA’ 19. 146–157
2019
-
[45]
Kaidi Xu, Huan Zhang, Shiqi Wang, Yihan Wang, Suman Jana, Xue Lin, and Cho- Jui Hsieh. 2020. Fast and Complete: Enabling Complete Neural Network Verifica- tion with Rapid and Massively Parallel Incomplete Verifiers.CoRRabs/2011.13824 (2020). arXiv:2011.13824 doi:10.48550/arXiv.2011.13824
-
[46]
Tensor-Based Batch Fuzzing with Adaptive Perturbation Scaling for Deep Neural Networks
Guanqin Zhang and Yulei Sui. 2026. Artifact for “Tensor-Based Batch Fuzzing with Adaptive Perturbation Scaling for Deep Neural Networks”. doi:10.5281/ zenodo.19340748
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.