Omni-Perception Policy Optimization for Multimodal Emotion Reasoning
Pith reviewed 2026-06-25 21:29 UTC · model grok-4.3
The pith
OPPO applies reinforcement learning to optimize multimodal perception and reduce hallucinations in emotion reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
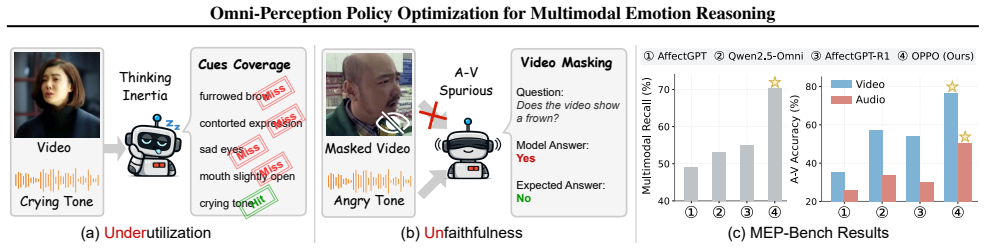
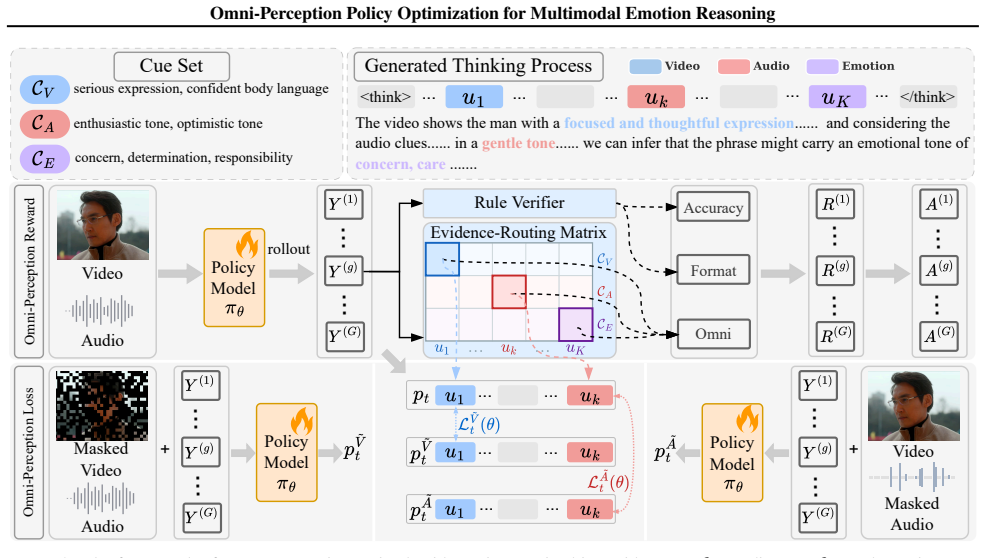
The central claim is that an Omni-Perception Reward that decomposes ground-truth into fine-grained modality cues, combined with an Omni-Perception Loss that penalizes only modality-specific evidence tokens under masked inputs, produces models that both utilize multimodal information more fully and generate fewer unfaithful statements during emotion reasoning.
What carries the argument
Omni-Perception Reward (decomposes ground-truth into visual, acoustic, and emotion cues) paired with modality-specific KL penalty in the loss function (suppresses cross-modal hallucination on masked inputs).
If this is right
- Models reach state-of-the-art accuracy on MER-UniBench and MME-Emotion benchmarks.
- Utilization of multimodal cues and faithfulness of generated statements both rise measurably on MEP-Bench.
- Explicit perception optimization becomes a practical lever for reliable multimodal emotion reasoning.
- The introduced MEP-Bench serves as a diagnostic tool to track perception sufficiency and faithfulness separately.
Where Pith is reading between the lines
- The same reward-plus-masked-penalty structure could be tested on non-emotion multimodal reasoning tasks such as visual question answering or video captioning.
- If the approach scales, perception optimization might become a standard stage before fine-tuning on downstream multimodal tasks.
- MEP-Bench style diagnostics could be applied to existing open models to measure how widespread the underutilization and hallucination problems are.
- The framework assumes the ground-truth reasoning already contains cleanly separable modality cues; any ambiguity in that decomposition would limit the method's reliability.
Load-bearing premise
The reward decomposition and the targeted KL penalty correctly isolate and improve perception quality without adding new biases or overfitting to the chosen benchmarks.
What would settle it
A model trained with OPPO that shows no gains in utilization or faithfulness scores on MEP-Bench, or that continues to produce modality-specific hallucinations at the same rate as the baseline.
Figures
read the original abstract
We find that current emotion-oriented Omni-MLLMs still lack reliable omni-modal perception: they (i) underutilize multimodal cues in their reasoning trajectories and (ii) exhibit unfaithful behavior, often hallucinating modality-specific statements from other modalities. Building on these insights, we propose OPPO (Omni-Perception Policy Optimization), a reinforcement learning framework that explicitly optimizes multimodal perception. First, an Omni-Perception Reward decomposes ground-truth reasoning into fine-grained visual, acoustic, and emotion cues and rewards trajectories that semantically recover these cues. Second, an Omni-Perception Loss compares the policy under full and unimodally masked inputs, applying a KL penalty only to modality-specific evidence tokens to suppress cross-modal hallucination. We further introduce MEP-Bench, a diagnostic benchmark that quantifies utilization and faithfulness. Experiments show that OPPO achieves state-of-the-art performance on MER-UniBench and MME-Emotion, while substantially improving utilization and faithfulness scores on MEP-Bench, highlighting the importance of sufficient and faithful omni perception for multimodal emotion reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies that current emotion-oriented Omni-MLLMs underutilize multimodal cues and exhibit cross-modal hallucinations in reasoning. It proposes OPPO, a reinforcement learning framework consisting of an Omni-Perception Reward that decomposes ground-truth trajectories into fine-grained visual, acoustic, and emotion cues, and an Omni-Perception Loss that applies a modality-specific KL penalty on evidence tokens under full versus masked inputs. The authors introduce MEP-Bench to quantify utilization and faithfulness, and report that OPPO achieves SOTA results on MER-UniBench and MME-Emotion while substantially improving scores on MEP-Bench.
Significance. If the performance gains prove robust and independent of benchmark construction, the work would provide a concrete mechanism for improving perception quality in multimodal emotion models, along with a diagnostic benchmark that could see wider adoption. The explicit decomposition of perception into modality-specific cues and the targeted KL penalty represent a focused contribution over generic RLHF approaches.
major comments (2)
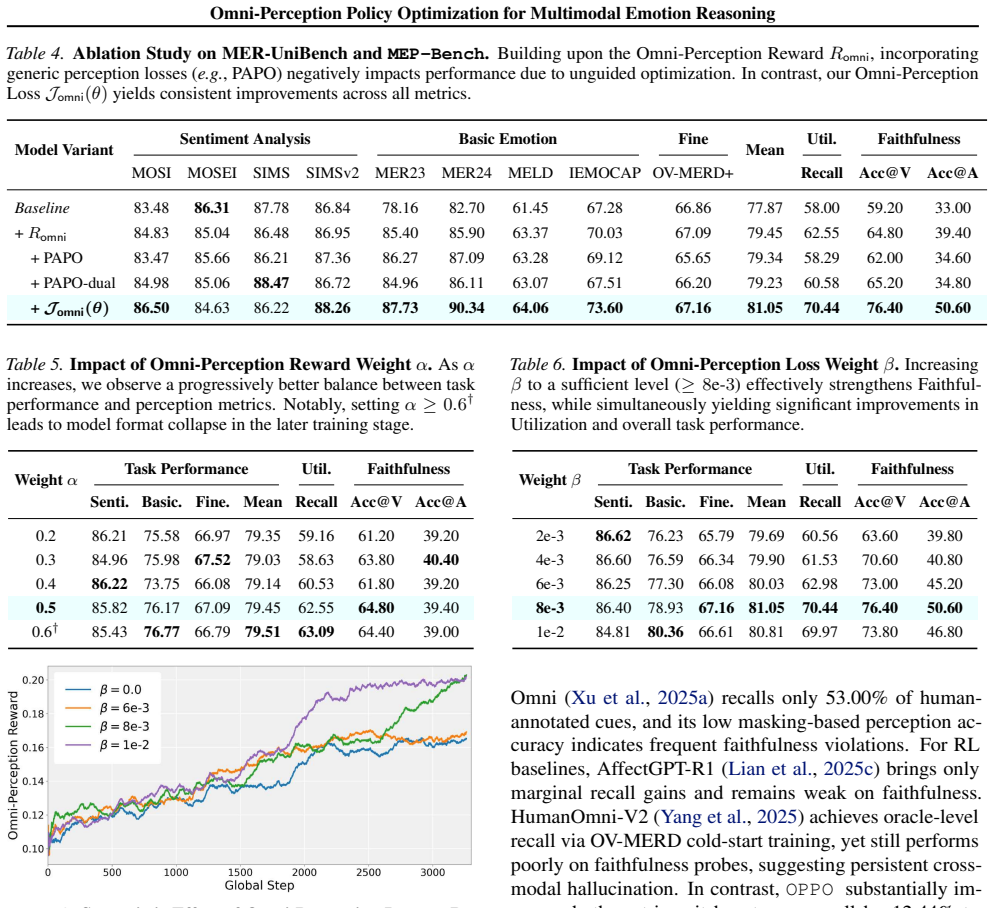
- [MEP-Bench definition and experimental results] The central claim of 'substantially improving utilization and faithfulness scores on MEP-Bench' is load-bearing, yet MEP-Bench is introduced by the same authors to measure precisely the quantities optimized by the Omni-Perception Reward and Loss. Without an independent construction protocol or external validation set, the reported gains risk circularity; the manuscript must demonstrate that benchmark items and scoring rules were fixed prior to method development and are not post-hoc tuned to OPPO trajectories.
- [Omni-Perception Loss formulation] The Omni-Perception Loss applies a KL penalty only to modality-specific evidence tokens under unimodal masking. The exact token identification procedure, the mathematical form of the penalty (including any temperature or weighting hyperparameters), and ablations showing that this selective penalty does not simply suppress all non-visual tokens or introduce new modality biases are required; these details are load-bearing for the claim that the loss 'suppresses cross-modal hallucination' without side effects.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [MEP-Bench definition and experimental results] The central claim of 'substantially improving utilization and faithfulness scores on MEP-Bench' is load-bearing, yet MEP-Bench is introduced by the same authors to measure precisely the quantities optimized by the Omni-Perception Reward and Loss. Without an independent construction protocol or external validation set, the reported gains risk circularity; the manuscript must demonstrate that benchmark items and scoring rules were fixed prior to method development and are not post-hoc tuned to OPPO trajectories.
Authors: We agree that demonstrating independence between benchmark construction and method development is essential to address potential circularity. In the revised manuscript we will add a dedicated subsection detailing the MEP-Bench construction timeline, item selection criteria, scoring rubric, and inter-annotator validation protocol, explicitly stating that these elements were finalized before OPPO training began. We will also report any external validation steps performed (e.g., correlation with existing emotion benchmarks) to further substantiate that the benchmark was not tuned post-hoc to OPPO trajectories. revision: yes
-
Referee: [Omni-Perception Loss formulation] The Omni-Perception Loss applies a KL penalty only to modality-specific evidence tokens under unimodal masking. The exact token identification procedure, the mathematical form of the penalty (including any temperature or weighting hyperparameters), and ablations showing that this selective penalty does not simply suppress all non-visual tokens or introduce new modality biases are required; these details are load-bearing for the claim that the loss 'suppresses cross-modal hallucination' without side effects.
Authors: We acknowledge that the current manuscript lacks sufficient implementation detail on the loss. In revision we will expand the methodology section to include: (i) the exact algorithm and criteria used to identify modality-specific evidence tokens, (ii) the complete mathematical expression of the Omni-Perception Loss with all hyperparameters (temperature, weighting coefficients, etc.), and (iii) new ablation experiments that measure the loss's effect on visual versus non-visual tokens and across modalities to rule out unintended suppression or bias. These additions will directly support the claim that the penalty targets cross-modal hallucination without the side effects noted. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe OPPO's reward decomposition and loss, plus introduction of MEP-Bench to measure utilization/faithfulness, with SOTA claims on the independent external benchmarks MER-UniBench and MME-Emotion. No equations, self-citations, or derivation steps are supplied that reduce any claimed result to its own inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop, no load-bearing self-citation chain). The central performance claims on external benchmarks remain independent of the new benchmark's construction, so the derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ground-truth reasoning trajectories can be reliably decomposed into modality-specific cues that serve as an objective reward signal.
- domain assumption KL divergence applied only to modality-specific tokens under masked inputs suppresses hallucination without harming overall performance.
invented entities (1)
-
MEP-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Fourteenth International Conference on Learning Representations , year=
Real-Time Motion-Controllable Autoregressive Video Diffusion , author=. The Fourteenth International Conference on Learning Representations , year=
-
[2]
Wang, Ruoyu and Li, Ziyu and Zhu, Beier and Yuan, Liangyu and Zhang, Hanwang and Yang, Xun and Chang, Xiaojun and Zhang, Chi , journal=. 2026 , volume=. doi:10.1109/TPAMI.2026.3692227 , url =
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Zhao, Kesen and Zhu, Beier and Sun, Qianru and Zhang, Hanwang , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[4]
Proceedings of the ACM Web Conference 2026 , pages=
From Social Media to Psychological Scale: An Adaptive Framework with Two-Hop Retrieval for Depression Screening , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[5]
arXiv preprint arXiv:2508.10848 , year=
Psyche-r1: Towards reliable psychological llms through unified empathy, expertise, and reasoning , author=. arXiv preprint arXiv:2508.10848 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Affordbot: 3d fine-grained embodied reasoning via multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Augrefer: Advancing 3d visual grounding via cross-modal augmentation and spatial relation-based referring , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Stimuli-Aware Emotion Adaptor for Enhancing LLM in Affective Explanation Captioning , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[9]
Emotional Video Captioning With Vision-Based Emotion Interpretation Network , year=
Song, Peipei and Guo, Dan and Yang, Xun and Tang, Shengeng and Wang, Meng , journal=. Emotional Video Captioning With Vision-Based Emotion Interpretation Network , year=
-
[10]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Multi-round Mutual Emotion-Cause Pair Extraction for Emotion-Attributed Video Captioning , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[11]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[12]
ICLR , year=
Mme-emotion: A holistic evaluation benchmark for emotional intelligence in multimodal large language models , author=. ICLR , year=
-
[13]
arXiv preprint arXiv:2601.03267 , year=
OpenAI GPT-5 System Card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[14]
5-omni technical report , author=
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
-
[15]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[16]
ArXiv , year=
Qwen2.5 Technical Report , author=. ArXiv , year=
-
[17]
arXiv preprint arXiv:2509.17765 , year=
Qwen3-Omni Technical Report , author=. arXiv preprint arXiv:2509.17765 , year=
-
[18]
2000 , publisher=
Affective computing , author=. 2000 , publisher=
2000
-
[19]
arXiv preprint arXiv:2509.24322 , year=
Multimodal large language models meet multimodal emotion recognition and reasoning: A survey , author=. arXiv preprint arXiv:2509.24322 , year=
-
[20]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[21]
arXiv preprint arXiv:2506.21277 , year=
HumanOmniV2: From Understanding to Omni-Modal Reasoning with Context , author=. arXiv preprint arXiv:2506.21277 , year=
-
[22]
arXiv preprint arXiv:2508.01318 , year=
AffectGPT-R1: Leveraging Reinforcement Learning for Open-Vocabulary Multimodal Emotion Recognition , author=. arXiv preprint arXiv:2508.01318 , year=
-
[23]
ACM MM , year=
Benchmarking and bridging emotion conflicts for multimodal emotion reasoning , author=. ACM MM , year=
-
[24]
EMNLP , year=
Evaluating object hallucination in large vision-language models , author=. EMNLP , year=
-
[25]
arXiv preprint arXiv:2410.12787 , year=
The curse of multi-modalities: Evaluating hallucinations of large multimodal models across language, visual, and audio , author=. arXiv preprint arXiv:2410.12787 , year=
-
[26]
AAAI , year=
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Confusion? , author=. AAAI , year=
-
[27]
NeurIPS , year=
Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning , author=. NeurIPS , year=
-
[28]
arXiv preprint arXiv:2411.10442 , year=
Enhancing the reasoning ability of multimodal large language models via mixed preference optimization , author=. arXiv preprint arXiv:2411.10442 , year=
-
[29]
ICLR2025 , year=
Mask-dpo: Generalizable fine-grained factuality alignment of llms , author=. ICLR2025 , year=
-
[30]
ICLR , year=
Perception-aware policy optimization for multimodal reasoning , author=. ICLR , year=
-
[31]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[32]
arXiv preprint arXiv:2503.07365 , year=
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2503.07365 , year=
-
[33]
ICCV , year=
Visual-RFT: Visual Reinforcement Fine-Tuning , author=. ICCV , year=
-
[34]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[35]
ACM MM , year=
Mer 2025: When affective computing meets large language models , author=. ACM MM , year=
2025
-
[36]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[37]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Meld: A multimodal multi-party dataset for emotion recognition in conversations , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[38]
Language resources and evaluation , volume=
IEMOCAP: Interactive emotional dyadic motion capture database , author=. Language resources and evaluation , volume=. 2008 , publisher=
2008
-
[39]
ACM MM , year=
Mafw: A large-scale, multi-modal, compound affective database for dynamic facial expression recognition in the wild , author=. ACM MM , year=
-
[40]
CoRR , year=
Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos , author=. CoRR , year=
-
[41]
ACL , year=
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph , author=. ACL , year=
-
[42]
ACL , year=
Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality , author=. ACL , year=
-
[43]
0 dataset and av-mixup consistent module , author=
Make acoustic and visual cues matter: Ch-sims v2. 0 dataset and av-mixup consistent module , author=. ICMI , year=
-
[44]
IEEE Transactions on Affective Computing , volume=
Crema-d: Crowd-sourced emotional multimodal actors dataset , author=. IEEE Transactions on Affective Computing , volume=. 2014 , publisher=
2014
-
[45]
IEEE Transactions on Affective Computing , volume=
Mgeed: A multimodal genuine emotion and expression detection database , author=. IEEE Transactions on Affective Computing , volume=. 2023 , publisher=
2023
-
[46]
ACM MM , year=
Mer 2023: Multi-label learning, modality robustness, and semi-supervised learning , author=. ACM MM , year=
2023
-
[47]
Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing , year=
Mer 2024: Semi-supervised learning, noise robustness, and open-vocabulary multimodal emotion recognition , author=. Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing , year=
2024
-
[48]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Merbench: A unified evaluation benchmark for multimodal emotion recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[49]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[50]
CoRR , year=
Explainable multimodal emotion reasoning , author=. CoRR , year=
-
[51]
ICML , year=
Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models , author=. ICML , year=
-
[52]
NeurIPS , year=
Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning , author=. NeurIPS , year=
-
[53]
arXiv preprint arXiv:2501.09502 , year=
Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis , author=. arXiv preprint arXiv:2501.09502 , year=
-
[54]
arXiv preprint arXiv:2501.15111 , year=
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding , author=. arXiv preprint arXiv:2501.15111 , year=
-
[55]
arXiv preprint arXiv:2503.05379 , year=
R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcing Learning , author=. arXiv preprint arXiv:2503.05379 , year=
-
[56]
arXiv preprint arXiv:2511.18437 , year=
Perceptual-Evidence Anchored Reinforced Learning for Multimodal Reasoning , author=. arXiv preprint arXiv:2511.18437 , year=
-
[57]
arXiv preprint arXiv:2509.21854 , year=
Perception-Consistency Multimodal Large Language Models Reasoning via Caption-Regularized Policy Optimization , author=. arXiv preprint arXiv:2509.21854 , year=
-
[58]
arXiv preprint arXiv:2506.07218 , year=
Advancing Multimodal Reasoning Capabilities of Multimodal Large Language Models via Visual Perception Reward , author=. arXiv preprint arXiv:2506.07218 , year=
-
[59]
Nature Machine Intelligence , volume=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature Machine Intelligence , volume=
-
[60]
arXiv preprint arXiv:2403.14608 , year=
Parameter-efficient fine-tuning for large models: A comprehensive survey , author=. arXiv preprint arXiv:2403.14608 , year=
-
[61]
ICLR , year=
Lora: Low-rank adaptation of large language models , author=. ICLR , year=
-
[62]
arXiv preprint arXiv:2312.12379 , year=
Mixture of cluster-conditional lora experts for vision-language instruction tuning , author=. arXiv preprint arXiv:2312.12379 , year=
-
[63]
NeurIPS , year=
Hydralora: An asymmetric lora architecture for efficient fine-tuning , author=. NeurIPS , year=
-
[64]
ACM MM , year=
Dfew: A large-scale database for recognizing dynamic facial expressions in the wild , author=. ACM MM , year=
-
[65]
CVPR , year=
Mono-internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training , author=. CVPR , year=
-
[66]
arXiv preprint arXiv:2407.21770 , year=
Moma: Efficient early-fusion pre-training with mixture of modality-aware experts , author=. arXiv preprint arXiv:2407.21770 , year=
-
[67]
CVPR , year=
Image as a foreign language: Beit pretraining for vision and vision-language tasks , author=. CVPR , year=
-
[68]
Findings of EMNLP , year=
Scaling vision-language models with sparse mixture of experts , author=. Findings of EMNLP , year=
-
[69]
CVPR , year=
Omni-smola: Boosting generalist multimodal models with soft mixture of low-rank experts , author=. CVPR , year=
-
[70]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=
-
[71]
arXiv preprint arXiv:2309.05922 , year=
A survey of hallucination in large foundation models , author=. arXiv preprint arXiv:2309.05922 , year=
-
[72]
arXiv preprint arXiv:2402.00253 , year=
A survey on hallucination in large vision-language models , author=. arXiv preprint arXiv:2402.00253 , year=
-
[73]
CVPR , year=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. CVPR , year=
-
[74]
CVPR , year=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. CVPR , year=
-
[75]
arXiv preprint arXiv:2411.15839 , year=
VaLiD: Mitigating the Hallucination of Large Vision Language Models by Visual Layer Fusion Contrastive Decoding , author=. arXiv preprint arXiv:2411.15839 , year=
-
[76]
arXiv preprint arXiv:2411.09968 , year=
Seeing clearly by layer two: Enhancing attention heads to alleviate hallucination in lvlms , author=. arXiv preprint arXiv:2411.09968 , year=
-
[77]
ICLR , year=
Decoupled weight decay regularization , author=. ICLR , year=
-
[78]
arXiv preprint arXiv:2303.15389 , year=
Eva-clip: Improved training techniques for clip at scale , author=. arXiv preprint arXiv:2303.15389 , year=
-
[79]
EMNLP , year=
Video-llava: Learning united visual representation by alignment before projection , author=. EMNLP , year=
-
[80]
CVPR , year=
Onellm: One framework to align all modalities with language , author=. CVPR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.