Stagnant Neuron: Towards Understanding the Plasticity Loss in Multi-Agent Reinforcement Learning Value Factorization Methods
Pith reviewed 2026-06-25 21:20 UTC · model grok-4.3
The pith
KNIFE restores learning capacity in multi-agent RL value factorization by directly replacing stagnant neurons whose gradients have shrunk to near zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
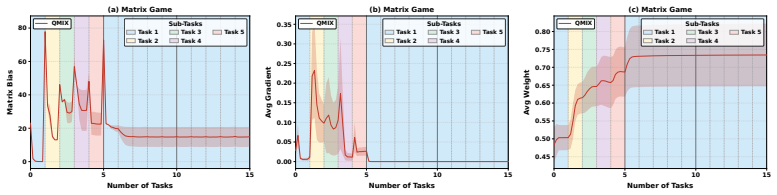
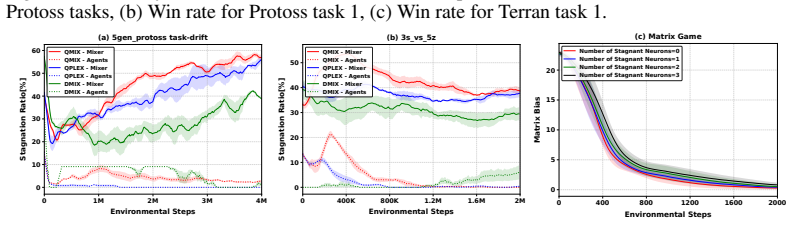
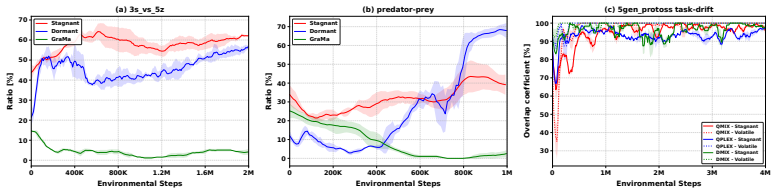
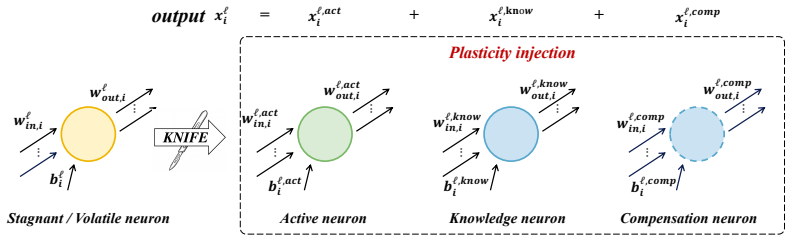
Stagnant neurons cause plasticity loss in MARL value factorization; KNIFE replaces each such neuron with a composite unit consisting of a frozen knowledge neuron, a re-initialized active neuron, and a compensation neuron whose combined output matches the original, thereby restoring learning capacity while preserving cooperation knowledge.
What carries the argument
KNIFE composite replacement: a three-neuron module (frozen knowledge neuron + re-initialized active neuron + compensation neuron) that substitutes for each identified stagnant neuron while keeping the value factorization output unchanged.
If this is right
- Value-factorization networks can continue adapting after task transfer without full retraining.
- Gradient-collapse detection becomes a practical diagnostic for when plasticity has been lost.
- The same neuron-level replacement logic could be applied to other cooperative MARL architectures that rely on centralized training.
- Knowledge preservation no longer requires freezing entire layers or replay buffers.
Where Pith is reading between the lines
- If stagnant neurons appear in single-agent RL as well, the same composite replacement could be tested outside multi-agent settings.
- The compensation neuron might be replaceable by a simple scaling factor if the output-matching requirement can be enforced at the layer level instead of per neuron.
- Measuring the fraction of stagnant neurons over training could serve as an early-warning signal for when transfer performance will degrade.
Load-bearing premise
The composite replacement keeps previously learned cooperation knowledge intact and does not create new interference inside the factorization.
What would settle it
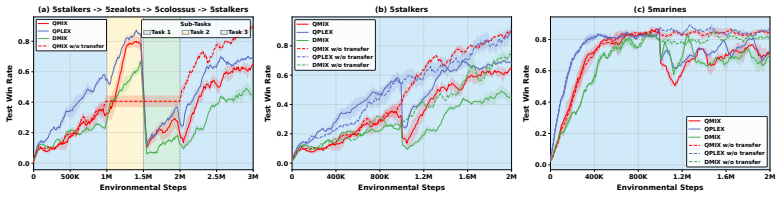
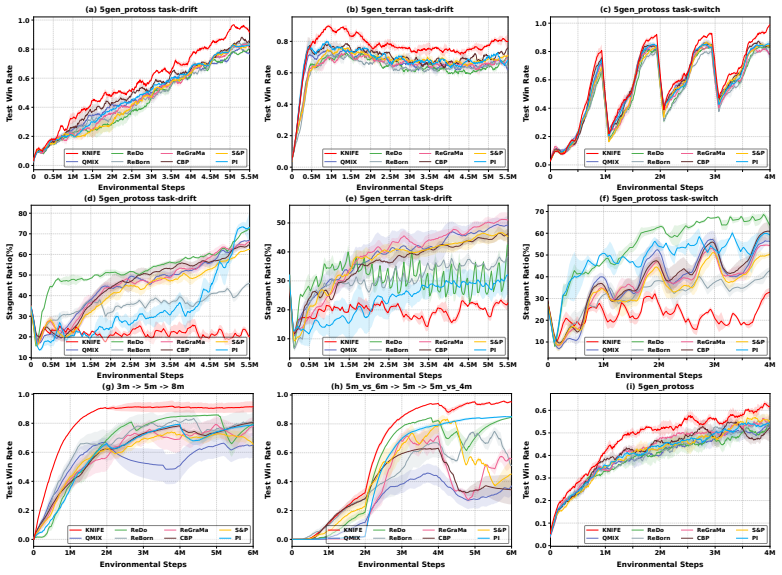
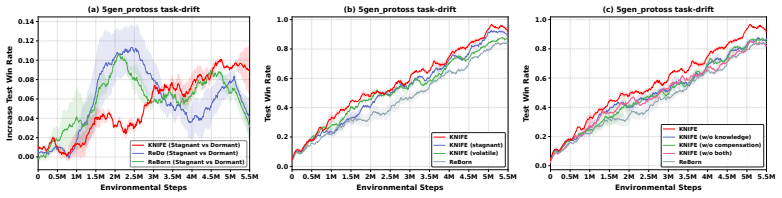
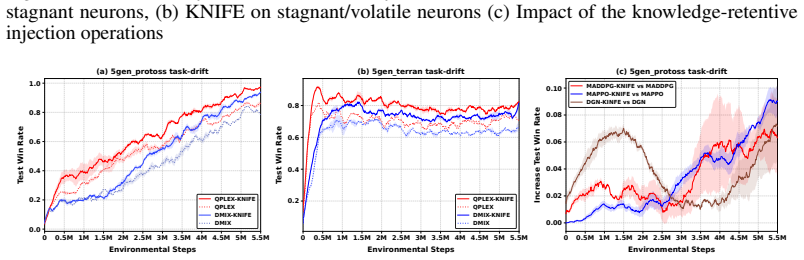
Run the same SMACv2, predator-prey, and matrix-game transfer protocols; if KNIFE no longer outperforms the prior plasticity-injection baselines, the claim that the composite replacement solves stagnant-neuron plasticity loss is false.
Figures
read the original abstract
Multi-Agent Reinforcement Learning (MARL) value factorization methods can suffer from a loss of plasticity, gradually failing to adapt when transferring to new task instances. We trace this issue to stagnant neurons, units whose gradient updates become negligibly small relative to their weights, thereby hindering learning. While existing plasticity injection methods exist, they prove ineffective for such neurons. To address this, we propose Knowledge-retentive Neuron-level PlastIcity Focusing InjEction (KNIFE), a novel method that directly targets stagnant neurons. KNIFE replaces each stagnant neuron with a composite unit comprising three specialized components: a frozen knowledge neuron to preserve acquired knowledge, a re-initialized active neuron to restore learning capacity, and a compensation neuron to ensure the combined output matches the original, thus maintaining previous learned cooperation knowledge. Extensive experiments on SMACv2, predator-prey, and matrix games demonstrate that KNIFE significantly outperforms state-of-the-art plasticity injection methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that plasticity loss in MARL value factorization methods arises from stagnant neurons (units whose gradient updates become negligibly small relative to their weights). It introduces KNIFE, which replaces each such neuron with a composite of a frozen knowledge neuron (to retain acquired knowledge), a re-initialized active neuron (to restore learning capacity), and a compensation neuron (to ensure the combined output matches the original). Experiments on SMACv2, predator-prey, and matrix games are reported to show that KNIFE significantly outperforms existing plasticity injection methods.
Significance. If the results hold under rigorous verification, the work could provide a targeted intervention for restoring adaptability in cooperative MARL without disrupting prior value factorization, addressing a practical barrier in transfer settings.
major comments (2)
- [Abstract] Abstract: the claim that KNIFE 'significantly outperforms state-of-the-art plasticity injection methods' is made without any quantitative metrics, identification criteria for stagnant neurons, or ablation details; the central empirical claim therefore rests on unreported experiments.
- [Method] Method description: the assertion that the composite replacement (frozen knowledge neuron + re-initialized active neuron + compensation neuron) exactly preserves previously learned cooperation knowledge without introducing new interference is load-bearing for the method's validity, yet no derivation, output-matching proof, or empirical verification of this property is supplied.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that KNIFE 'significantly outperforms state-of-the-art plasticity injection methods' is made without any quantitative metrics, identification criteria for stagnant neurons, or ablation details; the central empirical claim therefore rests on unreported experiments.
Authors: The abstract is intentionally concise per conference guidelines, but the full manuscript reports quantitative results (e.g., win-rate and return improvements on SMACv2, predator-prey, and matrix games) with tables and statistical significance in Section 4. Stagnant-neuron identification uses the gradient-to-weight ratio threshold defined in Section 3.2, and ablations appear in Section 4.3. We will revise the abstract to include one or two key quantitative highlights and a brief reference to the identification criterion. revision: yes
-
Referee: [Method] Method description: the assertion that the composite replacement (frozen knowledge neuron + re-initialized active neuron + compensation neuron) exactly preserves previously learned cooperation knowledge without introducing new interference is load-bearing for the method's validity, yet no derivation, output-matching proof, or empirical verification of this property is supplied.
Authors: Section 3.3 derives the compensation neuron explicitly: given the additive decomposition in value factorization, the compensation weights are solved so that the sum of the three component outputs equals the original neuron output at the moment of replacement. This is a direct algebraic identity under the linear mixing assumption used by the methods considered. Empirical verification is provided via source-task performance retention experiments in Section 4.2. We will expand the derivation with an explicit equation and a short proof sketch in the revision for clarity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical method (KNIFE) that procedurally replaces identified stagnant neurons with a three-part composite unit whose compensation component is explicitly constructed to match prior outputs. No equations, fitted parameters renamed as predictions, self-definitional derivations, or load-bearing self-citations appear in the abstract or described claims. The central result is an experimental performance comparison on SMACv2, predator-prey, and matrix games rather than a closed-form derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
stagnant neuron
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E. Taylor. Is multiagent deep reinforcement learning the answer or the question? A brief survey. InAAMAS, pages 750–797, 2019. URL http://arxiv.org/abs/1810.05587
arXiv 2019
-
[2]
Foerster, and Shimon Whiteson
Tabish Rashid, Mikayel Samvelyan, Christian Schröder de Witt, Gregory Farquhar, Jakob N. Foerster, and Shimon Whiteson. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. InICML, pages 4292–4301, 2018
2018
-
[3]
Meal: A benchmark for continual multi-agent reinforcement learning
Tristan Tomilin, Luka van den Boogaard, Samuel Garcin, Bram Grooten, Meng Fang, Yali Du, and Mykola Pechenizkiy. Meal: A benchmark for continual multi-agent reinforcement learning. arXiv preprint arXiv:2506.14990, 2025
Pith/arXiv arXiv 2025
-
[4]
Understanding plasticity in neural networks
Clare Lyle, Zeyu Zheng, Evgenii Nikishin, Bernardo Avila Pires, Razvan Pascanu, and Will Dabney. Understanding plasticity in neural networks. InICML, pages 23190–23211, 2023
2023
-
[5]
Deep reinforcement learning with plasticity injection
Evgenii Nikishin, Junhyuk Oh, Georg Ostrovski, Clare Lyle, Razvan Pascanu, Will Dabney, and André Barreto. Deep reinforcement learning with plasticity injection. InNeurIPS, 2023
2023
-
[6]
Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024
2024
-
[7]
The dormant neuron phenomenon in multi-agent reinforcement learning value factorization
Haoyuan Qin, Chennan Ma, Mian Deng, Zhengzhu Liu, Songzhu Mei, Xinwang Liu, Cheng Wang, and Siqi Shen. The dormant neuron phenomenon in multi-agent reinforcement learning value factorization. InNeurIPS, 2024
2024
-
[8]
Qplex: Duplex dueling multi-agent q-learning
Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. Qplex: Duplex dueling multi-agent q-learning. InICLR, 2021
2021
-
[9]
Foerster, and Shimon Whiteson
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob N. Foerster, and Shimon Whiteson. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning. InNeurIPS, 2023
2023
-
[10]
The dormant neuron phenomenon in deep reinforcement learning
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro, and Utku Evci. The dormant neuron phenomenon in deep reinforcement learning. InICML, pages 32145–32168, 2023
2023
-
[11]
Jiashun Liu, Zihao Wu, Johan Obando-Ceron, Pablo Samuel Castro, Aaron Courville, and Ling Pan. Measure gradients, not activations! enhancing neuronal activity in deep reinforcement learning.arXiv preprint arXiv:2505.24061, 2025
arXiv 2025
-
[12]
Oliehoek and Christopher Amato.A Concise Introduction to Decentralized POMDPs
Frans A. Oliehoek and Christopher Amato.A Concise Introduction to Decentralized POMDPs. Springer Briefs in Intelligent Systems. Springer, 2016
2016
-
[13]
A definition of continual reinforcement learning.Advances in Neural Information Processing Systems, 36:50377–50407, 2023
David Abel, André Barreto, Benjamin Van Roy, Doina Precup, Hado P van Hasselt, and Satinder Singh. A definition of continual reinforcement learning.Advances in Neural Information Processing Systems, 36:50377–50407, 2023
2023
-
[14]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[15]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InInternational conference on machine learning, pages 3987–3995. PMLR, 2017
2017
-
[16]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018
2018
-
[17]
Learning continually by spectral regularization
Alex Lewandowski, Michał Bortkiewicz, Saurabh Kumar, András György, Dale Schuurmans, Mateusz Ostaszewski, and Marlos C Machado. Learning continually by spectral regularization. arXiv preprint arXiv:2406.06811, 2024. 10
arXiv 2024
-
[18]
Packnet: Adding multiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018
2018
-
[19]
Neuroplastic expansion in deep reinforcement learning.arXiv preprint arXiv:2410.07994, 2024
Jiashun Liu, Johan Obando-Ceron, Aaron Courville, and Ling Pan. Neuroplastic expansion in deep reinforcement learning.arXiv preprint arXiv:2410.07994, 2024
arXiv 2024
-
[20]
Pseudo-rehearsal: Achieving deep reinforcement learning without catastrophic forgetting.Neurocomputing, 428: 291–307, 2021
Craig Atkinson, Brendan McCane, Lech Szymanski, and Anthony Robins. Pseudo-rehearsal: Achieving deep reinforcement learning without catastrophic forgetting.Neurocomputing, 428: 291–307, 2021
2021
-
[21]
Jiuqi Wang, Rohan Chandra, and Shangtong Zhang. Experience replay addresses loss of plasticity in continual learning.arXiv preprint arXiv:2503.20018, 2025
arXiv 2025
-
[22]
Retaining suboptimal actions to follow shifting optima in multi-agent reinforcement learning
Yonghyeon Jo, Sunwoo Lee, and Seungyul Han. Retaining suboptimal actions to follow shifting optima in multi-agent reinforcement learning. InICLR, 2026
2026
-
[23]
Shibhansh Dohare, Richard S Sutton, and A Rupam Mahmood. Continual backprop: Stochastic gradient descent with persistent randomness.arXiv preprint arXiv:2108.06325, 2021
arXiv 2021
-
[24]
Courville
Evgenii Nikishin, Max Schwarzer, Pierluca D’Oro, Pierre-Luc Bacon, and Aaron C. Courville. The primacy bias in deep reinforcement learning. InICML, pages 16828–16847, 2022. URL https://proceedings.mlr.press/v162/nikishin22a.html
2022
-
[25]
Sample-efficient multiagent re- inforcement learning with reset replay
Yaodong Yang, Guangyong Chen, Pheng-Ann Heng, et al. Sample-efficient multiagent re- inforcement learning with reset replay. InForty-first international conference on machine learning, 2024
2024
-
[26]
Weighted QMIX: expanding monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Gregory Farquhar, Bei Peng, and Shimon Whiteson. Weighted QMIX: expanding monotonic value function factorisation for deep multi-agent reinforcement learning. InNeurIPS, 2020
2020
-
[27]
Resq: A residual q function-based approach for multi-agent reinforcement learning value factorization
Siqi Shen, Mengwei Qiu, Jun Liu, Weiquan Liu, Yongquan Fu, Xinwang Liu, and Cheng Wang. Resq: A residual q function-based approach for multi-agent reinforcement learning value factorization. InNeurIPS, 2022
2022
-
[28]
Riskq: Risk-sensitive multi-agent reinforcement learning value factorization
Siqi Shen, Chennan Ma, Chao Li, Weiquan Liu, Yongquan Fu, Songzhu Mei, Xinwang Liu, and Cheng Wang. Riskq: Risk-sensitive multi-agent reinforcement learning value factorization. In NeurIPS, 2023. URLhttps://openreview.net/forum?id=FskZtRvMJI
2023
-
[29]
Qatten: A general framework for cooperative multiagent reinforcement learning.CoRR,
Yaodong Yang, Jianye Hao, Ben Liao, Kun Shao, Guangyong Chen, Wulong Liu, and Hongyao Tang. Qatten: A general framework for cooperative multiagent reinforcement learning.CoRR,
-
[30]
URLhttps://arxiv.org/abs/2002.03939
arXiv 2002
-
[31]
Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers
Siyi Hu, Fengda Zhu, Xiaojun Chang, and Xiaodan Liang. Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers. InICLR, 2021
2021
-
[32]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InNeurIPS, pages 6379–6390, 2017
2017
-
[33]
The surprising effectiveness of ppo in cooperative multi-agent games.NeurIPS, 35:24611– 24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.NeurIPS, 35:24611– 24624, 2022
2022
-
[34]
Graph convolutional reinforcement learning
Jiechuan Jiang, Chen Dun, Tiejun Huang, and Zongqing Lu. Graph convolutional reinforcement learning. InICLR, 2020
2020
-
[35]
Mikayel Samvelyan, Tabish Rashid, Christian Schröder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob N. Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. InAAMAS, pages 2186–2188, 2019
2019
-
[36]
Dai, and Quoc V
David Ha, Andrew M. Dai, and Quoc V . Le. Hypernetworks. InICLR, 2017. 11
2017
-
[37]
On warm-starting neural network training.NeurIPS, 33: 3884–3894, 2020
Jordan Ash and Ryan P Adams. On warm-starting neural network training.NeurIPS, 33: 3884–3894, 2020
2020
-
[38]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinícius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. InAAMAS, pages 2085–2087, 2018
2085
-
[39]
QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Hostallero, and Yung Yi. QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning. In ICML, pages 5887–5896, 2019
2019
-
[40]
−10−10 12 −9−12−8 −4−8−11 # , M 2 =
Wei-Fang Sun, Cheng-Kuang Lee, and Chun-Yi Lee. DFAC framework: Factorizing the value function via quantile mixture for multi-agent distributional q-learning. InICML, pages 9945–9954, 2021. 12 A Background A.1 Value Function Factorization In value factorization methods [ 2, 37, 8, 38], per-agent utilities Qi are approximated byagent networks, and then mix...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.