Project-wise Comparison of Software Birthmarks Using Weighted Partial Similarity
Pith reviewed 2026-06-25 20:31 UTC · model grok-4.3
The pith
A symmetric aggregation framework with module-size weighting and top-fraction partial similarity enables robust project-level birthmark comparison for detecting partial code reuse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
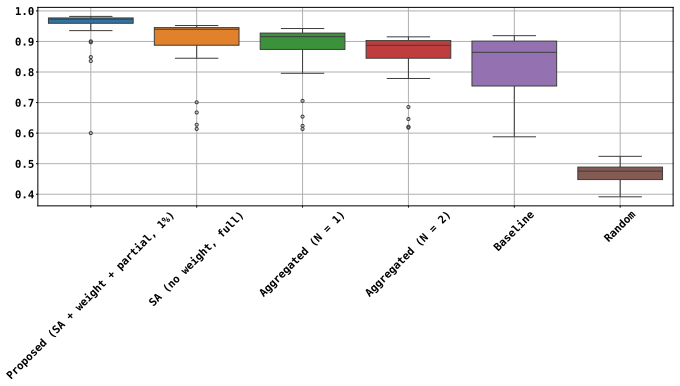
By replacing direct module-level comparison with a symmetric aggregation that incorporates size-based weighting and a focus on the top fraction of similar pairs, the method produces higher combined resilience-credibility scores than prior approaches when applied to 35 Java projects whose different versions serve as reuse examples.
What carries the argument
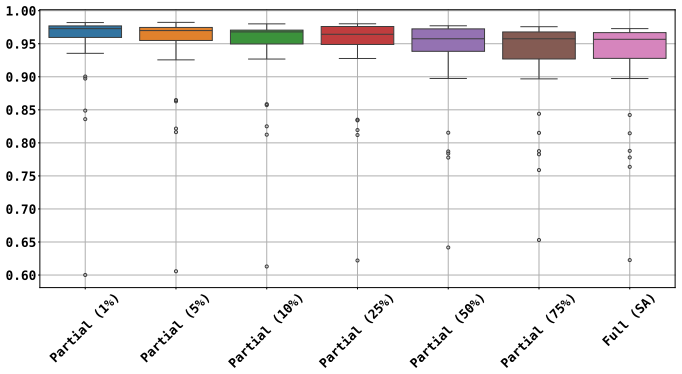
Symmetric aggregation of module-level birthmark similarities, augmented by a size-weighting scheme and a partial-similarity selector that retains only the top fraction of module pairs.
If this is right
- Detection remains stable even when reused code forms only a small fraction of the overall project.
- False positives triggered by incidental matches in small modules are reduced.
- The harmonic mean of resilience and credibility rises compared with unweighted or full-project baselines.
- The same framework can be applied to any birthmark type that supplies per-module similarity values.
Where Pith is reading between the lines
- The public dataset of 35 projects and their versions could serve as a benchmark for testing other project-level similarity techniques.
- The weighting and partial-match ideas might transfer to non-birthmark reuse detectors such as those based on abstract syntax trees or binary fingerprints.
- If the method scales to very large repositories, it could support automated scanning for license violations at the project level rather than file by file.
Load-bearing premise
Treating different versions of the same project as realistic examples of partial reuse between independently developed projects accurately reflects real-world reuse patterns.
What would settle it
Running the method on pairs of unrelated projects that share only small common utility modules and checking whether the combined score stays below the detection threshold.
Figures

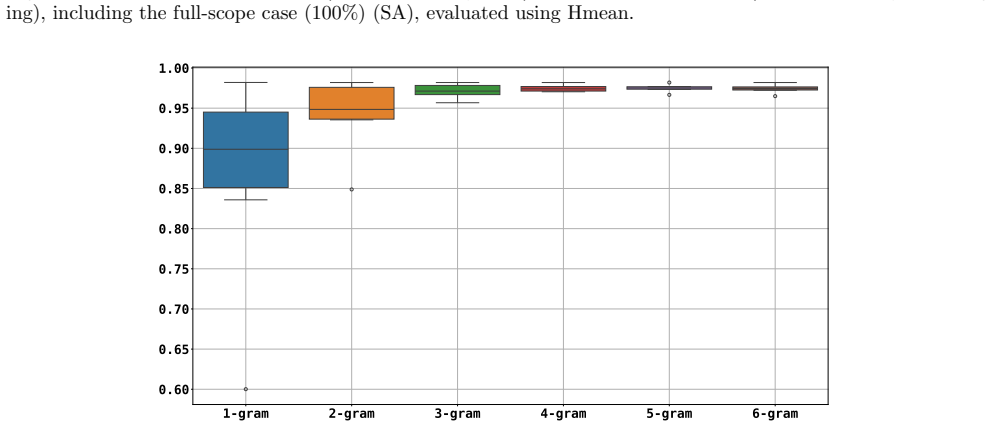
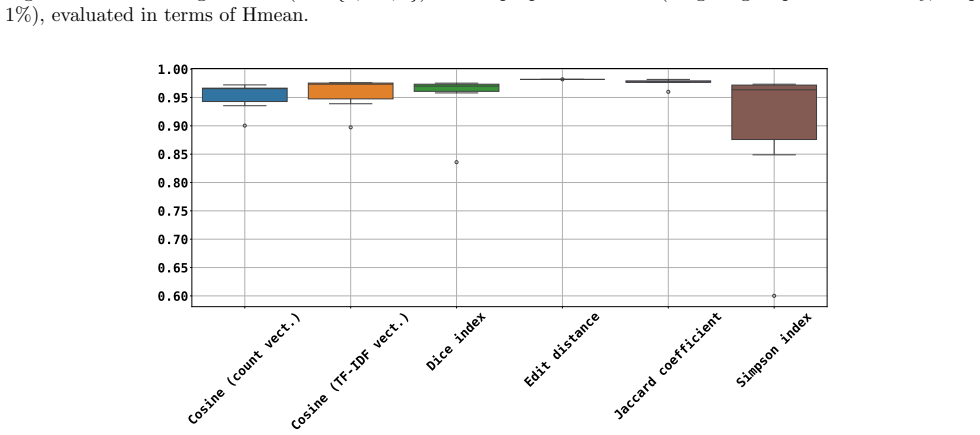
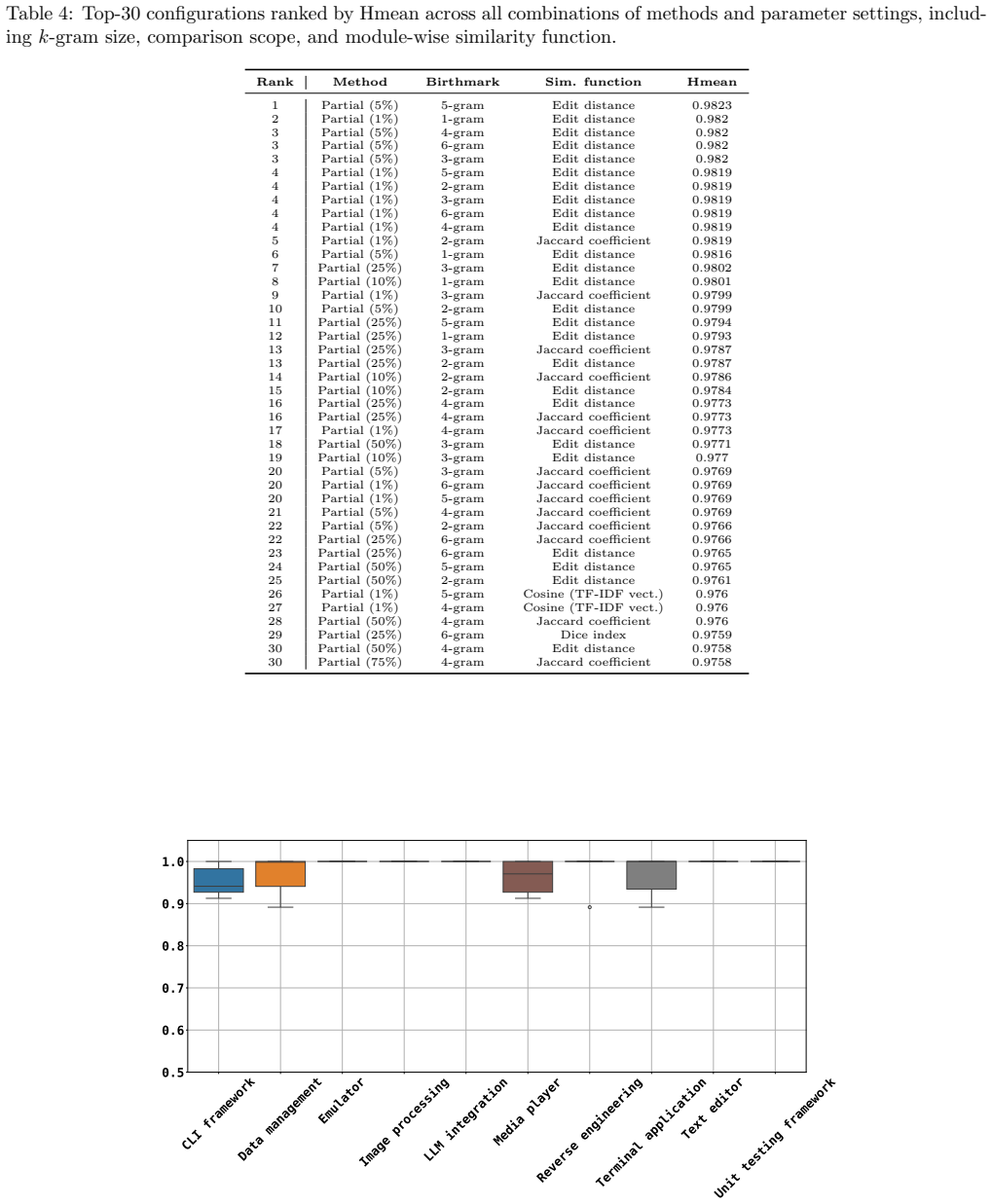
read the original abstract
Software birthmarks provide a robust approach to detecting code plagiarism even under substantial modifications, while distinguishing independently developed software. Existing similarity measures are typically applied at the module level (e.g., source or class files). However, in practice, software reuse often occurs at the project level, where only a subset of modules may be reused. This setting introduces two key challenges: (1) partial reuse, where reused modules constitute only a small fraction of the project, and (2) incidental similarity from small modules, which can lead to false positives. In this paper, we establish a framework for project-wise birthmark comparison based on a symmetric aggregation of module-level similarities. On top of this framework, we propose two complementary mechanisms to address the above challenges. First, we introduce a weighting scheme that assigns higher importance to larger modules, reducing the influence of noisy matches from small modules. Second, we propose a partial similarity method that focuses on the top fraction of highly similar module pairs, enabling robust detection of partial reuse. We evaluate the proposed approach on 35 open-source Java projects across ten categories, where different versions of the same project are treated as reuse cases. The dataset and experimental artifacts are made publicly available to support reproducibility. Performance is assessed using two complementary properties of software birthmarks, resilience and credibility, combined via their harmonic mean. The results show that the proposed method consistently outperforms existing approaches, achieving robust and stable detection of partial code reuse at the project level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for project-wise software birthmark comparison via symmetric aggregation of module-level similarities. It adds a weighting scheme that prioritizes larger modules to reduce noise from small ones and a partial-similarity method that considers only the top fraction of highly similar module pairs. The approach is evaluated on 35 open-source Java projects by treating different versions of the same project as reuse cases; performance is measured by the harmonic mean of resilience and credibility, with the claim that the method consistently outperforms existing approaches for partial code reuse at the project level. The dataset and artifacts are released publicly.
Significance. If the evaluation setup were aligned with the target scenario, the work would provide a practical advance in birthmark-based detection of partial project-level reuse while addressing incidental similarity from small modules. The public release of data and artifacts is a positive contribution to reproducibility.
major comments (1)
- [Abstract / Evaluation] Abstract and Evaluation section: the positive cases are constructed from different versions of the same 35 projects. Version pairs typically share the majority of modules rather than a small fraction and are not independently developed; this proxy therefore does not expose the partial-reuse and incidental-similarity difficulties that the weighting and top-fraction mechanisms are claimed to solve in real-world reuse between independent projects. The mismatch is load-bearing for the central claim of robust detection of partial code reuse.
minor comments (1)
- [Abstract] Abstract: the claim of outperformance is stated without any reference to the concrete birthmark extraction technique, the exact symmetric aggregation formula, the statistical tests employed, or error bars; these details should be summarized or cross-referenced to the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key alignment issue between the evaluation design and the target partial-reuse scenario. We address the comment directly below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the positive cases are constructed from different versions of the same 35 projects. Version pairs typically share the majority of modules rather than a small fraction and are not independently developed; this proxy therefore does not expose the partial-reuse and incidental-similarity difficulties that the weighting and top-fraction mechanisms are claimed to solve in real-world reuse between independent projects. The mismatch is load-bearing for the central claim of robust detection of partial code reuse.
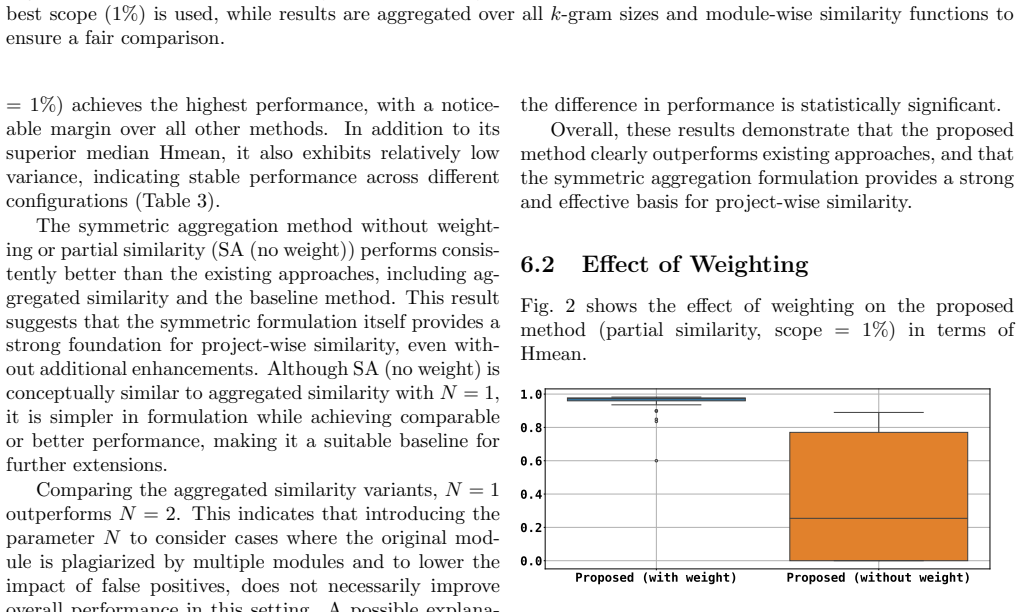
Authors: We acknowledge the validity of this observation. Version pairs from the same project are a standard proxy in birthmark literature because they supply ground-truth reuse under real modifications, yet they typically retain the majority of modules and therefore do not stress-test the partial-similarity component for the small-fraction case nor fully isolate incidental similarity arising from cross-project small modules. The weighting scheme is still exercised by the presence of small modules within each version pair, but the partial-reuse claim would be more convincingly supported by additional cross-project experiments. We will revise the Evaluation section to (1) explicitly state this limitation of the current proxy, (2) add a new set of experiments that construct partial-reuse positives by injecting a controlled minority of modules from one project into an independent project, and (3) report the harmonic-mean results under these conditions. The public dataset release already contains the necessary artifacts to support such supplementary runs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a symmetric aggregation framework plus weighting and top-fraction partial-similarity mechanisms, then reports empirical performance on an external collection of 35 open-source Java projects (different versions treated as reuse cases) using the harmonic mean of resilience and credibility. No equation, parameter fit, or self-citation is shown to make the outperformance claim equivalent to its inputs by construction; the evaluation rests on publicly released artifacts and independent metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open Source Software Detection using Function-level Static Software Birthmark
D. Kim, S. Cho, S. Han, M. Park, and I. You, “Open Source Software Detection using Function-level Static Software Birthmark”,Journal of Internet Services and Information Security (JISIS), vol.4, no.4, pp. 25– 37, 2014
2014
-
[2]
D´ ej` aVu: A Map of Code Duplicates on GitHub
C. V. Lopes, P. Maj, P. Martins, V. Saini, D. Yang, J. Zitny, H. Sajnani, and J. Vitek, “D´ ej` aVu: A Map of Code Duplicates on GitHub”, inProc. ACM Pro- gram. Lang. 1, OOPSLA, Article 84, 28 pages, 2017. DOI: 10.1145/3133908
-
[3]
Identifying Open-Source License Violation and 1-day Security Risk at Large Scale
R. Duan, A. Bijlani, M. Xu, T. Kim, and W. Lee, “Identifying Open-Source License Violation and 1-day Security Risk at Large Scale”,CCS ’17, USA, 2017. DOI: 10.1145/3133956.3134048
-
[4]
Stack Overflow: A Code Laundering Platform?
L. An, o. Mlouki, F. Khomh, and G. Antoniol, “Stack Overflow: A Code Laundering Platform?”. arXiv:1703.03897 [cs.SE], 2017
Pith/arXiv arXiv 2017
-
[5]
Sourcerer’s Apprentice and the study of code snippet migration
S. Romansky, C. Chen, B. Malhotra, and A. Hindle, “Sourcerer’s Apprentice and the study of code snippet migration”. arXiv:1808.00106 [cs.SE], 2018
Pith/arXiv arXiv 2018
-
[6]
A Study of Potential Code Borrowing and License Violations in Java Projects on GitHub
Y. Golubev, M. Eliseeva, N. Povarov, and T. Bryksin, “A Study of Potential Code Borrowing and License Violations in Java Projects on GitHub”. arXiv:2002.05237 [cs.SE], 2020
arXiv 2002
-
[7]
Detecting the Theft of Programs Us- ing Birthmarks
H. Tamada, M. Nakamura, A. Monden, and K. Matsumoto, “Detecting the Theft of Programs Us- ing Birthmarks”,Information Science Technical Re- port, NAIST-IS-TR2003014, ISSN 0919-9527, Grad- uate School of Information Science, Nara Institute of Science and Technology, Japan, 2003
2003
-
[8]
k-gram based software birthmarks
G. Myles and C. Collberg, “k-gram based software birthmarks”,Proc. 2005 ACM symposium on Applied Computing, pp.314—318, ACM, 2005
2005
-
[9]
Design and evaluation of birthmarks for de- tecting theft of Java programs
H. Tamada, M. Nakamura, A. Monden, and K. Mat- sumoto, “Design and evaluation of birthmarks for de- tecting theft of Java programs”, inProc. IASTED SE 2004, pp.569—575, Innsbruck, Austria, 2004
2004
-
[10]
Java birthmarks - detecting the software theft
H. Tamada, M. Nakamura, A. Monden, and K. Mat- sumoto, “Java birthmarks - detecting the software theft”,IEICE Trans. Inf. Syst., E88-D(9): pp.2148— 2158, 2005. DOI: 10.1093/ietisy/e88-d.9.2148
-
[11]
API-based software birthmarking method using fuzzy hashing,
D. Lee, D. Kang, Y. Choi, J. Kim, and D. Won, “API-based software birthmarking method using fuzzy hashing,”IEICE Trans. Inf. Syst., E99.D(7): pp.1836-–1851, 2016. DOI: 10.1587/transinf.2015EDP7379
-
[12]
A static API birthmark for windows binary executa- bles
S. Choi, H. Park, H. I. Lim, and T. Han, “A static API birthmark for windows binary executa- bles”,Journal of Systems and Software, 82(5):862— 873, 2009
2009
-
[13]
Detecting Software Theft with API Call Sequence Sets
D. Schuler and V. Dallmeier, “Detecting Software Theft with API Call Sequence Sets”, inProc. of the 8th Workshop Software Reengineering (WSR’06), Germany, 2006
2006
-
[14]
Comparison of Similarity Functions for n-gram Software Birthmarks,
N. Fedorov, H. Tamada, H. Inayoshi, and A. Mon- den, “Comparison of Similarity Functions for n-gram Software Birthmarks,” inProc. of the 2024 WSSE, pp.169—176, 2024. DOI: 10.1145/3698062.3698087
-
[15]
Detecting software theft via whole program path birthmarks
G. Myles and C. Collberg, “ Detecting software theft via whole program path birthmarks”,Information se- curity, pp.404—415, Springer, 2004
2004
-
[16]
Using software birth- marks to identify similar classes and major function- alities
T. Kakimoto, A. Monden, Y. Kamei, H. Tamada, M. Tsunoda, and K. Matumoto, “Using software birth- marks to identify similar classes and major function- alities”, inProc. of the 2006 MSR, pp.171–172, 2006. DOI: 10.1145/1137983.113802
-
[17]
Effects of nested classes
IBM Corporation, “Effects of nested classes.” [On- line]. Available:www.ibm.com/docs/en/clearcase/ 11.0.0?topic=omake-effects-nested-classes, Accessed on: Mar. 10, 2025. 16 Table 5: Open-source projects. Category Project name V ersion 1 V ersion 2 V ersion 3 V ersion 4 CLI framework Airline 0.4 2012-8-21 0.5 2013-01-10 0.7 2014-11-06 0.9 2019-12-06 JComma...
2025
-
[18]
Nested Classes
Oracle Corporation, “Nested Classes.” [Online]. Available:https://docs.oracle.com/javase/ tutorial/java/javaOO/nested.html, Accessed on: Mar. 10, 2025
2025
-
[19]
Software plagiarism detection: a graph- based approach
D.-K. Chae, J. Ha, S.-W. Kim, B. Kang, and E. G. Im, “Software plagiarism detection: a graph- based approach”,Proc. 22nd ACM Intern. Conf. on Inf. and Knowl. Manag., pp.1577–1580, 2013. DOI: 10.1145/2505515.2507848
-
[20]
A sur- vey of software watermarking
W. Zhu, C. Thomborson, and F.-Y. Wang, “A sur- vey of software watermarking”,Intel. and Sec. Inf., pp.454-–458, Springer, 2005
2005
-
[21]
A practical method for watermarking Java programs
A. Monden, H. Iida, K. Matsumoto, K. Inoue, and K. Torii, “A practical method for watermarking Java programs”, inProc. 24th IEEE compsac2000, pp.191– 197, Taipei, Taiwan, 2000
2000
-
[22]
A method for detecting the theft of java programs through anal- ysis of the control flow information
H.-I. Lim, H. Park, S. Choi, and T. Han, “A method for detecting the theft of java programs through anal- ysis of the control flow information”,Information and Software Technology, vol.51, no.9, pp.1338-–1350, 2009
2009
-
[23]
Soft- ware birthmark design and estimation: A system- atic literature review
S. Nazir, S. Shahzad, and N. Mukhtar, “Soft- ware birthmark design and estimation: A system- atic literature review”,Arab. Journal for Science and Engineering, vol.44, pp.3905–3927, 2019. DOI: 10.1007/s13369-019-03718-9
-
[24]
Design and Evaluation of Dynamic Soft- ware Birthmarks Based on API Calls
H. Tamada, K. Okamoto, M. Nakamura, and A. Monden, “Design and Evaluation of Dynamic Soft- ware Birthmarks Based on API Calls”,Information Science Technical Report, NAIST-IS-TR2007011, ISSN 0919-9527, Graduate School of Information Science, Nara Institute of Science and Technology, Japan, 2007
2007
-
[25]
A New Soft- ware Birthmark based on Weight Sequences of Dy- namic Control Flow Graph for Plagiarism Detection
B. Yuan, J. Wang, Z. Fang, and L. Qi, “A New Soft- ware Birthmark based on Weight Sequences of Dy- namic Control Flow Graph for Plagiarism Detection”, The Computer Journal, vol.61, no.8, pp.1202—1215,
-
[26]
DOI: 10.1093/comjnl/bxy055
-
[27]
Dynamic Software Birthmarks to Detect the Theft of Windows Applications
H. Tamada, K. Okamoto, M. Nakamura, and A. Monden, “Dynamic Software Birthmarks to Detect the Theft of Windows Applications”,International Symposium on Future Software Technology, vol. 20, no. 22, 2004
2004
-
[28]
Software Plagiarism Detection with Birthmarks Based on Dynamic Key Instruc- tion Sequences
Z. Tian, Q. Zheng, T. Liu, M. Fan, E. Zhuang, and Z. Yang, “Software Plagiarism Detection with Birthmarks Based on Dynamic Key Instruc- tion Sequences”,IEEE Trans. on Software Engi- neering, vol.41, no.12, pp.1217–1235, 2015. DOI: 10.1109/TSE.2015.2454508
-
[29]
Malware Variant Detec- tion Using Similarity Search over Sets of Control Flow Graphs
S. Cesare and Y. Xiang, “Malware Variant Detec- tion Using Similarity Search over Sets of Control Flow Graphs”,2011IEEE 10th International Conference on Trust, Security and Privacy in Computing and Com- munications, Changsha, China, 2011, pp. 181–189. DOI: 10.1109/TrustCom.2011.26
-
[30]
A summary of the international standard date and time notation
Markus Kuhn, “A summary of the international standard date and time notation”, [Online]. Avail- 17 able:https://www.cl.cam.ac.uk/ ~mgk25/iso- time.html. Accessed on: Mar. 13, 2025
2025
-
[31]
ReDeBug: finding unpatched code clones in entire os distribu- tions
J. Jang, A. Agrawal, and D. Brumley, “ReDeBug: finding unpatched code clones in entire os distribu- tions”, inProc. of the 33rd IEEE Symposium on Se- curity and Privacy (Oakland), USA, 2012
2012
-
[32]
Towards the auto extraction for the dynamic software birth- marks with the inputs from the plaintiff software
C. Alejandro, H. Tamada, and Y. Kanzaki, “Towards the auto extraction for the dynamic software birth- marks with the inputs from the plaintiff software”, J-Global, vol.22, no.1, pp.165–168, 2023
2023
-
[33]
Clone search for malicious code correlation
P. Charland, B. C. Fung, and M. R. Farhadi, “Clone search for malicious code correlation”,In ATO RTO Symposium on Information Assurance and Cyber De- fense (IST-111), 2012
2012
-
[34]
Public Git Archive: a Big Code dataset for all
V. Markovtsev, W. Long, “Public Git Archive: a Big Code dataset for all”. arXiv:1803.10144 [cs.SE], 2018. DOI: 10.48550/arXiv.1803.10144
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.10144 2018
-
[35]
A Software Birthmark Based on Dynamic Op- code n-gram
B. Lu, F. Liu, X. Ge, B. Liu, and X. Luo, “A Software Birthmark Based on Dynamic Op- code n-gram”,International Conference on Seman- tic Computing (ICSC 2007), pp.37–44, 2007. DOI: 10.1109/ICSC.2007.15
-
[36]
Program Characterization Using Runtime Values and Its Application to Software Plagiarism Detection
Y.-C. Jhi, X. Jia, X. Wang, S. Zhu, P. Liu, and D. Wu, “Program Characterization Using Runtime Values and Its Application to Software Plagiarism Detection”, inProc. of the ACM/IEEE 33rd Inter- national Conference on Software Engineering (ICSE 2011), Software Engineering in Practice Track, USA, 2011
2011
-
[37]
Behav- ior Based Software Theft Detection
X. Wang, Y.-C. Jhi, S. Zhu, and P. Liu, “Behav- ior Based Software Theft Detection”,CCS’09, USA, 2009
2009
-
[38]
DKISB: Dy- namic key instruction sequence birthmark for software plagiarism detection
Z. Tian, Q. Zheng, T. Liu, and M. Fan, “DKISB: Dy- namic key instruction sequence birthmark for software plagiarism detection”,in Proc. IEEE Int. Conf. High Perform. Comput. Commun., pp. 619-–627, 2013
2013
-
[39]
A dynamic birthmark for Java,
D. Schuler, V. Dallmeier, and C. Lindig, “A dynamic birthmark for Java,” inProc. of the twenty-second IEEE/ACM international conference on Automated software engineering (ASE ’07), pp. 274-–283, 2007
2007
-
[40]
Dy- namic k-gram based software birthmark
Y. Bai, X. Sun, G. Sun, X. Deng, and X. Zhou, “Dy- namic k-gram based software birthmark”, inProc. 19th Australian Softw. Eng. Conf., pp. 644-–649, 2008
2008
-
[41]
GPLAG: detec- tion of software plagiarism by program dependence graph analysis
C. Liu, C. Chen, J. Han, P. S. Yu, “GPLAG: detec- tion of software plagiarism by program dependence graph analysis”,KDD ’06, pp. 872–881, 2006
2006
-
[42]
Program Logic Based Software Plagiarism Detection
F. Zhang, D. Wu, P. Liu, and S. Zhu, “Program Logic Based Software Plagiarism Detection”,2014 IEEE 25th International Symposium on Software Reliability Engineering, pp.66–77, 2014
2014
-
[43]
De- tecting software theft via system call based birth- marks
X. Wang, Y.-C. Jhi, S. Zhu, and P. Liu, “De- tecting software theft via system call based birth- marks”,Computer Security Applications Conference ACSAC’09., 2009
2009
-
[44]
Current Sta- tus of Vizio Case
Software Freedom Conservancy, Inc., “Current Sta- tus of Vizio Case”, Software Freedom Conservancy, [Online]. Available:https://sfconservancy.org/ copyleft-compliance/vizio.html. Accessed on: May 24, 2025
2025
-
[45]
CASE NO.: 30-2021- 01226723-CU-BC-CJC. COMPLAINT FOR: (1) BREACH OF CONTRACT; and (2) DECLARA- TORY RELIEF
R. G. Sanders, S. V. Vakili, J. A. Schlaff, D. N. Schultz, and S. P. Hoffman, “CASE NO.: 30-2021- 01226723-CU-BC-CJC. COMPLAINT FOR: (1) BREACH OF CONTRACT; and (2) DECLARA- TORY RELIEF”, SUPERIOR COURT OF THE STATE OF CALIFORNIA COUNTY OF OR- ANGE - CENTRAL JUSTICE CENTER. [Online]. Available:https://sfconservancy.org/static/ docs/software-freedom-conser...
2021
-
[46]
IBM Cor- poration v. Teraproc Inc. (7:16-cv-07989)
District Court S.D. New York, “IBM Cor- poration v. Teraproc Inc. (7:16-cv-07989)”, CourtListener. [Online]. Available:https: //www.courtlistener.com/docket/4524777/ibm- corporation-v-teraproc-inc/. Accessed on: May 24, 2025
arXiv 2025
-
[47]
Plagiarism in Programming Assignments
M. Joy and M. Luck, “Plagiarism in Programming Assignments”, University of Warwick. Department of Computer Science. (Department of Computer Science Research Report). (Unpublished), 1998
1998
-
[48]
T. Le, A. Carbone, J. Sheard, M. Schuhmacher, M. d. Raadt, and C. Johnson, “Educating computer pro- gramming students about plagiarism through use of a code similarity detection tool”,2013 Learning and Teaching in Computing and Engineering, 2013. DOI: 10.1109/LaTiCE.2013.37
-
[49]
A Generic Approach to Automatic Deobfus- cation of Executable Code
B. Yadegari, B. Johannesmeyer, B. Whitely, and S. Debray, “A Generic Approach to Automatic Deobfus- cation of Executable Code”.In 2015 IEEE Sympo- sium on Security and Privacy. IEEE, USA, 674–691,
2015
-
[50]
DOI: 10.1109/SP.2015.47
-
[51]
A Taxon- omy of Obfuscating Transformations
C. Collberg, C. Thomborson, and D. Low, “A Taxon- omy of Obfuscating Transformations”.Department of Computer Science, The University of Auckland. New Zealand, 1997. URL:http://www.cs.auckland.ac. nz/staff-cgi-bin/mjd/csTRcgi.pl?serial
1997
-
[52]
A survey on software clone detection research,
C. K. Roy and J. R. Cordy, “A survey on software clone detection research,” Queen’s School of Comput- ing TR, vol. 541, no. 115, pp. 64–68, 2007
2007
-
[53]
A Static Java Birthmark Based on Control Flow Edges,
H. -i. Lim, H. Park, S. Choi and T. Han, “A Static Java Birthmark Based on Control Flow Edges,” 2009 33rd Annual IEEE International Computer Soft- ware and Applications Conference, Seattle, WA, USA, 2009, pp. 413-420, DOI: 10.1109/COMPSAC.2009.62. 18
-
[54]
Proceedings of the 22nd International Conference on Program Comprehension , pages=
Z. Tian, Q. Zheng, T. Liu, M. Fan, X. Zhang and Z. Yang, “Plagiarism detection for multithreaded soft- ware based on thread-aware software birthmarks, ” In Proceedings of the 22nd International Conference on Program Comprehension (ICPC 2014). Associa- tion for Computing Machinery, New York, USA, 2014, pp. 304–313, DOI: 10.1145/2597008.2597143. B Biography...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.