Variational Inference via Entropic Transport Descent
Pith reviewed 2026-06-25 21:44 UTC · model grok-4.3
The pith
Particle updates in variational inference can be recast as entropy-regularized optimal transport problems solved by Sinkhorn iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
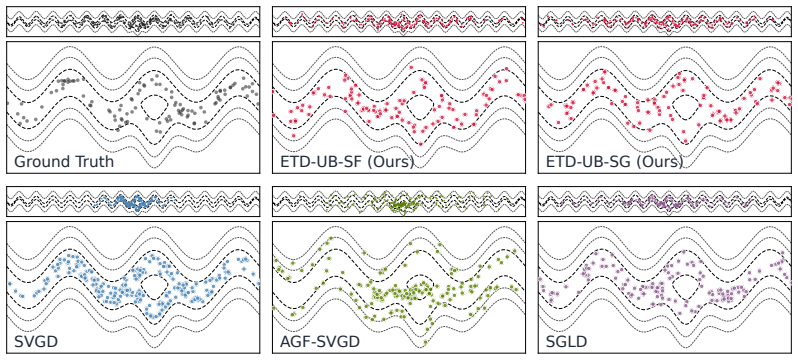
Entropic transport descent frames each particle update as an entropy-regularized optimal transport problem. The scheme is obtained by lifting the JKO proximal map to couplings and relaxing it through the KL chain rule, so that every iteration reduces to a Sinkhorn computation whose transport plan coordinates all particles simultaneously. The procedure uses only pointwise density evaluations, requires no score function, and produces updates that preserve multimodal structure by design.
What carries the argument
Lifting the JKO proximal scheme to the space of couplings followed by KL-chain-rule relaxation, which reduces each step to a Sinkhorn computation whose transport plan supplies global coordination.
If this is right
- ETD operates score-free and needs only pointwise evaluations of the unnormalized target density.
- Each iteration supplies a transport plan that coordinates the entire ensemble rather than applying local repulsion.
- The method matches or exceeds SVGD, AGF-SVGD, and SGLD on Bayesian logistic regression, neural-network posteriors, and molecular Boltzmann distributions.
- Gains are largest in high-dimensional and multimodal regimes where kernel methods suffer collapse.
Where Pith is reading between the lines
- The same lifting-plus-relaxation pattern could be applied to other proximal schemes in sampling or optimization.
- Sinkhorn cost can be traded against ensemble size by early termination or low-rank approximations of the transport plan.
- Because the update depends only on density values, ETD can be paired with black-box simulators that supply no gradients.
Load-bearing premise
The KL-chain-rule relaxation of the lifted JKO scheme produces particle moves that retain global transport structure without creating new collapse modes.
What would settle it
On a 100-dimensional mixture of 10 well-separated Gaussians, run ETD for a fixed number of iterations and measure whether any mode loses all particles or whether particle variance collapses below the level seen with SVGD.
Figures
read the original abstract
Particle-based variational inference (ParVI) methods approximate an intractable target distribution by evolving an ensemble of interacting samples. Existing approaches rely predominantly on kernel-based repulsion (e.g., SVGD), which suffers from variance collapse in high dimensions and mode collapse on multimodal targets -- pathologies caused by the absence of global transport structure. We introduce entropic transport descent (ETD), a ParVI family that frames each particle update as an entropy-regularized optimal transport problem. Derived from the JKO proximal scheme by lifting to the space of couplings and relaxing via the KL chain rule, each ETD iteration reduces to a Sinkhorn computation. The resulting transport plan provides global coordination, guiding each particle to nearby high-density proposals and naturally preserving multimodal structure. ETD can operate entirely score-free, requiring only pointwise evaluations of the unnormalized target density. Experiments on variance-collapse diagnostics, Bayesian logistic regression, neural networks, and molecular Boltzmann distributions show that ETD matches or outperforms SVGD, AGF-SVGD, and SGLD, with the largest gains in high-dimensional and multimodal settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Entropic Transport Descent (ETD) for particle-based variational inference. It derives the method by lifting the JKO proximal scheme to the space of couplings and relaxing via the KL chain rule to obtain a Sinkhorn update that supplies global transport structure. This is claimed to mitigate variance collapse in high dimensions and mode collapse on multimodal targets while remaining score-free (requiring only unnormalized density evaluations). Experiments on variance-collapse diagnostics, Bayesian logistic regression, neural networks, and molecular Boltzmann distributions report that ETD matches or outperforms SVGD, AGF-SVGD, and SGLD, with largest gains in high-dimensional and multimodal regimes.
Significance. If the central derivation holds and the reported gains are reproducible, ETD would constitute a useful addition to the ParVI literature by replacing kernel repulsion with an entropic OT mechanism that coordinates particles globally. The score-free property and the explicit connection to the JKO scheme are strengths that could be leveraged in future work on transport-based inference.
major comments (3)
- [Derivation (abstract and main derivation section)] The lifting of the JKO scheme to couplings followed by relaxation via the KL chain rule is presented as yielding a valid proximal step that preserves global transport without new collapse modes, but no error analysis or bound on the approximation error introduced by the chain-rule relaxation is supplied. This step is load-bearing for the claim that the resulting dynamics retain the multimodal fidelity of the original proximal map.
- [Experiments section] The experimental claims of outperformance rest on reported results without error bars, ablation studies on the Sinkhorn regularization parameter, or verification that gains are not attributable to implementation details of the baselines. This undermines assessment of the central empirical claim that ETD supplies superior global coordination.
- [Theoretical properties / derivation] No explicit verification is given that the relaxed Sinkhorn map remains a valid proximal operator in the original Wasserstein geometry; the skeptic's concern that the chain-rule step may lose the very coordination properties asserted to outperform kernel methods is therefore unaddressed.
minor comments (1)
- [Abstract] The abstract refers to 'variance-collapse diagnostics' without defining them or pointing to the corresponding experimental subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Derivation (abstract and main derivation section)] The lifting of the JKO scheme to couplings followed by relaxation via the KL chain rule is presented as yielding a valid proximal step that preserves global transport without new collapse modes, but no error analysis or bound on the approximation error introduced by the chain-rule relaxation is supplied. This step is load-bearing for the claim that the resulting dynamics retain the multimodal fidelity of the original proximal map.
Authors: We agree that an explicit error bound on the KL chain-rule relaxation is missing and would strengthen the theoretical foundation. The derivation establishes that the relaxation produces a tractable global transport update, but without quantitative control on the approximation it is difficult to rigorously claim preservation of multimodal fidelity. In revision we will add a dedicated subsection deriving an error bound in terms of the regularization parameter and the number of Sinkhorn iterations, showing that the deviation from the exact proximal map vanishes in the appropriate limit. revision: yes
-
Referee: [Experiments section] The experimental claims of outperformance rest on reported results without error bars, ablation studies on the Sinkhorn regularization parameter, or verification that gains are not attributable to implementation details of the baselines. This undermines assessment of the central empirical claim that ETD supplies superior global coordination.
Authors: We accept that the current experimental presentation lacks error bars, ablations on the regularization parameter, and matched baseline implementations. These omissions weaken the empirical support for superior global coordination. The revised manuscript will include results averaged over multiple random seeds with standard deviations, an ablation study sweeping the Sinkhorn regularization parameter, and re-implemented baselines under identical particle counts, optimizer settings, and computational budgets to isolate the contribution of the entropic transport mechanism. revision: yes
-
Referee: [Theoretical properties / derivation] No explicit verification is given that the relaxed Sinkhorn map remains a valid proximal operator in the original Wasserstein geometry; the skeptic's concern that the chain-rule step may lose the very coordination properties asserted to outperform kernel methods is therefore unaddressed.
Authors: This is a substantive concern. While the paper motivates the Sinkhorn map as an entropic relaxation of the lifted JKO step, it does not supply a proof that the resulting operator remains a proximal map with respect to the original Wasserstein metric. We will add a clarifying remark and short appendix discussion that (i) states the precise sense in which the map approximates the proximal operator and (ii) identifies conditions under which the global coordination properties are retained. A complete verification may require additional technical work and will be noted as future research if it cannot be completed within the revision. revision: partial
Circularity Check
No significant circularity; derivation anchored in established JKO scheme and KL chain rule from prior literature
full rationale
The paper's central derivation lifts the JKO proximal scheme to couplings then relaxes via the KL chain rule to obtain a Sinkhorn update. These steps are presented as following from standard prior results (JKO scheme and KL chain rule), with no equations shown reducing by construction to author-defined quantities, no fitted parameters renamed as predictions, and no load-bearing self-citations whose content is unverified within the paper. Experiments compare against external baselines (SVGD, SGLD) on independent tasks, confirming the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math JKO proximal scheme defines the correct Wasserstein gradient flow discretization for the target functional
- domain assumption KL chain rule relaxation on the space of couplings yields a valid entropy-regularized transport problem whose solution coordinates particles globally
Reference graph
Works this paper leans on
-
[1]
and Kucukelbir, Alp and McAuliffe, Jon D
Blei, David M. and Kucukelbir, Alp and McAuliffe, Jon D. , journal=. Variational Inference:. 2017 , publisher=
2017
-
[2]
The Variational Formulation of the
Jordan, Richard and Kinderlehrer, David and Otto, Felix , journal=. The Variational Formulation of the. 1998 , publisher=
1998
-
[3]
Stochastic differential equations:
Stochastic differential equations , author=. Stochastic differential equations:. 2003 , publisher=
2003
-
[4]
Advances in Neural Information Processing Systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
An Introduction to Sequential
Chopin, Nicolas and Papaspiliopoulos, Omiros , volume=. An Introduction to Sequential. 2020 , publisher=
2020
-
[6]
arXiv preprint arXiv:2605.02147 , year=
Sampling-Based Control via Entropy-Regularized Optimal Transport , author=. arXiv preprint arXiv:2605.02147 , year=
-
[7]
, journal=
Williams, Grady and Aldrich, Andrew and Theodorou, Evangelos A. , journal=. Model predictive path integral control:. 2017 , publisher=
2017
-
[8]
Computational Optimal Transport:
Peyr. Computational Optimal Transport:. 2019 , publisher=
2019
-
[9]
International Conference on Machine Learning , pages=
Variational Inference with Normalizing Flows , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[10]
Message Passing
Zhuo, Jingwei and Liu, Chang and Shi, Jiaxin and Zhu, Jun and Chen, Ning and Zhang, Bo , booktitle=. Message Passing. 2018 , organization=
2018
-
[11]
Annealed
D'. Annealed. Advances in Approximate Bayesian Inference , year=
-
[12]
Bayesian Learning via Stochastic Gradient
Welling, Max and Teh, Yee Whye , booktitle=. Bayesian Learning via Stochastic Gradient
-
[13]
Journal on Scientific Computing , volume=
Stabilized Sparse Scaling Algorithms for Entropy Regularized Transport Problems , author=. Journal on Scientific Computing , volume=. 2019 , publisher=
2019
-
[14]
Reviews of Modern Physics , volume=
Bayesian inference in physics , author=. Reviews of Modern Physics , volume=. 2011 , publisher=
2011
-
[15]
Advances in Neural Information Processing Systems , volume=
Variational Diffusion Models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
1995 , publisher=
Bayesian data analysis , author=. 1995 , publisher=
1995
-
[17]
arXiv preprint arXiv:2402.06121 , year=
Iterated denoising energy matching for sampling from boltzmann densities , author=. arXiv preprint arXiv:2402.06121 , year=
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Qiang Liu and Dilin Wang , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[19]
International Conference on Machine Learning (ICML) , year =
Chang Liu and Jingwei Zhuo and Pengyu Cheng and Ruiyi Zhang and Jun Zhu , title =. International Conference on Machine Learning (ICML) , year =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Sinho Chewi and Thibaut. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2020 , note =
2020
-
[21]
International Conference on Learning Representations (ICLR) , year =
Lingxiao Li and Qiang Liu and Anna Korba and Mikhail Yurochkin and Justin Solomon , title =. International Conference on Learning Representations (ICLR) , year =
-
[22]
Bertozzi , title =
Katy Craig and Andrea L. Bertozzi , title =. Mathematics of Computation , volume =. 2016 , note =
2016
-
[23]
A Blob Method for Diffusion , journal =
Jos. A Blob Method for Diffusion , journal =. 2019 , note =
2019
-
[24]
Mathematics of Computation , year =
Katy Craig and Karthik Elamvazhuthi and Matt Haberland and Olga Turanova , title =. Mathematics of Computation , year =
-
[25]
Wasserstein Variational Gradient Descent , journal =
Luca Ambrogioni and Umut G. Wasserstein Variational Gradient Descent , journal =
-
[26]
International Joint Conference on Artificial Intelligence (IJCAI) , year =
Jiaqi Zhang and Yang Li and Cheng Du and Qiang Qian , title =. International Joint Conference on Artificial Intelligence (IJCAI) , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Petr Mokrov and Alexander Korotin and Lingxiao Li and Aude Genevay and Justin Solomon and Evgeny Burnaev , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2021 , note =
2021
-
[28]
Optimizing Functionals on the Space of Probabilities with Input Convex Neural Networks , journal =
David. Optimizing Functionals on the Space of Probabilities with Input Convex Neural Networks , journal =. 2022 , note =
2022
-
[29]
International Conference on Machine Learning (ICML) , year =
Jiaojiao Fan and Shu Zhang and Amirhossein Taghvaei and Yongxin Chen , title =. International Conference on Machine Learning (ICML) , year =
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Sangyun Xu and Xingcheng Cheng and Peixi Xie , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2023 , note =
2023
-
[31]
International Conference on Machine Learning (ICML) , year =
Charlotte Bunne and Laetitia Meng-Papaxanthos and Andreas Krause and Marco Cuturi , title =. International Conference on Machine Learning (ICML) , year =
-
[32]
Entropic Approximation of
Gabriel Peyr. Entropic Approximation of. SIAM Journal on Imaging Sciences , volume =
-
[33]
Convergence of Entropic Schemes for Optimal Transport and Gradient Flows , journal =
Guillaume Carlier and Vincent Duval and Gabriel Peyr. Convergence of Entropic Schemes for Optimal Transport and Gradient Flows , journal =
-
[34]
arXiv preprint arXiv:2502.12666 , year =
Anastasiia Hraivoronska and others , title =. arXiv preprint arXiv:2502.12666 , year =
-
[35]
arXiv preprint arXiv:2406.10823 , year =
Medha Agarwal and Zaid Harchaoui and Garrett Mulcahy and Soumik Pal , title =. arXiv preprint arXiv:2406.10823 , year =
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Adil Salim and Anna Korba and Giulia Luise , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[37]
arXiv preprint arXiv:1905.09863 , year =
Yulong Lu and Jianfeng Lu and James Nolen , title =. arXiv preprint arXiv:1905.09863 , year =
Pith/arXiv arXiv 1905
-
[38]
Variational Inference via
Marc Lambert and Sinho Chewi and Francis Bach and Silv. Variational Inference via. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , note =
2022
-
[39]
Interpolating between Optimal Transport and
Jean Feydy and Thibault S. Interpolating between Optimal Transport and. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[40]
Learning Generative Models with
Aude Genevay and Gabriel Peyr. Learning Generative Models with. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[41]
Sample Complexity of
Aude Genevay and L. Sample Complexity of. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[42]
Scaling Algorithms for Unbalanced Transport Problems , journal =
L. Scaling Algorithms for Unbalanced Transport Problems , journal =. 2018 , note =
2018
-
[43]
Sinkhorn Divergences for Unbalanced Optimal Transport , journal =
Thibault S. Sinkhorn Divergences for Unbalanced Optimal Transport , journal =
-
[44]
Unbalanced Optimal Transport, from Theory to Numerics , journal =
Thibault S. Unbalanced Optimal Transport, from Theory to Numerics , journal =. 2023 , note =
2023
-
[45]
A Gradient Descent Perspective on
Flavien L. A Gradient Descent Perspective on. Applied Mathematics & Optimization , volume =. 2021 , note =
2021
-
[46]
arXiv preprint arXiv:2307.16421 , year =
Nabarun Deb and Young-Heon Kim and Soumik Pal and Geoffrey Schiebinger , title =. arXiv preprint arXiv:2307.16421 , year =
-
[47]
Computational Optimal Transport , journal =
Gabriel Peyr. Computational Optimal Transport , journal =. 2019 , note =
2019
-
[48]
Bayesian Inference with Optimal Maps , journal =
Tarek A. Bayesian Inference with Optimal Maps , journal =. 2012 , note =
2012
-
[49]
Journal of Machine Learning Research , volume =
Alessio Spantini and Daniele Bigoni and Youssef Marzouk , title =. Journal of Machine Learning Research , volume =. 2018 , note =
2018
-
[50]
Yaron Lipman and Ricky T. Q. Chen and Heli Ben-Hamu and Maximilian Nickel and Matthew Le , title =. International Conference on Learning Representations (ICLR) , year =
-
[51]
Transactions on Machine Learning Research (TMLR) , year =
Alexander Tong and Nikolay Malkin and Kilian Fatras and Lazar Atanackovic and Yanlei Zhang and Guillaume Huguet and Guy Wolf and Yoshua Bengio , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[52]
International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
Alexander Tong and others , title =. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[53]
Diffusion
Valentin. Diffusion. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2021 , note =
2021
-
[54]
Diffusion
Yuyang Shi and Valentin. Diffusion. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2023 , note =
2023
-
[55]
Transport Meets Variational Inference: Controlled
Francisco Vargas and Shreyas Padhy and Denis Blessing and Nikolas N. Transport Meets Variational Inference: Controlled. International Conference on Learning Representations (ICLR) , year =
-
[56]
Parno and Youssef M
Matthew D. Parno and Youssef M. Marzouk , title =. SIAM/ASA Journal on Uncertainty Quantification , volume =. 2018 , note =
2018
-
[57]
arXiv preprint arXiv:2302.07227 , year =
Yian Zhang and Youssef Marzouk and Konstantinos Spiliopoulos , title =. arXiv preprint arXiv:2302.07227 , year =
-
[58]
Hoffman and Pavel Sountsov and Joshua V
Matthew D. Hoffman and Pavel Sountsov and Joshua V. Dillon and Ian Langmore and Dustin Tran and Srinivas Vasudevan , title =. arXiv preprint arXiv:1903.03704 , year =
Pith/arXiv arXiv 1903
-
[59]
Stuart , title =
Alfredo Garbuno-Inigo and Franca Hoffmann and Wuchen Li and Andrew M. Stuart , title =. SIAM Journal on Applied Dynamical Systems , volume =. 2020 , note =
2020
-
[60]
Affine Invariant Interacting
Alfredo Garbuno-Inigo and Nikolas N. Affine Invariant Interacting. SIAM Journal on Applied Dynamical Systems , volume =. 2020 , note =
2020
-
[61]
Stuart , title =
Claudia Schillings and Andrew M. Stuart , title =. SIAM Journal on Numerical Analysis , volume =. 2017 , note =
2017
-
[62]
Natural Evolution Strategies , journal =
Daan Wierstra and Tom Schaul and Tobias Glasmachers and Yi Sun and Jan Peters and J. Natural Evolution Strategies , journal =. 2014 , note =
2014
-
[63]
Journal of Machine Learning Research , volume =
Yann Ollivier and Ludovic Arnold and Anne Auger and Nikolaus Hansen , title =. Journal of Machine Learning Research , volume =. 2017 , note =
2017
-
[64]
Conference on Uncertainty in Artificial Intelligence (UAI) , year =
Cornelius Braun and Robert Tobias Lange and Marc Toussaint , title =. Conference on Uncertainty in Artificial Intelligence (UAI) , year =
-
[65]
Dalalyan , title =
Arnak S. Dalalyan , title =. Conference on Learning Theory (COLT) , year =
-
[66]
Journal of the Royal Statistical Society: Series B , volume =
Mark Girolami and Ben Calderhead , title =. Journal of the Royal Statistical Society: Series B , volume =. 2011 , note =
2011
-
[67]
Mirror and Preconditioned Gradient Descent in
Cl\'. Mirror and Preconditioned Gradient Descent in. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[68]
arXiv preprint arXiv:2511.14278 , year=
Gradient Flows of Potential Energies in the Geometry of Sinkhorn Divergences , author=. arXiv preprint arXiv:2511.14278 , year=
-
[69]
International Conference on Machine Learning , pages=
Stein variational gradient descent without gradient , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[70]
International conference on machine learning , pages=
Equivariant flows: exact likelihood generative learning for symmetric densities , author=. International conference on machine learning , pages=. 2020 , organization=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.