STEB: A Speech-to-Speech Translation Expressiveness Benchmark for Evaluating Beyond Translation Fidelity
Pith reviewed 2026-06-25 20:14 UTC · model grok-4.3
The pith
Current speech-to-speech translation systems preserve lexical meaning but struggle to transfer emotion and nonverbal vocalizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
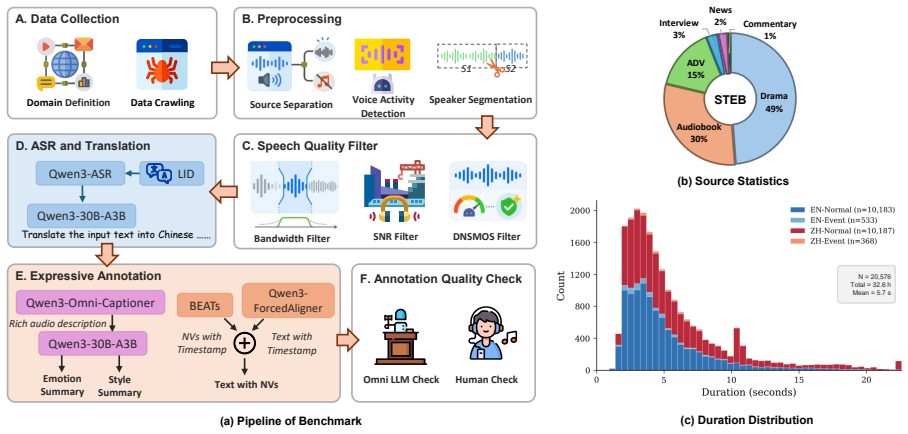
STEB evaluates S2ST on a 32.6-hour Chinese-English dataset using both conventional metrics and a caption-then-summarize approach with an LLM judge for expressiveness attributes. Across cascaded, end-to-end, and LLM-based systems, strong fidelity performance contrasts with weak results on emotion and NV preservation, demonstrating that semantic transfer and expressive transfer are separate capabilities.
What carries the argument
A caption-then-summarize framework that extracts structured expressive attributes from speech and uses an LLM to compare source and translated attributes without needing aligned references.
If this is right
- Expressiveness must be treated as a separate objective from meaning preservation in S2ST development.
- Cascaded systems require specific enhancements to handle emotion and vocalization transfer effectively.
- Reference-free evaluation becomes essential for expressive dimensions because creating aligned expressive references is impractical at scale.
- Speech large language models show potential but still fall short on nonverbal preservation compared to fidelity.
Where Pith is reading between the lines
- Applications like real-time interpretation in sensitive contexts may suffer from lost emotional nuance even when words are accurate.
- Extending the benchmark to additional language pairs could reveal whether the expressiveness gap is language-specific or general.
- Training methods that incorporate expressiveness feedback directly could be tested using the benchmark's evaluation approach.
Load-bearing premise
The structured attributes extracted by the caption-then-summarize process and judged by the LLM accurately reflect human judgments of expressiveness in speech.
What would settle it
Human listener studies that find no correlation or weak correlation between the benchmark's LLM scores and direct ratings of emotion or NV preservation would invalidate the evaluation method.
Figures

read the original abstract
Speech-to-speech translation (S2ST) should preserve not only lexical meaning, but also expressive attributes: emotion, scenario style (e.g., news reporting vs. dramatic dialogue), and nonverbal vocalizations (NVs). Moreover, collecting cross-lingual target speech that is both translation-faithful and expressively aligned with the source is difficult at scale, making reference-based evaluation impractical. We introduce STEB (Speech-to-Speech Translation Expressiveness Benchmark), a 32.6-hour Chinese--English benchmark that evaluates both standard dimensions (translation fidelity, speaker similarity, duration alignment) and expressiveness dimensions (emotion, scenario style, NV preservation). For expressiveness evaluation, STEB uses a caption-then-summarize framework that converts speech into structured expressive attributes and compares source and hypothesis attributes with an LLM judge. Human validation shows statistically significant correlations with listener judgments across all expressive dimensions. We evaluate six S2ST systems covering cascaded systems, end-to-end models, and speech large language models. Many systems, especially cascaded ones, achieve strong translation fidelity, but they still struggle with emotion preservation (best: 3.82/5) and NV preservation (best: 2.31/5). These results reveal a gap between semantic transfer and expressive transfer, identifying expressiveness preservation as an open challenge for S2ST. Audio samples are available at https://cmots.github.io/steb.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STEB, a 32.6-hour Chinese-English benchmark for speech-to-speech translation (S2ST) that evaluates standard dimensions (translation fidelity, speaker similarity, duration alignment) alongside expressiveness dimensions (emotion, scenario style, and nonverbal vocalization preservation). It employs a caption-then-summarize framework to extract structured attributes from speech and uses an LLM judge for source-hypothesis comparisons on expressiveness, with human validation demonstrating statistically significant correlations to listener judgments. Evaluation of six systems (cascaded, end-to-end, and speech LLMs) shows strong fidelity in many cases but limited expressiveness preservation (best emotion score 3.82/5, best NV score 2.31/5), identifying expressiveness transfer as an open challenge. Audio samples are provided.
Significance. If the LLM-judge pipeline validly tracks human perception of expressiveness, the benchmark is significant for addressing the practical difficulty of collecting expressively aligned cross-lingual references in S2ST. It provides a scalable, reference-free evaluation method with external human validation and an independent LLM judge, while making audio samples available. The results credibly separate semantic from expressive transfer and flag a concrete limitation in current systems.
major comments (1)
- [Human validation section] Human validation section: the manuscript states that correlations with listener judgments are statistically significant across expressive dimensions but does not report the correlation coefficients, inter-rater agreement statistics, or per-dimension/per-system robustness. Because the headline claim of an expressiveness gap (and thus the benchmark's validity) rests on the caption-then-summarize + LLM-judge pipeline reliably reflecting human perception, these quantitative details are required to assess whether the observed gap could be partly attributable to metric noise.
minor comments (1)
- [Abstract] Abstract: the claim of 'statistically significant correlations' would be strengthened by including the actual coefficient values or at least their range.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the human validation section. We agree that additional quantitative details will strengthen the presentation of our results and better substantiate the reliability of the LLM-judge pipeline.
read point-by-point responses
-
Referee: [Human validation section] Human validation section: the manuscript states that correlations with listener judgments are statistically significant across expressive dimensions but does not report the correlation coefficients, inter-rater agreement statistics, or per-dimension/per-system robustness. Because the headline claim of an expressiveness gap (and thus the benchmark's validity) rests on the caption-then-summarize + LLM-judge pipeline reliably reflecting human perception, these quantitative details are required to assess whether the observed gap could be partly attributable to metric noise.
Authors: We agree with the referee that reporting the specific correlation values and agreement statistics is necessary for a complete assessment. In the revised manuscript we will add: (1) Pearson and Spearman correlation coefficients between the LLM-judge scores and human listener judgments for each expressive dimension (emotion, scenario style, NV preservation); (2) inter-rater agreement statistics (e.g., Krippendorff’s alpha) across the human evaluators; and (3) per-dimension and, where sample sizes permit, per-system breakdowns to demonstrate robustness. These additions will be placed in the human validation subsection and will be accompanied by the corresponding statistical significance values already mentioned in the current text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines STEB as a new benchmark whose expressiveness scores are produced by an independent caption-then-summarize + LLM-judge pipeline that is then separately validated against human listeners via reported statistically significant correlations. No equations, fitted parameters, or self-citations are shown that would make any reported score or the identified fidelity-expressiveness gap equivalent to its own inputs by construction; the evaluation pipeline and human validation stand as external checks rather than tautological re-statements of the benchmark definition itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-based comparison of structured expressive attributes correlates with human listener judgments of emotion, style, and NV preservation
- standard math Standard speech metrics (translation fidelity, speaker similarity, duration alignment) can be measured independently of expressiveness dimensions
Reference graph
Works this paper leans on
-
[1]
Weiss and Fadi Biadsy and Wolfgang Macherey and Melvin Johnson and Zhifeng Chen and Yonghui Wu , title =
Ye Jia and Ron J. Weiss and Fadi Biadsy and Wolfgang Macherey and Melvin Johnson and Zhifeng Chen and Yonghui Wu , title =. INTERSPEECH , year =
-
[2]
ICML , year =
Ye Jia and Michelle Tadmor Ramanovich and Tal Remez and Roi Pomerantz , title =. ICML , year =
-
[3]
Ann Lee and Peng-Jen Chen and Changhan Wang and Jiatao Gu and Sravya Popuri and Xutai Ma and Adam Polyak and Yossi Adi and Qing He and Yun Tang and Juan Pino and Wei-Ning Hsu , title =. Proc. Assoc. Comput. Linguistics (Volume 1: Long Papers) (ACL) , year =
-
[4]
2023 , pages =
Kun Song and Yi Ren and Yi Lei and Chunfeng Wang and Kun Wei and Lei Xie and Xiang Yin and Zejun Ma , title =. 2023 , pages =
2023
-
[5]
Yongqi Wang and Jionghao Bai and Rongjie Huang and Ruiqi Li and Zhiqing Hong and Zhou Zhao , title =. Proc. Assoc. Comput. Linguistics (Volume 4: Student Research Workshop) (ACL) , year =
-
[6]
Qianqian Dong and Zhiying Huang and Qiao Tian and Chen Xu and Tom Ko and Yunlong Zhao and Siyuan Feng and Tang Li and Kexin Wang and Xuxin Cheng and Fengpeng Yue and Ye Bai and Xi Chen and Lu Lu and Zejun Ma and Yuping Wang and Mingxuan Wang and Yuxuan Wang , title =
-
[7]
Chenyang Le and Yao Qian and Dongmei Wang and Long Zhou and Shujie Liu and Xiaofei Wang and Midia Yousefi and Yanmin Qian and Jinyu Li and Sheng Zhao and Michael Zeng , title =
-
[8]
Paul K. Rubenstein and Chulayuth Asawaroengchai and Duc Dung Nguyen and Ankur Bapna and Zalán Borsos and Félix de Chaumont Quitry and Peter Chen and Dalia El Badawy and Wei Han and Eugene Kharitonov and Hannah Muckenhirn and Dirk Padfield and James Qin and Danny Rozenberg and Tara Sainath and Johan Schalkwyk and Matt Sharifi and Michelle Tadmor Ramanovich...
2023
-
[9]
2023 , eprint =
Tianrui Wang and Long Zhou and Ziqiang Zhang and Yu Wu and Shujie Liu and Yashesh Gaur and Zhuo Chen and Jinyu Li and Furu Wei , title =. 2023 , eprint =
2023
-
[10]
2024 , eprint =
Hongyu Gong and Bandhav Veluri , title =. 2024 , eprint =
2024
-
[11]
Seamless Communication and Loïc Barrault and Yu-An Chung and Mariano Coria Meglioli and David Dale and Ning Dong and Mark Duppenthaler and Paul-Ambroise Duquenne and Brian Ellis and Hady Elsahar and Justin Haaheim and John Hoffman and Min-Jae Hwang and Hirofumi Inaguma and Christopher Klaiber and Ilia Kulikov and Pengwei Li and Daniel Licht and Jean Maill...
2023
-
[12]
and Markov, K
Nakamura, S. and Markov, K. and Nakaiwa, H. and Kikui, G. and Kawai, H. and Jitsuhiro, T. and Zhang, J.-S. and Yamamoto, H. and Sumita, E. and Yamamoto, S. , title =. IEEE Trans. Speech Audio Process. , volume =
-
[13]
Casacuberta and H
F. Casacuberta and H. Ney and F.J. Och and E. Vidal and J.M. Vilar and S. Barrachina and I. Garc. Some approaches to statistical and finite-state speech-to-speech translation , journal =
-
[14]
2024 , eprint =
Yifan Peng and Ilia Kulikov and Yilin Yang and Sravya Popuri and Hui Lu and Changhan Wang and Hongyu Gong , title =. 2024 , eprint =
2024
-
[15]
LREC , year =
Ye Jia and Michelle Tadmor Ramanovich and Quan Wang and Heiga Zen , title =. LREC , year =
-
[16]
2022 , pages =
Alexis Conneau and Min Ma and Simran Khanuja and Yu Zhang and Vera Axelrod and Siddharth Dalmia and Jason Riesa and Clara Rivera and Ankur Bapna , title =. 2022 , pages =
2022
-
[17]
2020 , eprint =
Changhan Wang and Anne Wu and Juan Pino , title =. 2020 , eprint =
2020
-
[18]
2002 , pages =
Kishore Papineni and Salim Roukos and Todd Ward and Wei-Jing Zhu , title =. 2002 , pages =
2002
-
[19]
2023 , pages =
Alec Radford and Jong Wook Kim and Tao Xu and Greg Brockman and Christine McLeavey and Ilya Sutskever , title =. 2023 , pages =
2023
-
[20]
2022 , pages =
Zhifu Gao and Shiliang Zhang and Ian McLoughlin and Zhijie Yan , title =. 2022 , pages =
2022
-
[21]
2024 , howpublished =
Silero Team , title =. 2024 , howpublished =
2024
-
[22]
2025 , eprint=
Qwen3-Omni Technical Report , author=. 2025 , eprint=
2025
-
[23]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =
-
[24]
Hirofumi Inaguma and Sravya Popuri and Ilia Kulikov and Peng-Jen Chen and Changhan Wang and Yu-An Chung and Yun Tang and Ann Lee and Shinji Watanabe and Juan Pino , title =. Proc. Assoc. Comput. Linguistics (Volume 1: Long Papers) (ACL) , year =
-
[25]
Peloquin and Hongyu Gong and Peng-Jen Chen and Ann Lee , title =
Min-Jae Hwang and Ilia Kulikov and Benjamin N. Peloquin and Hongyu Gong and Peng-Jen Chen and Ann Lee , title =. 2024 , pages =
2024
-
[26]
2025 , eprint=
UniSS: Unified Expressive Speech-to-Speech Translation with Your Voice , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint =
Tom Labiausse and Laurent Mazaré and Edouard Grave and Patrick Pérez and Alexandre Défossez and Neil Zeghidour , title =. 2025 , eprint =
2025
-
[28]
SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations , booktitle =
Paul-Ambroise Duquenne and Hongyu Gong and Ning Dong and Jingfei Du and Ann Lee and Vedanuj Goswami and Changhan Wang and Juan Pino and Beno. SpeechMatrix: A Large-Scale Mined Corpus of Multilingual Speech-to-Speech Translations , booktitle =. 2023 , pages =
2023
-
[29]
2025 , eprint=
Step-Audio 2 Technical Report , author=. 2025 , eprint=
2025
-
[30]
Farinha and Alon Lavie , title =
Ricardo Rei and Craig Stewart and Ana C. Farinha and Alon Lavie , title =. Proc. Empirical Methods Nat. Lang. Process. (EMNLP) (Volume 1: Long Papers) , year =
-
[31]
xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection , journal =
Nuno Miguel Guerreiro and Ricardo Rei and Daan van Stigt and Lu. xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection , journal =
-
[32]
EMNLP (Findings) , pages =
Cheng-Han Chiang and Xiaofei Wang and Chung-Ching Lin and Kevin Lin and Linjie Li and Radu Kopetz and Yao Qian and Zhendong Wang and Zhengyuan Yang and Hung-yi Lee and Lijuan Wang , title =. EMNLP (Findings) , pages =
-
[33]
2026 , eprint=
TTS-PRISM: A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis , author=. 2026 , eprint=
2026
-
[34]
2026 , eprint=
EchoMind: An Interrelated Multi-level Benchmark for Evaluating Empathetic Speech Language Models , author=. 2026 , eprint=
2026
-
[35]
ACL , pages =
Qian Yang and Jin Xu and Wenrui Liu and Yunfei Chu and Ziyue Jiang and Xiaohuan Zhou and Yichong Leng and Yuanjun Lv and Zhou Zhao and Chang Zhou and Jingren Zhou , title =. ACL , pages =
-
[36]
Mattia Antonino Di Gangi and Roldano Cattoni and Luisa Bentivogli and Matteo Negri and Marco Turchi , title =
-
[37]
Sirou Chen and Sakiko Yahata and Shuichiro Shimizu and Zhengdong Yang and Yihang Li and Chenhui Chu and Sadao Kurohashi , title =
-
[38]
EMNLP , pages =
Maureen de Seyssel and Antony D'Avirro and Adina Williams and Emmanuel Dupoux , title =. EMNLP , pages =
-
[39]
ICASSP , pages =
Herv\'e Bredin and Ruiqing Yin and Juan Manuel Coria and Gregory Gelly and Pavel Korshunov and Marvin Lavechin and Diego Fustes and Hadrien Titeux and Wassim Bouaziz and Marie-Philippe Gill , title =. ICASSP , pages =
-
[40]
INTERSPEECH , pages =
Hui Wang and Siqi Zheng and Yafeng Chen and Luyao Cheng and Qian Chen , title =. INTERSPEECH , pages =
-
[41]
Chandan K. A. Reddy and Vishak Gopal and Ross Cutler , title =. ICASSP , pages =
-
[42]
2026 , eprint=
Qwen3-ASR Technical Report , author=. 2026 , eprint=
2026
-
[43]
Effective Pre-Training of Audio Transformers for Sound Event Detection , booktitle =
Florian Schmid and Tobias Morocutti and Francesco Foscarin and Jan Sch. Effective Pre-Training of Audio Transformers for Sound Event Detection , booktitle =
-
[44]
ICASSP , pages =
Wei Tsung Lu and Ju-Chiang Wang and Qiuqiang Kong and Yun-Ning Hung , title =. ICASSP , pages =
-
[45]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[46]
Chen , title =
Bin Wang and Xunlong Zou and Geyu Lin and Shuo Sun and Zhuohan Liu and Wenyu Zhang and Zhengyuan Liu and AiTi Aw and Nancy F. Chen , title =. Proc. North Am. Chapter Assoc. Comput. Linguistics (NAACL) (Long Papers) , year =
-
[47]
2025 , eprint=
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice , author=. 2025 , eprint=
2025
-
[48]
Sanyuan Chen and Yu Wu and Chengyi Wang and Shujie Liu and Daniel Tompkins and Zhuo Chen and Wanxiang Che and Xiangzhan Yu and Furu Wei , title =. Proc. Int. Conf. Mach. Learn. (ICML) , year =
-
[49]
2023 , pages =
Yihan Wu and Junliang Guo and Xu Tan and Chen Zhang and Bohan Li and Ruihua Song and Lei He and Sheng Zhao and Arul Menezes and Jiang Bian , title =. 2023 , pages =
2023
-
[50]
2025 , url =
A New Era of Intelligence with Gemini 3 , author =. 2025 , url =
2025
-
[51]
GitHub , year =
VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning , author =. GitHub , year =
-
[52]
UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data , booktitle =
Chengyi Wang and Yu Wu and Yao Qian and Kenichi Kumatani and Shujie Liu and Furu Wei and Michael Zeng and Xuedong Huang , editor =. UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data , booktitle =. 2021 , url =
2021
-
[53]
The American Journal of Psychology 15, 72–101
The Proof and Measurement of Association Between Two Things , author=. The American Journal of Psychology , volume=. 1904 , publisher=. doi:10.2307/1412159 , url=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.