Optimizing Semiconductor Device Simulations through Low-Precision Arithmetic
Pith reviewed 2026-06-25 20:22 UTC · model grok-4.3
The pith
Low-precision arithmetic enables 51% higher throughput in quantum transport simulations using 40% fewer resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
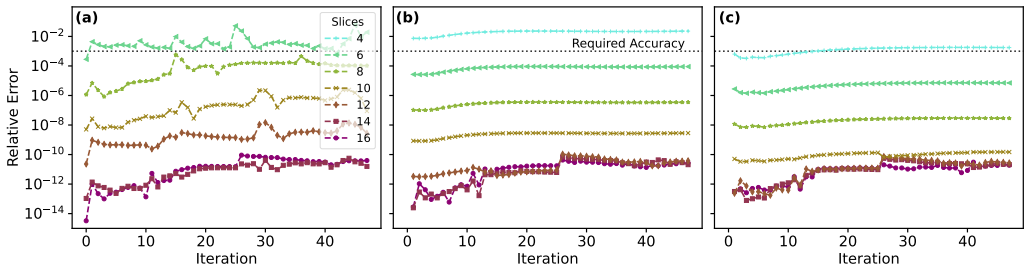
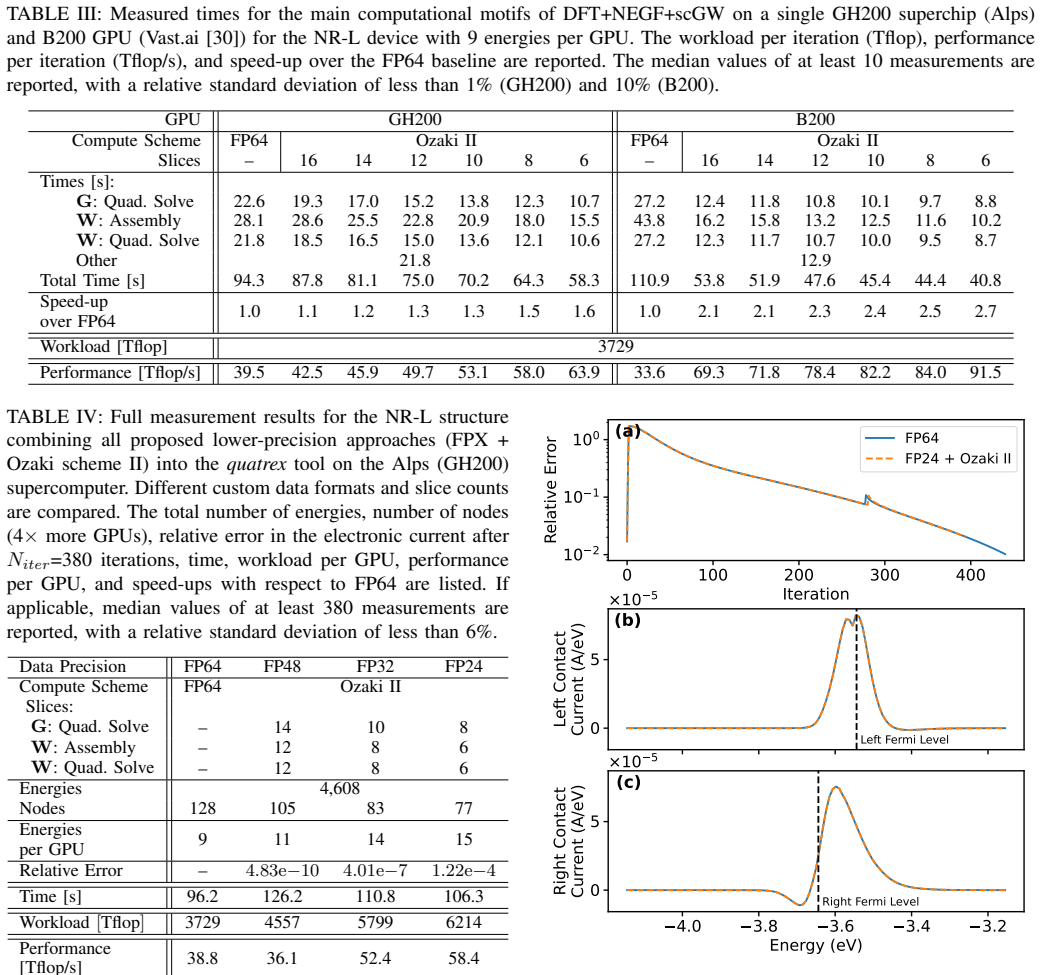
By performing a detailed numerical stability analysis when moving from high- to low-precision formats, the application reveals opportunities for performance gains. Applying these insights to a larger system achieves up to 51% higher throughput while maintaining accurate results on 40% fewer HPC resources than the standard high-precision reference.
What carries the argument
Numerical stability analysis of the solver's computations across different precision formats, identifying safe reductions that preserve result accuracy.
If this is right
- Quantum transport simulations can achieve higher throughput by using low-precision formats where stability allows.
- High-performance computing resources can be reduced by 40% for equivalent accurate results.
- Modern GPU architectures with low-precision units become more accessible for this type of scientific computing.
- The approach generalizes the benefits of precision reduction to other similar applications after benchmark validation.
Where Pith is reading between the lines
- Other HPC codes with similar computational patterns might benefit from analogous stability checks to adopt low-precision arithmetic.
- Future hardware could be optimized for mixed-precision workloads based on application-specific insights like these.
- Testing on additional device structures could help map out the boundaries of safe precision reduction more broadly.
Load-bearing premise
The numerical stability properties observed in the three representative benchmark structures generalize to the larger, more realistic system without introducing unacceptable accuracy degradation.
What would settle it
Executing the larger realistic system simulation with the selected low-precision formats and finding that the results deviate unacceptably from the high-precision reference or produce errors.
Figures

read the original abstract
Architectural changes in GPUs, especially the promotion of low-precision computational units, pose significant challenges to traditional, FP64-based high-performance computing (HPC) applications, while also presenting opportunities. Adopting reduced-precision data formats is a promising avenue to exploit the increased throughput capabilities. However, straightforward data conversions may lead to degraded accuracy or even erroneous results. For a given application, only an in-depth analysis of its numerical stability can reveal the potential of low-precision arithmetic. In this work, we consider the open-source quatrex package, a quantum transport solver capable of breaking the sustained FP64 Eflop/s barrier, to illustrate trade-offs between accuracy losses and computational speed-ups when moving from high- to low-precision formats. We use three representative benchmark structures to explore the application's numerical properties. Applying the gained insights to a larger, more realistic system, we achieve up to 51% higher throughput while maintaining accurate results, on 40% fewer HPC resources than the FP64 reference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the potential of low-precision arithmetic in the open-source quatrex quantum transport solver for semiconductor device simulations. It analyzes numerical stability trade-offs using three representative benchmark structures and applies the resulting insights to a larger, more realistic system, claiming up to 51% higher throughput while maintaining accurate results on 40% fewer HPC resources than the FP64 reference.
Significance. If the generalization of numerical stability holds with quantified error bounds, the work would provide a concrete demonstration of performance gains from reduced-precision formats in a production-grade quantum transport code that already exceeds FP64 Eflop/s. The empirical focus on an open-source package and the move from controlled benchmarks to a realistic device constitute a practical contribution to HPC optimization in computational electronics.
major comments (1)
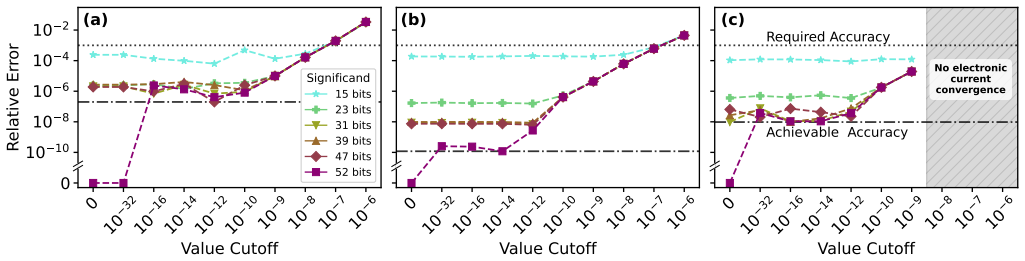
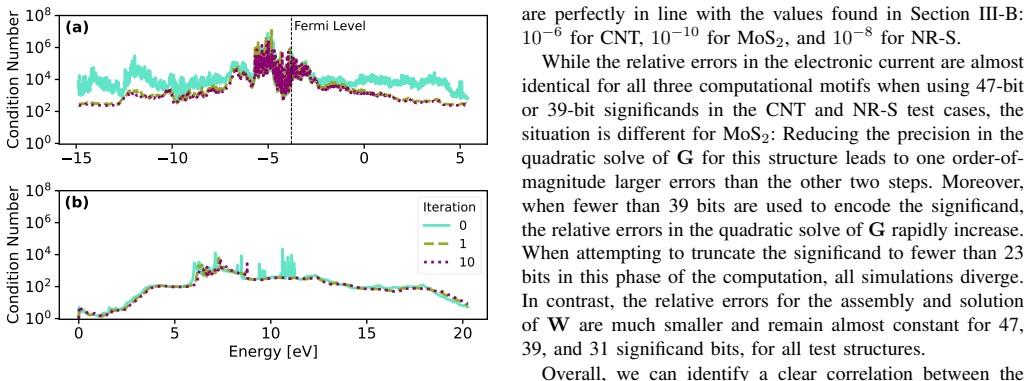
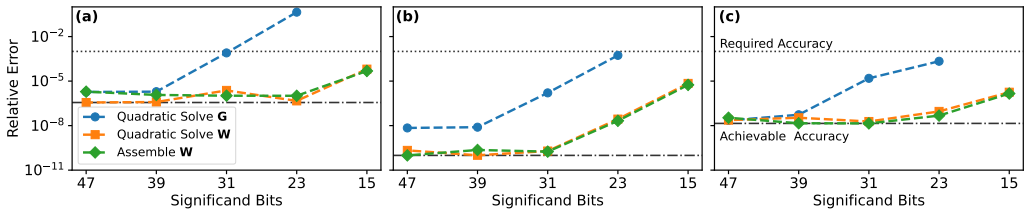
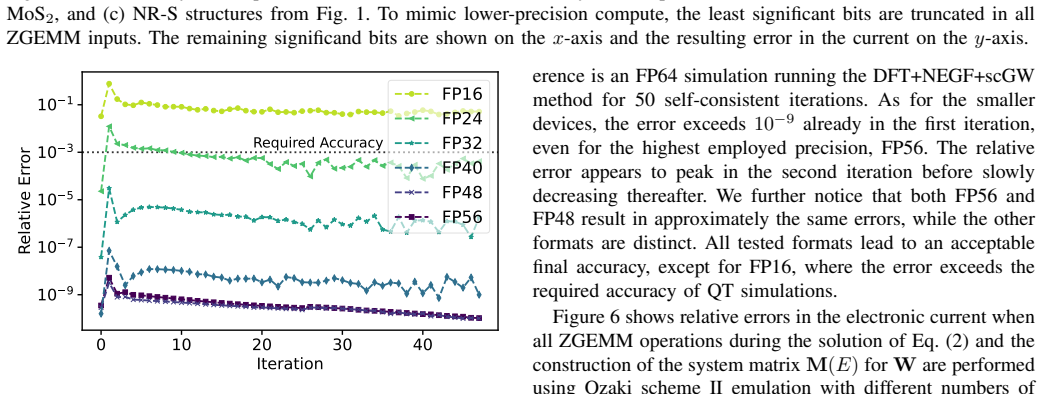
- [Abstract] Abstract: the central claim of 'maintaining accurate results' on the larger system with 51% throughput improvement rests on the unverified transfer of stability properties from the three benchmark structures. No quantitative error metrics (relative error in current, carrier density, or transmission), no tolerance thresholds, and no explicit comparison of larger-system errors against benchmark errors are supplied, preventing assessment of whether accuracy degradation remains acceptable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and will revise the manuscript to strengthen the presentation of quantitative accuracy metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'maintaining accurate results' on the larger system with 51% throughput improvement rests on the unverified transfer of stability properties from the three benchmark structures. No quantitative error metrics (relative error in current, carrier density, or transmission), no tolerance thresholds, and no explicit comparison of larger-system errors against benchmark errors are supplied, preventing assessment of whether accuracy degradation remains acceptable.
Authors: We agree that the abstract would be strengthened by explicit quantitative error metrics and a direct comparison to the benchmark results. The three benchmark structures were selected to capture the dominant numerical sensitivities of the quantum transport solver (potential barriers, scattering rates, and device geometry variations). The realistic system employs identical numerical kernels and material models, providing the basis for transferring stability observations; however, we acknowledge that this transfer should be quantified rather than asserted. In the revised version we will update the abstract to report the relative errors in current, carrier density, and transmission for the larger system, state the tolerance thresholds applied, and include a sentence comparing these error magnitudes to those measured on the benchmarks. These values are already computed in our internal analysis and will be added without altering any results or conclusions. revision: yes
Circularity Check
No circularity; empirical benchmarks and application are independent of inputs by construction.
full rationale
The paper reports direct empirical measurements of numerical stability on three benchmark structures, followed by application of those observations to a larger system. No derivation, equation, or claim reduces to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no self-citation chain supplies a load-bearing uniqueness result. The central throughput claim is presented as an observed outcome of the larger-system run rather than a logical consequence of the benchmark data alone.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dongarra, H
J. Dongarra, H. Meuer, and E. Strohmaier, “TOP500,” https://www. top500.org, 2025, accessed: 2026-03-25
2025
-
[2]
[Online]
NVIDIA Corporation,NVIDIA Blackwell Datasheet, 2025, accessed: 2026-03-25. [Online]. Available: https://nvdam.widen.net/ s/wwnsxrhm2w/blackwell-datasheet-3384703
2025
-
[3]
[Online]
——,NVIDIA GH200 Grace Hopper Superchip Datasheet, 2025, accessed: 2026-03-25. [Online]. Available: https://nvdam.widen.net/s/ rrgqqnpbz8/grace-datasheet-gh200-grace-hopper-superchip-3773000
2025
-
[4]
L. Deuschle, A. Maeder, V . Maillou, N. Vetsch, A. Winka, J. Cao, A. N. Ziogas, and M. Luisier, “Towards exascale simulations of nanoelectronic devices in the gw approximation,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, ser. SC ’24. IEEE Press, 2024. [Online]. Available: https://doi.or...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00069 2024
-
[5]
Silicon ribbonfet cmos at 6nm gate length,
A. Agrawal, W. Chakraborty, W. Li, H. Ryu, B. Markman, S. H. Hoon, R. K. Paul, C. Y . Huang, S. M. Choi, K. Rho, A. Shu, R. Iglesias, P. Wallace, S. Ghosh, K. L. Cheong, J. L. Hockel, R. Thorman, L. Baumgartel, L. Shoer, V . Mishra, S. Berrada, A. Ashita, C. Weber, B. Obradovic, A. A. Oni, Z. Brooks, N. Franco, J. Kavalieros, and G. Dewey, “Silicon ribbon...
-
[6]
N. Vetsch, A. Maeder, V . Maillou, A. Winka, J. Cao, G. Kwasniewski, L. Deuschle, T. Hoefler, A. N. Ziogas, and M. Luisier, “Ab-initio quantum transport with the gw approximation, 42,240 atoms, and sustained exascale performance,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. N...
-
[7]
Datta,Non-equilibrium Green’s function formalism, ser
S. Datta,Non-equilibrium Green’s function formalism, ser. Cambridge Studies in Semiconductor Physics and Microelectronic Engineering. Cambridge University Press, 1995, p. 293–342. [Online]. Available: https://doi.org/10.1017/CBO9780511805776.009
-
[8]
Electron correlation in semiconductors and insulators: Band gaps and quasiparticle energies,
M. S. Hybertsen and S. G. Louie, “Electron correlation in semiconductors and insulators: Band gaps and quasiparticle energies,” Phys. Rev. B, vol. 34, pp. 5390–5413, Oct 1986. [Online]. Available: https://doi.org/10.1103/PhysRevB.34.5390
-
[9]
Conservinggwscheme for nonequilibrium quantum transport in molecular contacts,
K. S. Thygesen and A. Rubio, “Conservinggwscheme for nonequilibrium quantum transport in molecular contacts,”Phys. Rev. B, vol. 77, p. 115333, Mar 2008. [Online]. Available: https://doi.org/10.1103/PhysRevB.77.115333
-
[10]
Self-Consistent Equations Including Exchange and Correlation Effects,
W. Kohn and L. J. Sham, “Self-Consistent Equations Including Exchange and Correlation Effects,”Phys. Rev., vol. 140, no. 4A, pp. A1133–A1138, Nov. 1965. [Online]. Available: https://doi.org/10.1103/ PhysRev.140.A1133
1965
-
[11]
G. Pitner, N. Safron, T.-A. Chao, S. Li, S.-K. Su, G. Zeevi, Q. Lin, H.-Y . Chiu, M. Passlack, Z. Zhang, D. M. Sathaiya, A. Wei, C. Gilardi, E. Chen, S.-L. Liew, V . D.-H. Hou, C.-W. Wu, J. Wu, Z. Lin, J. Fagan, M. Zheng, H. Wang, S. Mitra, H.-S. Philip Wong, and I. Radu, “Building high performance transistors on carbon nanotube channel,” in2023 IEEE Symp...
work page doi:10.23919/vlsitechnologyandcir57934.2023.10185374 2023
-
[12]
Novel channel-last integration of ald mos2 into stacked channel fets on 300mm wafers,
S. Barraud, M. Rodriguez-Fano, J. Pedini, S. Cadot, R. Chouk, B. Dey, J. Hartmann, A. Gharbi, C. Comboroure, A. Sarrazin, F. Boulard, L. Laraignou, A. Campo, H. Grampeix, C. Castan, J. Sturm, A. Souhait ´e, A. Lassenberger, L. Couture, D. Mariolle, P. Hauchecorne, V . Loup, E. Gapihan, K. O’Brien, U. Avci, and F. Andrieu, “Novel channel-last integration o...
-
[13]
K. Ozaki, Y . Uchino, and T. Imamura, “Ozaki scheme ii: A gemm-oriented emulation of floating-point matrix multiplication using an integer modular technique,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.08009
-
[14]
Density-functional method for nonequilibrium electron transport,
M. Brandbyge, J.-L. Mozos, P. Ordej ´on, J. Taylor, and K. Stokbro, “Density-functional method for nonequilibrium electron transport,” Phys. Rev. B, vol. 65, p. 165401, Mar 2002. [Online]. Available: https://doi.org/10.1103/PhysRevB.65.165401
-
[15]
Inelastic transport theory from first principles: Methodology and application to nanoscale devices,
T. Frederiksen, M. Paulsson, M. Brandbyge, and A.-P. Jauho, “Inelastic transport theory from first principles: Methodology and application to nanoscale devices,”Phys. Rev. B, vol. 75, p. 205413, May 2007. [Online]. Available: https://doi.org/10.1103/PhysRevB.75.205413
-
[16]
Mobility calculation in disordered WS2-Al2O3 stacks from first principles,
M. Dossena, B. Van Troeye, F. Ducry, J. Cao, A. Afzalian, G. Pourtois, and M. Luisier, “Mobility calculation in disordered WS2-Al2O3 stacks from first principles,”npj 2D Materials and Applications, vol. 9, no. 1, p. 67, 2025. [Online]. Available: https://doi.org/10.1038/s41699-025-00587-9
-
[17]
L. Deuschle, J. Cao, A. N. Ziogas, A. Winka, A. Maeder, N. Vetsch, and M. Luisier, “Electron-electron interactions in device simulation via nonequilibrium green’s functions and the gw approximation,” Phys. Rev. B, vol. 111, p. 195421, May 2025. [Online]. Available: https://doi.org/10.1103/PhysRevB.111.195421
-
[18]
L. P. Kadanoff and G. Baym,Quantum Statistical Mechanics. CRC Press, Mar. 2018. [Online]. Available: https://doi.org/10.1201/ 9780429493218
2018
-
[19]
Parallel quadratic selected inversion in quantum transport simulation,
V . Maillou, M. Bollhofer, O. Schenk, A. N. Ziogas, and M. Luisier, “Parallel quadratic selected inversion in quantum transport simulation,”
-
[20]
Available: https://doi.org/10.48550/arXiv.2601.04904
[Online]. Available: https://doi.org/10.48550/arXiv.2601.04904
-
[21]
S. Kirchhoff, “Ueber den durchgang eines elektrischen stromes durch eine ebene, insbesondere durch eine kreisf ¨ormige,”Annalen der Physik, vol. 140, no. 4, pp. 497–514, 1845. [Online]. Available: https://doi.org/10.1002/andp.18451400402
-
[22]
Ieee standard for floating-point arithmetic,
“Ieee standard for floating-point arithmetic,”IEEE Std 754-2019 (Revi- sion of IEEE 754-2008), pp. 1–84, 2019
2019
-
[23]
Numerical behavior of nvidia tensor cores,
M. Fasi, N. J. Higham, M. Mikaitis, and S. Pranesh, “Numerical behavior of nvidia tensor cores,”PeerJ Computer Science, vol. 7, p. e330, Feb
-
[24]
Available: https://doi.org/10.7717/peerj-cs.330
[Online]. Available: https://doi.org/10.7717/peerj-cs.330
-
[25]
K. Ozaki, T. Ogita, S. Oishi, and S. M. Rump, “Error-free transformations of matrix multiplication by using fast routines of matrix multiplication and its applications,”Numer. Algorithms, vol. 59, no. 1, p. 95–118, Jan. 2012. [Online]. Available: https: //doi.org/10.1007/s11075-011-9478-1
-
[26]
Dgemm on integer matrix multiplication unit,
H. Ootomo, K. Ozaki, and R. Yokota, “Dgemm on integer matrix multiplication unit,”The International Journal of High Performance Computing Applications, vol. 38, no. 4, pp. 297–313, 2024. [Online]. Available: https://doi.org/10.1177/10943420241239588
-
[27]
Performance enhancement of the ozaki scheme on integer matrix multiplication unit,
Y . Uchino, K. Ozaki, and T. Imamura, “Performance enhancement of the ozaki scheme on integer matrix multiplication unit,”The International Journal of High Performance Computing Applications, vol. 39, no. 3, p. 462–476, jan 2025. [Online]. Available: https: //doi.org/10.1177/10943420241313064
-
[28]
A. Schwarz, A. Anders, C. Brower, H. Bayraktar, J. Gunnels, K. Clark, R. G. Xu, S. Rodriguez, S. Cayrols, P. Tabaszewski, and V . Podlozhnyuk, “Guaranteed dgemm accuracy while using reduced precision tensor cores through extensions of the ozaki scheme,” inProceedings of the Supercomputing Asia and International Conference on High Performance Computing in ...
-
[29]
Stability of block lu factorization,
J. W. Demmel, N. J. Higham, and R. S. Schreiber, “Stability of block lu factorization,”Numerical Linear Algebra with Applications, vol. 2, no. 2, p. 173–190, Mar. 1995. [Online]. Available: https: //doi.org/10.1002/nla.1680020208
-
[30]
G. H. Golub and C. F. van Loan,Matrix Computations, 4th ed. JHU Press, 2013. [Online]. Available: https://epubs.siam.org/doi/abs/10. 1137/1.9781421407944
2013
-
[31]
Emulation of complex matrix multiplication based on the chinese remainder theorem,
Y . Uchino, Q. Ma, T. Imamura, K. Ozaki, and P. L. Gutsche, “Emulation of complex matrix multiplication based on the chinese remainder theorem,” 2025. [Online]. Available: https://doi.org/10.48550/ arXiv.2512.08321
arXiv 2025
-
[32]
Vast.ai: Rent gpus,
Vast.ai, “Vast.ai: Rent gpus,” 2026, accessed: April 5, 2026. [Online]. Available: https://vast.ai/
2026
-
[33]
Fixed-rate compressed floating-point arrays,
P. Lindstrom, “Fixed-rate compressed floating-point arrays,”IEEE Transactions on Visualization and Computer Graphics, vol. 20, no. 12, pp. 2674–2683, 2014. [Online]. Available: https://doi.org/10.1109/ TVCG.2014.2346458
arXiv 2014
-
[34]
Atomistic simulation of nanowires in thesp 3d5s∗ tight-binding formalism: From boundary conditions to strain calculations,
M. Luisier, A. Schenk, W. Fichtner, and G. Klimeck, “Atomistic simulation of nanowires in thesp 3d5s∗ tight-binding formalism: From boundary conditions to strain calculations,”Phys. Rev. B, vol. 74, p. 205323, Nov 2006. [Online]. Available: https://doi.org/10.1103/ PhysRevB.74.205323
2006
-
[35]
Atomistic nanoelectronic device engineering with sustained performances up to 1.44 pflop/s,
M. Luisier, T. B. Boykin, G. Klimeck, and W. Fichtner, “Atomistic nanoelectronic device engineering with sustained performances up to 1.44 pflop/s,” inProceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’11. New York, NY , USA: Association for Computing Machinery,
2011
-
[36]
Available: https://doi.org/10.1145/2063384.2063387
[Online]. Available: https://doi.org/10.1145/2063384.2063387
-
[37]
A data-centric approach to extreme-scale ab initio dissipative quantum transport simulations,
A. N. Ziogas, T. Ben-Nun, G. I. Fern ´andez, T. Schneider, M. Luisier, and T. Hoefler, “A data-centric approach to extreme-scale ab initio dissipative quantum transport simulations,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’19. New York, NY , USA: Association for Computing Mac...
-
[38]
and Rahimian, Abtin and Stadler, Georg and Zorin, Denis , month = nov, year =
——, “Optimizing the data movement in quantum transport simulations via data-centric parallel programming,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’19. New York, NY , USA: Association for Computing Machinery, 2019. [Online]. Available: https://doi.org/10.1145/3295500.3356200
-
[39]
cuBLAS 13.0 documentation,
NVIDIA Corporation, “cuBLAS 13.0 documentation,” https://docs.nvidia.com/cuda/archive/13.0.2/cublas/index.html# floating-point-emulation, 2025, accessed: 2026-03-31
2025
-
[40]
Unlocking Tensor Core Performance with Floating Point Emulation in cuBLAS — NVIDIA Technical Blog,
——, “Unlocking Tensor Core Performance with Floating Point Emulation in cuBLAS — NVIDIA Technical Blog,” https://developer.nvidia.com/blog/ unlocking-tensor-core-performance-with-floating-point-emulation-in-cublas, 2025, accessed: 2026-03-31
2025
-
[41]
Floating Point Emulation in NVIDIA Math Libraries,
——, “Floating Point Emulation in NVIDIA Math Libraries,” https://indico.cern.ch/event/1538409/contributions/6521976/ attachments/3096181/5485165/cern-talk.pdf, 2025, accessed: 2026- 03-31
arXiv 2025
-
[42]
Generalized Slow Roll for Tensors
M. D. Ben, C. Yang, Z. Li, F. H. d. Jornada, S. G. Louie, and J. Deslippe, “Accelerating large-scale excited-state gw calculations on leadership hpc systems,” inSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, 2020, pp. 1–11. [Online]. Available: https://doi.org/10.1109/SC41405.2020.00008
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00008 2020
-
[43]
Quantum espresso toward the exascale,
P. Giannozzi, O. Baseggio, P. Bonf `a, D. Brunato, R. Car, I. Carnimeo, C. Cavazzoni, S. de Gironcoli, P. Delugas, F. Ferrari Ruffino, A. Ferretti, N. Marzari, I. Timrov, A. Urru, and S. Baroni, “Quantum espresso toward the exascale,”The Journal of Chemical Physics, vol. 152, no. 15, p. 154105, 04 2020. [Online]. Available: https://doi.org/10.1063/5.0005082
-
[44]
B. Wilfong, A. Radhakrishnan, H. Le Berre, D. Vickers, T. Prathi, N. Tselepidis, B. Dorschner, R. Budiardja, B. Cornille, S. Abbott, F. Sch ¨afer, and S. Bryngelson, “Simulating many-engine spacecraft: Exceeding 1 quadrillion degrees of freedom via information geometric regularization,” inProceedings of the International Conference for High Performance Co...
-
[45]
H. Ltaief, R. Alomairy, Q. Cao, J. Ren, L. Slim, T. Kurth, B. Dorschner, S. Bougouffa, R. Abdelkhalak, and D. E. Keyes, “Toward capturing genetic epistasis from multivariate genome-wide association studies using mixed-precision kernel ridge regression,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00012 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.