Lifelong In-Context Learning with Transformers Requires Parametric Forms of Attention
Pith reviewed 2026-06-25 21:17 UTC · model grok-4.3
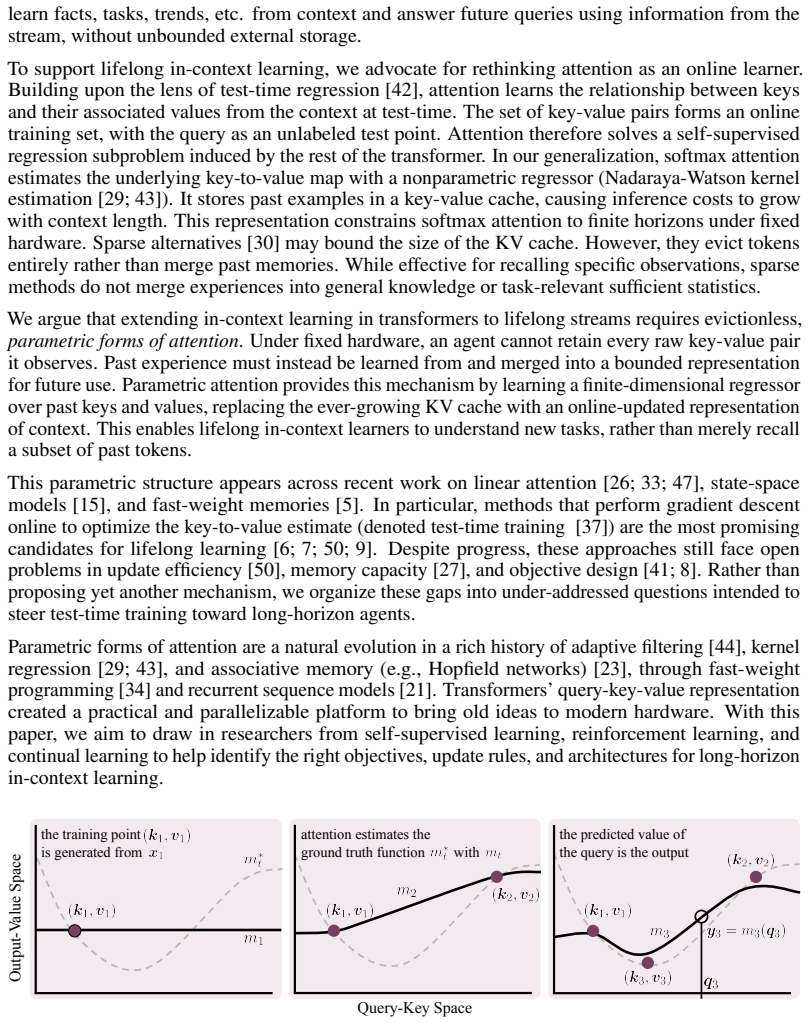
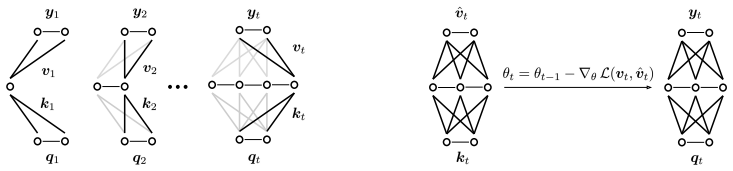
The pith
Transformers require parametric attention to perform lifelong in-context learning on a fixed memory budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Parametric forms of attention learn the relationship between keys and their associated values at test-time with parametric regression, replacing the ever-growing key-value cache with an online-trainable neural network to maintain a constant memory footprint while extending in-context learning to lifelong settings.
What carries the argument
Parametric attention, which performs parametric regression to associate keys with values during inference instead of storing them explicitly.
If this is right
- Transformers can process sequences of arbitrary length while using only constant memory.
- In-context learning extends to lifelong continual learning for AI agents.
- Methods such as linear attention and state-space models become building blocks for long-horizon agents.
- Resolving capacity and update-cost limits in parametric attention will be required to realize the approach.
Where Pith is reading between the lines
- Hybrid architectures that combine parametric attention with existing transformer layers could enable gradual knowledge accumulation without full model resets.
- Success would shift emphasis from ever-larger pretraining runs toward ongoing test-time adaptation.
- The open questions on capacity and cost suggest concrete benchmarks that measure retention over thousands of steps with fixed parameters.
Load-bearing premise
An online-trainable neural network can replace the key-value cache without prohibitive update costs or hitting hard capacity limits.
What would settle it
A direct comparison showing that a parametric attention model either drops accuracy on sequences longer than its training horizon or requires more total compute than softmax attention with a memory-bounded cache.
Figures
read the original abstract
Lifelong continual learning remains an obstacle on the path to human-like intelligence. Modern transformers show sparks of intelligence with in-context learning. The quadratic nature of attention, however, prohibits transformers from performing this process on arbitrarily long sequences. In this work, we argue that extending in-context learning to lifelong settings is a practical solution for continual learning in AI agents. In particular, we argue that \emph{parametric forms of attention} are needed to understand a lifetime of context with transformers on a fixed hardware budget. These attention mechanisms learn the relationship between keys and their associated values at test-time with parametric regression. Our generalization of parametric approaches (linear attention, state-space models, fast weight programmers, and test-time training layers) contrasts with nonparametric counterparts like softmax attention. They replace the ever-growing key-value cache with an online-trainable neural network, maintaining a constant memory footprint. We highlight how parametric attention currently fall short of lifelong learning due to limited memory capacity or costly online updates. To address these issues, we pose a set of open questions with novel insights to guide the field toward long-horizon agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper arguing that extending in-context learning to lifelong settings in transformers requires parametric forms of attention. These replace the growing key-value cache of softmax attention with an online-trainable neural network via parametric regression, thereby maintaining constant memory on fixed hardware while processing arbitrarily long sequences. The paper unifies linear attention, state-space models, fast weight programmers, and test-time training under this parametric umbrella, contrasts them with nonparametric methods, acknowledges current shortcomings in capacity and update cost, and poses open questions to guide future research on long-horizon agents.
Significance. If the argument is accepted, the paper could usefully redirect research toward parametric attention mechanisms that support continual learning without unbounded memory growth. Its main contribution is the synthesis of existing methods under a single framing and the explicit listing of open challenges; the work contains no new derivations, proofs, or experiments.
major comments (1)
- [Abstract] Abstract: the necessity claim that parametric attention is required 'to understand a lifetime of context with transformers on a fixed hardware budget' assumes without supporting argument that constant memory is mandatory. The manuscript provides no analysis ruling out alternatives such as cache compression, hierarchical memory, or periodic eviction that could keep quadratic attention feasible within hardware limits.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to strengthen the manuscript. As a position paper, our goal is to synthesize existing approaches and highlight open challenges rather than provide exhaustive proofs. We address the concern regarding the necessity claim below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the necessity claim that parametric attention is required 'to understand a lifetime of context with transformers on a fixed hardware budget' assumes without supporting argument that constant memory is mandatory. The manuscript provides no analysis ruling out alternatives such as cache compression, hierarchical memory, or periodic eviction that could keep quadratic attention feasible within hardware limits.
Authors: We agree that the abstract states the necessity of parametric attention for constant-memory lifelong ICL without explicitly analyzing alternatives. Our core argument is that any approach relying on an ever-growing key-value cache (even with compression or eviction) will eventually exceed fixed hardware limits for truly arbitrary sequence lengths, as compression ratios are bounded and eviction risks losing critical lifelong context. Hierarchical memory introduces additional complexity and latency that may not resolve the fundamental scaling issue. We will revise the abstract and add a short paragraph in the introduction (or a dedicated subsection) acknowledging these alternatives and explaining why we view parametric regression as the more scalable path for constant footprint. This revision will be made without altering the position paper's scope or adding new experiments. revision: yes
Circularity Check
Position paper with no derivational claims or reductions
full rationale
The paper is explicitly a position paper that argues for the necessity of parametric attention forms to enable lifelong in-context learning under fixed memory constraints. It presents no equations, formal derivations, fitted parameters, predictions, or empirical results. The abstract and text instead highlight shortcomings of existing parametric methods, contrast them with softmax attention at a conceptual level, and conclude by posing open questions. No load-bearing step reduces to a self-definition, fitted input, or self-citation chain; the argument is self-contained as advocacy for future work rather than a closed derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The quadratic nature of attention prohibits transformers from performing in-context learning on arbitrarily long sequences.
- domain assumption An online-trainable neural network can replace the ever-growing key-value cache while maintaining performance.
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023
Pith/arXiv arXiv 2023
-
[2]
Physics of language models: Part 4.1, architecture design and the magic of canon layers, 2025
Zeyuan Allen-Zhu. Physics of language models: Part 4.1, architecture design and the magic of canon layers, 2025. URLhttps://arxiv.org/abs/2512.17351
arXiv 2025
-
[3]
Just read twice: closing the recall gap for recurrent language models, 2024
Simran Arora, Aman Timalsina, Aaryan Singhal, Benjamin Spector, Sabri Eyuboglu, Xinyi Zhao, Ashish Rao, Atri Rudra, and Christopher Ré. Just read twice: closing the recall gap for recurrent language models, 2024. URLhttps://arxiv.org/abs/2407.05483
arXiv 2024
-
[4]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
2023
-
[5]
xlstm: Ex- tended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Ex- tended long short-term memory. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[6]
Titans: Learning to memorize at test time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024
Pith/arXiv arXiv 2024
-
[7]
Atlas: Learning to optimally memorize the context at test time.arXiv preprint arXiv:2505.23735, 2025
Ali Behrouz, Zeman Li, Praneeth Kacham, Majid Daliri, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, and Vahab Mirrokni. Atlas: Learning to optimally memorize the context at test time.arXiv preprint arXiv:2505.23735, 2025
arXiv 2025
-
[8]
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online optimization. arXiv preprint arXiv:2504.13173, 2025
arXiv 2025
-
[9]
Nested learning: The illusion of deep learning architectures.arXiv preprint arXiv:2512.24695, 2025
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. Nested learning: The illusion of deep learning architectures.arXiv preprint arXiv:2512.24695, 2025
arXiv 2025
-
[10]
Modular duality in deep learning.arXiv preprint arXiv:2410.21265, 2024
Jeremy Bernstein and Laker Newhouse. Modular duality in deep learning.arXiv preprint arXiv:2410.21265, 2024
arXiv 2024
-
[11]
Lora learns less and forgets less.arXiv preprint arXiv:2405.09673, 2024
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less.arXiv preprint arXiv:2405.09673, 2024
arXiv 2024
-
[12]
Continual lifelong learning in natural language processing: A survey
Magdalena Biesialska, Katarzyna Biesialska, and Marta R Costa-jussà. Continual lifelong learning in natural language processing: A survey. InProceedings of the 28th International Conference on Computational Linguistics, pages 6523–6541, 2020
2020
-
[13]
An iterative algorithm for computing the best estimate of an orthogonal matrix.SIAM Journal on Numerical Analysis, 8(2):358–364, 1971
Åke Björck and Clazett Bowie. An iterative algorithm for computing the best estimate of an orthogonal matrix.SIAM Journal on Numerical Analysis, 8(2):358–364, 1971
1971
-
[14]
Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
Rewon Child. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
Pith/arXiv arXiv 1904
-
[15]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[16]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2024. URL https://arxiv.org/abs/2312.00752
Pith/arXiv arXiv 2024
-
[17]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2021. 10
2021
-
[18]
Designing robust transformers using robust kernel density estimation.Advances in Neural Information Processing Systems, 36:53362–53384, 2023
Xing Han, Tongzheng Ren, Tan Nguyen, Khai Nguyen, Joydeep Ghosh, and Nhat Ho. Designing robust transformers using robust kernel density estimation.Advances in Neural Information Processing Systems, 36:53362–53384, 2023
2023
-
[19]
Psychology press, 2005
Donald Olding Hebb.The organization of behavior: A neuropsychological theory. Psychology press, 2005
2005
-
[20]
Parallel models of associative memory
Geoffrey E Hinton and James A Anderson. Parallel models of associative memory. 1989
1989
-
[21]
Long short-term memory.Neural Computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997. doi: 10.1162/neco.1997.9.8.1735
-
[22]
The hardware lottery.Communications of the ACM, 64(12):58–65, 2021
Sara Hooker. The hardware lottery.Communications of the ACM, 64(12):58–65, 2021
2021
-
[23]
Hwang, S., Folli, V ., Lanza, E., Parisi, G., Ruocco, G., and Zamponi, F
J J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982. doi: 10.1073/pnas.79.8.2554. URL https://www.pnas.org/doi/abs/10.1073/pnas. 79.8.2554
-
[24]
Kernel memory networks: A unifying framework for memory modeling, 2024
Georgios Iatropoulos, Johanni Brea, and Wulfram Gerstner. Kernel memory networks: A unifying framework for memory modeling, 2024. URL https://arxiv.org/abs/2208. 09416
2024
-
[25]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
2024
-
[26]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[27]
Lola: Low-rank linear attention with sparse caching.arXiv preprint arXiv:2505.23666, 2025
Luke McDermott, Robert W Heath Jr, and Rahul Parhi. Lola: Low-rank linear attention with sparse caching.arXiv preprint arXiv:2505.23666, 2025
arXiv 2025
-
[28]
Embodied lifelong learning for task and motion planning
Jorge Mendez-Mendez, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Embodied lifelong learning for task and motion planning. InConference on Robot Learning, pages 2134–2150. PMLR, 2023
2023
-
[29]
Some new estimates for distribution functions.Theory of Probability & Its Applications, 9(3):497–500, 1964
Elizbar A Nadaraya. Some new estimates for distribution functions.Theory of Probability & Its Applications, 9(3):497–500, 1964
1964
-
[30]
Piotr Nawrot, Robert Li, Renjie Huang, Sebastian Ruder, Kelly Marchisio, and Edoardo M Ponti. The sparse frontier: Sparse attention trade-offs in transformer llms.arXiv preprint arXiv:2504.17768, 2025
Pith/arXiv arXiv 2025
-
[31]
Neural network capacity using delta rule.Electronics Letters, 25(3): 197–199, 1989
DL Prados and SC Kak. Neural network capacity using delta rule.Electronics Letters, 25(3): 197–199, 1989
1989
-
[32]
Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[33]
Linear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. InInternational conference on machine learning, pages 9355–9366. PMLR, 2021
2021
-
[34]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
1992
-
[35]
Deltaproduct: Increasing the expressivity of deltanet through products of householders
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Increasing the expressivity of deltanet through products of householders. InICLR 2025 Workshop on Foundation Models in the Wild, 2025
2025
-
[36]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. 11
2024
-
[37]
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620, 2024
Pith/arXiv arXiv 2024
-
[38]
Retentive network: A successor to transformer for large language models, 2023
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models, 2023. URLhttps://arxiv.org/abs/2307.08621
Pith/arXiv arXiv 2023
-
[39]
Sutton, Michael Bowling, and Patrick M
Richard S. Sutton, Michael Bowling, and Patrick M. Pilarski. The alberta plan for ai research,
-
[40]
URLhttps://arxiv.org/abs/2208.11173
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Max- imilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, et al. Mesanet: Sequence modeling by locally optimal test-time training.arXiv preprint arXiv:2506.05233, 2025
Pith/arXiv arXiv 2025
-
[43]
Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test-time regression: a unifying framework for designing sequence models with associative memory.arXiv preprint arXiv:2501.12352, 2025
arXiv 2025
-
[44]
Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, pages 359–372, 1964
Geoffrey S Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, pages 359–372, 1964
1964
-
[45]
Adaptive filters.Aspects of network and system theory, 1971
Bernard Widrow. Adaptive filters.Aspects of network and system theory, 1971
1971
-
[46]
Adaptive switching circuits
Bernard Widrow and Marcian E Hoff. Adaptive switching circuits. InNeurocomputing: foundations of research, pages 123–134. 1988
1988
-
[47]
Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Pith/arXiv arXiv 2024
-
[48]
Gated linear attention transformers with hardware-efficient training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. InInternational Conference on Machine Learning, pages 56501–56523. PMLR, 2024
2024
-
[49]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[50]
Cambridge University Press, 2023
Aston Zhang, Zachary C Lipton, Mu Li, and Alexander J Smola.Dive into deep learning. Cambridge University Press, 2023
2023
-
[51]
Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
Pith/arXiv arXiv 2025
-
[52]
Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, and Xiangyu Zhao. Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
arXiv 2025
-
[53]
Understanding transformer from the perspective of associative memory, 2025
Shu Zhong, Mingyu Xu, Tenglong Ao, and Guang Shi. Understanding transformer from the perspective of associative memory, 2025. URL https://arxiv.org/abs/2505. 19488. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.